打开深度学习的锁
- 导言
- PS:神经网络的训练过程
- 一、数据集和包的说明
- 1.1准备文件
- 1.2 需要导入的包
- 二、构建神经网络的架构
- 三、初始化函数
- 四、激活函数
- 4.1 tanh(双曲正切函数)函数
- 五,前向传播
- 六、损失函数
- 七、后向传播
- 八、梯度下降
- 九、构建预测
- 十、聚合和主函数
- 完整代码:
- 总结
导言
本篇知识背景来源于吴恩达教授的DeepLearning课程作业–第三节,有兴趣的同学可以自行搜索。
博客所用到的数据集和测试代码已经公开:GitHub
这篇博客本质内容吴恩达教授的DeepLearning的课程作业第三节,是题解。
有了上次的学习作为引导,这次的练习简单了很多。
这次要做的任务,是构建一个只有一个隐藏层的神经网络。
本次学习用到的数据集-那朵花,是使用随机数生成的。
虽然是随机,不过在生成的时候使用了随机数种子,保证了数据的一致,所以在每一个模块的测试练习的时候,如果你的输出和我的不一样,那就说明代码中存在一些问题。
它们必须一样
好了,开始吧
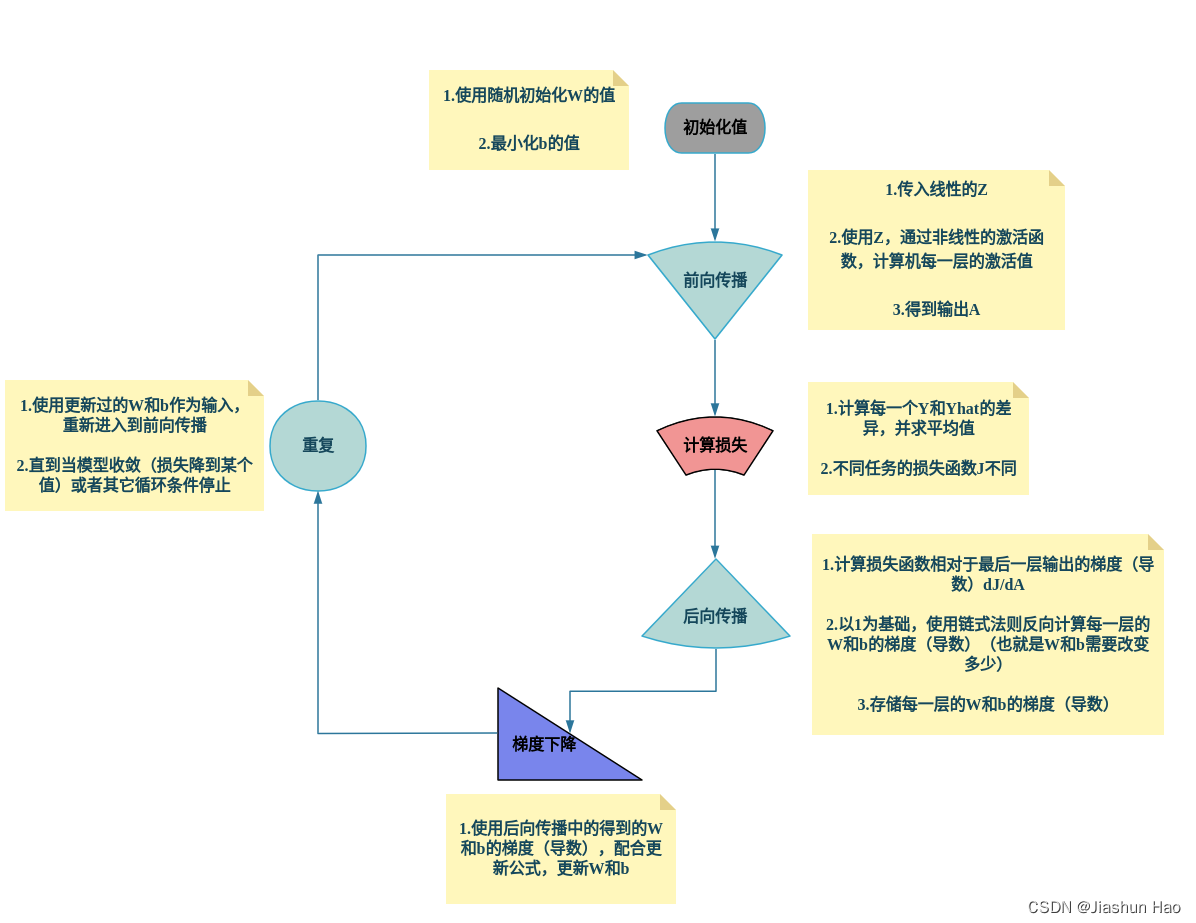
PS:神经网络的训练过程
放此图在这里为了快速认识,也为了需要的时候快速查找。初次看的时候看不懂没关系,可以先看下面的内容。
一、数据集和包的说明
1.1准备文件
本次练习用给到的文件是两个.py文件,别无其他。分别是planar_utils.py和testCases.py。如果一些原因没办法访问Github,可以直接复制代码,如下:
planar_utils.py主要作用就是生成一些随机数,以此来充当数据集。
虽然是随机,不过在生成的时候使用了随机数种子,保证了数据的一致,所以在每一个模块的测试练习的时候,如果你的输出和我的不一样,那就说明代码中存在一些问题。
planar_utils.py:
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.linear_modeldef plot_decision_boundary(model, X, y):"""绘制模型的决策边界。参数:- model: 用于预测数据集输出的函数。- X: 输入数据。- y: 实际标签。"""# 设置最小和最大值并给予一些填充x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1h = 0.01# 生成距离为h的点阵xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))# 预测整个网格的函数值Z = model(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)# 绘制轮廓和训练样本plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)plt.ylabel('x2')plt.xlabel('x1')plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral)def sigmoid(x):"""计算x的sigmoid。参数:- x: 任意大小的标量或numpy数组。返回:s: sigmoid(x)"""s = 1/(1+np.exp(-x))return sdef load_planar_dataset():"""加载2D平面数据集到X和Y。返回:- X: 表示数据点的numpy数组。- Y: 表示标签的numpy数组。"""np.random.seed(1)m = 400 # 样本数量N = int(m/2) # 每个类别的点数D = 2 # 维度X = np.zeros((m,D)) # 每行为一个单独的例子的数据矩阵Y = np.zeros((m,1), dtype='uint8') # 标签向量 (0为红色, 1为蓝色)a = 4 # 花的最大半径for j in range(2):ix = range(N*j,N*(j+1))t = np.linspace(j*3.12,(j+1)*3.12,N) + np.random.randn(N)*0.2 # 角度r = a*np.sin(4*t) + np.random.randn(N)*0.2 # 半径X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]Y[ix] = jX = X.TY = Y.Treturn X, Ydef load_extra_datasets(): """加载额外的数据集。返回:- 不同的合成数据集作为元组 (数据, 标签)。"""N = 200noisy_circles = sklearn.datasets.make_circles(n_samples=N, factor=.5, noise=.3)noisy_moons = sklearn.datasets.make_moons(n_samples=N, noise=.2)blobs = sklearn.datasets.make_blobs(n_samples=N, random_state=5, n_features=2, centers=6)gaussian_quantiles = sklearn.datasets.make_gaussian_quantiles(mean=None, cov=0.5, n_samples=N, n_features=2, n_classes=2, shuffle=True, random_state=None)no_structure = np.random.rand(N, 2), np.random.rand(N, 2)return noisy_circles, noisy_moons, blobs, gaussian_quantiles, no_structuretestCases.py的主要作用是提供了一些用于测试单元的工具,在需要的时候直接调用就可。
testCases.py:
import numpy as npdef layer_sizes_test_case():np.random.seed(1)X_assess = np.random.randn(5, 3)Y_assess = np.random.randn(2, 3)return X_assess, Y_assessdef initialize_parameters_test_case():n_x, n_h, n_y = 2, 4, 1return n_x, n_h, n_ydef forward_propagation_test_case():np.random.seed(1)X_assess = np.random.randn(2, 3)parameters = {'W1': np.array([[-0.00416758, -0.00056267],[-0.02136196, 0.01640271],[-0.01793436, -0.00841747],[ 0.00502881, -0.01245288]]),'W2': np.array([[-0.01057952, -0.00909008, 0.00551454, 0.02292208]]),'b1': np.array([[ 0.],[ 0.],[ 0.],[ 0.]]),'b2': np.array([[ 0.]])}return X_assess, parametersdef compute_cost_test_case():np.random.seed(1)Y_assess = np.random.randn(1, 3)parameters = {'W1': np.array([[-0.00416758, -0.00056267],[-0.02136196, 0.01640271],[-0.01793436, -0.00841747],[ 0.00502881, -0.01245288]]),'W2': np.array([[-0.01057952, -0.00909008, 0.00551454, 0.02292208]]),'b1': np.array([[ 0.],[ 0.],[ 0.],[ 0.]]),'b2': np.array([[ 0.]])}a2 = (np.array([[ 0.5002307 , 0.49985831, 0.50023963]]))return a2, Y_assess, parametersdef backward_propagation_test_case():np.random.seed(1)X_assess = np.random.randn(2, 3)Y_assess = np.random.randn(1, 3)parameters = {'W1': np.array([[-0.00416758, -0.00056267],[-0.02136196, 0.01640271],[-0.01793436, -0.00841747],[ 0.00502881, -0.01245288]]),'W2': np.array([[-0.01057952, -0.00909008, 0.00551454, 0.02292208]]),'b1': np.array([[ 0.],[ 0.],[ 0.],[ 0.]]),'b2': np.array([[ 0.]])}cache = {'A1': np.array([[-0.00616578, 0.0020626 , 0.00349619],[-0.05225116, 0.02725659, -0.02646251],[-0.02009721, 0.0036869 , 0.02883756],[ 0.02152675, -0.01385234, 0.02599885]]),'A2': np.array([[ 0.5002307 , 0.49985831, 0.50023963]]),'Z1': np.array([[-0.00616586, 0.0020626 , 0.0034962 ],[-0.05229879, 0.02726335, -0.02646869],[-0.02009991, 0.00368692, 0.02884556],[ 0.02153007, -0.01385322, 0.02600471]]),'Z2': np.array([[ 0.00092281, -0.00056678, 0.00095853]])}return parameters, cache, X_assess, Y_assessdef update_parameters_test_case():parameters = {'W1': np.array([[-0.00615039, 0.0169021 ],[-0.02311792, 0.03137121],[-0.0169217 , -0.01752545],[ 0.00935436, -0.05018221]]),'W2': np.array([[-0.0104319 , -0.04019007, 0.01607211, 0.04440255]]),'b1': np.array([[ -8.97523455e-07],[ 8.15562092e-06],[ 6.04810633e-07],[ -2.54560700e-06]]),'b2': np.array([[ 9.14954378e-05]])}grads = {'dW1': np.array([[ 0.00023322, -0.00205423],[ 0.00082222, -0.00700776],[-0.00031831, 0.0028636 ],[-0.00092857, 0.00809933]]),'dW2': np.array([[ -1.75740039e-05, 3.70231337e-03, -1.25683095e-03,-2.55715317e-03]]),'db1': np.array([[ 1.05570087e-07],[ -3.81814487e-06],[ -1.90155145e-07],[ 5.46467802e-07]]),'db2': np.array([[ -1.08923140e-05]])}return parameters, gradsdef nn_model_test_case():np.random.seed(1)X_assess = np.random.randn(2, 3)Y_assess = np.random.randn(1, 3)return X_assess, Y_assessdef predict_test_case():np.random.seed(1)X_assess = np.random.randn(2, 3)parameters = {'W1': np.array([[-0.00615039, 0.0169021 ],[-0.02311792, 0.03137121],[-0.0169217 , -0.01752545],[ 0.00935436, -0.05018221]]),'W2': np.array([[-0.0104319 , -0.04019007, 0.01607211, 0.04440255]]),'b1': np.array([[ -8.97523455e-07],[ 8.15562092e-06],[ 6.04810633e-07],[ -2.54560700e-06]]),'b2': np.array([[ 9.14954378e-05]])}return parameters, X_assess1.2 需要导入的包
与上一篇相比,除了Numpy和 Matplotlib以外,多了一个sklearn,#scikit-learn,提供了许多常见的机器学习算法的简单和高效的工具,如分类、回归、聚类和降维等。它还包括了用于模型选择和评估的工具,如交叉验证和各种性能指标。
import numpy as np #Python科学计算的一些包
import matplotlib.pyplot as plt #画图
from Week_3_DataSet.testCases import * #测试示例
from Week_3_DataSet.planar_utils import * #一些功能#导数数据挖掘和数据分析的一些包
import sklearn
import sklearn.datasets #它提供了一系列用于测试和学习的数据集。这个模块包含了多种类型的数据集
import sklearn.linear_model #它包含了许多线性模型,这些模型可以用于各种任务,如回归、分类和异常检测。
二、构建神经网络的架构
首先,我们要引入一个新的中间层,隐藏层。
让我们先不考虑损失的计算,也就是现忽略标签 Y Y Y数据集合,单单来讨论 X X X和 Y ^ \hat Y Y^的关系
那么我们现在知道的神经网络结构这样的:
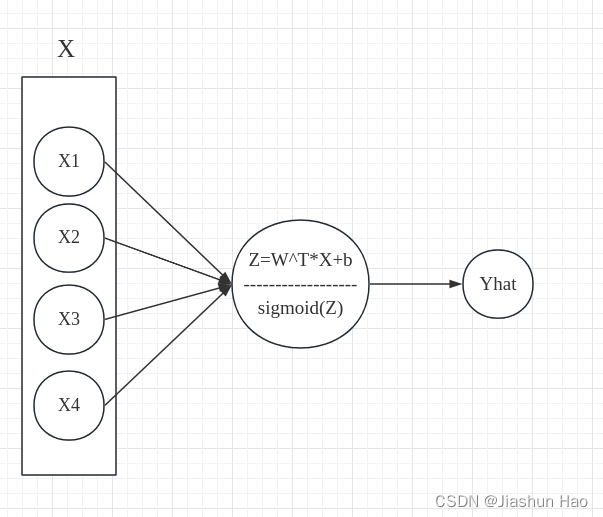
总的来说,就是将特征输入到线性回归+激活函数函数中,得到预测,然后计算损失,然后调整模型参数,然后重复这一过程。
现在,我们添加一个东西,顺便完善一下这个结构
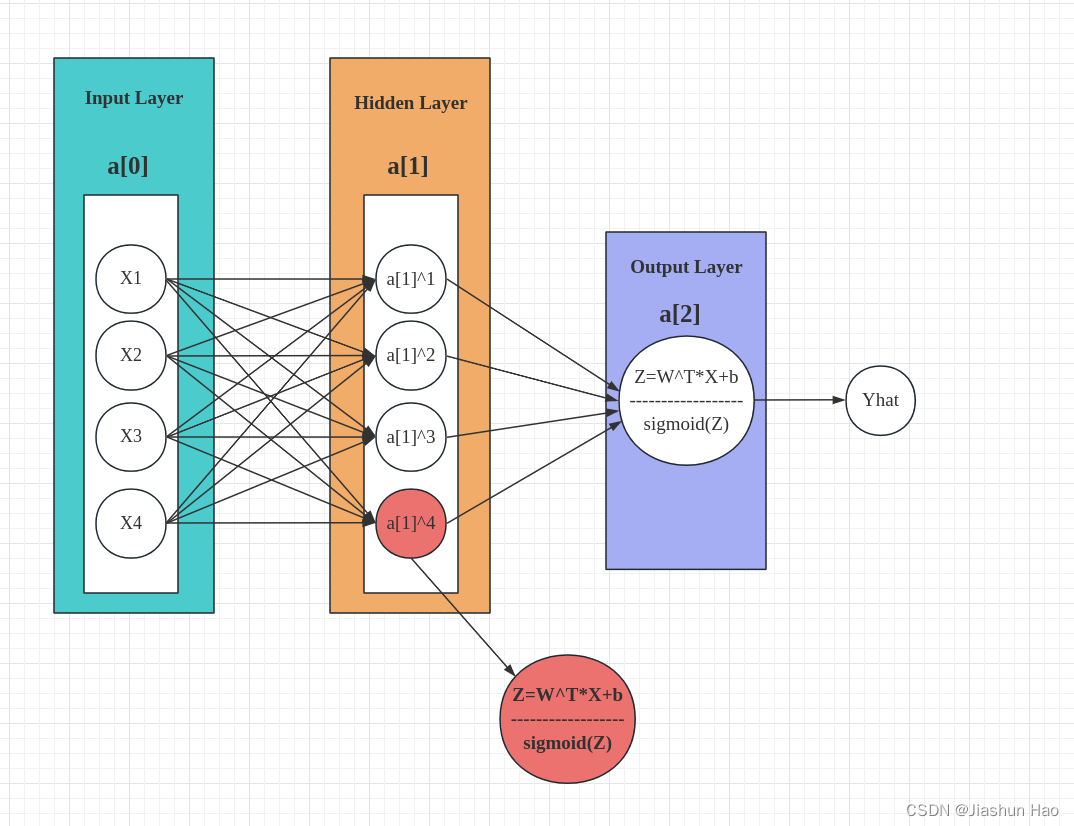
现在,在中间添加了一个层,名字叫隐藏层。
从目前来看,这个层中的元素个数有四个,分别从 a [ 1 ] 1 a[1]^1 a[1]1 到 a [ 1 ] 4 a[1]^4 a[1]4,而这四个节点呢,每一个其实都是一个线性回归+激活函数(线性回归+激活函数也就是逻辑回归)
我们可以看到,输入层中的每一个元素都于这四个元素进行了全链接,如果换个角度来看的话,就是:
在隐藏层中,输入的样本被每一个逻辑回归单元进行了一次预测
然后,我们将隐藏层中得到的预测再次进行拟合,也就是传入到输出层,得到一个最终的 y ^ \hat y y^
所以,通俗的理解来说:添加了隐藏层就是为了对样本进行二次预测处理。
但是, 我可以这么说,但你不能这样想!这个话本是并不是很正确。但是我希望这句话可以让你有一个大概的感觉。
如果你有了,一定要忘记这句话。
那么,隐藏层到底是用来做什么的呢?
在深度学习中,神经网络的隐藏层的作用可以从以下几个方面来理解:
1.特征抽取: 隐藏层可以自动从数据中提取更高级和更复杂的特征。在卷积神经网络(CNN)中,例如,前几层可能会捕获边缘和纹理,而更深的层则可能会捕获更复杂的图案和结构。
2.非线性映射: 通过在隐藏层使用非线性激活函数,神经网络能够学习并表示非线性函数。这使得网络能够逼近几乎任何复杂的函数。
3.抽象表示: 在很多任务中,隐藏层提供了一种抽象表示的能力,这意味着每一层都在将数据转化为一种更加抽象和通用的表示。例如,在自然语言处理任务中,深层网络的早期层可能关注于单词和短语,而后续的层则可能捕获句子或段落的更高级含义。
4.计算层: 隐藏层提供了更多的计算层,允许网络学习更多的参数和更复杂的结构。这使得网络能够逼近更为复杂的函数。
如果搞不懂这些意义暂时也没关系。只需要知道,我们在编写神经网络对应的函数的时候,我们需要指定输入层、隐藏层、输出层
#1.定义神经网络的结构
def layer_sizes(X,Y):#传入数据集和标签# X:样本集合 维度(数据的特征数量,数据量) 每一个数据有两个特征,即:每一个点有X和Y两个坐标值# Y:标签的集合(标签数量,数据量) 每一个数据有一个标签,即:0/1 == 红/蓝色Input_layer=X.shape[0]#输入层的神经元数量,它等于数据的特征数量,每个数据点有两个特征(x ,y )坐标Hidden_layer=4 #隐藏层单元的数量,设置4Output_layer=Y.shape[0]#,表示输出层只有一个神经元来预测一个标签(0或1)。return (Input_layer,Hidden_layer,Output_layer)#得到神经网络
三、初始化函数
现在,我们可以来构建初始化函数了,也就是对 W W W和 b b b赋值了。这里有两个关键点:
1:初始化最好用随机
2:需要构建的 W W W和 b b b的个数。
第一个我在第一章的时候解释过,随机的 W W W比全0的要好。
但是第二个,为什么要构建 W W W和 b b b的个数呢?因为这个时候的 W W W和 b b b的不止一个。
我们再看一下这张图:
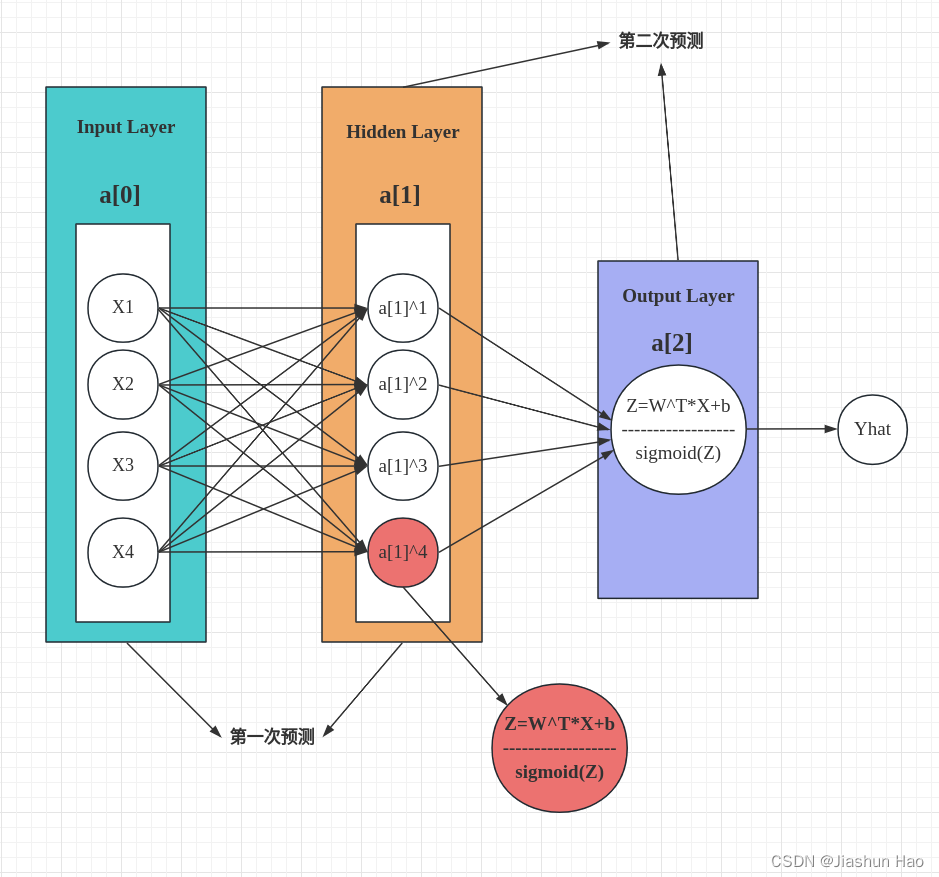
之前说过,添加了隐藏层的神经网络相较于普通的神经网络可以视为是对样本的二次预测,既然要进行两次预测,自然需要两个
W W W和 b b b啦。
对应的公式其实和上一篇没有什么大太变化。
#2.初始化函数
def init_parameters(Input_layer,Hidden_layer,Output_layer):np.random.seed(2) #由于只有一层隐藏层,所以可以显式的写出初始化W1和W2W1=np.random.randn(Hidden_layer,Input_layer)*0.01 #W的维度(当前层的单元数,上一层的单元数)b1=np.zeros(shape=(Hidden_layer,1)) #b的维度(当前层的单元数,1)W2=np.random.randn(Output_layer,Hidden_layer)*0.01b2=np.zeros(shape=(Output_layer,1)) #断言测试个格式assert(W1.shape==(Hidden_layer,Input_layer))assert(b1.shape==( Hidden_layer , 1))assert(W2.shape==(Output_layer,Hidden_layer))assert(b2.shape==(Output_layer,1))parameters ={"W1":W1,"b1":b1,"W2":W2,"b2":b2}return parameters
四、激活函数
激活函数是做什么的呢?
用一句话来说就是:
转化线性函数的为非线性函数,使得模型具有更多的功能。 转化线性函数的为非线性函数,使得模型具有更多的功能。 转化线性函数的为非线性函数,使得模型具有更多的功能。
对了,还有一句话,别问为什么,记住就行————
除了用于二分类任务最后的输出,否则不要用 s i g m o i d 函数 除了用于二分类任务最后的输出,否则不要用sigmoid函数 除了用于二分类任务最后的输出,否则不要用sigmoid函数
不用 s i g m o i d sigmoid sigmoid用什么呢?
让我来介绍另外一种激活函数: t a n h tanh tanh函数
4.1 tanh(双曲正切函数)函数
关于tanh函数,它的图像是这样的:上趋近于1,下趋近于-1
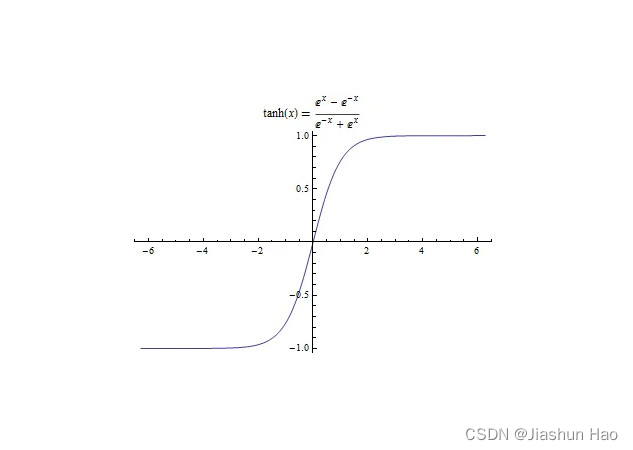
由于 t a n h tanh tanh函数的输出值位于-1到1之间。这意味着它会将输入值归一化到这个范围内,所以如果我们想控制和规范神经元的输出值,我们可以选择这个函数。
在这道题中,为了练习。对于第一个激活函数,我选择使用了 t a n h tanh tanh函数,而之后涉及到最终输出的激活函数,还是需要 s i g m o i d sigmoid sigmoid函数
所以我们需要定义两个激活函数
#3.激活函数
#Numpy里面有thah函数,但是为了练习还是自己写一个吧
def tanh(z): #传入一个线性的函数A=(np.exp(z)-np.exp(-z))/(np.exp(z)+np.exp(-z))return A #A是非线性输出#因为是二分类任务,所以对于最后的结果输出一定要用sigmoid函数
def sigmoid(z):A=1/(1+np.exp(-z))return A
五,前向传播
相较于上一篇文章提到的公式。有隐藏层的神经网络的公式由很大的改动:
假设: N x Nx Nx =( N [ 0 ] N^{\left[0\right]} N[0], N [ 1 ] N^{\left[1\right]} N[1], N [ 2 ] N^{\left[2\right]} N[2])
N [ 0 ] N^{\left[0\right]} N[0]:输入特征的个数;
N [ 1 ] N^{\left[1\right]} N[1]:隐藏单元的个数;
N [ 2 ] N^{\left[2\right]} N[2]:输出特征的个数;
此外,给定单层神经网络的逻辑回归方程:
隐藏层:
Z [ 1 ] = W [ 1 ] X + b [ 1 ] Z^{\left[1\right]}=W^{\left[1\right]}X+b^{\left[1\right]} Z[1]=W[1]X+b[1]
A [ 1 ] = g [ 1 ] ( Z [ 1 ] ) A^{\left[1\right]}=g^{\left[1\right]}(Z^{\left[1\right]}) A[1]=g[1](Z[1])
// 其中 Z [ 1 ] Z^{\left[1\right]} Z[1]是输入的线性函数的输出, A [ 1 ] A^{\left[1\right]} A[1]是 Z [ 1 ] Z^{\left[1\right]} Z[1]进过 非线性函数变换 以后的 输出
W [ 1 ] W^{\left[1\right]} W[1]的维度为( N [ 1 ] N^{\left[1\right]} N[1], N [ 0 ] N^{\left[0\right]} N[0])
b [ 1 ] b^{\left[1\right]} b[1]的维度为( N [ 1 ] N^{\left[1\right]} N[1], 1 1 1)
输出层:
Z [ 2 ] = W [ 2 ] A [ 1 ] + b [ 2 ] Z^{\left[2\right]}=W^{\left[2\right]}A^{\left[1\right]}+b^{\left[2\right]} Z[2]=W[2]A[1]+b[2]
A [ 2 ] = g [ 2 ] ( Z [ 2 ] ) A^{\left[2\right]}=g^{\left[2\right]}(Z^{\left[2\right]}) A[2]=g[2](Z[2])
W [ 2 ] W^{\left[2\right]} W[2]的维度为( N [ 2 ] N^{\left[2\right]} N[2], N [ 1 ] N^{\left[1\right]} N[1])
b [ 2 ] b^{\left[2\right]} b[2]的维度为( N [ 2 ] N^{\left[2\right]} N[2], 1 1 1)
// 其中 Z [ 2 ] Z^{\left[2\right]} Z[2]是 非线性输出 A [ 1 ] A^{\left[1\right]} A[1] 添加上当前的 权重 W [ 1 ] W^{\left[1\right]} W[1]和偏差 b [ 1 ] b^{\left[1\right]} b[1] 所构成的线性输出。
A [ 2 ] A^{\left[2\right]} A[2]是 Z [ 2 ] Z^{\left[2\right]} Z[2]经过 非线性函数变换 以后的 最终输出,也就是预测结果 y ^ \hat y y^
知道公式以后,代码很好写:
#4.构建前向传播(不用Y)
def propagate(X,parameters):W1=parameters["W1"]b1=parameters["b1"]W2=parameters["W2"]b2=parameters["b2"]Z1=np.dot(W1,X)+b1#使用tanh函数聚合值A1=tanh(Z1)#输出层计算Z2=np.dot(W2,A1)+b2#因为是二分类任务,所以对于最后的结果输出一定要用sigmoid函数A2=sigmoid(Z2) #A2就是最后的输出cache={"Z1":Z1,"A1":A1,"Z2":Z2,"A2":A2}return (A2,cache)# #测试forward_propagation
# print("=========================测试forward_propagation=========================")
# X_assess, parameters = forward_propagation_test_case()
# A2, cache = propagate(X_assess, parameters)
# print(np.mean(cache["Z1"]), np.mean(cache["A1"]), np.mean(cache["Z2"]), np.mean(cache["A2"]))
测试结果:

六、损失函数
根据任务的不同,所用到的损失函数也不同。
关于当前这道题,我们处理的内容还是二分类问题。所以损失函数没有太大的变化
对于单个样本:
二元交叉熵损失函数(Binary Cross-Entropy Loss,也称为log loss)
L o s s = L ( y , y ^ ) = − [ y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) ] Loss=L(y, \hat{y}) = -[y \log(\hat{y}) + (1 - y) \log(1 - \hat{y})] Loss=L(y,y^)=−[ylog(y^)+(1−y)log(1−y^)]
对于神经网络损失的计算:
损失函数(Cost Function / Loss Function)
J ( w [ 1 ] , b [ 1 ] , w [ 2 ] , b [ 2 ] ) = 1 m ∑ i = 1 m L ( y ( i ) , y ^ ( i ) ) J(w^{\left[1\right]}, b^{\left[1\right]},w^{\left[2\right]}, b^{\left[2\right]}) = \frac{1}{m} \sum_{i=1}^{m} \text{L}(y^{(i)}, \hat{y}^{(i)}) J(w[1],b[1],w[2],b[2])=m1i=1∑mL(y(i),y^(i))
或者也可以使用 A [ 2 ] A^{\left[2\right]} A[2] 代替 y ^ ( i ) \hat{y}^(i) y^(i)
J ( w [ 1 ] , b [ 1 ] , w [ 2 ] , b [ 2 ] ) = 1 m ∑ i = 1 m L ( y ( i ) , A [ 2 ] ( i ) ) J(w^{\left[1\right]}, b^{\left[1\right]},w^{\left[2\right]}, b^{\left[2\right]}) = \frac{1}{m} \sum_{i=1}^{m} \text{L}(y^{(i)}, A^{\left[2](i\right)}) J(w[1],b[1],w[2],b[2])=m1i=1∑mL(y(i),A[2](i))
在深度学习中,我们需要找合适的 w w w和 b b b,尽可能的缩小 J ( w , b ) J(w,b) J(w,b)
代码:
#5.损失函数构建
# 首先,A2是输出的结果,也就是预测,也就是Yhat,
# 其次,我们需要真实的标签Y
def Cost_Func(A2,Y):m=Y.shape[1] #总数据数sum_cost=-(np.multiply(np.log(A2),Y)+np.multiply(np.log(1-A2),(1-Y))) cost=np.sum(sum_cost)/m#当前通过矩阵计算的得到的应该还是一个矩阵,这个不行,我们需要一个数cost=float(np.squeeze(cost))return cost# #测试compute_cost
# print("=========================测试compute_cost=========================")
# A2 , Y_assess , parameters = compute_cost_test_case()
# print("cost = " + str(Cost_Func(A2,Y_assess)))
测试结果:

七、后向传播
所谓后向传播,就是计算 W W W和 b b b需要改变多少,只是计算,不改变。改变是梯度下降的事情。
如果想玩后向传播就必须学会导数!
可是我不会导数呀?不能玩吗?
…也能, 这样吧,我给你导完以后的公式,你直接用,别问为什么就行。
后向传播公式(其中的Y是(1,m)的标签集):
d Z [ 2 ] = A [ 2 ] − Y dZ^{\left[2\right]}=A^{\left[2\right]}-Y dZ[2]=A[2]−Y
d W [ 2 ] = 1 m d Z [ 2 ] A [ 1 ] T dW^{\left[2\right]}=\frac{1}{m}dZ^{\left[2\right]}A^{\left[1\right]T} dW[2]=m1dZ[2]A[1]T
d b [ 2 ] = 1 m n p . s u m ( d z [ 2 ] , a x i s = 1 , k e e p d i m s = T r u e ) db^{\left[2\right]}=\frac{1}{m}np.sum(dz^{\left[2\right]}, axis=1, keepdims=True) db[2]=m1np.sum(dz[2],axis=1,keepdims=True)
d Z [ 1 ] = W [ 2 ] T d Z [ 2 ] ∗ g [ Z ] ′ dZ^{\left[1\right]}=W^{\left[2\right]T}dZ^{\left[2\right]}*g^{\left[Z\right]'} dZ[1]=W[2]TdZ[2]∗g[Z]′
d W [ 1 ] = 1 m d Z [ 1 ] X T dW^{\left[1\right]}=\frac{1}{m}dZ^{\left[1\right]}X^T dW[1]=m1dZ[1]XT
d b [ 1 ] = 1 m n p . s u m ( d z [ 1 ] , a x i s = 1 , k e e p d i m s = T r u e ) db^{\left[1\right]}=\frac{1}{m}np.sum(dz^{\left[1\right]}, axis=1, keepdims=True) db[1]=m1np.sum(dz[1],axis=1,keepdims=True)
代码:
#后向传播
#首先,我们需要损失函数想相较于最后一层输出的导数
#我们还需要使用链式法则计算每一层的W和b的梯度
def back_propagtion(parameters,cache,X,Y):m=Y.shape[1] #总数据数W1=parameters["W1"]W2=parameters["W2"]A1=cache["A1"]A2=cache["A2"]#就算损失函数较于最后一层输出的导数dz#带入公式就好dZ2=A2-YdW2=(1/m) *(np.dot(dZ2,A1.T))db2=(1/m) * np.sum(dZ2,axis=1,keepdims=True)#使用公式 g`(z)=1-a^2dZ1=np.dot(W2.T,dZ2)*(1-np.power(A1,2))dW1=(1/m)*np.dot(dZ1,X.T)db1=(1/m)*np.sum(dZ1,axis=1,keepdims=True)back_con={"dW1":dW1,"dW2":dW2,"db2":db2,"db1":db1}return back_con
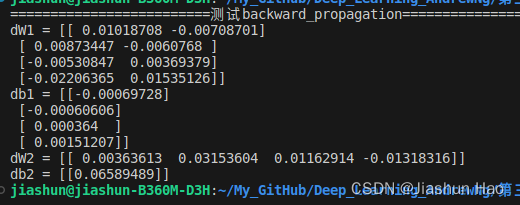
# #测试backward_propagation
# print("=========================测试backward_propagation=========================")
# parameters, cache, X_assess, Y_assess = backward_propagation_test_case()# grads = back_propagtion(parameters, cache, X_assess, Y_assess)
# print ("dW1 = "+ str(grads["dW1"]))
# print ("db1 = "+ str(grads["db1"]))
# print ("dW2 = "+ str(grads["dW2"]))
# print ("db2 = "+ str(grads["db2"]))
测试结果:
八、梯度下降
更新 W W W和 b b b,其中 α \alpha \frac{}{} α是学习率
公式:
w = w − α ∂ J ∂ w w = w - \alpha \frac{\partial J}{\partial w} w=w−α∂w∂J
b = b − α ∂ J ∂ b b = b - \alpha \frac{\partial J}{\partial b} b=b−α∂b∂J
代码:
#梯度下降,也就是更新参数
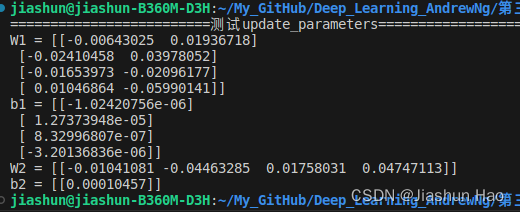
def update_parameter(parameters,back_con,learning_rate=1.2):#原数据W1,W2=parameters["W1"],parameters["W2"]b1,b2=parameters["b1"],parameters["b2"]#它们的导数dW1,dW2,db1,db2=back_con["dW1"],back_con["dW2"],back_con["db1"],back_con["db2"]W1=W1-learning_rate*dW1b1=b1-learning_rate*db1W2=W2-learning_rate*dW2b2=b2-learning_rate*db2update ={"W1":W1,"b1":b1,"W2":W2,"b2":b2}return update# #测试update_parameters
# print("=========================测试update_parameters=========================")
# parameters, grads = update_parameters_test_case()
# parameters = update_parameter(parameters, grads)# print("W1 = " + str(parameters["W1"]))
# print("b1 = " + str(parameters["b1"]))
# print("W2 = " + str(parameters["W2"]))
# print("b2 = " + str(parameters["b2"]))
测试结果:
九、构建预测
这一步很关键,我们要使用 X X X来生成预测,与它们的标签 Y Y Y来进行拟合。
上一篇中没有把它们单独拿出来,看起来有点乱有点难理解,这一次单独提出来。
#构建预测
def predict(parameters,X):#parameters - 包含参数的字典类型的变量。#X - 输入数据(n_x,m)A2,cache=propagate(X,parameters)predic=np.round(A2)return predic
# #测试predict
# print("=========================测试predict=========================")# parameters, X_assess = predict_test_case()
# predictions = predict(parameters, X_assess)
# print("预测的平均值 = " + str(np.mean(predictions)))
测试结果:

十、聚合和主函数
好了,所有的功能都写完了。接下来写一个聚合它们的函数就可以了。
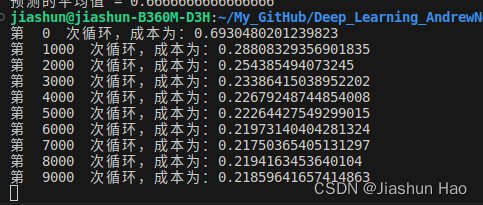
def model(X,Y,num_iterations,print_cost=False):np.random.seed(3)#开始初始化Input_layer=layer_sizes(X,Y)[0] #导入输入层、隐藏层和输出层Hidden_layer=layer_sizes(X,Y)[1]Output_layer=layer_sizes(X,Y)[2]parameters=init_parameters(Input_layer,Hidden_layer,Output_layer)W1=parameters["W1"]W2=parameters["W2"]b1=parameters["b1"]b2=parameters["b2"]#初始化完成,开始神经网络for i in range(num_iterations):#前向传播,得到最后一个非线性输出结果和其它结果A2,cache=propagate(X,parameters)#计算损失cost=Cost_Func(A2,Y)#后向传播back_con=back_propagtion(parameters,cache,X,Y)#梯度下降/更新parametersparameters=update_parameter(parameters,back_con)#1000次打印if print_cost:if i%1000 == 0:print("第 ",i," 次循环,成本为:"+str(cost))#循环结束,返回最后的值return parameters
主函数:
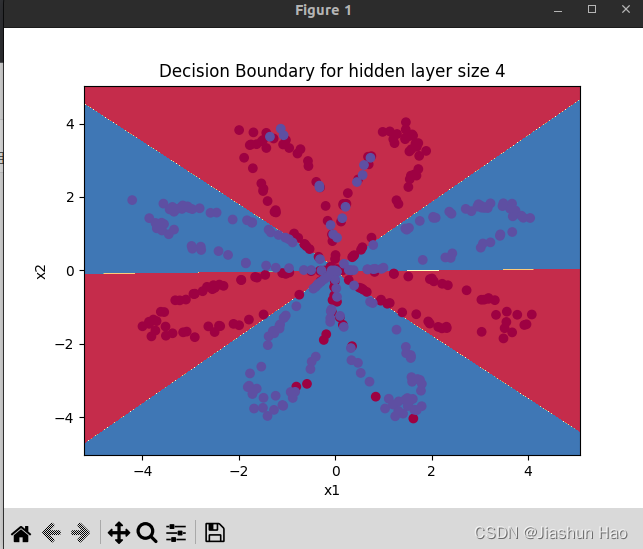
def main():X,Y=load_planar_dataset()parameters=model(X,Y,num_iterations=10000,print_cost=True)#draw grapheplot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)plt.title("Decision Boundary for hidden layer size " + str(4))plt.show()predictions = predict(parameters, X)
完整代码:
import numpy as np #Python科学计算的一些包
import matplotlib.pyplot as plt #画图
from Week_3_DataSet.testCases import * #测试示例
from Week_3_DataSet.planar_utils import * #一些功能#scikit-learn提供了许多常见的机器学习算法的简单和高效的工具,如分类、回归、聚类和降维等。它还包括了用于模型选择和评估的工具,如交叉验证和各种性能指标。
#导数数据挖掘和数据分析的一些包
import sklearn
import sklearn.datasets #它提供了一系列用于测试和学习的数据集。这个模块包含了多种类型的数据集
import sklearn.linear_model #它包含了许多线性模型,这些模型可以用于各种任务,如回归、分类和异常检测。#1.定义神经网络的结构
def layer_sizes(X,Y):# X:样本集合 维度(数据的特征数量,数据量) 每一个数据有两个特征,即:每一个点有X和Y两个坐标值# Y:标签的集合(标签数量,数据量) 每一个数据有一个标签,即:0/1 == 红/蓝色Input_layer=X.shape[0]#输入层的神经元数量,它等于数据的特征数量,每个数据点有两个特征(x ,y )坐标Hidden_layer=4 #隐藏层单元的数量,设置4Output_layer=Y.shape[0]#,表示输出层只有一个神经元来预测一个标签(0或1)。return (Input_layer,Hidden_layer,Output_layer)#2.初始化函数
def init_parameters(Input_layer,Hidden_layer,Output_layer):np.random.seed(2) #由于只有一层隐藏层,所以可以显式的写出初始化W1和W2W1=np.random.randn(Hidden_layer,Input_layer)*0.01 #W的维度(当前层的单元数,上一层的单元数)b1=np.zeros(shape=(Hidden_layer,1)) #b的维度(当前层的单元数,1)W2=np.random.randn(Output_layer,Hidden_layer)*0.01b2=np.zeros(shape=(Output_layer,1)) #断言测试个格式assert(W1.shape==(Hidden_layer,Input_layer))assert(b1.shape==( Hidden_layer , 1))assert(W2.shape==(Output_layer,Hidden_layer))assert(b2.shape==(Output_layer,1))parameters ={"W1":W1,"b1":b1,"W2":W2,"b2":b2}return parameters#3.激活函数
#Numpy里面有thah函数,但是为了练习还是自己写一个吧
def tanh(z): #传入一个线性的函数A=(np.exp(z)-np.exp(-z))/(np.exp(z)+np.exp(-z))return A #A是非线性输出#因为是二分类任务,所以对于最后的结果输出一定要用sigmoid函数
def sigmoid(z):A=1/(1+np.exp(-z))return A#4.构建前向传播(不用Y)
def propagate(X,parameters):W1=parameters["W1"]b1=parameters["b1"]W2=parameters["W2"]b2=parameters["b2"]Z1=np.dot(W1,X)+b1A1=tanh(Z1)#输出层计算Z2=np.dot(W2,A1)+b2#因为是二分类任务,所以对于最后的结果输出一定要用sigmoid函数A2=sigmoid(Z2) #A2就是最后的输出cache={"Z1":Z1,"A1":A1,"Z2":Z2,"A2":A2} #为什么要存呢?return (A2,cache)# #测试forward_propagation
# print("=========================测试forward_propagation=========================")
# X_assess, parameters = forward_propagation_test_case()
# A2, cache = propagate(X_assess, parameters)
# print(np.mean(cache["Z1"]), np.mean(cache["A1"]), np.mean(cache["Z2"]), np.mean(cache["A2"]))#5.损失函数构建
# 首先,A2是输出的结果,也就是预测,也就是Yhat,
# 其次,我们需要真实的标签Y
def Cost_Func(A2,Y):m=Y.shape[1] #总数据数sum_cost=-(np.multiply(np.log(A2),Y)+np.multiply(np.log(1-A2),(1-Y))) cost=np.sum(sum_cost)/m#当前通过矩阵计算的得到的应该还是一个矩阵,这个不行,我们需要一个数cost=float(np.squeeze(cost))return cost# #测试compute_cost
# print("=========================测试compute_cost=========================")
# A2 , Y_assess , parameters = compute_cost_test_case()
# print("cost = " + str(Cost_Func(A2,Y_assess)))#后向传播
#首先,我们需要损失函数想相较于最后一层输出的导数
#我们还需要使用链式法则计算每一层的W和b的梯度
def back_propagtion(parameters,cache,X,Y):m=Y.shape[1] #总数据数W1=parameters["W1"]W2=parameters["W2"]A1=cache["A1"]A2=cache["A2"]#就算损失函数较于最后一层输出的导数dz#带入公式就好dZ2=A2-YdW2=(1/m) *(np.dot(dZ2,A1.T))db2=(1/m) * np.sum(dZ2,axis=1,keepdims=True)#使用公式 g`(z)=1-a^2dZ1=np.dot(W2.T,dZ2)*(1-np.power(A1,2))dW1=(1/m)*np.dot(dZ1,X.T)db1=(1/m)*np.sum(dZ1,axis=1,keepdims=True)back_con={"dW1":dW1,"dW2":dW2,"db2":db2,"db1":db1}return back_con
# #测试backward_propagation
# print("=========================测试backward_propagation=========================")
# parameters, cache, X_assess, Y_assess = backward_propagation_test_case()# grads = back_propagtion(parameters, cache, X_assess, Y_assess)
# print ("dW1 = "+ str(grads["dW1"]))
# print ("db1 = "+ str(grads["db1"]))
# print ("dW2 = "+ str(grads["dW2"]))
# print ("db2 = "+ str(grads["db2"]))#梯度下降,也就是更新参数
def update_parameter(parameters,back_con,learning_rate=1.2):#原数据W1,W2=parameters["W1"],parameters["W2"]b1,b2=parameters["b1"],parameters["b2"]#它们的导数dW1,dW2,db1,db2=back_con["dW1"],back_con["dW2"],back_con["db1"],back_con["db2"]W1=W1-learning_rate*dW1b1=b1-learning_rate*db1W2=W2-learning_rate*dW2b2=b2-learning_rate*db2update ={"W1":W1,"b1":b1,"W2":W2,"b2":b2}return update# #测试update_parameters
# print("=========================测试update_parameters=========================")
# parameters, grads = update_parameters_test_case()
# parameters = update_parameter(parameters, grads)# print("W1 = " + str(parameters["W1"]))
# print("b1 = " + str(parameters["b1"]))
# print("W2 = " + str(parameters["W2"]))
# print("b2 = " + str(parameters["b2"]))def model(X,Y,num_iterations,print_cost=False):np.random.seed(3)#开始初始化Input_layer=layer_sizes(X,Y)[0] #导入输入层、隐藏层和输出层Hidden_layer=layer_sizes(X,Y)[1]Output_layer=layer_sizes(X,Y)[2]parameters=init_parameters(Input_layer,Hidden_layer,Output_layer)W1=parameters["W1"]W2=parameters["W2"]b1=parameters["b1"]b2=parameters["b2"]#初始化完成,开始神经网络for i in range(num_iterations):#前向传播,得到最后一个非线性输出结果和其它结果A2,cache=propagate(X,parameters)#计算损失cost=Cost_Func(A2,Y)#后向传播back_con=back_propagtion(parameters,cache,X,Y)#梯度下降/更新parametersparameters=update_parameter(parameters,back_con)#1000次打印if print_cost:if i%1000 == 0:print("第 ",i," 次循环,成本为:"+str(cost))#循环结束,返回最后的值return parameters#构建预测
def predict(parameters,X):#parameters - 包含参数的字典类型的变量。#X - 输入数据(n_x,m)A2,cache=propagate(X,parameters)predic=np.round(A2)return predic
# #测试predict
# print("=========================测试predict=========================")# parameters, X_assess = predict_test_case()
# predictions = predict(parameters, X_assess)
# print("预测的平均值 = " + str(np.mean(predictions)))def main():X,Y=load_planar_dataset()parameters=model(X,Y,num_iterations=10000,print_cost=True)#draw grapheplot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)plt.title("Decision Boundary for hidden layer size " + str(4))plt.show()predictions = predict(parameters, X)# Y=Y*0 改变颜色玩一下# plt.scatter(X[0, :], X[1, :], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral) #绘制散点图# plt.show()# print(X.shape)#(2,400) 点的横坐标和纵坐标# print(Y.shape)#(1,400) 标签,红0蓝1# #原样测试:# plt.scatter(X[0, :], X[1, :], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral) #绘制散点图# plt.show()# #测试:使用自带的函数逻辑回归的线性分割# clf=sklearn.linear_model.LogisticRegressionCV()# clf.fit(X.T,Y.T)# plot_decision_boundary(lambda x: clf.predict(x), X, Y) #绘制决策边界# plt.title("Logistic Regression") #图标题、# plt.show()# LR_predictions = clf.predict(X.T) #预测结果# print(Y.shape)# print(LR_predictions.shape)# print ("逻辑回归的准确性: %d " % float((np.dot(Y, LR_predictions) + # np.dot(1 - Y,1 - LR_predictions)) / float(Y.size) * 100) +# "% " + "(正确标记的数据点所占的百分比)")if __name__ =="__main__":main()
输出结果:
总结
这个人太懒了,什么都没有写~~
疑缺待补