保姆级 Keras 实现 Faster R-CNN 十三 训练
- 一. 将 Faster R-CNN 包装成一个类
- 二. 修改模型结构
- 1. 修改 input_reader 函数
- 2. 增加 RoiLabelLayer 层
- 三. 损失函数
- 1. 自定义损失函数
- 2. 自定义精度评价函数
- 四. 模型编译
- 五. 模型训练
- 六. 预训练模型
- 七. 保存模型与参数
- 八. 代码下载
上一篇 文章中我们实现了整个 Faster R-CNN 的前向计算过程, 现在到了可能是你最想看的训练部分了
注意, 接下来如果不点赞的话, 可能会看不懂
一. 将 Faster R-CNN 包装成一个类
之前的文章为了方便理解与讲解都是一个函数一个函数的 “散装” 的方式完成的, 为了后面操作方便和维护, 将这些散装的变量或函数放到类里面去. 定义一个 FasterRcnn 类如下
# 定义 FasterRcnn 类
class FasterRcnn:def __init__(self,base_net = None, # 特征提取网络short_size = 300, # 图像缩放最短边度长anchor_size = (64, 128, 256), # anchor 三种尺寸anchor_ratio = (0.5, 1.0, 2.0), # anchor 三种比例feature_stride = 16, # 特征图相对于原始输入图像的缩小的倍数train_num = 256, # 每一张图中参加训练的 anchor box 的数量iou_thres = (0.3, 0.7), # 正负样本阈值 (负样本 0.3, 正样本 0.7)nms_thres = 0.7, # 做 NMS 是的阈值categories = None, # 类别列表dense_cells = 2048, # 分类与回归之前全连接层的神经元个数data_path = "data_set", # 存放图像和标签文件的路径, 里面有图像和标签文件log_path = None, # 日志目录**kwargs):self.base_net = base_netself.short_size = short_sizeself.anchor_size = anchor_sizeself.anchor_ratio = anchor_ratioself.feature_stride = feature_strideself.train_num = train_numself.iou_thres = iou_thresself.nms_thres = nms_thresself.categories = categoriesself.dense_cells = dense_cellsself.data_path = data_pathself.log_path = log_pathself.model = None # Faster R-CNN 模型self.train_set = None # 由 get_data_set 函数划分的训练集self.valid_set = None # 由 get_data_set 函数划分的验证集self.test_set = None # 由 get_data_set 函数划分的测试集# 9 个基础 anchor boxself.base_anchors = self.create_base_anchors()self.POS_VAL = 1 # 正样本self.NEG_VAL = 0 # 负样本self.NEUTRAL = -1 # 其他不参与计算 loss 的样本self.REG_NO_TRAIN = 8.0 # 不参与训练的修正标签值# 因为修正值一般不会大于 1# 所以可以用小于 8 的值来判断是否参与训练# 因为 K 和 ANCHOR_DIMS 很多地方都要用到, 所以这里就当成一个常量来用self.K = len(self.base_anchors) # k 个基础 anchor box self.ANCHOR_DIMS = 4 # 一个 anchor box 需要 4 个坐标self.NUM_CLS = len(self.categories) # 类别数量, 包括背景if not osp.exists(log_path):os.mkdir(log_path)#----------------------------------------------------------------------------# 取得图像和标注文件路径# split_rate: 这些文件中用于训练, 验证, 测试所占的比例# 如果为 None, 则不区分, 直接返回全部# 如果只写一个小数, 如 0.8, 则表示 80% 为训练集, 20% 为验证集, 没有测试集# 如果是一个 tuple 或 list, 只有一个元素的话, 同上面的一个小数的情况# shuffle_enable: 是否要打乱顺序def get_data_set(self, split_rate = (0.8, 0.1, 0.1), shuffle_enable = True):pass#----------------------------------------------------------------------------# 图像缩放函数# image: 原始图像# interpolation: 插值方式# 返回缩放后的图像和缩放比例def new_size_image(self, image, interpolation = cv.INTER_LINEAR):pass#----------------------------------------------------------------------------# 生成基础的 k 个 anchor boxdef create_base_anchors(self):pass#----------------------------------------------------------------------------# 显示基础 anchor boxdef show_base_anchors(self):pass#----------------------------------------------------------------------------# 按特征图大小生成训练的 anchor box# feature_size: 特征图尺寸def create_train_anchors(self, feature_size):pass#----------------------------------------------------------------------------# 测试 create_train_anchors 并画到图像上# data_set: 数据集# image_index: 显示图像的索引序号def show_train_anchors(self, data_set = None, image_index = 0):pass#----------------------------------------------------------------------------# 计算 IoU# anchor_box 坐标格式为 (x1, y1, x2, y2)def get_iou(self, a1, a2):pass#----------------------------------------------------------------------------# 从 xml 或 json 文件中读出 ground_truth# label_path: 图标与标签路径# file_type: 标注文件类型# scale: 缩放系数, 因为输入的图像都要把最短边变成指定值, 所以需要缩放# 返回 ground_truth 坐标与类别def get_ground_truth(self, label_path, file_type, scale = 1.0):pass#----------------------------------------------------------------------------# 测试 get_ground_truth# data_set: 数据集# image_index: 显示图像的索引序号def show_ground_truth(self, data_set = None, image_index = 0):pass#----------------------------------------------------------------------------#拆分 ground_truth# ground_truth: 从标签文件中读出的标签信息, 由 get_ground_truth 返回# 返回拆分后的类别列表和坐标列表def split_ground_truth(self, ground_truth):pass#----------------------------------------------------------------------------# 为每一个 anchor box 打类别标签# img_shape: 图像形状# anchors: create_train_anchors 生成的 anchor box# ground_truth: get_ground_truth 从标签文件中读出来的标签# neg_thres: 负样本阈值# pos_thres: 正样本阈值# train_num: 每一张图中参加训练的样本数量# 返回每一个 anchor box 的标签类型 1: 正, 0: 负: -1: 中立# 代码的实现逻辑见 https://blog.csdn.net/yx123919804/article/details/120651815def get_rpn_cls_label(self, img_shape, anchors, ground_truth,neg_thres = 0.3, pos_thres = 0.7, train_num = 256):pass#----------------------------------------------------------------------------# 测试 get_rpn_cls_label# data_set: 数据集# image_index: 显示图像的索引序号# show_num: 最多显示的 anchor box 数量, 因为太多会把图画满了def show_rpn_cls_label(self, data_set = None, image_index = 0, show_num = 32):pass#----------------------------------------------------------------------------# 生成 rpn anchor box 修正量标签# 只有类别为目标的 anchor box 才参数修正# anchors: 由 create_train_anchors 函数生成的 anchor_box# cls_labels: get_rpn_cls_label 生成的类别标签列表# gt_boxes: get_rpn_cls_label 返回的对应的 ground_truth# 返回每一个 anchor box 修正量 Δx, Δy, Δw, Δhdef get_rpn_reg_label(self, anchors, cls_labels, gt_boxes):pass#----------------------------------------------------------------------------# 测试 get_rpn_reg_label 函数# data_set: 数据集# image_index: 显示图像的索引序号def show_rpn_reg_label(self, data_set = None, image_index = 0):pass#----------------------------------------------------------------------------# 数据增强函数, 包括左右, 上下, 左右上翻转# data_pair: data_set_path 返回的数据元素# train_num: 一次参数训练的 anchor 的数量# 返回增强后的图像和标签def data_augment(self, data_pair, train_num = 256):pass#----------------------------------------------------------------------------# 测试 data_augment# data_set: 数据集# image_index: 显示图像的索引序号# show_num: 最多显示的 anchor box 数量, 因为太多会把图画满了def show_data_augment(self, data_set = None, image_index = 0, show_num = 32):pass#----------------------------------------------------------------------------# 网络输入数据 generator# data_set: 训练或测试数据列表# batch_size: 一次输入训练的图像数量# train_num: 参加训练的 anchor 的数量# augment_fun: 数据增强函数# train_mode: True: 训练模式, False: 测试模式# shuffle_enable: 打乱标记# 返回图像和标签def input_reader(self, data_set, batch_size = 1, train_num = 256,augment_fun = None, train_mode = True, shuffle_enable = True):pass#----------------------------------------------------------------------------# 测试 input_reader# reader: 生成器# show_cols: 显示列数def show_next_batch(self, reader, show_cols = 4):pass#----------------------------------------------------------------------------# RPN 网络# feature: base_net 输出def rpn_net(self, feature):pass#----------------------------------------------------------------------------# Fast R-CNN 网络# pooled_rois: RoiPooling 输出# cells: 全连接网络的神经元的数量# num_classes: 类别数量def fast_rcnn(self, pooled_rois, cells, num_classes):pass#----------------------------------------------------------------------------# 创建训练模型def create_train_model(self, summary = True):pass#----------------------------------------------------------------------------# RPN 网络分类损失函数def rpn_cls_loss(self, y_true, y_pred):pass#----------------------------------------------------------------------------# RPN 网络分类精度评价函数def rpn_cls_acc(self, y_true, y_pred):pass#----------------------------------------------------------------------------# RPN 网络回归损失失函数def rpn_reg_loss(self, y_true, y_pred):pass#----------------------------------------------------------------------------# RPN 网络回归精度评价函数def rpn_reg_acc(self, y_true, y_pred):pass#----------------------------------------------------------------------------# RCNN 网络分类损失函数def rcnn_cls_loss(self, y_true, y_pred):pass#----------------------------------------------------------------------------# RCNN 网络分类精度评价函数def rcnn_cls_acc(self, y_true, y_pred):pass#----------------------------------------------------------------------------# RCNN 网络回归损失失函数def rcnn_reg_loss(self, y_true, y_pred):pass#----------------------------------------------------------------------------# RCNN 网络回归精度评价函数def rcnn_reg_acc(self, y_true, y_pred):pass#----------------------------------------------------------------------------# 编译模型def compile(self, optimizer = keras.optimizers.Adam(learning_rate = 1e-4)):pass#----------------------------------------------------------------------------# 训练模型# augment_fun: 数据增强函数# augmented_num: 一张图像增强后的数量, 默认只有翻转, 所以是 4# trained_weight: 加载序训练模型路径def train(self, epochs = 128, batch_size = 4,augment_fun = None, augmented_num = 4, trained_weights = None): pass#----------------------------------------------------------------------------# 保存模型与参数# file_name: 保存的文件名称# save_model: 是否要保存模型# save_weight: 是否要保存参数def save(self, file_name, save_model = True, save_weight = True):pass
类中的成员函数并没有具体的定义, 但并不影响本文的理解与阅读. 只需要把以前散装的函数修改一下参数放到类里, 再将相关的全局变量换成类成员变量就可以了, 完整的代码我会传上来供大家下载
要仔细看的是类的初始化函数中的一些变量定义, 这些变量可以修改成你喜欢的值就好, 比如把最短边改一下. anchor 的形状数量之类的改一下
我们要达到的效果是, 如果想训练的话, 定义一个 FasterRcnn 类的实例, 再调用 train 函数就可以, 像下面这样
# 定义类实例
faster_rcnn = FasterRcnn(base_net = base_net, categories = CATEGORIES)
# 训练模型
faster_rcnn.train(epochs = 64, batch_size = 4, "再加其他一些不是必须的参数..")
就是这样简单的代码, 听懂的掌声!
二. 修改模型结构
上一篇 文章中定义的模型结构如下
# 组合成 Faster R-CNN 模型
x = keras.layers.Input(shape = (None, None, 3), name = "input")feature = vgg16_conv(x)
rpn_cls, rpn_reg = rpn(feature)proposal = ProposalLayer(base_anchors, num_rois = TRAIN_NUM, iou_thres = 0.7,name = "proposal")([x, rpn_cls, rpn_reg])pooled_rois = RoiPoolingLayer(name = "roi_pooling")([x, feature, proposal])
y_cls, y_reg = fast_rcnn(pooled_rois, cells = 2048, num_classes = len(CATEGORIES))faster_rcnn = keras.Model(x, [y_cls, y_reg], name = "faster_rcnn")
faster_rcnn.summary()
输出只有 y_cls 与 y_reg, 也就是最后的分类和回归, 这是用于预测的结构, 因为预测只需要这两个. 如果要训练模型的话, 就要将 RPN 网络的输出也放出来, 才能计算 RPN 训练时的损失. 现在我们用类成员函数的方式修改一下模型结构. 函数名是 create_train_model. 后面预测时就不会用这个模型了, 相应的函数名则是 create_predict_model
# 创建训练模型
def create_train_model(self, summary = True):x = keras.layers.Input(shape = (None, None, 3), name = "input")features = self.base_net(x) # base_net 在定义类实例的时候需要传的一个参数, 也就是特征提取网络rpn_cls, rpn_reg = self.rpn(features)proposals = ProposalLayer(self.base_anchors,stride = self.feature_stride,num_rois = self.train_num,iou_thres = self.nms_thres,name = "proposal")([x, rpn_cls, rpn_reg])pooled_rois = RoiPoolingLayer(name = "roi_pooling")([x, features, proposals])# 分类与回归rcnn_cls, rcnn_reg = self.fast_rcnn(pooled_rois, cells = self.dense_cells, num_classes = self.NUM_CLS)self.model = keras.Model(x, [rpn_cls, rpn_reg, rcnn_cls, rcnn_reg], name = "faster_rcnn")if summary:self.model.summary()
这样一改的话, 问题就出来了
- input_reader 函数输出的标签只有 2 个, 现在需要 4 个, 因为 rcnn_cls, rcnn_reg 没有对应的 y_true, 这个问题看起来好像很好办, 在 input_reader 返回数据时添加就好了. 但是请看下面个问题
- rcnn_cls 和 rcnn_reg 是网络的输出值, 但是对应的 y_true 是需要动态计算的, 在哪里动态计算? 在 ProposalLayer 输出之后, 因为建议框的大小和类别我们不能提前在 input_reader 函数中知道, 所以怎么在训练的时候将动态的 y_true 传递给 loss 计算函数呢? 和前面文章中自定义的损失函数比较一下, 这里的问题是不是有点棘手
注: y_true 是 loss 计算函数的形参, 相对的则是 y_pred, 也就是网络的输出(预测值), 监督型学习需要 y_true 去矫正 y_pred. 这个在前面文章中自定义损失函数的时候已经见识过了
接下来讲怎么解决这两个问题
1. 修改 input_reader 函数
原本 input_reader 函数只为 RPN 网络服务, 输出是 (x, [rpn_cls, rpn_reg]), 现在貌似需要改成 (x, [rpn_cls, rpn_reg, rcnn_cls, rcnn_reg]), 让每个输出有对应的 y_true
那怎么改? rcnn_cls, rcnn_reg 两个里面又装的是什么?
我们来分析一下, 原本的 input_reader 输出就已经满足了 RPN 的需求. fast_rcnn 输出的是最终的分类类别和对建议框的修正值, 所以 rcnn_cls 对应的 y_true 就要包含从标签文件读出来的具体的类别, rcnn_reg 对应的 y_true 是从标签文件读出来的 绝对坐标. 包含具体类别这个都好理解, 但是使用绝对坐标而不使用像 RPN 回归标签那样归一化的值是为什么, 不是说不能预测绝对坐标吗? 这个也是没有办法的办法, 因为不能提前知道 ProposalLayer 输出的是什么鬼, 所以我们需要在 ProposalLayer 之后操作一番, 才能让绝对坐标变成归一化的值. 具体怎么操作下面会慢慢讲, 先解决 input_reader 函数的输出问题
因为在 input_reader 函数中用到了数据增强函数 data_augment, 所以要先修改 data_augment 函数的输出, 让其返回值中增加类别标签和绝对坐标
不过在这之前, 我们定义一个成员函数以方便处理 get_ground_truth 的返回值, get_ground_truth 返回的格式是 [bnd_box, cls_id], 新定义的这个成员函数将 [bnd_box, cls_id] 拆分成 [cls_id] 和 [bnd_box] 两个列表
# 拆分 ground_truth
# ground_truth: 从标签文件中读出的标签信息, 由 get_ground_truth 返回
# 返回拆分后的类别列表和坐标列表
def split_ground_truth(self, ground_truth):boxes = []cls_ids = []for b, c, in ground_truth:boxes.append(b)cls_ids.append(c)return cls_ids, boxes
有了 split_ground_truth 函数这后, 修改 data_augment 如下
# 数据增强函数, 包括左右, 上下, 左右上翻转
# data_pair: data_set_path 返回的数据元素
# train_num: 一次参数训练的 anchor 的数量
# 返回增强后的图像和标签
def data_augment(self, data_pair, train_num = 256):augmented = [] # 返回增强后的数据img_src = cv.imread(data_pair[0])img_new, scale = self.new_size_image(img_src)feature_size = (img_new.shape[0] // self.feature_stride,img_new.shape[1] // self.feature_stride)anchors = self.create_train_anchors(feature_size)# 原始图像与标签------------------------------------------------------ground_truth = self.get_ground_truth(data_pair[1], data_pair[2], scale)rpn_cls_label, gt_boxes = self.get_rpn_cls_label(img_new.shape,anchors,ground_truth,self.iou_thres[0],self.iou_thres[1],train_num = train_num)rpn_reg_label = self.get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)# 增加部分rcnn_cls_idx, rcnn_boxes = self.split_ground_truth(ground_truth)augmented.append([img_new,rpn_cls_label, rpn_reg_label,rcnn_cls_idx, rcnn_boxes])# 原始图像与标签------------------------------------------------------# 左右翻转与标签------------------------------------------------------# 复制一份,后面的操作在备份上操作gt_copy = copy.deepcopy(ground_truth)x_flip = cv.flip(img_new, 1) # 左右翻转图像for gt in gt_copy: # 左右翻转标签gt[0][0] = x_flip.shape[1] - 1 - gt[0][0]gt[0][2] = x_flip.shape[1] - 1 - gt[0][2]gt[0][0], gt[0][2] = gt[0][2], gt[0][0]rpn_cls_label, gt_boxes = self.get_rpn_cls_label(x_flip.shape,anchors,gt_copy,self.iou_thres[0],self.iou_thres[1],train_num = train_num)rpn_reg_label = self.get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)# 增加部分rcnn_cls_idx, rcnn_boxes = self.split_ground_truth(gt_copy)augmented.append([x_flip,rpn_cls_label, rpn_reg_label,rcnn_cls_idx, rcnn_boxes])# 左右翻转与标签------------------------------------------------------# 上下翻转与标签------------------------------------------------------# 复制一份,后面的操作在备份上操作gt_copy = copy.deepcopy(ground_truth)y_flip = cv.flip(img_new, 0) # 左右翻转图像for gt in gt_copy: # 上下翻转标签gt[0][1] = y_flip.shape[0] - 1 - gt[0][1]gt[0][3] = y_flip.shape[0] - 1 - gt[0][3]gt[0][1], gt[0][3] = gt[0][3], gt[0][1]rpn_cls_label, gt_boxes = self.get_rpn_cls_label(y_flip.shape,anchors,gt_copy,self.iou_thres[0],self.iou_thres[1],train_num = train_num)rpn_reg_label = self.get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)# 增加部分rcnn_cls_idx, rcnn_boxes = self.split_ground_truth(gt_copy)augmented.append([y_flip,rpn_cls_label, rpn_reg_label,rcnn_cls_idx, rcnn_boxes])# 上下翻转与标签------------------------------------------------------# 左右上下翻转与标签--------------------------------------------------# 复制一份,后面的操作在备份上操作gt_copy = copy.deepcopy(ground_truth)xy_flip = cv.flip(img_new, -1) # 左右翻转图像for gt in gt_copy: # 左右上下翻转标签gt[0][0] = xy_flip.shape[1] - 1 - gt[0][0]gt[0][1] = xy_flip.shape[0] - 1 - gt[0][1]gt[0][2] = xy_flip.shape[1] - 1 - gt[0][2]gt[0][3] = xy_flip.shape[0] - 1 - gt[0][3]gt[0][0], gt[0][2] = gt[0][2], gt[0][0]gt[0][1], gt[0][3] = gt[0][3], gt[0][1]rpn_cls_label, gt_boxes = self.get_rpn_cls_label(xy_flip.shape,anchors,gt_copy,self.iou_thres[0],self.iou_thres[1],train_num = train_num)rpn_reg_label = self.get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)# 增加部分rcnn_cls_idx, rcnn_boxes = self.split_ground_truth(gt_copy)augmented.append([xy_flip,rpn_cls_label, rpn_reg_label,rcnn_cls_idx, rcnn_boxes])# 左右上下翻转与标签--------------------------------------------------return augmented
对比旧的 data_augment 函数, 可以看到修改的地方很少, 除了输出多了 rcnn_cls_idx, rcnn_boxes. 还有增加了下面一句
# 增加部分
rcnn_cls_idx, rcnn_boxes = self.split_ground_truth(ground_truth)
接下来就可以修改 input_reader 函数了
# 网络输入数据 generator
# data_set: 训练或测试数据列表
# batch_size: 一次输入训练的图像数量
# train_num: 参加训练的 anchor 的数量
# augment_fun: 数据增强函数
# train_mode: True: 训练模式, False: 测试模式
# shuffle_enable: 打乱标记
# 返回图像和标签
def input_reader(self, data_set, batch_size = 1, train_num = 256,augment_fun = None, train_mode = True, shuffle_enable = True):assert(isinstance(data_set, (tuple, list)))stop_now = Falsedata_nums = len(data_set)index_list = [x for x in range(data_nums)] # 用这个列表序号来打乱 data_set 排序x = [] # 图像rpn_cls = [] # RPN 分类标签rpn_reg = [] # RPN 回归标签rcnn_cls = [] # RCNN 分类标签rcnn_reg = [] # RCNN 回归标签max_rows = 0 # 记录一个 batch 中图像的最大行数max_cols = 0 # 记录一个 batch 中图像的最大列数while False == stop_now:if train_mode and shuffle_enable:shuffle(index_list)for i in index_list:# 如果 3 == data_set[i], 表示带标签输入, 否则只有图像is_with_label = 3 == len(data_set[i])data_list = [] # 图像与标签 listif is_with_label:if augment_fun and train_mode:data_list.extend(augment_fun(data_set[i], train_num))else:# 这里的代码和 augment_fun 中的开始部分一样, 就不解释了img_src = cv.imread(data_set[i][0])img_new, scale = self.new_size_image(img_src)feature_size = (img_new.shape[0] // self.feature_stride,img_new.shape[1] // self.feature_stride)anchors = self.create_train_anchors(feature_size)ground_truth = self.get_ground_truth(data_set[i][1], data_set[i][2], scale)rpn_cls_label, gt_boxes = self.get_rpn_cls_label(img_new.shape,anchors,ground_truth,self.iou_thres[0],self.iou_thres[1],train_num = train_num) rpn_reg_label = self.get_rpn_reg_label(anchors, rpn_cls_label, gt_boxes)rcnn_cls_idx, rcnn_boxes = self.split_ground_truth(ground_truth)data_list.append([img_new, rpn_cls_label, rpn_reg_label,rcnn_cls_idx, rcnn_boxes])else:train_mode = Falseimg_src = cv.imread(data_set[i])img_new, scale = self.new_size_image(img_src)data_list.append([img_new, [], [], [], []]) # 为了保持和时候相同的形状for data in data_list:x.append(data[0])rpn_cls.append(data[1])rpn_reg.append(data[2])rcnn_cls.append(data[3]) # 此处为增加的 rcnn_cls 标签rcnn_reg.append(data[4]) # 此处为增加的 rcnn_reg 标签max_rows = max(max_rows, x[-1].shape[0])max_cols = max(max_cols, x[-1].shape[1])if len(x) >= batch_size:# 一个 batch 中图像的尺寸不一样是不能一起训练的, 所以要将其统一到相同的尺寸# 行数小于最大行数在图像下方填充 0, 列数小于最大列数在图像右方填充 0# 图像填充的同时标签也要填充new_shape = (max_rows // self.feature_stride,max_cols // self.feature_stride)for j, img in enumerate(x):# 原图对应的特征图尺寸old_shape = (img.shape[0] // self.feature_stride,img.shape[1] // self.feature_stride)# 这里 = 号前要用 x[j] 不能用 img, 因为要改变 x[j], img 只是一个副本x[j] = cv.copyMakeBorder(img,0, max_rows - img.shape[0], 0, max_cols - img.shape[1],cv.BORDER_CONSTANT, (0, 0, 0))if is_with_label:# 行方向填充数据if new_shape[0] - old_shape[0] > 0:pad_num = (new_shape[0] - old_shape[0]) * old_shape[1] * self.Ky_pad = [self.NEUTRAL] * pad_numrpn_cls[j].extend(y_pad)y_pad = [self.REG_NO_TRAIN] * pad_num * self.ANCHOR_DIMSrpn_reg[j].extend(y_pad)# 列方向填充# 行方向时直接加在末尾, 而列方向是不连续的, 所以一行一行加在末尾if new_shape[1] - old_shape[1] > 0:pad_pos = old_shape[1] * self.K pad_num = (new_shape[1] - old_shape[1]) * self.Ky_pad = [self.NEUTRAL] * pad_numfor r in range(new_shape[0]):# 这里不能用 insert 函数, insert 会把 y_pad 整体当成一个元素rpn_cls[j][pad_pos: pad_pos] = y_padpad_pos += (pad_num + old_shape[1] * self.K)pad_pos = old_shape[1] * self.K * self.ANCHOR_DIMSpad_num = (new_shape[1] - old_shape[1]) * self.K * self.ANCHOR_DIMSy_pad = [self.REG_NO_TRAIN] * pad_numfor r in range(new_shape[0]):# 这里不能用 insert 函数, insert 会把 y_pad 整体当成一个元素rpn_reg[j][pad_pos: pad_pos] = y_padpad_pos += (pad_num + old_shape[1] * self.K * self.ANCHOR_DIMS)# 一个 batch 中的数据的维度要相同, 不足的要填充# max_targets 为 一个 batch 中一张图中最多的目标个数max_targets = 0for each in rcnn_cls:targets = len(each)if targets > max_targets:max_targets = targetsfor k in range(batch_size):targets = len(rcnn_cls[k])rcnn_cls[k].extend([0] * (max_targets - targets)) # 填充 0for k in range(batch_size):targets = len(rcnn_reg[k])rcnn_reg[k].extend([[0, 0, 0, 0]] * (max_targets - targets)) # 填充 0# 图像数据x = np.array(x).astype(np.float32) / 255.0# RPN 分类标签rpn_cls = np.array(rpn_cls).astype(np.float32)if is_with_label:rpn_cls = rpn_cls.reshape((-1, new_shape[0], new_shape[1], self.K))# RPN 回归标签rpn_reg = np.array(rpn_reg)if is_with_label:rpn_reg = rpn_reg.reshape((-1, new_shape[0], new_shape[1], self.K * self.ANCHOR_DIMS))# RCNN 分类标签rcnn_cls = np.array(rcnn_cls)if is_with_label:rcnn_cls = rcnn_cls.reshape((batch_size, -1, 1))# RCNN 回归标签rcnn_reg = np.array(rcnn_reg)if is_with_label:rcnn_reg = rcnn_reg.reshape((batch_size, -1, self.ANCHOR_DIMS))yield x, [rpn_cls, rpn_reg, rcnn_cls, rcnn_reg]x = []rpn_cls = []rpn_reg = []rcnn_cls = []rcnn_reg = []max_rows = 0max_cols = 0if False == train_mode:stop_now = True
相对于旧的 input_reader 函数, 修改的地方也很少, 只要和旧的对比着看, 很容易就能发现修改的地方. 主要是 yield 返回增加了 rcnn_cls, rcnn_reg, 要特别注意的地方是同一个 batch 中数据的维度要一样, 所以当一个 batch 中有的图像目标数量多, 有的目标数量少的时候, 少的要填充到和多的一样多, 填充 0 就好. 相当于填充的是背景, 并不影响后面的类别判断. 填充代码摘出来放下面方便看
# 一个 batch 中的数据的维度要相同, 不足的要填充
# max_targets 为 一个 batch 中一张图中最多的目标个数
max_targets = 0for each in rcnn_cls:targets = len(each)if targets > max_targets:max_targets = targetsfor k in range(batch_size):targets = len(rcnn_cls[k])rcnn_cls[k].extend([0] * (max_targets - targets)) # 填充 0for k in range(batch_size):targets = len(rcnn_reg[k])rcnn_reg[k].extend([[0, 0, 0, 0]] * (max_targets - targets)) # 填充 0
修改之后, input_reader 返回数据变成了 (x, [rpn_cls, rpn_reg, rcnn_cls, rcnn_reg]), 这样也就符合了网络的结构
那现在可以训练了吗? 答案是不可以. 损失函数暂且我们还没有定义, 单是 input_reader 返回的 rcnn_cls, rcnn_reg 维度就对应不了网络输出维度, 因为 ProposalLayer 输出的建议框的个数可能远大于标签文件中的目标个数, 这样的话, 有很多建议框就找不到对应的标签了. 这个我们后面会处理, 先暂时不用理会
注意: 因为 input_reader 中返回值的命名和网络输出层一样, 请注意根据上下文区分
2. 增加 RoiLabelLayer 层
这是一个非常重要的层. 前面我们有提到, 网络输出 rcnn_cls 和 rcnn_reg 对应的 y_true 是在 ProposalLayer 之后动态计算的, 如何动态计算? 这就需要我们再弄一个自定义层, 这个层吃的是 ProposalLayer 输出的建议框矩形和 input_reader 给出的 rcnn_cls, rcnn_reg. 两个一比较就可以计算 y_true 了. 吐的是网络输出 rcnn_cls 和 rcnn_reg 对应的 y_true, 也就是各 ROI 对应的类别标签和回归标签. 此时回归标签就是归一化的值. 所以这个层的功能就是 打标签
# 定义 RoiLabel Layer
# iou_thres: 正负样本阈值
# negative_flag: 负样本标记, 不参与 loss 计算, 正样本是自动计算的
class RoiLabelLayer(Layer):def __init__(self, iou_thres = 0.5, negative_flag = 8.0, **kwargs):self.iou_thres = iou_thresself.negative_flag = negative_flagsuper(RoiLabelLayer, self).__init__(**kwargs)def build(self, input_shape):super(RoiLabelLayer, self).build(input_shape)def call(self, inputs):proposals, class_true, regression_true = inputs# 计算每个候选框与真实目标框之间的 IoUious = self.calculate_iou(proposals, regression_true)class_true = self.get_class_label(ious, class_true)regression_true = self.get_regression_label(ious, proposals, regression_true) return [class_true, regression_true]def compute_output_shape(self, input_shape):return [(input_shape[0][0], input_shape[0][1], 1), input_shape[0]]# IoU 计算函数# 需要计算每个建议框与每个目标框之间的 IoU# proposals: ProposalLayer 选出来的建议框# regression_true: 标签文件中的目标框, 也就是 input_reader 返回的目标框坐标def calculate_iou(self, proposals, regression_true):num_proposals = tf.shape(proposals)[1] # ProposalLayer 选出来的建议框的个数num_regression_true = tf.shape(regression_true)[1] # 标签文件中的目标数量# 因为不能用 for 循环这样的操作来一一计算 IoU 所以要按下面的方式扩展维度后计算# 将 proposals 和 regression_true 的维度扩展# proposals 扩展后 shape == (batch_size, num_proposals, 1, 4)proposals = tf.expand_dims(proposals, axis = 2)# 扩展后 shape == (batch_size, 1, num_regression_true, num_regression_true)regression_true = tf.expand_dims(regression_true, axis = 1)# proposal_box_box 的坐标顺序是 (y1, x1, y2, x2)# true_box_box 的坐标顺序是 (x1, y1, x2, y2)proposals_y1, proposals_x1, proposals_y2, proposals_x2 = tf.unstack(proposals, axis = -1)true_x1, true_y1, true_x2, true_y2 = tf.unstack(regression_true, axis = -1)intersection_x1 = tf.maximum(proposals_x1, true_x1)intersection_y1 = tf.maximum(proposals_y1, true_y1)intersection_x2 = tf.minimum(proposals_x2, true_x2)intersection_y2 = tf.minimum(proposals_y2, true_y2)w = tf.maximum(intersection_x2 - intersection_x1, 0)h = tf.maximum(intersection_y2 - intersection_y1, 0)intersection_area = w * hproposal_area = (proposals_x2 - proposals_x1) * (proposals_y2 - proposals_y1)true_area = (true_x2 - true_x1) * (true_y2 - true_y1)# 计算 IoU# 完成后 ious.shape == (batch_size, num_regression_true, num_regression_true)# (i, j) 元素为 第 i 个建议框与第 j 个目标框的 IoUious = tf.where(tf.equal(proposal_area + true_area, 0),tf.zeros_like(intersection_area),intersection_area / (proposal_area + true_area - intersection_area + 1e-8))return ious# 计算每个建议框的类别标签# ious: calculate_iou 返回的 IoU# class_true: 每个目标框类别序号(整数)def get_class_label(self, ious, class_true):# 每个建议框与所有目标框的最大 IoUmax_ious = tf.reduce_max(ious, axis = -1)# 最大 IoU 的索引max_indices = tf.argmax(ious, axis = -1) # 利用 max_indices 将类别值(整数)从 class_true 中取出来, 相当于一个查表操作y_true = tf.gather(class_true, max_indices, axis = 1, batch_dims = 1) y_shape = tf.shape(y_true)# 超过阈值的 IoU 转换成 1, 其他为 0mask = tf.cast(max_ious >= self.iou_thres, dtype = tf.float32)# 转换成符合 RoiLabelLayer 输出的形状mask = tf.reshape(mask, (y_shape[0], y_shape[1], 1))y_true = tf.reshape(y_true, (y_shape[0], y_shape[1], 1))# 将小于阈值的 y_true 变成 0, 也就是背景序号y_true = y_true * maskreturn y_true# 计算每个建议框的回归标签, 其中负样本全部设置为 self.negative_flag# ious: calculate_iou 返回的 IoU# proposals: ProposalLayer 选出来的建议框# regression_true: 每个目标框坐标def get_regression_label(self, ious, proposals, regression_true):# 每个建议框与所有目标框的最大 IoUmax_ious = tf.reduce_max(ious, axis = -1)# 最大 IoU 的索引max_indices = tf.argmax(ious, axis = -1)# 利用 max_indices 将坐标从 regression_true 中取出来, 相当于一个查表操作regression_true = tf.gather(regression_true, max_indices, axis = 1, batch_dims = 1)# 建议框宽度和高度proposal_w = proposals[..., 3] - proposals[..., 1]proposal_h = proposals[..., 2] - proposals[..., 0]# 建议框中心坐标proposal_x = proposals[..., 1] + proposal_w * 0.5proposal_y = proposals[..., 0] + proposal_h * 0.5# 目标框宽度和高度true_w = regression_true[..., 2] - regression_true[..., 0]true_h = regression_true[..., 3] - regression_true[..., 1]# 目标框中心坐标true_x = regression_true[..., 0] + true_w * 0.5true_y = regression_true[..., 1] + true_h * 0.5# 超过阈值的 IoU 转换成 1, 其他为 0postive_mask = tf.cast(max_ious >= self.iou_thres, dtype = tf.float32)# 负样本位置转换成负样本标签值, 其他为 0negative_mask = tf.cast(max_ious < self.iou_thres, dtype = tf.float32) * self.negative_flag# 修正量, 负样本的标签修正值都变成 8.0dx = (true_x - proposal_x) / proposal_w * postive_mask + negative_maskdy = (true_y - proposal_y) / proposal_h * postive_mask + negative_maskdw = tf.math.log(true_w / proposal_w) * postive_mask + negative_maskdh = tf.math.log(true_h / proposal_h) * postive_mask + negative_masky_true = tf.stack([dx, dy, dw, dh], axis = -1)return y_true
上面的代码并不难, 主要是要理解 TensorFlow 的一些函数的用法以及如何为每个建议框打标签的原理. 打标签的话, 可以看一下前面相关的文章, 里面有祥细的讲解
这个层放在网络中的什么地方呢? 正所谓有图有真相, No 图 No bi bi. 看下就很明了了. 橙色的框表示网络输出
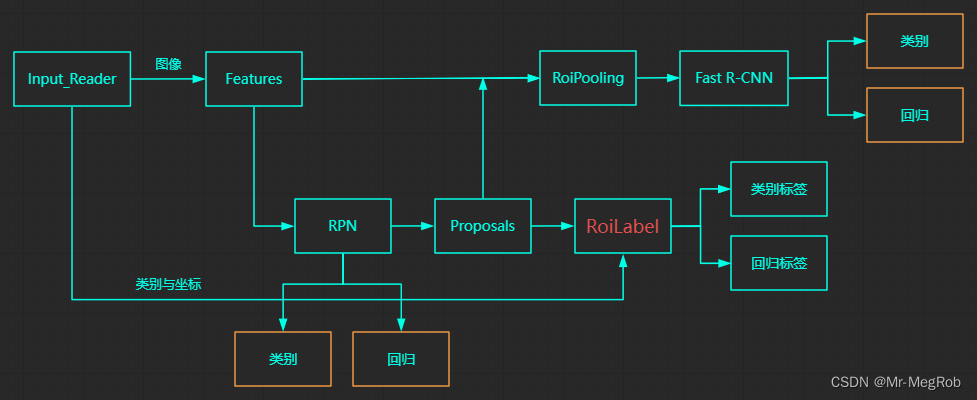
好, 理解了上面的图之后, 可以举一个带数字的例子, 如下图

- 图中有 4 个建议框, 3个目标框
- 图中红框表示 ProposalLayer 输出的建议框, 左上和右下角圆括号中的数字表示坐标, 顺序是 ( y 1 , x 1 , y 2 , x 2 ) (y_1, x_1, y_2, x_2) (y1,x1,y2,x2), 左上角的小号数字表示建议框的序号
- 图中绿框表示目标框, 由 input_reader 函数给出, 左上和右下角圆括号中的数字表示坐标, 顺序是 ( x 1 , y 1 , x 2 , y 2 ) (x_1, y_1, x_2, y_2) (x1,y1,x2,y2), 左上角的小号数字表示目标框的序号, 中心字号大点的数字表示这个目标框的类别序号
交待完毕, 用代码测试
# 测试 RoiLabel
# 4 个建议框
proposals = [[[36, 77, 187, 160], [50, 269, 176, 372], [240, 77, 354, 243], [113, 334, 240, 554]]]
proposals = np.array(proposals).astype(np.float32)# 3 个 目标, 其类别分别为 3, 1, 2
class_true = [[3, 1, 2]]
class_true = np.array(class_true).astype(np.float32)# 3 个目标框的坐标, 其类别对应于上面的 3, 1, 2
reg_true = [[[316, 147, 536, 274], [86, 219, 268, 344], [49, 49, 194, 166]]]
reg_true = np.array(reg_true).astype(np.float32)
测试
roi_label = RoiLabelLayer(name = "roi_label")
ious = roi_label.calculate_iou(proposals, reg_true)
print("ious:", ious)
cls_id, regs = roi_label.call([proposals, class_true, reg_true])
print("\ncls_id:", cls_id, "\n\nregs:", regs)
输出
ious: tf.Tensor(
[[[0. 0. 0.49077678][0.04132947 0. 0. ][0. 0.6442042 0. ][0.5064431 0. 0. ]]], shape=(1, 4, 3), dtype=float32)cls_id: tf.Tensor(
[[[0][0][1][3]]], shape=(1, 4, 1), dtype=int32) regs: tf.Tensor(
[[[ 8. 8. 8. 8. ][ 8. 8. 8. 8. ][ 0.10240964 -0.13596492 0.09201895 0.09211528][-0.08181818 0.26771653 0. 0. ]]], shape=(1, 4, 4), dtype=float32)
上面的输出中, ious 中的 ( i , j ) (i, j) (i,j) 元素表示 第 i i i 个建议框与第 j j j 个目标框的 IoU.
- 0.49077678 表示 红框 0 与 绿框 2 的 IoU 为 0.49077678. 但是未超过正样本阈值 0.5, 所以在 cls_id 中对应的类别序号为 0
- 0.6442042 表示 红框 2 与 绿框 1 的 IoU 为 0.6442042. 超过正样本阈值 0.5, 而 绿框 1 的类别序号是 1, 所以在 cls_id 中对应的类别序号为 1. 因为是正样本, 所以有不为 0 的修正值 [ 0.10240964 , − 0.13596492 , 0.09201895 , 0.09211528 ] [0.10240964, -0.13596492, 0.09201895, 0.09211528] [0.10240964,−0.13596492,0.09201895,0.09211528]
- 负样本回归标签全部为 self.negative_flag, 在这里是 8.0, 后面计算损失时并不会参与计算
有了 RoiLabelLayer 层, 现在可以将其加到模型中吗? 还是不可以. 因为 RoiLabelLayer 要吃 input_reader 给的相关标签, 但是目前 input_reader 的输出是 (x, [rpn_cls, rpn_reg, rcnn_cls, rcnn_reg]), 真正输入到网络的只有 x, 列表 [rpn_cls, rpn_reg, rcnn_cls, rcnn_reg] 是给损失函数用的, 所以 RoiLabelLayer 得不到 input_reader 给的 rcnn_cls, rcnn_reg. 基于这个原因, 我们要改一下 input_reader 返回数据的地方, 也就一句话, 把
yield x, [rpn_cls, rpn_reg, rcnn_cls, rcnn_reg]
改成
yield [x, rcnn_cls, rcnn_reg], [rpn_cls, rpn_reg, rcnn_cls, rcnn_reg]
改完了之后, 模型就需要增加两个输入. 还有一点要处理. 就是怎么把 RoiLabelLayer 的输出告诉 loss 计算函数呢? 因为 RoiLabelLayer 在模型内部, 只有将其作为输出, 外部才能访问. 模型结构如下图. 橙色的框表示网络输出
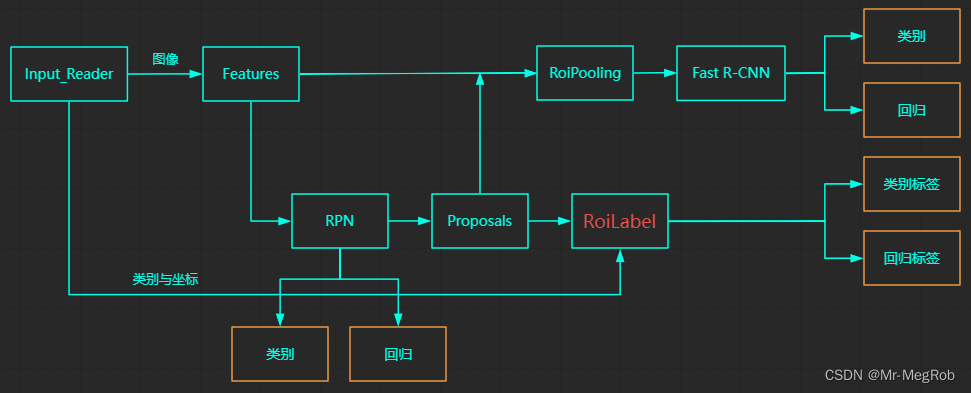
这样的结构也没有错, 只是这样损失函数会比较麻烦. 需要用到自定义损失层, 训练也不方便. 我们用更简单的方式来. 用下面的结构. 橙色的框表示网络输出
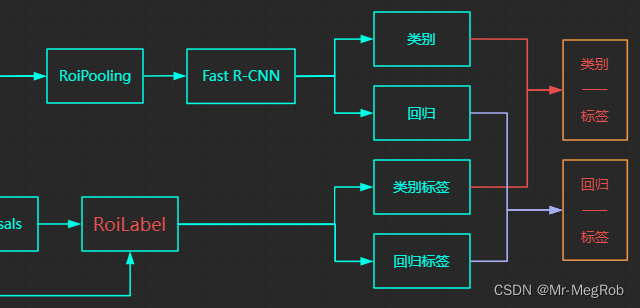
新的结构将预测值和标签组合成一个层作为输出. 改成组合的方式有一个好处, 就是计算 loss 很方便. 在自定义损失函数中将 y_pred 拆分开就有了 y_true 与 y_pred. 灰常银杏
现在修改 create_train_model 函数如下
# 创建训练模型
def create_train_model(self, summary = True):# 输入图像x_image = keras.layers.Input(shape = (None, None, 3), name = "input_image")# 从标签文件中读出的类别y_class = keras.layers.Input(shape = (None, 1), name = "input_classes")# 从标签文件中读出的目标框坐标y_boxes = keras.layers.Input(shape = (None, self.ANCHOR_DIMS), name = "input_boxes")features = self.base_net(x_image)rpn_cls, rpn_reg = self.rpn_net(features)proposals = ProposalLayer(self.base_anchors,stride = self.feature_stride,num_rois = self.train_num,iou_thres = self.nms_thres,name = "proposal")([x_image, rpn_cls, rpn_reg])pooled_rois = RoiPoolingLayer(name = "roi_pooling")([x_image, features, proposals])rcnn_cls, rcnn_reg = self.fast_rcnn(pooled_rois, cells = self.dense_cells, num_classes = self.NUM_CLS)# 类别标签与回归标签class_true, regression_true = RoiLabelLayer(iou_thres = 0.5,negative_flag = self.REG_NO_TRAIN,name = "roi_label")([proposals, y_class, y_boxes])rcnn_cls_concat = keras.layers.Concatenate(axis = -1, name = "class")([rcnn_cls, class_true])rcnn_reg_concat = keras.layers.Concatenate(axis = -1, name = "regression")([rcnn_reg, regression_true])self.model = keras.Model(inputs = [x_image, y_class, y_boxes],outputs = [rpn_cls, rpn_reg, rcnn_cls_concat, rcnn_reg_concat],name = "faster_rcnn")# plot_model(self.model, to_file = self.model.name + ".png", show_shapes = True)if summary:self.model.summary()
三. 损失函数
基于上面的修改后, 目前到了损失函数的定义了. RPN 网络的损失函数不用修改, 因为 input_reader 提供的标签已经够用了. 现在差的是 RCNN 网络的损失函数. 也是两个, 分别是分类和回归. 因为 RCNN 网络和 RPN 网络输出的相似性, 两个网络的损失函数很大程度上是相似的
1. 自定义损失函数
由于 ProposalLayer 输出只有正负样本, 也就不再区分中立样本. 分类损失函数可以光明正大的用 Keras 提供的与分类相关的损失函数. 而 RoiLabelLayer 输出的分类标签是整数类别标签, 虽然是多分类, 也没有必要转换成 one-hot 标签, sparse_categorical_crossentropy 损失函数吃的就是整数类别标签. 所以直接使用 sparse_categorical_crossentropy 作为 RCNN 分类的损失函数很合理. 因为预测值和标签是组合在一起的, 所以在自定义函数中要将其拆分. 因为不是 one-hot 标签, 所以 y_true 最后一维是 1
# RCNN 网络分类损失函数
def rcnn_cls_loss(self, y_true, y_pred):pred_shape = tf.shape(y_pred)# 拆分, 标签最后一维是 1y_pred, y_true = tf.split(y_pred, num_or_size_splits = [pred_shape[-1] - 1, 1], axis = -1)y_true = tf.cast(y_true, dtype = tf.int32) loss = K.sparse_categorical_crossentropy(y_true, y_pred)return loss
同理, RCNN 回归的损失函数可以写成下面这样, 简直和 RPN 的回归损失函数一模一样
# RCNN 网络回归损失失函数
def rcnn_reg_loss(self, y_true, y_pred):pred_shape = tf.shape(y_pred)# 拆分, 预测和标签各占一半y_pred, y_true = tf.split(y_pred, num_or_size_splits = [pred_shape[-1] // 2, pred_shape[-1] // 2], axis = -1)# 这里的 mask 用于区分正负样本, 负样本不参与计算损失mask = tf.cast(y_true < self.REG_NO_TRAIN, dtype = tf.float32)offset = mask * K.abs(y_true - y_pred)less_than_1 = tf.cast(offset <= 1.0, dtype = tf.float32)loss = K.sum(less_than_1 * 0.5 * offset ** 2 +(1 - less_than_1) * (offset - 0.5)) / (1e-6 + K.sum(mask))return loss
2. 自定义精度评价函数
有了损失函数, 也需要精度评价函数
# RCNN 网络分类精度评价函数
def rcnn_cls_acc(self, y_true, y_pred):pred_shape = tf.shape(y_pred)y_pred, y_true = tf.split(y_pred, num_or_size_splits = [pred_shape[-1] - 1, 1], axis = -1)acc = keras.metrics.sparse_categorical_accuracy(y_true, y_pred)return acc
# RCNN 网络回归精度评价函数
def rcnn_reg_acc(self, y_true, y_pred):pred_shape = tf.shape(y_pred)y_pred, y_true = tf.split(y_pred, num_or_size_splits = [pred_shape[-1] // 2, pred_shape[-1] // 2], axis = -1)mask = tf.cast(y_true < self.REG_NO_TRAIN, dtype = tf.float32)offset = mask * K.abs(y_true - y_pred)ofst_true = mask * K.abs(y_true)acc = 1 - K.sum(offset) / (1e-6 + K.sum(ofst_true))return acc
四. 模型编译
有了损失函数, 就可以编译模型了, 如下
# 编译模型
def compile(self, optimizer = keras.optimizers.Adam(learning_rate = 1e-4)):self.model.compile(optimizer = optimizer,loss = [self.rpn_cls_loss, self.rpn_reg_loss,self.rcnn_cls_loss, self.rcnn_reg_loss],loss_weights = [1.0, 10.0, 1.0, 10.0],metrics = {"rpn_cls": self.rpn_cls_acc,"rpn_reg": self.rpn_reg_acc,"class": self.rcnn_cls_acc,"regression": self.rcnn_reg_acc})
五. 模型训练
到了最激动的时刻了, 定义训练的函数
# 训练模型
# augment_fun: 数据增强函数
# augmented_num: 一张图像增强后的数量, 默认只有翻转, 所以是 4
def train(self, epochs = 64, batch_size = 4, augment_fun = None, augmented_num = 4):if None == augment_fun:augment_fun = self.data_augmenttrain_reader = self.input_reader(self.train_set, batch_size = batch_size,augment_fun = augment_fun, train_num = self.train_num)valid_reader = self.input_reader(self.valid_set, batch_size = batch_size,augment_fun = augment_fun, train_num = self.train_num)steps_per_epoch = len(self.train_set) * augmented_num // batch_sizevalidation_steps = max(1, len(self.valid_set) * augmented_num // batch_size)history = self.model.fit(train_reader,steps_per_epoch = steps_per_epoch,epochs = epochs,verbose = 1,validation_data = valid_reader,validation_steps = validation_steps,max_queue_size = 8,workers = 1)
像最开始的说那样, 我们要的效果是定义一个类实例, 调用函数就可以开始训练, 我们来试一下
# 特征提取网络
base_net = vgg16_conv
# 日志路径
log_path = osp.join(os.getcwd(), "train_log")
# 定义实例
faster_rcnn = FasterRcnn(base_net = base_net, categories = CATEGORIES, log_path = log_path)
# 划分数据集
faster_rcnn.get_data_set(split_rate = (0.8, 0.1, 0.1))
# 创建模型
faster_rcnn.create_train_model(summary = True)
# 编译模型
faster_rcnn.compile()
# 训练模型
faster_rcnn.train(epochs = 64, batch_size = 4)
Model: "faster_rcnn"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_image (InputLayer) (None, None, None, 3 0
__________________________________________________________________________________________________
vgg16_x1_1 (Conv2D) (None, None, None, 6 1792 input_image[0][0]
__________________________________________________________________________________________________
vgg16_x1_2 (Conv2D) (None, None, None, 6 36928 vgg16_x1_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_5 (MaxPooling2D) (None, None, None, 6 0 vgg16_x1_2[0][0]
__________________________________________________________________________________________________
vgg16_x2_1 (Conv2D) (None, None, None, 1 73856 max_pooling2d_5[0][0]
__________________________________________________________________________________________________
vgg16_x2_2 (Conv2D) (None, None, None, 1 147584 vgg16_x2_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_6 (MaxPooling2D) (None, None, None, 1 0 vgg16_x2_2[0][0]
__________________________________________________________________________________________________
vgg16_x3_1 (Conv2D) (None, None, None, 2 295168 max_pooling2d_6[0][0]
__________________________________________________________________________________________________
vgg16_x3_2 (Conv2D) (None, None, None, 2 590080 vgg16_x3_1[0][0]
__________________________________________________________________________________________________
vgg16_x3_3 (Conv2D) (None, None, None, 2 590080 vgg16_x3_2[0][0]
__________________________________________________________________________________________________
max_pooling2d_7 (MaxPooling2D) (None, None, None, 2 0 vgg16_x3_3[0][0]
__________________________________________________________________________________________________
vgg16_x4_1 (Conv2D) (None, None, None, 5 1180160 max_pooling2d_7[0][0]
__________________________________________________________________________________________________
vgg16_x4_2 (Conv2D) (None, None, None, 5 2359808 vgg16_x4_1[0][0]
__________________________________________________________________________________________________
vgg16_x4_3 (Conv2D) (None, None, None, 5 2359808 vgg16_x4_2[0][0]
__________________________________________________________________________________________________
max_pooling2d_8 (MaxPooling2D) (None, None, None, 5 0 vgg16_x4_3[0][0]
__________________________________________________________________________________________________
vgg16_x5_1 (Conv2D) (None, None, None, 5 2359808 max_pooling2d_8[0][0]
__________________________________________________________________________________________________
vgg16_x5_2 (Conv2D) (None, None, None, 5 2359808 vgg16_x5_1[0][0]
__________________________________________________________________________________________________
vgg16_x5_3 (Conv2D) (None, None, None, 5 2359808 vgg16_x5_2[0][0]
__________________________________________________________________________________________________
rpn_conv (Conv2D) (None, None, None, 5 2359808 vgg16_x5_3[0][0]
__________________________________________________________________________________________________
rpn_cls (Conv2D) (None, None, None, 9 4617 rpn_conv[0][0]
__________________________________________________________________________________________________
rpn_reg (Conv2D) (None, None, None, 3 18468 rpn_conv[0][0]
__________________________________________________________________________________________________
proposal (ProposalLayer) (None, 256, 4) 0 input_image[0][0] rpn_cls[0][0] rpn_reg[0][0]
__________________________________________________________________________________________________
roi_pooling (RoiPoolingLayer) (None, 256, 7, 7, 51 0 input_image[0][0] vgg16_x5_3[0][0] proposal[0][0]
__________________________________________________________________________________________________
roi_flatten (TimeDistributed) (None, 256, 25088) 0 roi_pooling[0][0]
__________________________________________________________________________________________________
fc_1 (TimeDistributed) (None, 256, 2048) 51382272 roi_flatten[0][0]
__________________________________________________________________________________________________
fc_2 (TimeDistributed) (None, 256, 2048) 4196352 fc_1[0][0]
__________________________________________________________________________________________________
input_classes (InputLayer) (None, None, 1) 0
__________________________________________________________________________________________________
input_boxes (InputLayer) (None, None, 4) 0
__________________________________________________________________________________________________
rcnn_cls (TimeDistributed) (None, 256, 21) 43029 fc_2[0][0]
__________________________________________________________________________________________________
roi_label (RoiLabelLayer) [(None, 256, 1), (No 0 proposal[0][0] input_classes[0][0] input_boxes[0][0]
__________________________________________________________________________________________________
rcnn_reg (TimeDistributed) (None, 256, 4) 8196 fc_2[0][0]
__________________________________________________________________________________________________
class (Concatenate) (None, 256, 22) 0 rcnn_cls[0][0] roi_label[0][0]
__________________________________________________________________________________________________
regression (Concatenate) (None, 256, 8) 0 rcnn_reg[0][0] roi_label[0][1]
==================================================================================================
Total params: 72,727,430
Trainable params: 72,727,430
Non-trainable params: 0
__________________________________________________________________________________________________
Epoch 1/6436/4008 [..............................] - ETA: 31:49 - loss: 2.4105 - rpn_cls_loss: 0.2319 - rpn_reg_loss: 0.0445 - class_loss: 1.1483 - regression_loss: 0.0585 - rpn_cls_rpn_cls_acc: 0.9587 - rpn_reg_rpn_reg_acc: -0.0715 - class_rcnn_cls_acc: 0.7901 - regression_rcnn_reg_acc: 0.0537
这样看训练是跑起来了, 但是你有 99.99% 的可能性看到 loss 虽然在下降, 但是精度不提升. rpn_cls_rpn_cls_acc 和 class_rcnn_cls_acc 分别维持在 0.95 和 0.8 左右. 而 rpn_reg_rpn_reg_acc 和 regression_rcnn_reg_acc 一会升一会降, 不过都在 0 左右. 这些值表明网络并没有学到想要的东西. 因为样本不均衡, 胡乱猜也就是这样的值
六. 预训练模型
上面模型训练达不到预期效果, 主要是因为各输出之间相互干扰. 如果我们只训练 RPN 的分类部分(参见保姆级 Keras 实现 Faster R-CNN 五)的话, 就非常好训练. 只训练 RPN 分类可以为模型参数的更新指示一个大致的方向, 充当 “药引子” 的功能. 当 RPN 分类训练得差不多的时候, 接着训练整个 RPN 模型(参见保姆级 Keras 实现 Faster R-CNN 八). 等 RPN 训完成后, RCNN 部分的分类与回归交替训练, 这样训练可以得到比较好的效果
那如何让这样分步训练的过程自动化的完成呢? 这就需要用到回调函数的功能. 在 fit 函数中有一个 callbacks 参数, 可以在训练过程中控制或者修改一些参数, 以达到控制训练过程的目的. 下面定义的这个 TrainCallback 类就是传递给 callbacks 的参数, 在不同的阶段冻结不需要训练的层并修改模型的 loss_weights 列表, 控制某个输出 loss 的权重
# 训练回调函数
# metrics: 各输出精度评价函数
# train_rpn: 是否要从头开始训练 RPN 网络, 如果不是, 则是加载了预训练模型
class TrainCallback(keras.callbacks.Callback):def __init__(self, metrics, train_rpn = True, **kwargs):self.train_rpn = train_rpnself.metrics = metricssuper(TrainCallback, self).__init__(**kwargs)def on_epoch_begin(self, epoch, logs = None):# 如果从头开始学习, 则 base = 0, 此时 epoch 正常计算# 如果加载了 RPN 预训练模型, 则 base 为 RPN 训练的 epoch 数量# 64 - base 相当于 epoch 为 0, 同理 80 - ofst 相当于 epoch 为 16base = 64 if self.train_rpn else 0# 是否显示各层 trainable 参数show_trainable = Falselayer_names = [layer.name for layer in self.model.layers]if self.train_rpn:if 0 == epoch:show_trainable = True# 冻结从 rpn_reg 到后面所有层, 只训练 RPN 分类start = layer_names.index("rpn_reg")end = len(layer_names)self.freeze_layers(self.model, [i for i in range(start, end)], True)# loss_weights 中将暂时不训练的输出 weight 设置为 0self.model.compile(optimizer = self.model.optimizer,loss = self.model.loss,loss_weights = [1.0, 0.0, 0.0, 0.0],metrics = self.metrics)elif 32 == epoch:show_trainable = True# 解冻 rpn_reg, 训练整个 RPN 网络self.freeze_layers(self.model, "rpn_reg", False)# 将 loss_weights 中 rpn_reg 对应的 weight 设置为 10.0self.model.compile(optimizer = self.model.optimizer,loss = self.model.loss,loss_weights = [1.0, 10.0, 0.0, 0.0],metrics = self.metrics)elif 0 <= epoch - base < 32:show_trainable = True if 0 == epoch - base:# 到这里 RPN 已训练完毕, 将 RPN 相关的层冻结proposal = layer_names.index("proposal")self.freeze_layers(self.model, [i for i in range(proposal)], True)# 解冻 RCNN 相关层end = len(layer_names)self.freeze_layers(self.model, [i for i in range(proposal, end)], False)# 交替训练 RCNN 分类与回归self.freeze_layers(self.model, ["rcnn_reg" if 0 == epoch % 2 else "rcnn_cls"], True)self.freeze_layers(self.model, ["rcnn_cls" if 0 == epoch % 2 else "rcnn_reg"], False)self.model.compile(optimizer = self.model.optimizer,loss = self.model.loss,loss_weights = [1.0, 10.0, 1.0, 10.0],metrics = self.metrics)elif 32 == epoch - base:show_trainable = True# 交替训练完成后, 将 rcnn_cls 和 rcnn_reg 解冻, 分类和回归一起训练self.freeze_layers(self.model, ["rcnn_cls", "rcnn_reg"], False)self.model.compile(optimizer = self.model.optimizer,loss = self.model.loss,loss_weights = [1.0, 10.0, 1.0, 10.0],metrics = self.metrics)elif 48 == epoch - base:show_trainable = True# 解冻 RPN 网络, 整个模型一起训练proposal = layer_names.index("proposal")self.freeze_layers(self.model, [i for i in range(proposal)], False)self.model.compile(optimizer = keras.optimizers.Adam(learning_rate = 1e-5),loss = self.model.loss,loss_weights = [1.0, 10.0, 1.0, 10.0],metrics = self.metrics)if show_trainable:for i, layer in enumerate(self.model.layers):print("%.2d" % i, layer.name, "trainable:", layer.trainable)# 冻结 layers# layers: 需要冻结的层的 name 或者序号# freeze: True 表示冻结, False 表示解冻def freeze_layers(self, model, layers, freeze):if not isinstance(layers, (tuple, list)):layers = [layers]for each in layers:if isinstance(each, str):model.get_layer(each).trainable = not freezeelse:model.get_layer(index = each).trainable = not freeze
这个回调函数也很简单, 就是在每个 epoch 开始的时候, 判断是否要冻结不想训练的层, 并修改相应的 loss_weights, 当 loss_weight 修改为 0 时, 相应的 loss 对总的 loss 就没有影响了, 参数更新只受 loss_weight 不为 0 的层影响
还有一个 train_rpn 参数, 如果不想从头开始训练, 则可以加载 保姆级 Keras 实现 Faster R-CNN 八 中训练好的 RPN 参数进行训练, 效果是一样的
现在 train 函数修改如下
# 训练模型
# augment_fun: 数据增强函数
# augmented_num: 一张图像增强后的数量, 默认只有翻转, 所以是 4
# trained_weight: 加载序训练模型路径
def train(self, epochs = 128, batch_size = 4,augment_fun = None, augmented_num = 4, trained_weights = None):if None == augment_fun:augment_fun = self.data_augment# 加载预训练参数if trained_weights:self.model.load_weights(trained_weights, True)train_reader = self.input_reader(self.train_set, batch_size = batch_size,augment_fun = augment_fun, train_num = self.train_num)valid_reader = self.input_reader(self.valid_set, batch_size = batch_size,augment_fun = augment_fun, train_num = self.train_num)steps_per_epoch = len(self.train_set) * augmented_num // batch_sizevalidation_steps = max(1, len(self.valid_set) * augmented_num // batch_size)metrics = {"rpn_cls": self.rpn_cls_acc,"rpn_reg": self.rpn_reg_acc,"class": self.rcnn_cls_acc,"regression": self.rcnn_reg_acc}callbacks = [TrainCallback(metrics, None == trained_weights)]history = self.model.fit(train_reader,steps_per_epoch = steps_per_epoch,epochs = epochs,verbose = 1,validation_data = valid_reader,validation_steps = validation_steps,callbacks = callbacks,max_queue_size = 8,workers = 1)
修改后增加预训练的 trained_weight 和 callbacks 需要的参数, 如果从头开始训练的话, 调用方式如下
# 训练模型
faster_rcnn.train(epochs = 128, batch_size = 4)
如果是加载 RPN 训练好的参数, 可以这样调用
# 训练模型
faster_rcnn.train(epochs = 64, batch_size = 4,trained_weights = osp.join(faster_rcnn.log_path, "trained_weights.h5"))
经过上面的修改, 开始就只训练 RPN 分类, 总的 loss 等于 rpn_cls_loss, 其他冻结的层不起作用. 这样训练下去就不会卡住了
Epoch 1/128
00 input_image trainable: False
01 vgg16_x1_1 trainable: True
02 vgg16_x1_2 trainable: True
03 max_pooling2d_1 trainable: True
04 vgg16_x2_1 trainable: True
05 vgg16_x2_2 trainable: True
06 max_pooling2d_2 trainable: True
07 vgg16_x3_1 trainable: True
08 vgg16_x3_2 trainable: True
09 vgg16_x3_3 trainable: True
10 max_pooling2d_3 trainable: True
11 vgg16_x4_1 trainable: True
12 vgg16_x4_2 trainable: True
13 vgg16_x4_3 trainable: True
14 max_pooling2d_4 trainable: True
15 vgg16_x5_1 trainable: True
16 vgg16_x5_2 trainable: True
17 vgg16_x5_3 trainable: True
18 rpn_conv trainable: True
19 rpn_cls trainable: True
20 rpn_reg trainable: False
21 proposal trainable: False
22 roi_pooling trainable: False
23 roi_flatten trainable: False
24 fc_1 trainable: False
25 fc_2 trainable: False
26 input_classes trainable: False
27 input_boxes trainable: False
28 rcnn_cls trainable: False
29 roi_label trainable: False
30 rcnn_reg trainable: False
31 class trainable: False
32 regression trainable: False4008/4008 [==============================] - 1006s 251ms/step - loss: 0.1498 -
rpn_cls_loss: 0.1498 - rpn_reg_loss: 0.0498 - class_loss: 3.7898 - regression_loss: 0.0215 -
rpn_cls_rpn_cls_acc: 0.9559 - rpn_reg_rpn_reg_acc: 8.2870e-08 - class_rcnn_cls_acc: 0.0019 - regression_rcnn_reg_acc: 0.0513 -
val_loss: 0.1007 - val_rpn_cls_loss: 0.1410 - val_rpn_reg_loss: 0.0417 - val_class_loss: 3.2293 - val_regression_loss: 0.0217 -
val_rpn_cls_rpn_cls_acc: 0.9556 - val_rpn_reg_rpn_reg_acc: 7.8678e-08 - val_class_rcnn_cls_acc: 0.0025 - val_regression_rcnn_reg_acc: 0.0333
经过九九八十一天的训练… …
七. 保存模型与参数
训练完成后需要保存参数, 要不然就白干了
# 保存模型与参数
# file_name: 保存的文件名称
# save_model: 是否要保存模型
# save_weight: 是否要保存参数
def save(self, file_name, save_model = True, save_weight = True):if save_model:self.model.save(osp.join(self.log_path, file_name + "_model.h5"))if save_weight:self.model.save_weights(osp.join(self.log_path, file_name + "_weights.h5"))
需要解释一下 file_name 这个参数, 只需要文件名就可以了, 不用带扩展名. 调用如下
faster_rcnn.save("faster_rcnn", True, True)
在 log_path 路径下会保存两个相应的文件, 预测的时候会用到 faster_rcnn_weights.h5
以上就是整个 Faster R-CNN 从零到训练完成的所有步骤
八. 代码下载
示例代码可下载 Jupyter Notebook 示例代码
上一篇: 保姆级 Keras 实现 Faster R-CNN 十二
下一篇: 保姆级 Keras 实现 Faster R-CNN 十四 (预测)