自动爬取网页数据
正常情况下是我们使用浏览器输入指定url,对服务器发送访问请求,服务器返回请求信息,浏览器进行解析为我们看到的界面,爬虫就是使用python脚本取代正常的浏览器,获取相应服务器的返回请求信息,并配合python强大的库进行解析分析,能够快速高效地帮助我们进行大数据分析。
不需要登录即可返回请求
以爬取虎牙交友频道每个直播封面图片为例
-
请求服务器
url = 'https://www.huya.com/g/4079'result = requests.get(url=url).text其实就是与cmd命令的 curl url一样,他们两个的返回是一样的,都是返回请求网页的源代码
curl url的返回太长,可以直接保存到文件中,方便比较
curlhttps://www.huya.com/g/4079> C:\Users\72403\Desktop\py\cmdRes.txt -
在网站源码内筛选我们需要的数据,这里用到xpath
我们可以在网站要爬取的内容右键选检查,就会看到对应内容的标签等信息
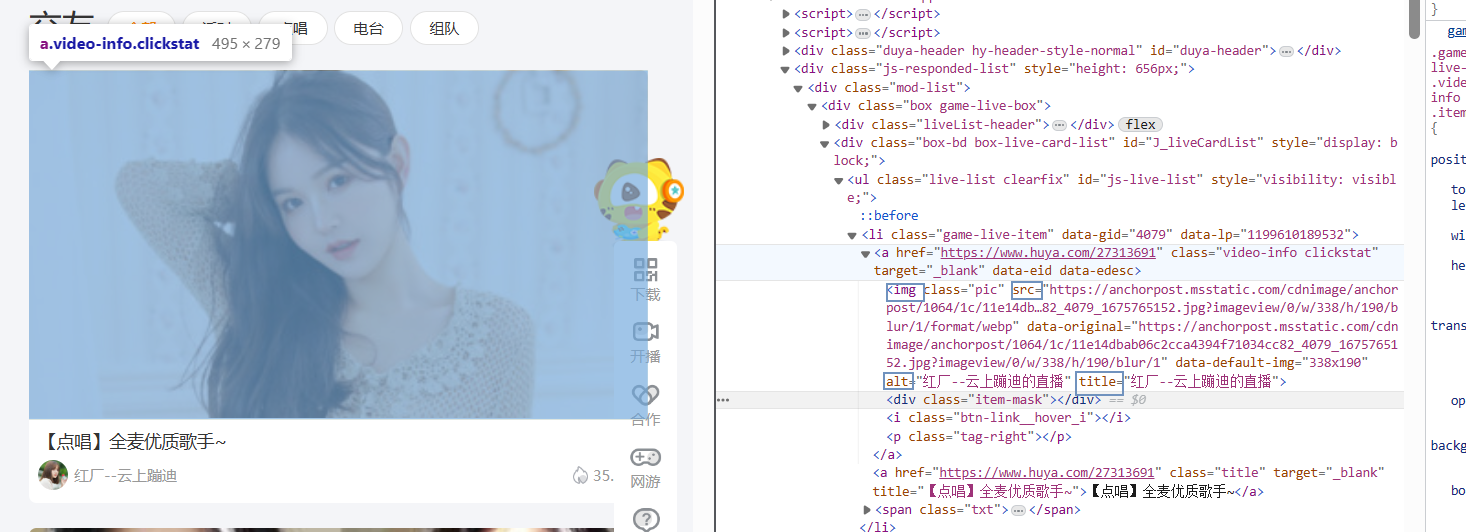
data = etree.HTML(result)imgs = data.xpath('//img[@class="pic"]') -
保存数据
for img in imgs:imgUrl = img.xpath('./@data-original')[0]imgName = img.xpath('./@alt')[0]request.urlretrieve(imgUrl, r'C:/Users/72403/Pictures/video/huya/' + imgName + '.jpg')
都被爬到了本地:

需要登录才可返回请求
有的网站访客请求不能成功返回请求,这里以小b站为例
其他的都是一样的,就是要加上一个cookie,来告诉服务端我不是访客,我是你们尊贵的vip用户,快给我返回请求
获取自己已经登录账户的cookie
-
打开小b站,登录
-
按下F12进入调试窗口
-
选中网络
-
按下
alt+r刷新界面 -
滑动到界面的最上方,找到www.bilibili.com这条
cookie就在图下方所示位置
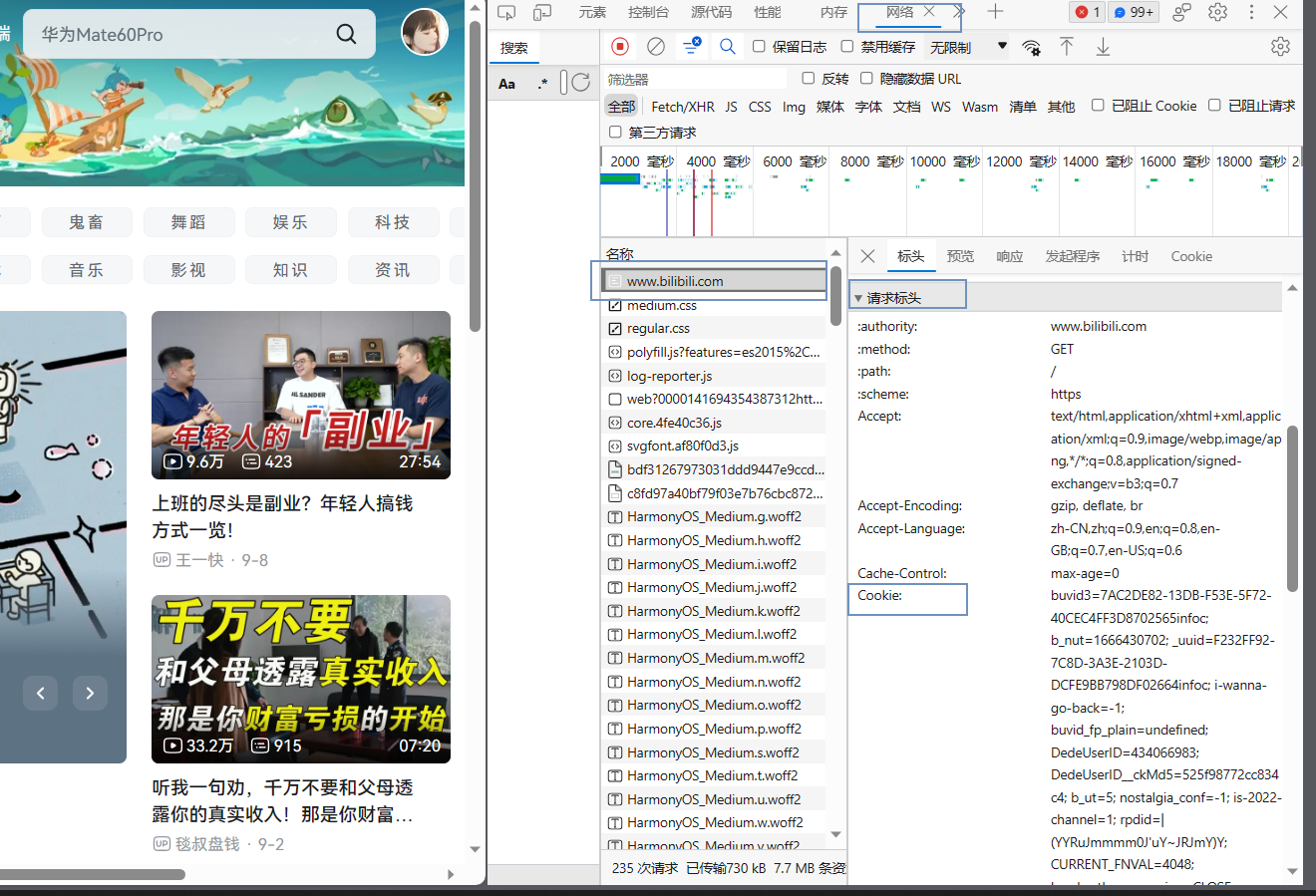
请求的时候请求头加上cookie
headers = {# 假装自己是浏览器'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/73.0.3683.75 Chrome/73.0.3683.75 Safari/537.36',# 把你刚刚拿到的Cookie塞进来'Cookie':'把上一步得到的Cookie复制到此处'
}
session = requests.Session()
result = session.get('https://www.bilibili.com', headers=headers).text
完整代码
headers = {# 假装自己是浏览器'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/73.0.3683.75 Chrome/73.0.3683.75 Safari/537.36',# 把你刚刚拿到的Cookie塞进来'Cookie':'把上一步得到的Cookie复制到此处'
}
if __name__ == '__main__':url = 'https://www.bilibili.com'session = requests.Session()result = session.get('https://www.bilibili.com', headers=headers).text#result = requests.get(url=url).textdata = etree.HTML(result)imgs = data.xpath('//img')for img in imgs:imgUrl = img.xpath('./@src')[0]imgName = img.xpath('./@alt')[0]print(imgName+":"+imgUrl)# 会出现有的图片路径不带https,加下面的判断if imgUrl.find("https://") !=-1:request.urlretrieve(imgUrl, r'C:/Users/72403/Pictures/video/bilibili/' + imgName + '.jpg')else:request.urlretrieve("https:"+imgUrl, r'C:/Users/72403/Pictures/video/bilibili/' + imgName + '.jpg')print("{%s}下载完毕!" % imgName)