目录
第一题
题目来源
题目内容
解决方法
方法一:动态规划
方法二:栈
方法三:双指针
第二题
题目来源
题目内容
解决方法
方法一:二分查找
方法二:线性扫描
方法三:递归
第三题
题目来源
题目内容
解决方法
方法一:二分查找
方法二:线性扫描
方法三:双指针
第一题
题目来源
32. 最长有效括号 - 力扣(LeetCode)
题目内容

解决方法
方法一:动态规划
- 创建一个长度为
n的数组dp,用于保存以当前字符结尾的最长有效括号子串的长度。 - 初始化
dp数组的所有元素为 0。 - 遍历字符串
s的每个字符:- 如果当前字符是
(,则直接跳过。 - 如果当前字符是
),则判断前一个字符是否是(:- 如果前一个字符是
(,则更新dp[i] = dp[i-2] + 2,表示以当前字符结尾的最长有效括号子串长度为前一个字符结尾的最长有效括号子串长度加上当前的两个括号。 - 如果前一个字符是
),则判断前一个字符结尾的最长有效括号子串之前的字符是否是(,即判断i-dp[i-1]-1位置的字符是否是(:- 如果是
(,则更新dp[i] = dp[i-1] + dp[i-dp[i-1]-2] + 2,表示以当前字符结尾的最长有效括号子串长度为前一个字符结尾的最长有效括号子串长度加上前一个字符结尾的最长有效括号子串之前的最长有效括号子串长度加上当前的两个括号。
- 如果是
- 如果前一个字符是
- 如果当前字符是
- 遍历完整个字符串后,找出
dp数组中的最大值,即为最长有效括号子串的长度。
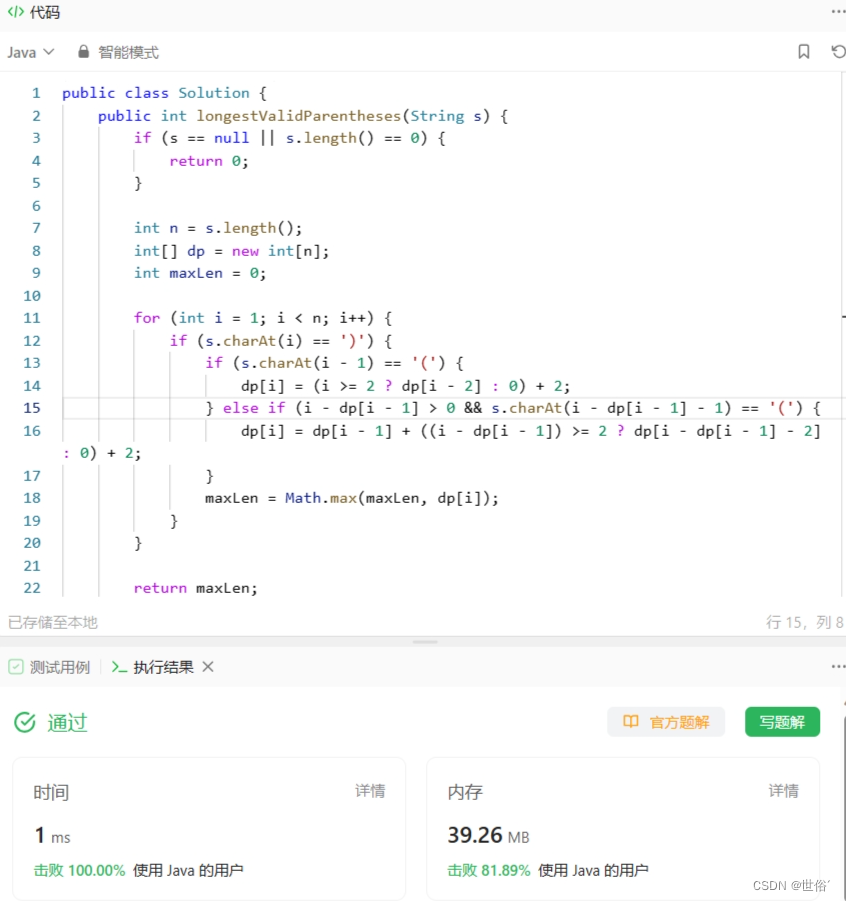
public class Solution {public int longestValidParentheses(String s) {if (s == null || s.length() == 0) {return 0;}int n = s.length();int[] dp = new int[n];int maxLen = 0;for (int i = 1; i < n; i++) {if (s.charAt(i) == ')') {if (s.charAt(i - 1) == '(') {dp[i] = (i >= 2 ? dp[i - 2] : 0) + 2;} else if (i - dp[i - 1] > 0 && s.charAt(i - dp[i - 1] - 1) == '(') {dp[i] = dp[i - 1] + ((i - dp[i - 1]) >= 2 ? dp[i - dp[i - 1] - 2] : 0) + 2;}maxLen = Math.max(maxLen, dp[i]);}}return maxLen;}
}
复杂度分析:
时间复杂度:
- 遍历字符串
s的每个字符需要 O(n) 的时间。 - 在每个字符上,我们都进行了常数次的比较和更新操作。
- 因此,总体上,时间复杂度为 O(n)。
空间复杂度:
- 我们使用了一个长度为
n的数组dp来保存以当前字符结尾的最长有效括号子串的长度。 - 因此,空间复杂度为 O(n)。
综合起来,该解法的时间复杂度为 O(n),空间复杂度为 O(n)。
注意:对于这个特定的问题,在给定的限制条件下(0 <= s.length <= 3 * 10^4),这个解法是高效且可行的。
LeetCode运行结果:
方法二:栈
该方法的思路如下:
- 首先,我们使用一个栈来保存括号的索引位置。
- 初始化栈,将一个特殊的值
-1放入栈中。 - 遍历字符串
s的每个字符:- 如果遇到左括号
(,将其索引位置压入栈中。 - 如果遇到右括号
),弹出栈顶元素,表示当前右括号匹配了一个左括号。- 如果栈为空,将当前右括号的索引位置压入栈中,作为一个新的起点。
- 如果栈不为空,计算当前有效括号子串的长度,更新最大长度。
- 如果遇到左括号
- 最后,返回最大长度即可。
import java.util.Stack;public class Solution {public int longestValidParentheses(String s) {if (s == null || s.length() == 0) {return 0;}int maxLen = 0;Stack<Integer> stack = new Stack<>();stack.push(-1);for (int i = 0; i < s.length(); i++) {char c = s.charAt(i);if (c == '(') {stack.push(i);} else {stack.pop();if (stack.isEmpty()) {stack.push(i);} else {maxLen = Math.max(maxLen, i - stack.peek());}}}return maxLen;}
}
复杂度分析:
时间复杂度:
- 遍历字符串 s 的每个字符需要 O(n) 的时间。
- 在每个字符上,我们进行了常数次的栈操作(压栈和弹栈)。
- 因此,总体上,时间复杂度为 O(n)。
空间复杂度:
- 我们使用了一个栈来保存括号的索引位置。
- 在最坏情况下,当所有字符都是左括号时,栈的大小为 n。
- 因此,空间复杂度为 O(n)。
综合起来,该方法的时间复杂度为 O(n),空间复杂度为 O(n)。
LeetCode运行结果:

方法三:双指针
除了动态规划和栈,还有一种双指针的方法来解决最长有效括号问题。
这种方法的思路如下:
- 从左到右遍历字符串,统计左右括号的数量。
- 如果左右括号数量相等,则更新最大长度。
- 如果右括号数量大于左括号数量,则重置左右括号数量为0。
- 然后从右到左再进行一次相同的操作。
public class Solution {public int longestValidParentheses(String s) {if (s == null || s.length() == 0) {return 0;}int left = 0; // 左括号数量int right = 0; // 右括号数量int maxLen = 0; // 最大长度// 从左到右遍历for (int i = 0; i < s.length(); i++) {char c = s.charAt(i);if (c == '(') {left++;} else {right++;}// 如果左括号数量等于右括号数量,则计算当前有效括号子串的长度if (left == right) {maxLen = Math.max(maxLen, right * 2);} else if (right > left) { // 右括号数量大于左括号数量,重置左右括号数量为0left = 0;right = 0;}}left = 0;right = 0;// 从右到左遍历for (int i = s.length() - 1; i >= 0; i--) {char c = s.charAt(i);if (c == ')') {right++;} else {left++;}// 如果左括号数量等于右括号数量,则计算当前有效括号子串的长度if (left == right) {maxLen = Math.max(maxLen, left * 2);} else if (left > right) { // 左括号数量大于右括号数量,重置左右括号数量为0left = 0;right = 0;}}return maxLen;}
}
复杂度分析:
时间复杂度:
- 遍历字符串 s 的每个字符需要 O(n) 的时间。
- 在第一次从左到右遍历中,我们进行了常数次的操作,不会产生额外的时间复杂度。
- 在第二次从右到左遍历中,同样也进行了常数次的操作。
- 因此,总体上,时间复杂度为 O(n)。
空间复杂度:
- 我们只使用了常数个变量来保存左右括号的数量和最大长度,没有使用额外的数据结构。
- 因此,空间复杂度为 O(1)。
综合起来,该方法的时间复杂度为 O(n),空间复杂度为 O(1)。
LeetCode运行结果:
第二题
题目来源
33. 搜索旋转排序数组 - 力扣(LeetCode)
题目内容

解决方法
方法一:二分查找
使用二分查找的思想,通过判断左右半边哪一边是有序的来决定向哪边继续查找。具体步骤如下:
- 初始化左指针
left为数组的第一个元素的索引,右指针right为数组最后一个元素的索引。 - 在每次循环中,计算中间元素的索引
mid。 - 如果中间元素等于目标值,则返回
mid。 - 判断左半边是否有序(即
nums[left] <= nums[mid]):- 如果目标值在左半边的有序范围内,则将右指针
right移动到mid - 1,继续在左半边查找。 - 否则,将左指针
left移动到mid + 1,继续在右半边查找。
- 如果目标值在左半边的有序范围内,则将右指针
- 如果左半边不是有序的,则右半边一定是有序的。判断目标值是否在右半边的有序范围内:
- 如果是,则将左指针
left移动到mid + 1,继续在右半边查找。 - 否则,将右指针
right移动到mid - 1,继续在左半边查找。
- 如果是,则将左指针
- 如果循环结束仍未找到目标值,则返回 -1。
public class Solution {public int search(int[] nums, int target) {if (nums == null || nums.length == 0) {return -1;}int left = 0;int right = nums.length - 1;while (left <= right) {int mid = left + (right - left) / 2;if (nums[mid] == target) {return mid;}if (nums[left] <= nums[mid]) { // 左半边有序if (target >= nums[left] && target < nums[mid]) {right = mid - 1;} else {left = mid + 1;}} else { // 右半边有序if (target > nums[mid] && target <= nums[right]) {left = mid + 1;} else {right = mid - 1;}}}return -1;}
}
复杂度分析:
- 该算法的时间复杂度为O(log n),其中n是数组的长度。在每次循环中,都将搜索范围缩小一半,所以总共最多需要进行log n次循环。因此,算法的时间复杂度为O(log n)。
- 空间复杂度为O(1),因为算法只使用了有限的额外空间来存储指针和常量。
总结起来,该算法具有较低的时间复杂度和空间复杂度,能够高效地解决搜索旋转排序数组的问题。
LeetCode运行结果:

方法二:线性扫描
除了二分查找的方法,还可以使用线性扫描的方法来搜索旋转排序数组。
该算法从数组的第一个元素开始,依次遍历数组中的每个元素,如果找到目标值,则返回其索引;如果遍历结束仍未找到目标值,则返回-1。
public class Solution {public int search(int[] nums, int target) {if (nums == null || nums.length == 0) {return -1;}for (int i = 0; i < nums.length; i++) {if (nums[i] == target) {return i;}}return -1;}
}
复杂度分析:
- 线性扫描算法的时间复杂度为O(n),其中n是数组的长度。算法需要遍历整个数组来查找目标值,因此最坏情况下需要执行n次比较操作。
- 空间复杂度为O(1),因为算法没有使用额外的空间,只需常数级别的额外空间。
相对于二分查找算法的O(log n)时间复杂度,线性扫描算法的时间复杂度较高。但在某些特定场景或者输入规模较小的情况下,线性扫描算法也可以快速解决问题。
综上所述,线性扫描算法适用于简单的问题或者规模较小的数据集,但在更大规模的数据集上,二分查找算法通常更具优势。
LeetCode运行结果:

方法三:递归
除了二分查找和线性扫描的方法,还可以使用递归的方法来搜索旋转排序数组。
该算法与二分查找算法类似,也是通过判断左右半边哪一边是有序的来决定向哪边继续查找。不同之处在于,该算法使用递归的方式实现,将数组的搜索范围不断缩小。
- 算法首先检查数组是否为空或者长度为0,如果是,则返回-1。然后调用递归函数 search 进行搜索,传入参数 nums 数组、目标值 target、搜索范围的左右端点索引 left 和 right。
- 在递归函数中,首先判断搜索范围是否合法,如果不合法,则返回-1。然后计算中间元素索引 mid。如果中间元素等于目标值,则返回 mid。
- 接着判断左半边是否有序(即 nums[left] <= nums[mid])。如果是,则判断目标值是否在左半边的有序范围内。如果是,则继续在左半边递归查找;否则,在右半边递归查找。
- 如果左半边不是有序的,则右半边一定是有序的。判断目标值是否在右半边的有序范围内。如果是,则在右半边递归查找;否则,在左半边递归查找。
- 最后,如果循环结束仍未找到目标值,则返回-1。
public class Solution {public int search(int[] nums, int target) {if (nums == null || nums.length == 0) {return -1;}return search(nums, target, 0, nums.length - 1);}private int search(int[] nums, int target, int left, int right) {if (left > right) {return -1;}int mid = left + (right - left) / 2;if (nums[mid] == target) {return mid;}if (nums[left] <= nums[mid]) { // 左半边有序if (target >= nums[left] && target < nums[mid]) {return search(nums, target, left, mid - 1);} else {return search(nums, target, mid + 1, right);}} else { // 右半边有序if (target > nums[mid] && target <= nums[right]) {return search(nums, target, mid + 1, right);} else {return search(nums, target, left, mid - 1);}}}
}
复杂度分析:
时间复杂度:
- 最好情况下,数组是完全有序的,每次都能通过比较找到目标值,时间复杂度为 O(log n)。
- 最坏情况下,每次都只能排除一个元素,需要遍历整个数组,时间复杂度为 O(n)。
- 平均情况下,假设数组中大致一半是有序的,一半是无序的,时间复杂度介于 O(log n) 和 O(n) 之间。
空间复杂度:
- 每次递归调用会在栈上保存一些临时变量和返回地址,最大递归深度为 log n,因此空间复杂度为 O(log n)。
综合考虑,递归搜索旋转排序数组的算法在最坏情况下的时间复杂度为 O(n),空间复杂度为 O(log n)。但如果数组是近似有序的或者目标值位于有序部分内,时间复杂度可以接近 O(log n),效率较高。
需要注意的是,递归算法和二分查找算法类似,但由于需要额外的栈空间,因此可能会更慢。在处理超大规模数据时,可能会导致栈溢出问题。
LeetCode运行结果:

第三题
题目来源
34. 在排序数组中查找元素的第一个和最后一个位置 - 力扣(LeetCode)
题目内容

解决方法
方法一:二分查找
- 首先,我们定义一个长度为2的整数数组 result,并初始化为 {-1, -1}。这个数组表示目标值的开始位置和结束位置。
- 然后,我们使用两个辅助函数 findLeft 和 findRight 来分别查找目标值的开始位置和结束位置。
- 在 findLeft 函数中,我们使用二分查找来搜索目标值的开始位置。初始时,左边界 left 指向数组的第一个元素,右边界 right 指向数组的最后一个元素。在每次循环中,计算中间元素索引 mid,并将它与目标值进行比较。如果中间元素大于或等于目标值,则将右边界 right 缩小为 mid;否则,将左边界 left 扩大为 mid + 1。最后,返回 left 的值作为目标值的开始位置。如果目标值不存在,则返回 -1。
- 在 findRight 函数中,我们同样使用二分查找来搜索目标值的结束位置。不过这次的二分查找稍有不同。初始时,左边界 left 指向数组的第一个元素,右边界 right 指向数组的最后一个元素。在每次循环中,计算中间元素索引 mid,并将它与目标值进行比较。如果中间元素小于或等于目标值,则将左边界 left 扩大为 mid;否则,将右边界 right 缩小为 mid - 1。最后,返回 left 的值作为目标值的结束位置。如果目标值不存在,则返回 -1。
- 最后,在主函数 searchRange 中,我们首先判断特殊情况,即数组为空或长度为0的情况,直接返回初始化好的 result 数组。
- 然后,我们通过调用辅助函数 findLeft 和 findRight 分别得到目标值的开始位置和结束位置,并将它们存储在 result 数组中。
- 最后,返回 result 数组作为结果。
class Solution {public int[] searchRange(int[] nums, int target) {int[] result = {-1, -1};if (nums == null || nums.length == 0) {return result;}int leftIndex = findLeft(nums, target);int rightIndex = findRight(nums, target);if (leftIndex <= rightIndex) {result[0] = leftIndex;result[1] = rightIndex;}return result;}private int findLeft(int[] nums, int target) {int left = 0;int right = nums.length - 1;while (left < right) {int mid = left + (right - left) / 2;if (nums[mid] >= target) {right = mid;} else {left = mid + 1;}}return nums[left] == target ? left : -1;}private int findRight(int[] nums, int target) {int left = 0;int right = nums.length - 1;while (left < right) {int mid = left + (right - left) / 2 + 1;if (nums[mid] <= target) {left = mid;} else {right = mid - 1;}}return nums[left] == target ? left : -1;}
}
复杂度分析:
- 时间复杂度:O(log n)。每次迭代都将搜索空间减半,因此时间复杂度为对数级别。
- 空间复杂度:O(1)。仅使用了有限的额外空间来存储几个变量。
LeetCode运行结果:

方法二:线性扫描
除了二分查找,还可以使用线性扫描的方法来搜索排序数组中目标值的开始位置和结束位置。
- 我们首先遍历整个数组来查找目标值的开始位置。如果找到目标值,我们将其索引存储在 result[0] 中并立即退出循环。如果没有找到目标值,则 result[0] 保持为初始值 -1。
- 接着,我们再从数组的末尾开始向前遍历,查找目标值的结束位置。如果找到目标值,我们将其索引存储在 result[1] 中并立即退出循环。如果没有找到目标值,则 result[1] 保持为初始值 -1。
- 最后,我们返回存储了目标值开始位置和结束位置的 result 数组。
class Solution {public int[] searchRange(int[] nums, int target) {int[] result = {-1, -1};if (nums == null || nums.length == 0) {return result;}for (int i = 0; i < nums.length; i++) {if (nums[i] == target) {result[0] = i;break;}}if (result[0] != -1) {for (int j = nums.length - 1; j >= 0; j--) {if (nums[j] == target) {result[1] = j;break;}}}return result;}
}
复杂度分析:
- 时间复杂度:O(n)。需要遍历整个数组,其中 n 是数组的长度。
- 空间复杂度:O(1)。仅使用了有限的额外空间来存储几个变量。
因为二分查找的时间复杂度为 log n,而线性扫描的时间复杂度为 n,所以在数组较大且已排序的情况下,二分查找的性能更好。它减少了搜索空间的大小,使得平均查找次数更低。然而,在数组较小或未排序的情况下,线性扫描是一种简单有效的方法。
LeetCode运行结果:

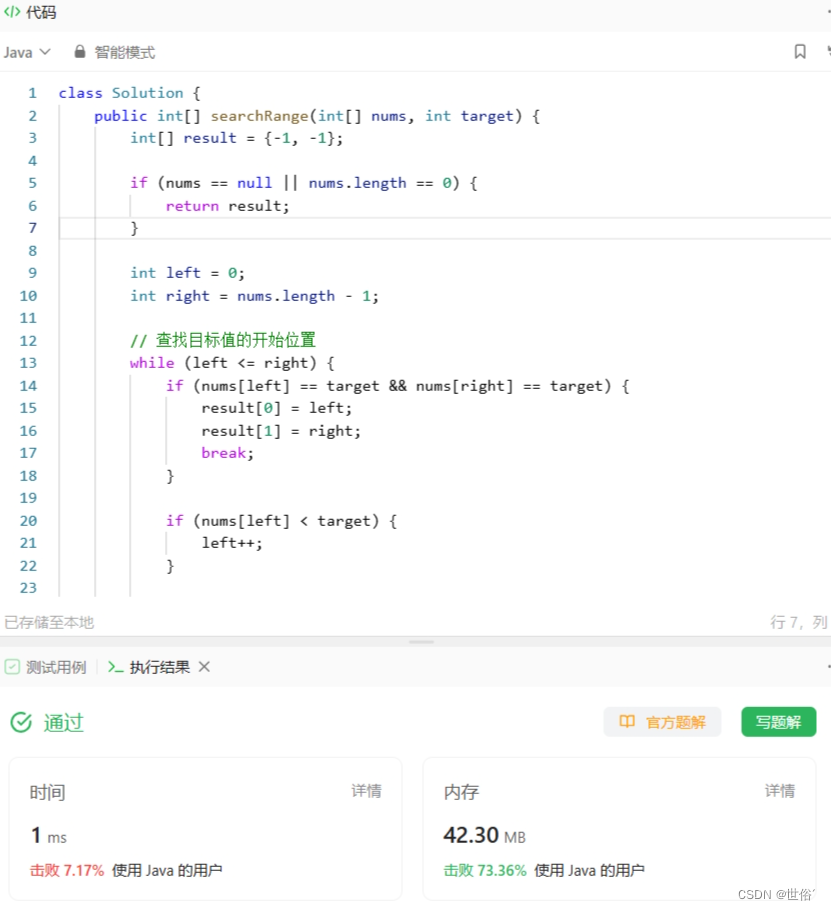
方法三:双指针
除了二分查找和线性扫描,还有一种常用的方法是双指针法。这种方法适用于有序数组或部分有序数组,并且可以在 O(n) 的时间复杂度内找到目标值的开始位置和结束位置。
class Solution {public int[] searchRange(int[] nums, int target) {int[] result = {-1, -1};if (nums == null || nums.length == 0) {return result;}int left = 0;int right = nums.length - 1;// 查找目标值的开始位置while (left <= right) {if (nums[left] == target && nums[right] == target) {result[0] = left;result[1] = right;break;}if (nums[left] < target) {left++;}if (nums[right] > target) {right--;}}return result;}
}
在上述代码中,我们使用两个指针 left 和 right 来标记搜索区间。通过不断更新指针的位置,我们可以确定目标值的开始位置和结束位置。
具体步骤如下:
- 初始化指针 left 和 right 分别指向数组的首尾元素。
- 当 left 指向的元素小于目标值时,将 left 向右移动一位。
- 当 right 指向的元素大于目标值时,将 right 向左移动一位。
- 如果 left 和 right 指向的元素都等于目标值,则找到了目标值的开始位置和结束位置。将结果存储在 result 数组中,并退出循环。
- 如果找不到目标值,则返回初始值为 -1 的 result 数组。
复杂度分析:
- 使用双指针法的时间复杂度是 O(n),其中 n 是数组的长度。在最坏的情况下,即目标值不在数组中或者目标值在数组中出现了 n 次,我们需要将指针 left 和 right 分别移动到数组的两端。因此,最多需要遍历整个数组一次,时间复杂度为 O(n)。
- 空间复杂度是 O(1),因为我们只需要使用有限的额外变量来记录指针的位置和存储结果数组。
需要注意的是,双指针法适用于有序数组或部分有序数组,如果数组无序,则双指针法无法正确找到目标值的开始位置和结束位置。
LeetCode运行结果: