文章目录
- 1. ActionVLAD: Learning spatio-temporal aggregation for action classification [code](https://github.com/rohitgirdhar/ActionVLAD/)[](https://github.com/rohitgirdhar/ActionVLAD/)
- 摘要和结论
- 引言:针对痛点和贡献
- 相关工作
- 模型框架
- 思考不足之处
- 2. Action Tubelet Detector for Spatio-Temporal Action Localization [code](https://github.com/qinzhi-0110/pytorch-act-detector)
- 术语前置
- 摘要和结论
- 引言:针对痛点和贡献
- 相关工作
- 模型框架
- 思考不足之处
- 3. Spatio-Temporal Vector of Locally Max Pooled Features for Action Recognition in Videos
- 摘要和结论
- 引言:针对痛点和贡献
- 模型框架
- 4. Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos [code](https://github.com/kirilllzaitsev/Action_detection/blob/master/action_detection/model.py)
- 摘要和结论
- 引言:针对痛点和贡献
- 相关工作
- 模型框架
- Tube of interest pooling
- Tube Proposal Network
- Linking Tube Proposals
1. ActionVLAD: Learning spatio-temporal aggregation for action classification code
摘要和结论
- 动作分类、在整个entire视频时空范围内 聚合局部卷积特征
- 结合双流网络和可学习的时空特征聚合、端到端
- 跨空间和时间汇集并组合来自不同流的信号。 pooling across space and time and combining signals from the different streams.
- (i)跨空间和时间联合池化很重要,但是(ii)外观和运动流最好聚合成它们自己单独的表示。 (i) it is important to pool jointly across space and time, but (ii) appearance and motion streams are best aggregated into their own separate representations.
引言:针对痛点和贡献
痛点:
- 对3D卷积和双流网络都进行了剖析: 视频建模合适的时空表示是什么? 3D 时空卷积,它可能学习复杂的时空依赖性,但迄今为止在识别性能方面很难扩展; 双流架构,将视频分解为运动流和外观流,并为每个流训练单独的 CNN,最终融合输出。虽然这两种方法都取得了快速进展,但双流架构通常优于时空卷积,因为它们可以轻松利用新的超深架构和针对静态图像分类进行预训练的模型。然而,双流架构在很大程度上忽视了视频的长期时间结构,本质上是学习一个对单个帧或少数(最多 10)帧的短块进行操作的分类器 ,可能会强制不同的分类分数达成共识。
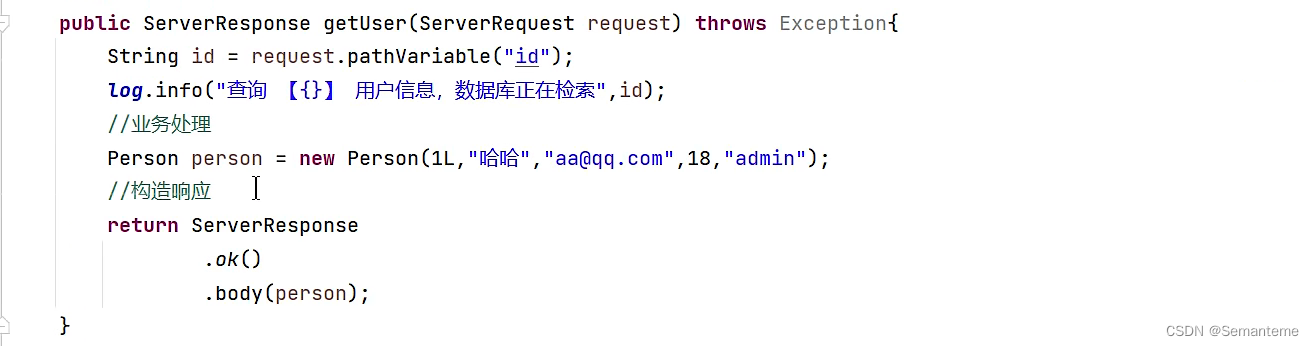
- 帧的独立分类再融合不能准确的对动作进行建模:时间平均是否能够模拟人类行为的复杂时空结构。当相同的子动作在多个动作类之间共享时,这个问题会更加严重。例如,考虑图 1 中所示的“篮球投篮”的复杂复合动作。仅给出几个连续的视频帧,它很容易与其他动作混淆,例如“跑步”、“运球”、“跳跃”和‘扔’。
贡献:
- ActionVLAD CNN 层,这可能有助于相关任务,例如长视频中人类行为的(时空)时间定位
- (1)我们通过将可训练的时空聚合与最先进的双流网络集成来开发强大的视频级表示。 (2) 我们研究了跨空间和时间汇集以及组合来自不同流的信号的不同策略,为不同的设计选择提供了见解和实验证据。
- 优于基线:
相关工作
Trainable Spatio-Temporal Aggregation:
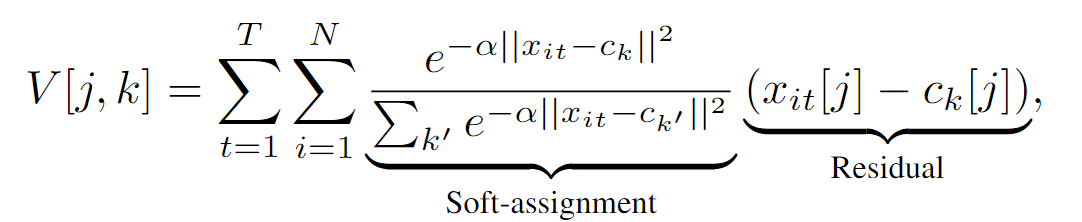
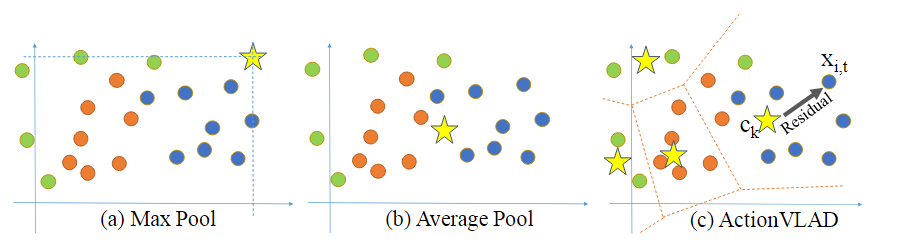
 使用由锚点{ck}表示的K个“动作词”的词汇表将描述符空间RD划分为K个单元来实现的(图3 ©)。
使用由锚点{ck}表示的K个“动作词”的词汇表将描述符空间RD划分为K个单元来实现的(图3 ©)。
模型框架
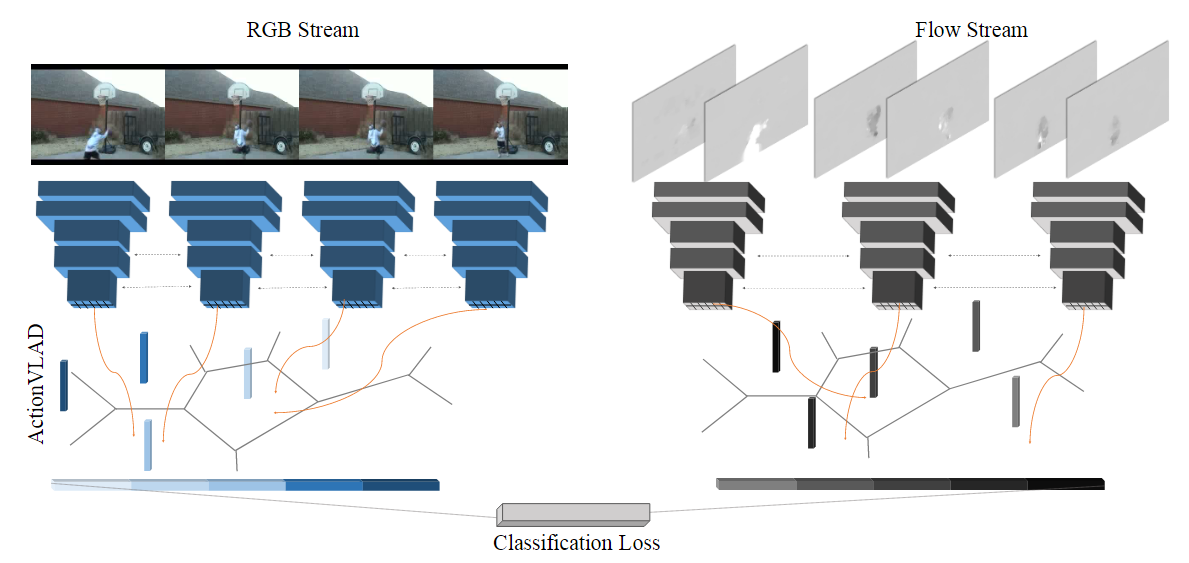
使用标准的CNN架构(VGG-16)从视频的采样外观和运动帧中提取特征。然后使用ActionVLAD池化层跨空间和时间池化这些特征,这是可训练的端到端与分类损失。
Which layer to aggregate?
Evaluation of (a) ActionVLAD at different positions in a VGG-16 network;
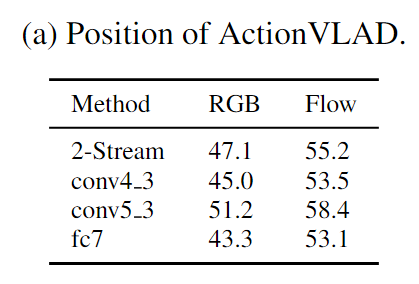
使用双流网络(在帧级上预训练)作为特征生成器,为我们可训练的ActionVLAD池化层提供来自不同帧的输入。但是,我们要汇集哪一层的激活呢?我们通过在最高卷积层(VGG-16的conv5.3)池化特征来获得最佳性能。
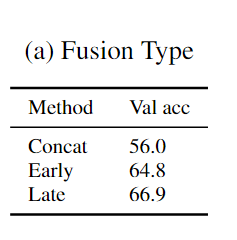
How to combine Flow and RGB streams?
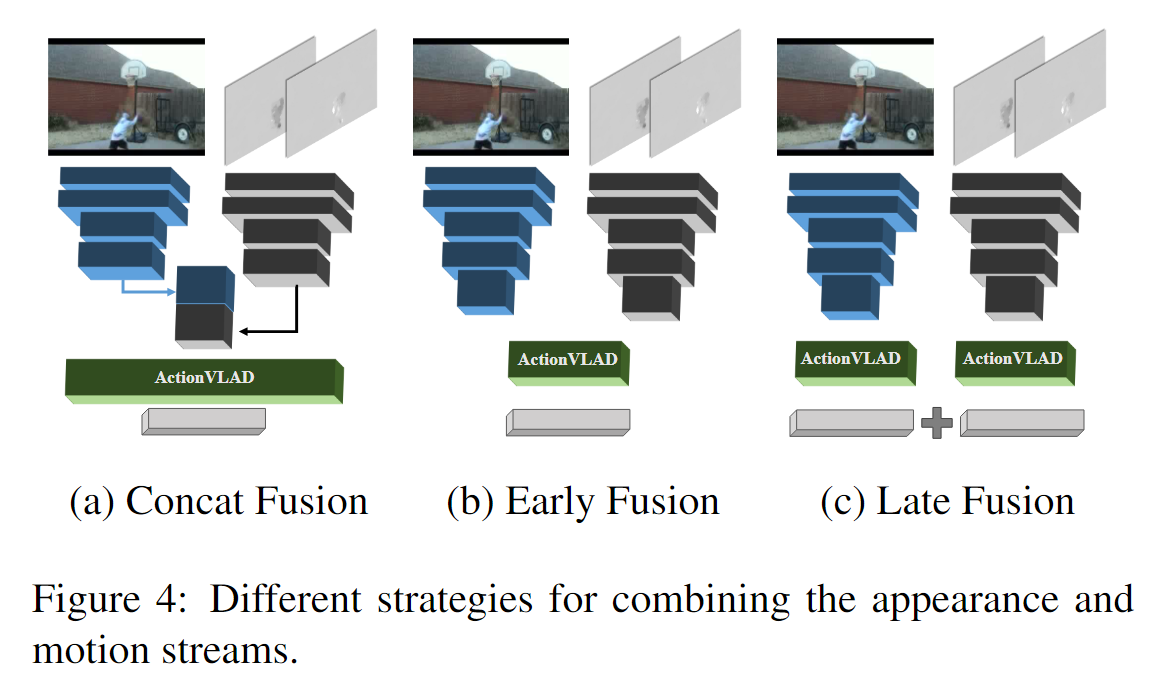
Single ActionVLAD layer over concatenated appearance and motion features (Concat Fusion).
Single ActionVLAD layer over all appearance and motion features (Early Fusion).
Late Fusion.
思考不足之处
- 出发点是好的:单一的动作分类,但是可能有多个不同的子类特征,所以找方法去整合多个子类特征到一整段视频特征的表示中。但多个子类的判断再整合无疑增加了最终精度的下降。
2. Action Tubelet Detector for Spatio-Temporal Action Localization code
术语前置
anchor cuboids : Anchor cuboids与二维目标检测中的bounding boxes类似,都是一种密集采样的方法,用于生成候选框。不同之处在于,anchor cuboids是一种三维形状的候选框,它可以处理视频中的运动物体,并利用了时间维度的信息,而anchor boxes仅适用于二维图像。
tubelets : 本文中的tubelet是指一个由多个连续帧中的bounding box序列组成的时空检测单元,其中每个bounding box都有一个关联的得分,用于表示该检测单元内是否存在某个动作类别。可以理解为在视频中对某个动作的时空位置进行检测和定位的一种方式。 a sequence of bounding boxes, with one confidence score per action class

摘要和结论
- 提出了ACtion Tubelet detector (ACT-detector)【动作管状探测器(ACT-探测器)】
- 将每一帧的特征进行时间的堆叠,形成时间序列信息sequences of frames
- 建立在SSD的基础上,并引入了锚定立方体anchor cuboids,这些锚定长方体在帧序列上sequences of frames进行评分和回归。
引言:针对痛点和贡献
痛点:
- 仅从单帧无法准确识别动作类别。
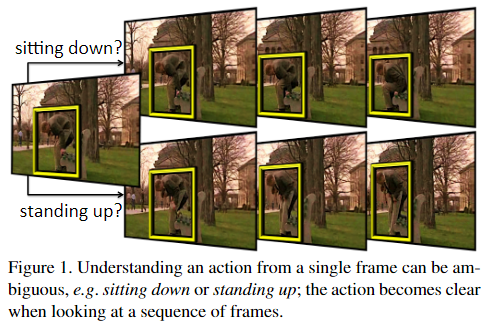
贡献:
- 提出一个Action Tubelet detector (ACT-detector),输入多帧连续视频帧,输出预测行为在多帧上的多个bbox构成的anchor cuboids,然后对每个bbox进行回归得到预测行为的tubelets。由于ACT-detector考虑到多个视频帧的连续性特征,从而能够减少行为预测的模糊性,同时提高定位准确度。
相关工作
- 目标检测:Faster-RCNN(RoI 锚框)–>YOLO和SSD。本文将它们扩展到锚长方体anchor cuboids,从而显著提高动作定位。
- 动作定位:(1)滑动窗口的拓展(需要诸如:长方体cuboid shape的假设,动作中涉及的物体或行为的空间范围保持不变,)(2)将候选框(提案)应用到视频领域,即对视频提出若干个proposals,并作分类。
模型框架
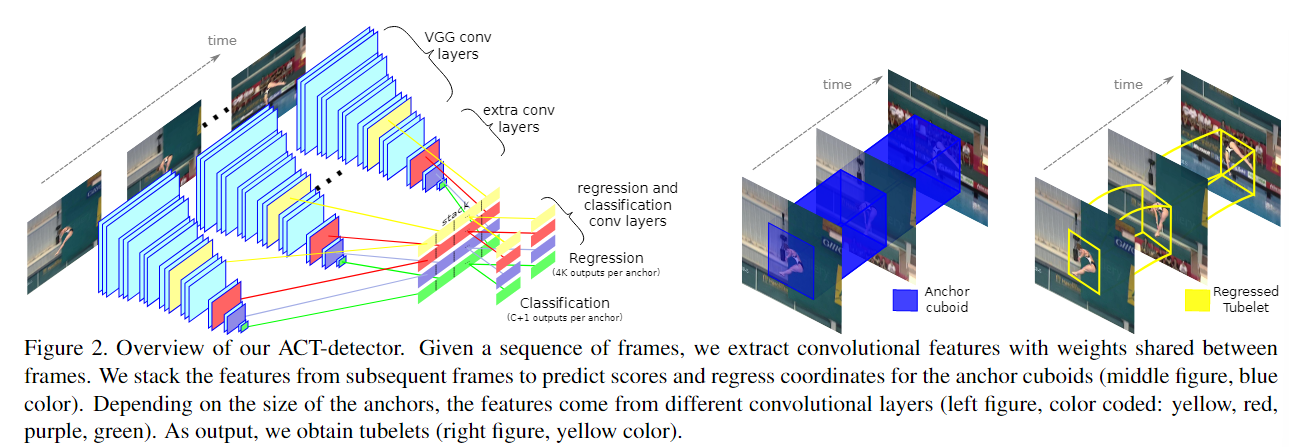

输入: K个连续帧
中间: 经过SSD网络,会有 K 个 * 不同层的特征,把K个不同特征堆叠在一起,不同层特征占不同行。
这些特征经过一个卷积会输出类别分数(class+1个),经过另一个卷积输出回归坐标(4*K )。不同层特征会输出不同分数和坐标,不同层对应不同anchors,因此不同图片位置和不同层会不同的anchor,同一位置也会有多个初始化的anchor,但K帧对应同一个anchor,相当于把SSD按时间维度扩展。
每个anchor最终会对应一个anchor cuboid,并最终NMS后输出一个tubelet或者被忽略.
初始化的anchor cuboid沿帧的维度有固定的位置,同时比人的区域要大,回归后每帧的位置不同,组成tubeltes。
输出: tubletes: a sequence of bounding boxes, with one confidence score per action class.
来源
在给定K帧序列的情况下,ACT检测器计算每个帧的卷积特征。这些卷积特征的权重在所有输入帧之间共享。
具体来说,当处理这个图像序列时,ACTdetector会使用卷积操作来提取每一帧图像的特征。不同的帧之间使用相同的卷积权重来进行特征提取,这意味着卷积核的参数在整个序列中是相同的。这种共享权重的方法有助于模型更好地理解和捕捉动作或物体在不同帧之间的相关性,因为它使用了来自所有帧的信息来提取特征,而不是独立处理每一帧。这有助于提高动作定位或检测的准确性。
堆叠来自K帧的每帧的卷积特征。(经过SSD网络,会有 K 个 * 不同层的特征,把K个不同特征堆叠在一起,不同层特征占不同行。) 堆叠的特征是两个卷积层的输入,一个用于为动作类评分,另一个用于回归锚定长方体。
分类层为每个锚定长方体C+1分数输出:每个动作类一个分数加上一个背景分数。这意味着管状分类是基于帧序列进行的。回归将为每个锚定长方体输出4×K个坐标(每个K帧4个)。请注意,尽管管束中的所有长方体都是联合回归的,但它们会为每个帧产生不同的回归。
(不同层特征会输出不同分数和坐标,不同层对应不同anchors,因此不同图片位置和不同层会不同的anchor,同一位置也会有多个初始化的anchor,但K帧对应同一个anchor,相当于把SSD按时间维度扩展。)
用于评分和回归锚定长方体的神经元的感受野大于其空间范围。这允许我们还基于长方体周围的上下文进行预测,即了解可能移动到长方体之外的参与者。

训练损失:
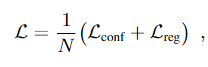 N表示anchor cuboids和真值匹配的个数,
N表示anchor cuboids和真值匹配的个数,
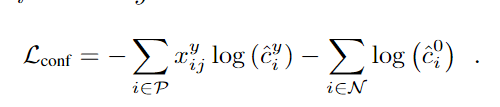 使用softmax损失定义置信度损失
使用softmax损失定义置信度损失
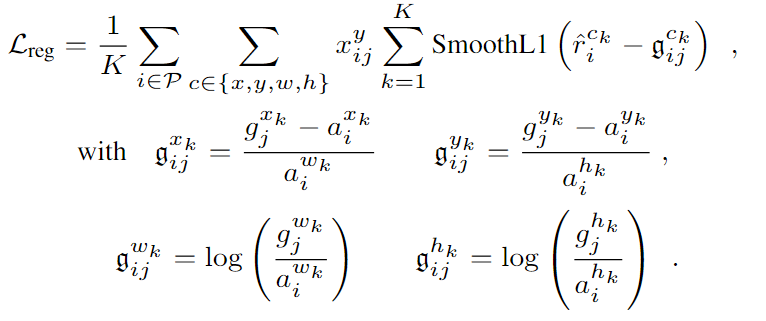
思考不足之处
- 锚点或短管的尺寸和形状的限制:方法中使用的锚点或短管的尺寸和形状通常是事先定义的,这可能导致在处理各种不同尺寸和形状的动作或物体时效果不佳。如果视频中的动作或物体与定义的锚点不匹配,可能会导致错过或误检测。
3. Spatio-Temporal Vector of Locally Max Pooled Features for Action Recognition in Videos
局部最大池特征时空向量(ST-VLMPF)
摘要和结论
- 局部最大池特征时空向量(ST-VLMPF),这是一种专门为局部深度特征编码而设计的基于超向量的编码方法。a super vector-based encoding method specifically designed for encoding local deep features.
- Feature assignment is carried out at two levels, by using the similarity and spatio-temporal information。利用相似性和时空信息在两个层次上进行特征分配。
引言:针对痛点和贡献
痛点:
- 当前标准编码的缺点之一是缺乏考虑时空信息
- 手工制作的特征是手工设计的,通常包含低水平的信息,如边缘。
- 当前预训练神经网络的可用性很高,许多研究人员将它们仅用作特征提取工具,因为在许多方面重新训练或微调神经网络都更加困难。因此,需要一种高效的深度特征编码方法来处理这个问题。
贡献:
- 解决了视频理解的一个重要问题:如何在整个视频上构建一个包含CNN特征的视频表示。
模型框架
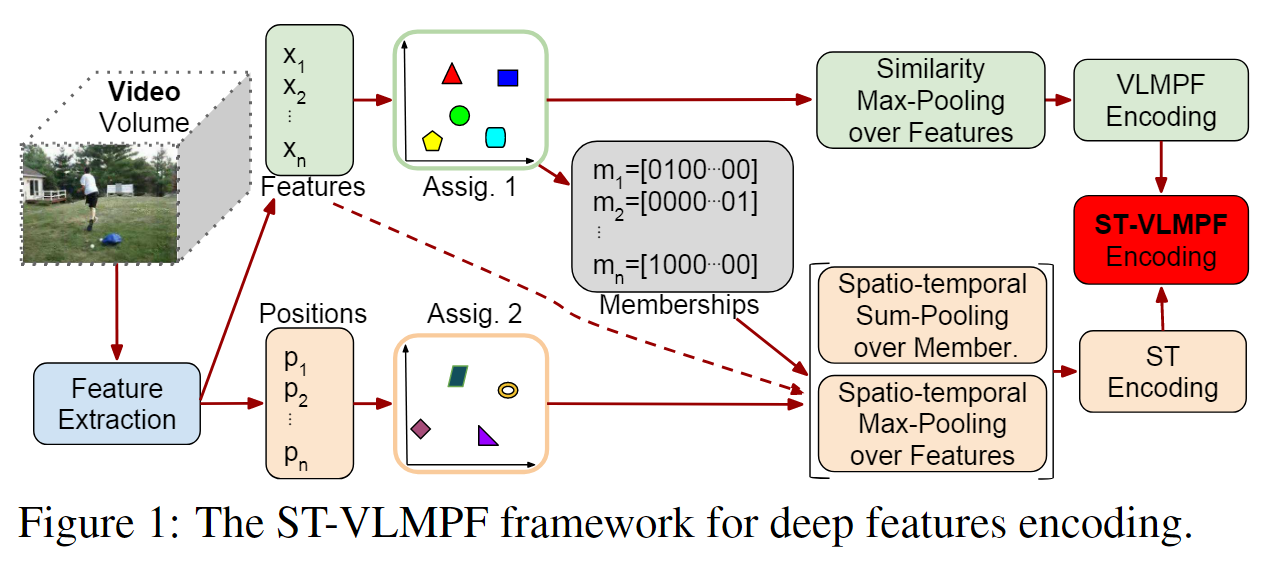
使用k-均值从从数据集中的视频子集提取的随机选择特征的大子集学习码本C。结果表示K1个视觉单词,C={c1,c2,…,ck 1},它们基本上是用k-Means学习的每个特征簇的平均值。
- 首先从视频中提取局部特征。视频用提取的局部特征X={x1, x2,…, xn}∈Rn×d,其中d为特征维数,n为视频的局部特征总数。与局部特征一起,我们保留了它们的位置P ={p1, p2,…, pn}∈Rn×3。
- 我们提出的编码方法使用获得的码本执行两个硬分配,第一个是基于特征相似性,第二个是基于它们的位置。对于第一次分配,每个本地视频特征 xj(j=1, …, n) 被分配给来自码本 C 的最接近的视觉单词。然后,在分配给集群 ci (i=1, …, n) 的特征组上。 …, k1)
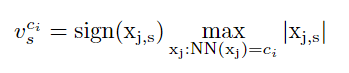
NN(xj) 表示特征 xj 的码本 C 的最近邻质心,基本上它保证我们对分配给视觉词的每组特征分别执行池化; Sign 函数返回数字和 |.| 的符号代表绝对值。基本上,公式 2 获得最大绝对值,同时保留返回的最终结果的初始符号。在图 1 中,我们将这种相似性称为特征最大池化,因为特征根据其相似性进行分组,然后对每个结果组执行最大池化。所有向量 [vc1 , vc2 , …, vck1 ] 的串联表示 VLMPF(局部最大池化特征向量)编码,最终向量大小为 (k1×d)。 - 第一次分配后,我们还保留每个特征的质心成员资格,目的是保留相关的基于相似性的聚类信息。第一次分配后,我们还保留每个特征的质心成员资格,目的是保留相关的基于相似性的聚类信息。对于每个特征,我们用一个向量 m 来表示隶属信息,例如,m=[0100…00] 将成员特征信息映射到码本 C 的第二个视觉词。
- 我们根据特征位置执行第二次分配。图 1 的底部显示了该路径。 P 中的每个特征位置 pj 被分配到码本 PC 中最近的质心。
- 根据时空信息对特征进行分组,然后计算最大绝对值,同时保持特征的原始符号。我们还在等式 3 中连接关于从第一次分配获得的特征相似性的成员信息,其目标是将时空分组特征的相似性成员与时空信息封装在一起。我们连接所有这些向量 [vpc1 , vpc2 , …, vpck2 ] 以创建 ST(时空)编码,从而得到 (k2×d + k2×k1) 向量大小。最后,我们连接 ST 和 VLMPF 编码以创建最终的 ST-VLMPF 表示,用作分类器的输入。因此,ST-VLMPF 表示的向量的最终大小为 (k1×d) + (k2×d + k2×k1)。
Local deep features extraction
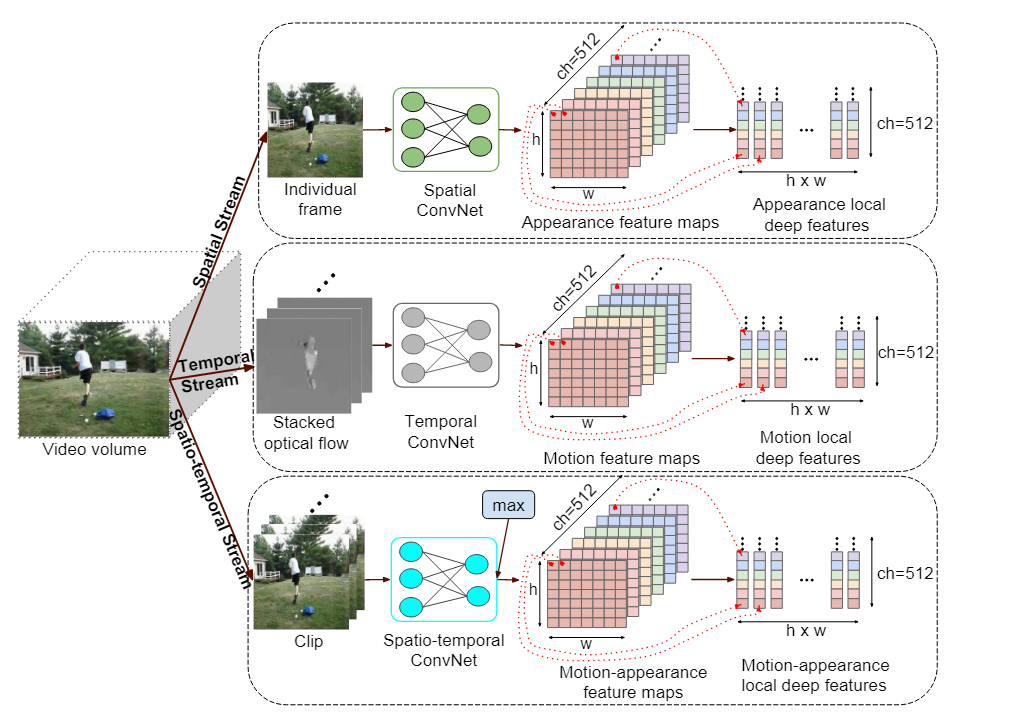
用于捕获外观的空间流、用于捕获运动的时间流和用于同时捕获外观和运动信息的时空流。
4. Tube Convolutional Neural Network (T-CNN) for Action Detection in Videos code
摘要和结论
- propose an endto-end deep network called Tube Convolutional Neural Network (T-CNN) for action detection in videos.提出了一种用于视频中动作检测的端到端管卷积神经网络(T-CNN)。它利用 3D 卷积网络提取有效的时空特征,并在统一的框架中执行动作定位和识别。粗略提议框基于 3D 卷积特征立方体进行密集采样,并链接起来以进行动作识别和定位。
引言:针对痛点和贡献
痛点:
- 以前基于卷积神经网络(CNN)的视频动作检测方法通常包含两个主要步骤:帧级动作提案生成和跨帧提案关联。此外,这些方法大多数采用双流 CNN 框架来分别分别(separately)处理空间和时间特征。
贡献:
- 提出了一种基于端到端深度学习的视频动作检测方法。它直接对原始视频进行操作,使用单个3D网络捕获时空信息,基于3D卷积特征进行动作定位和识别。这是第一个利用 3D ConvNet 进行动作检测的工作。
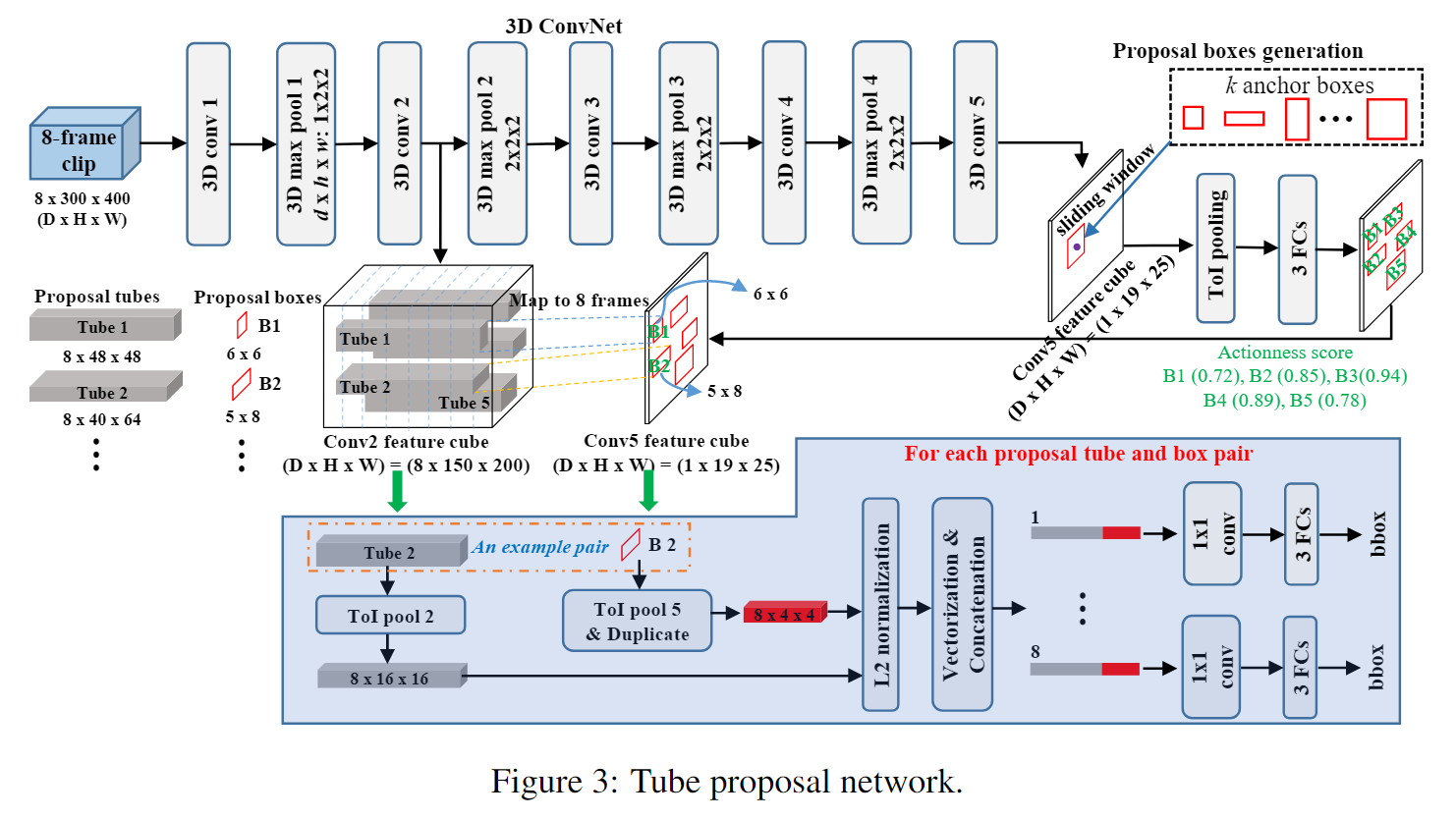
- 引入了 Tube Proposal Network,它利用时域中的skip pooling来保留 3D 体积中动作定位的时间信息。
- 在 T-CNN 中提出了一个新的池化层——Tube-of-Interesr(ToI)池化层。 ToI 池化层是 R-CNN 感兴趣区域 (RoI) 池化层的 3D 推广。它有效地缓解了管道提案的空间和时间大小可变的问题。
相关工作
- R-CNN:对于图像中的目标检测,Region-CNN(R-CNN),区域提案region proposal是使用选择性搜索selective search来提取的。然后将候选区candidate region扭曲warped为固定大小fixed size并输入 ConvNet 以提取 CNN 特征。最后,训练SVM模型用于对象分类。
- Fast R-CNN。与 R-CNN 的多级管道multi-stage pipline相比,Fast R-CNN 在网络中加入了对象分类器,同时训练对象分类器object classifiter和边界框回归器bounding box regressor。引入Region-of-Interest(RoI)池化层来提取不同大小的边界框的固定长度特征向量。
- Faster R-CNN。它引入了 RPN(Region Proposal Network)来代替选择性搜索来生成提案。 RPN 与检测网络共享完整的图像卷积特征,因此提案生成几乎是免费的。 Faster R-CNN 实现了最先进的目标检测性能,同时在测试过程中保持高效。受其高性能的推动,在本文中,我们探索将更快的 R-CNN 从 2D 图像区域推广到 3D 视频量以进行动作检测。
模型框架
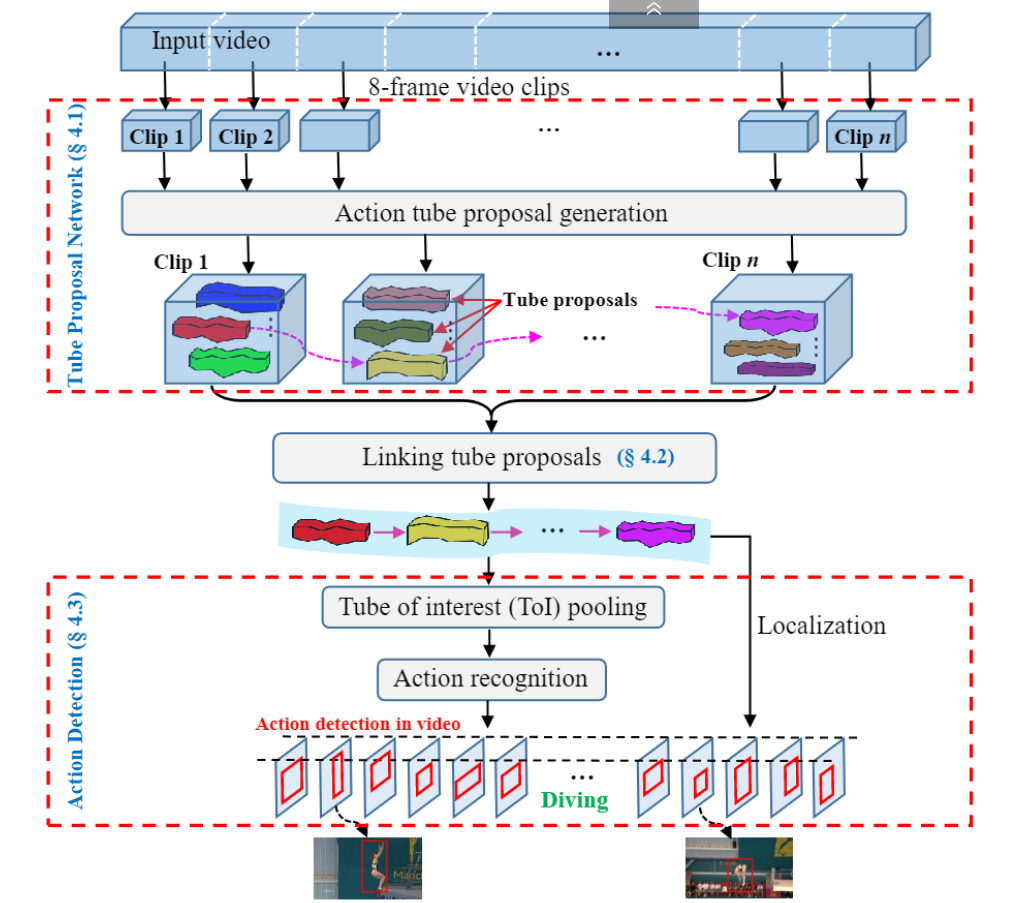
- 输入视频首先被分成相等长度的剪辑 clip。
- 然后,将剪辑clip输入到管建议网络(TPN)并获得一组管建议tube proposals。
- 接下来,每个视频剪辑的管建议根据其动作分数actioness score和相邻建议之间的重叠overlap进行链接,以形成视频中时空动作定位的完整管建议。
- 最后,将Tube-of-Interest(ToI)池化pooling应用于链接link的动作管提议,以生成用于动作标签预测的固定长度特征向量a fixed length feature vector。
Tube of interest pooling
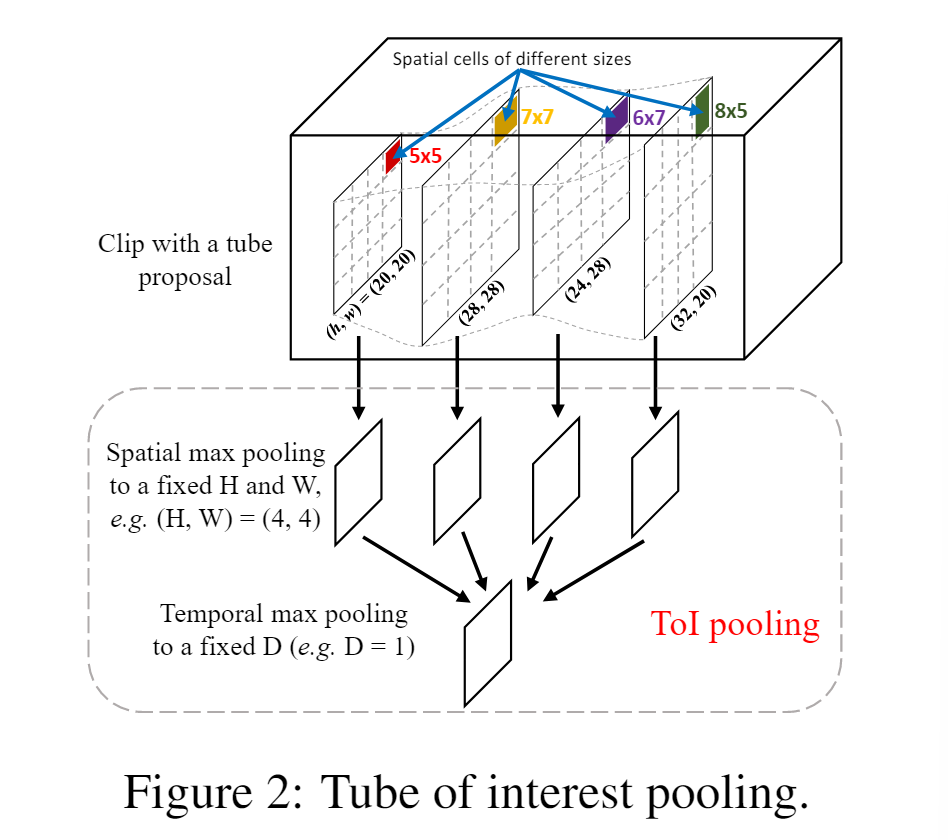
- 空间最大池化: 首先,将 h × w 特征图分为 H × W 个 bin,其中每个 bin 对应于大小约为 h/H × w/W 的单元。在每个单元格中,应用最大池化来选择最大值。
- 时间最大池化: 其次,空间池化的 d 个特征图在时间上被划分为 D个bin。与第一步类似,d/D 相邻特征图被分组在一起以执行标准时间最大池化。因此,ToI 池化层的固定输出大小为 D × H × W 。图 2 展示了 ToI 池化的图示。
- 如上图,红色区域卷积对20*20的特征图分了4个bins,
最大池化(Max Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。
Tube Proposal Network
Linking Tube Proposals
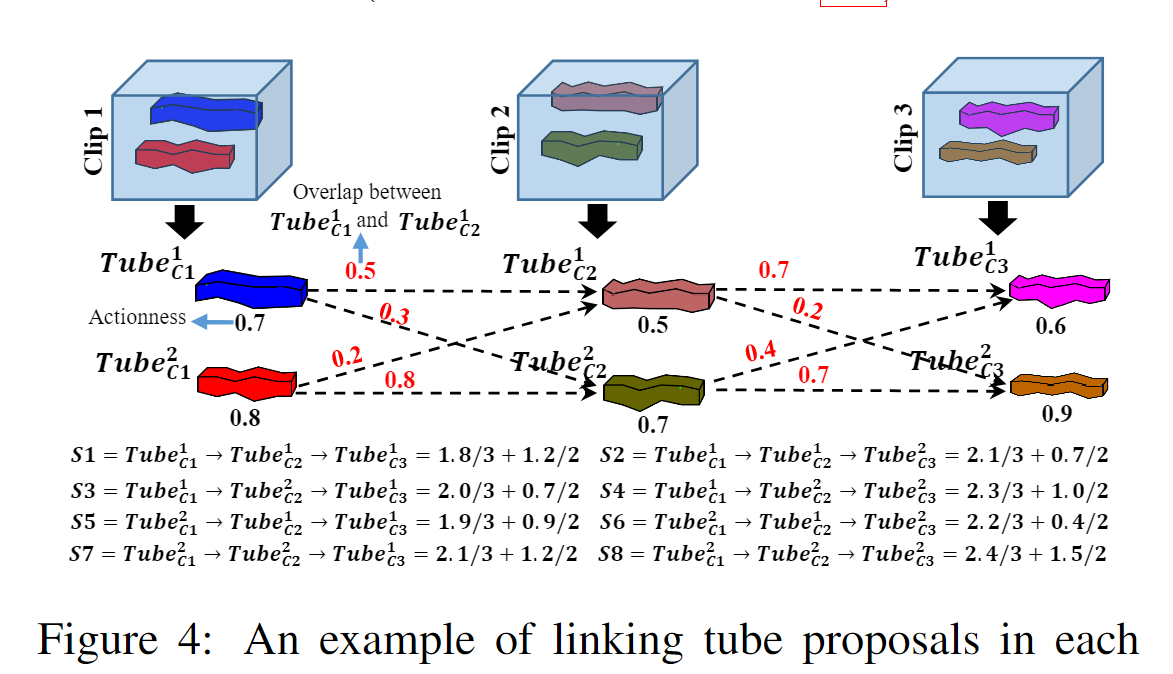
来自不同clip的每个tube proposal可以link在管提案序列tube proposal sequence ((即视频管提案)中以进行动作检测。然而,并非所有管建议的组合都能正确捕获完整的动作。例如,一个clip中的tube proposal可能包含动作,而下一clip中的tube proposal可能仅捕获背景。直观上,所选tube proposal中的内容应捕获动作,并且任何两个连续剪辑中连接的管建议应具有较大的时间重叠。 因此,在链接管提案时要考虑两个标准:行动性和重叠分数。然后为每个视频提案分配一个分数,定义如下:
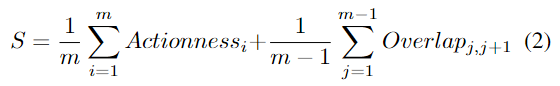
其中 Actionness_i 表示来自第 i 个clip的管提案的行动得分,Overlap_j,_j+1 测量分别来自第 j 和第 (j + 1) 个clip的链接的两个提案之间的重叠,m 是视频剪辑总数。如图 3 所示,来自 conv5 特征管的每个边界框提案都与一个动作分数相关联。行动分数由相应的管提案继承。
两个管提案之间的重叠是根据第 j 个管提案的最后一帧和第 (j+1) 个管提案的第一帧的 IoU(并交交集)来计算的。 S 的第一项计算视频提案中所有管提案的平均动作得分,第二项计算每两个连续视频剪辑中管提案之间的平均重叠度。因此,我们确保链接的管提案可以封装操作,同时具有时间一致性。图 4 展示了连接管提案和计算分数的示例。我们选择视频中分数最高的多个链接提案序列。