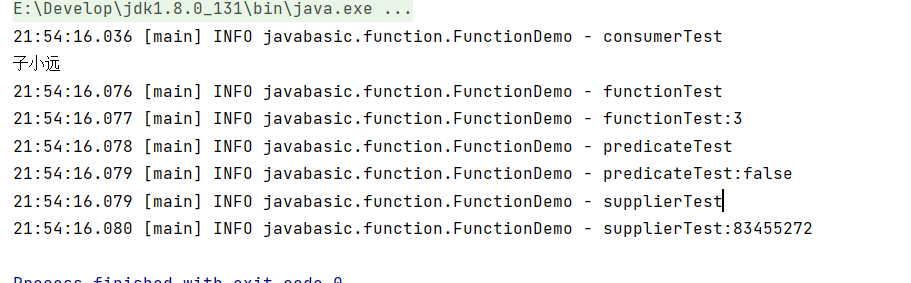
HTTP基本格式
HTTP协议也是日常开发中非常常用的的一种协议,在众多协议栈里HTTP可能是实际开发中用的最多的。
注意
这里说的HTTP是指HTTP1以及HTTP2,他们都是基于TCP协议的,注意:如今最新版的HTTP3是基于UDP的。
但如今在互联网中使用的最多的仍然是HTTP1.1的版本。
在整个协议栈中,上层和下层之间的关系是一定的关联关系的,上层协议要调用下层协议,下层协议要给上层协议提供一个支撑,所以说HTTP作为一个应用层协议,他在进行传输数据的时候,就要基于TCP的这一套机制的保证。
传输层协议,主要关注端对端之间的数据传输,像TCP重点关注可靠传输,
应用层协议则站在程序应用的角度上,来对传输的数据进行具体使用,
一些程序员大能发明了一些很好用的协议,直接让大家照搬,HTTP就是一个典型代表,
HTTP虽然是被设计好的,但自身的拓展性非常强,可根据需要,让程序猿传输各种自定义的数据信息
**HTTP具体的应用场景:**大家天天都在用的浏览器随便打开一个网站,这个时候其实你就用到了HTTP.或者你打开一个手机APP,随便加载一些数据,这个时候其实你大概率也就用到了HTTP。
HTTP协议格式
什么是协议格式:数据具体如何组织.
例如
TCP/UDP/IP这些协议都是属于二进制的协议,经常呀理解到二进制的bit位;
而HTTP则是一个文本格式的协议.文本格式更易于直接去观察;
那么如何看到HTTP的报文格式?
可以借助一些"抓包工具"来获取到具体的HTTP交互过程中的请求和响应.当然,TCP/UDP这些也是可以借助抓包工具来分析的
抓包工具,其实就是一个第三方的程序,在这个网络通信的过程中,类似于代理一样.
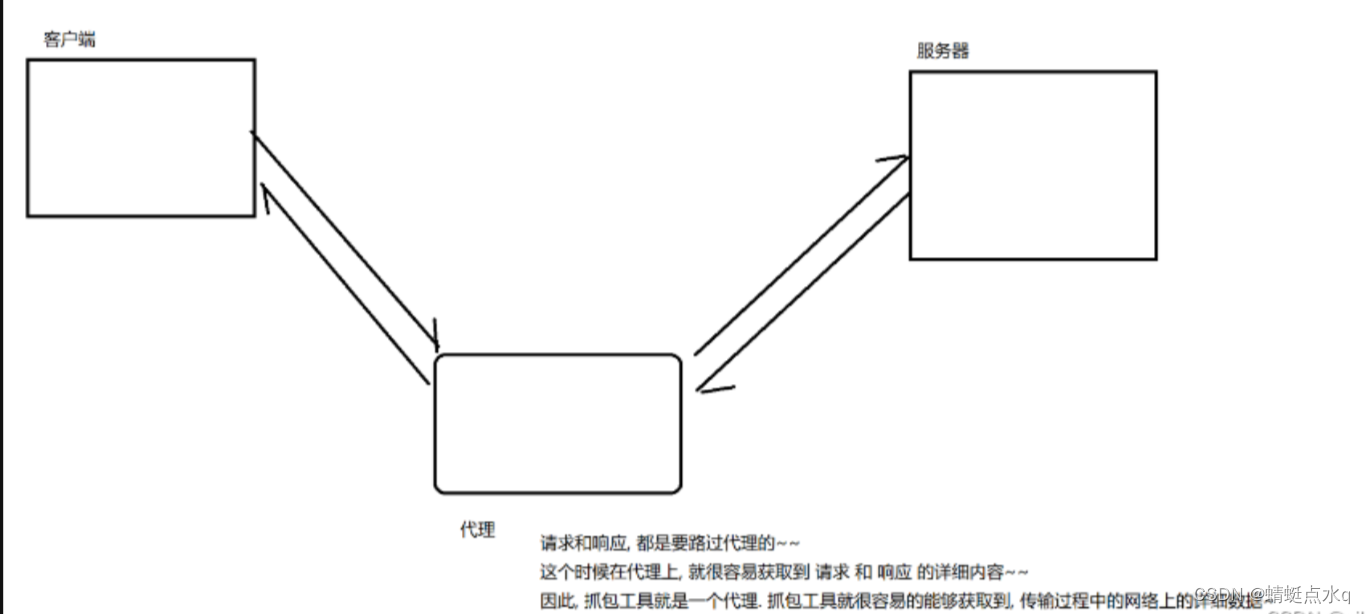
fiddler抓包工具方法
直接去fiddle官网(Fiddler | Web Debugging Proxy and Troubleshooting Solutions)下载一个fiddler,然后打开就可以自动帮你抓包.
注意
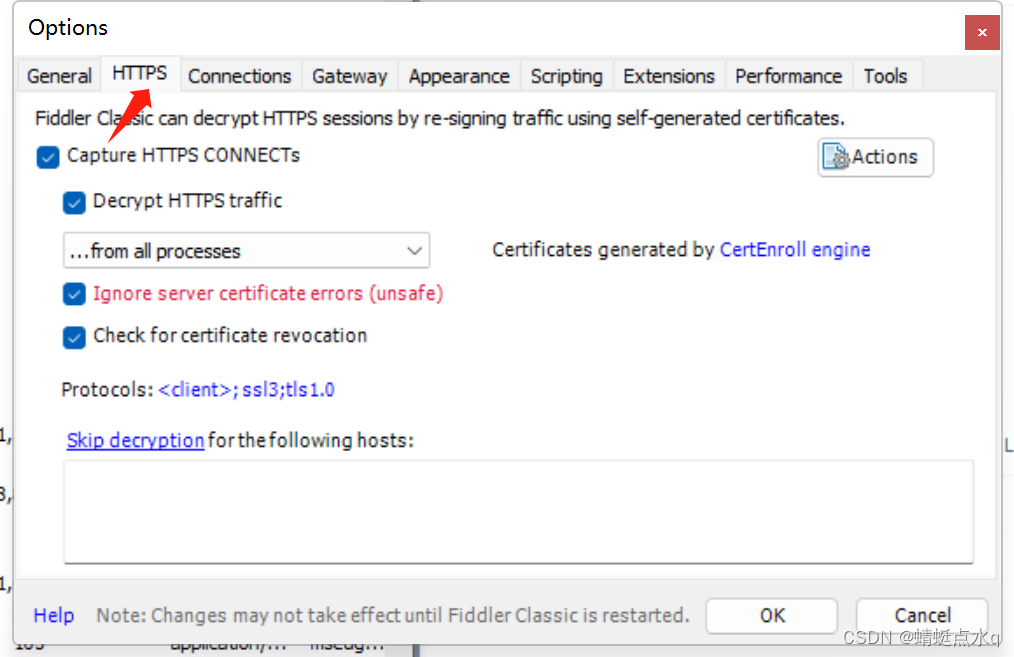
初次打开很可能只显示HTTP协议而不显示HTTPS协议
解决办法:
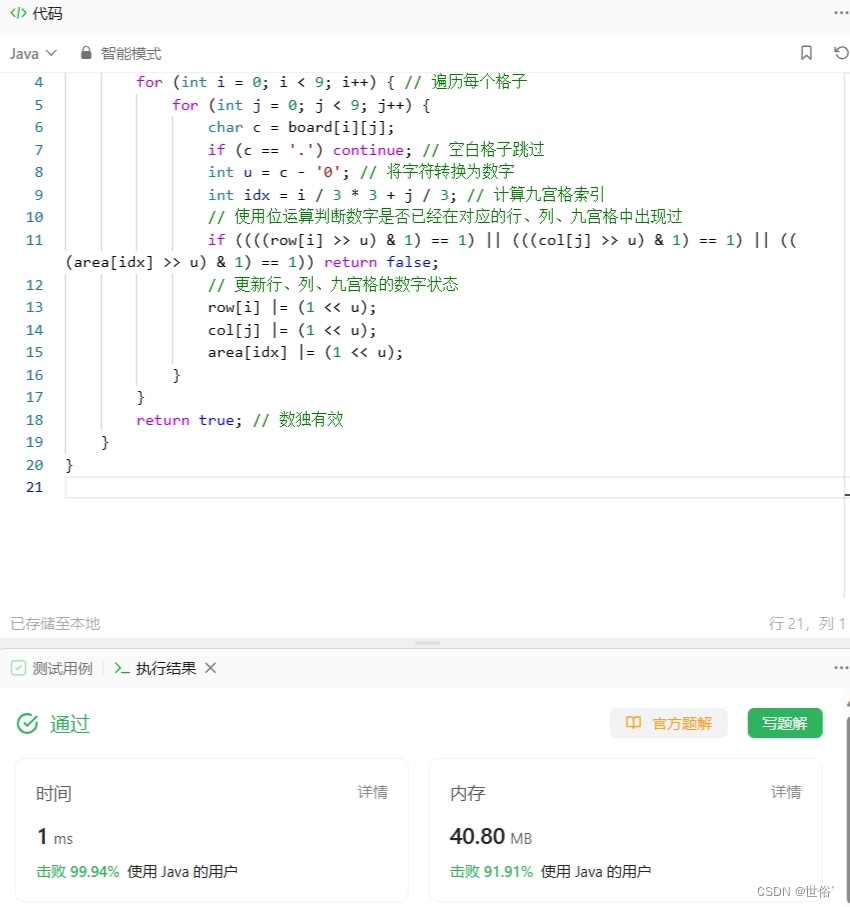
1.点击左上角的Tools
2.点击第一个Options…
3.点击HTTPS
4.像上面的图一样将√打上,如果出现提示,就一直yes
5.最后点击OK,重启就可以了!
6.如果仍有问题欢迎评论私信交流

界面说明
fidder左侧是一个列表,显示当前抓到的所有HTTP/HTTPS的数据报
(HTTPS和HTTP的区别简单来说,就是HTTPS在HTTP的基础上,引入了加密机制)
当选中左侧某个条目双击后,右侧就会显示这个条目的详细信息,如图:
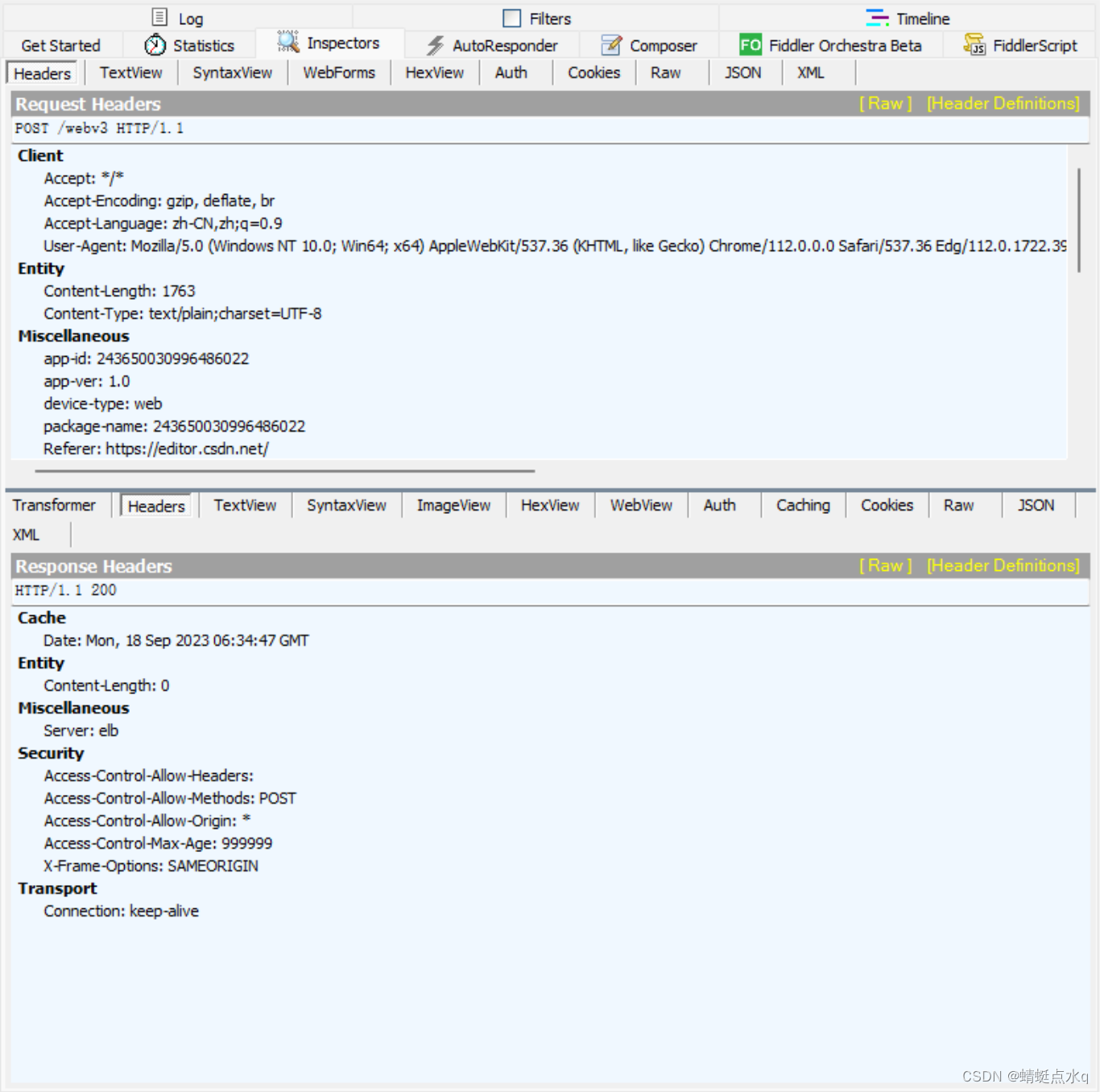
之后在选择Raw这个选项,看到的便是HTTP请求数据的本体,选择其他选项,相当于是fidder对数据进行了一些加工,调整了格式

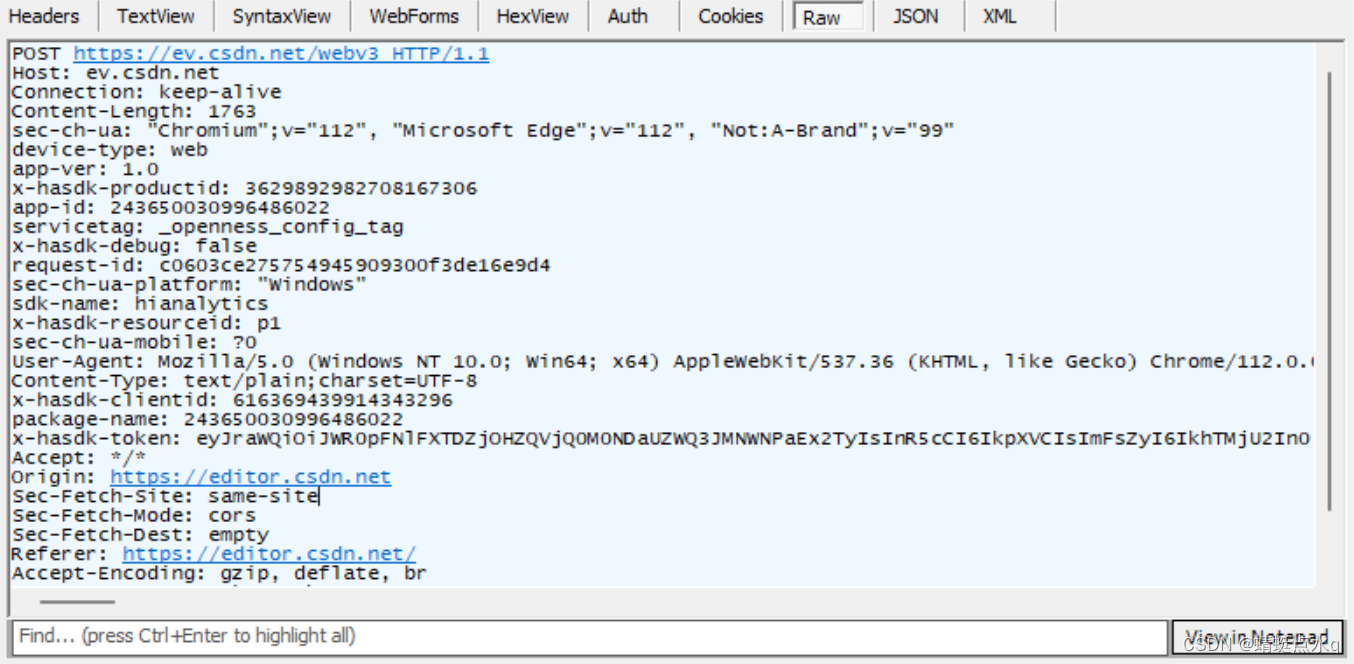
(如果觉得字小,可以点击右下角用记事本打开)

效果展示:
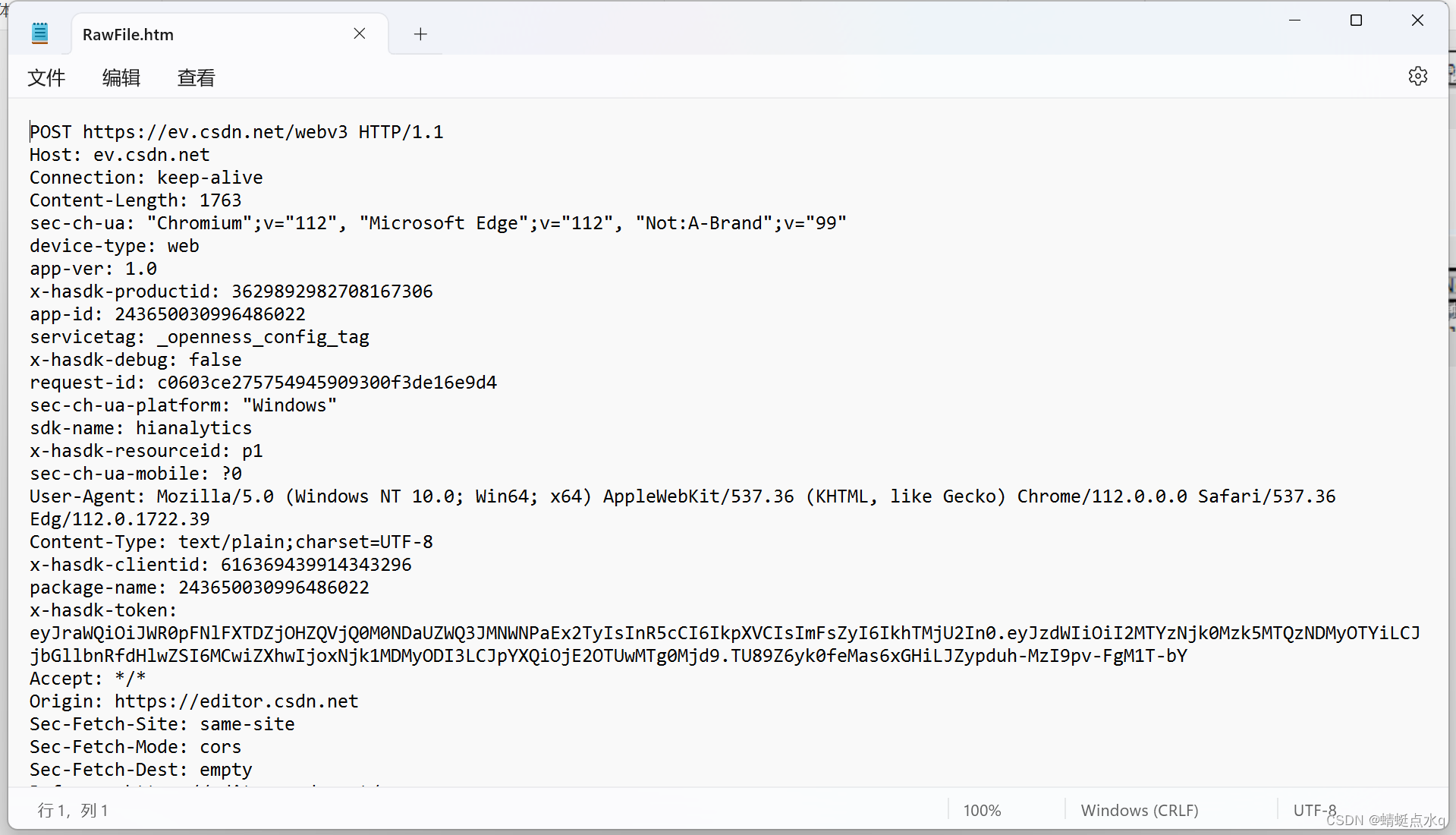
以上就是HTTP请求的原始模样,如果你往TCPsocket中,按照上述格式来构造数据,并写入socket,其实本质上就相当于构造了一个HTTP请求.
在右下那一块,也就是HTTP响应.此处也要选择Raw,才能看到本体.
为什么看到的本体是乱码?
乱码其实是压缩之后的结果
一个服务器,最贵的硬件资源,其实是网络带宽,像这些HTTP响应,经常会很大,就比较占用带宽,为了能够提高效率,经常服务器会放回“压缩之后”的数据,由浏览器收到之后再来解压缩
在我们学会了如何简单使用抓包工具后,我们来随便抓几个研究一下HTTP的协议的格式.
先看HTTP请求:
HTTP请求详解
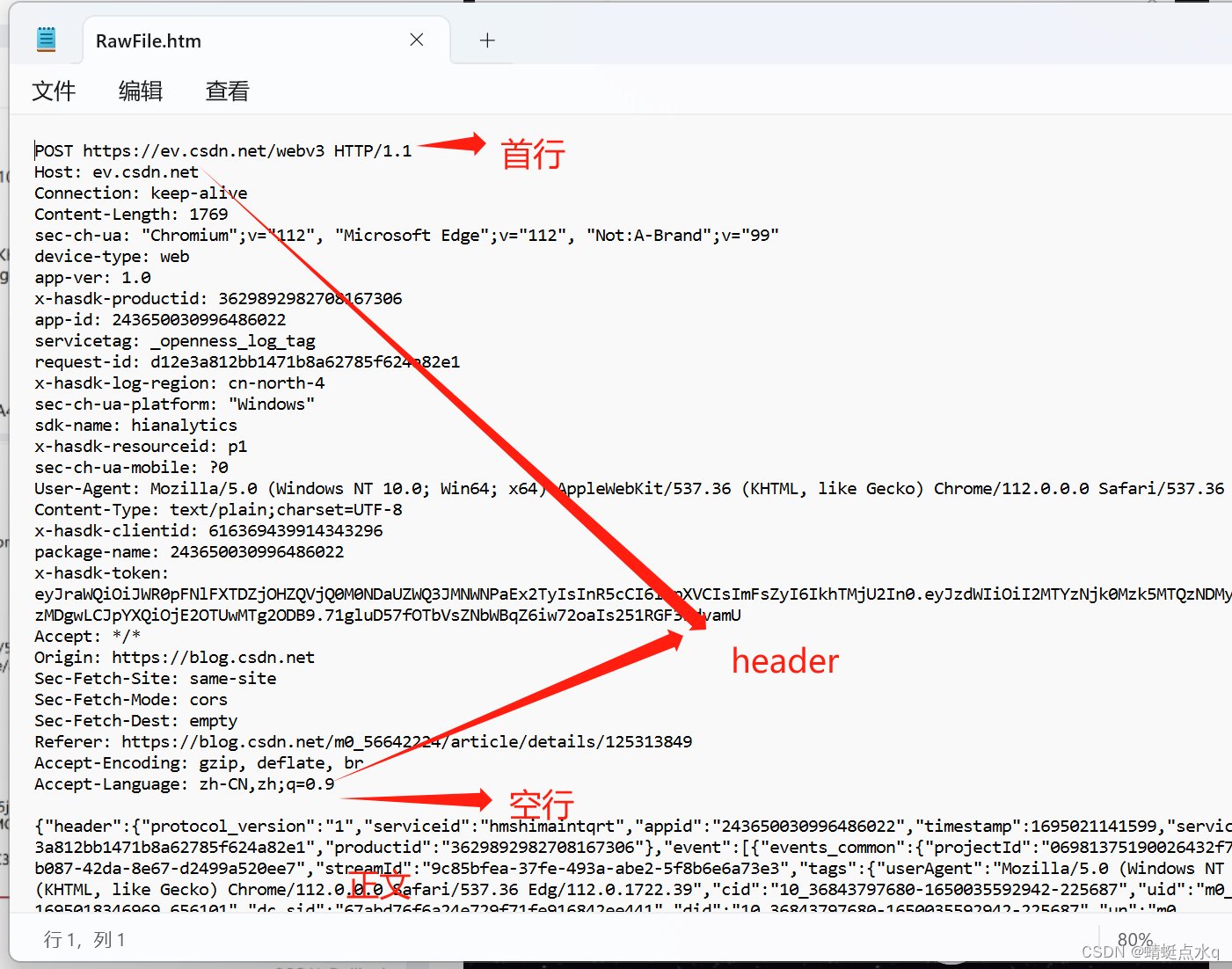
请求行分为四个部分
1.请求行(首行),包含三个部分
a)HTTP的方法,方法大概描述了这个请求想要干什么
b)URL描述了要访问的网络上的资源具体是在哪
c)版本号,HTTP/1.1表示当前使用的HTTP版本是1.1,1.1是目前最流行的版本。
2.请求头(header)包含了很多行,每一行都是一个键值对,键和值之间用空格来分割,这里的键值对个数是不固定的,有可能多也有可能少,不同的键值对,表示的含义也不同
3.空行 ,相当于请求头的结束标记
4.请求正文(body)可选的,不一定会有

下面我们逐个讲解下具体的含义
URL
URL(Uniform Resource Locator,统一资源定位符)是互联网上标准资源的地址(既要明确主机是谁,又要明确具体是主机上的哪个资源),用于指示可以从互联网上得到的资源的位置和访问方法。比如我们打开网页,地址栏里面的这个"网址其实就是URL"
对于URL来说,里面的结构看起来比较复杂,其实最重要的,和我们实际开发最关系紧密的,分为四个部分
1)IP地址/域名
2)端口号(经常是小透明)
3)带层次结构的路径
4)query string查询字符串~~

方法
HTTP协议的方法非常多,但是最最常用的也就是GET和POST方法
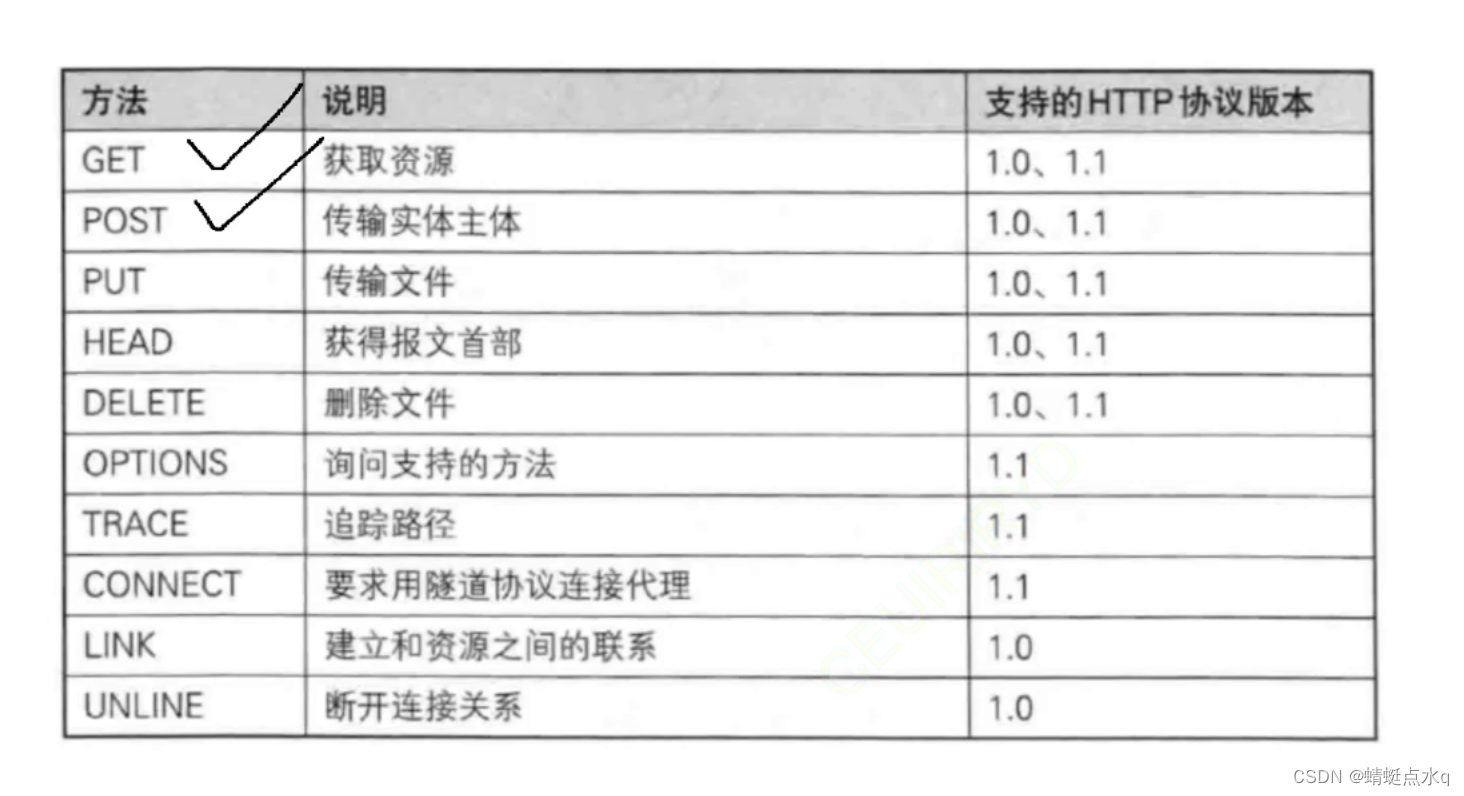
HTTP中引入这些方法,初衷是为了表达不同的含义
像HTML中(h3,p,a,img)这样的语义化标签,(div,span)无语义标签
现在大家写代码,基本都是GET/POST,基本无视掉了语义的事情,正因为如此,也就导致了多种HTTP方法之间的界限,就变得模糊了。
GET也可以给服务器送东西
POST也可以从服务器拿东西
谈谈GET和POST的区别
GET和POST是没有本质的区别的,相当于是GET能使用的场景,也能替换成POST,POST能使用的场景,也能替换成GET
但在细节上还是有一些区别
GET通常用来取数据,POST通常用来上传数据(实际上GET也经常用来上传数据,POST也经常用来获取数据)
通常情况下,GET是没有body,GET通过query string 向服务器传递数据。POST是有body的,POST通过body向服务器传递数据,但是POST 没有query string.
如果我就想让GET有body(自己构造),或者就想让POST带有query sring 也是完全可以的
GET请求一般是幂等的,POST请求一般是不幂等的
GET可以被缓存,POST不能被缓存,相当于提前把结果记住了.如果是幂等的,可以节省了下次访问的开销
header
header里面都是一些键值对,不同的键值对代表不同的含义,这里的种类非常多且杂,我们可以挑选几种来简单介绍一下
 表示body中的数据长度
表示body中的数据长度

表示body中的数据格式(看起来很长,但在实际开发中经常用到,这个东西的含义就是body中的数据表示格式,和URL中的query String一样)
Content-length的补充:
HTTP也是基于TCP的协议,TCP是一个面向字节流的协议,会出现粘包问题,可以合理设计应用层协议,来明确包和包之间的边界(HTTP中都有体现)
1.使用分隔符
2.使用长度
如果当前有若干个GET请求,到了TCP接受缓冲区了,应用程序读取请求的时候,就以空格作为分隔符
如果当前是有若干个POST请求,到了TCP缓冲区,这个时候,空行后面还有body.当应用程序读到空行之后,就需要按照Content-Length表明的长度,继续若干长度的数据
User-Agent (UA)

过去由于浏览器发展很快,一部分用户用的是比较老旧的浏览器(只能显示文本),一部分用的较新的浏览器(能够支持js),这给网站开发人员带来了挑战
为了解决这个问题,程序猿就想到了让浏览器发送请求的过程中,自报家门,服务器就可以根据这个自报家门的信息来做出区分了.
在如今2023年,主流浏览器的功能已经差别很小了,UA这个字段起到的作用就不那么大了,但如今,UA又有了新的使命:来区分是PC端还是手机端,最大的区别就是屏幕的尺寸和比例.服务器就可以根据UA来区分当前是手机端还是PC端,如果是手机就返回手机版的网页,如果是电脑就返回电脑版的网页
Referer

表示当前页面是从哪个页面跳转过来的(如果你是通过浏览器地址栏直接输入地址或者直接点收藏夹,这个时候是没referer)
那这个具体有什么用呢?其实这是一个非常有用的字段
我们现在用到Referer主要是用来广告计费,比如你在搜狗的浏览器里面点击了一个广告,其实都会先访问搜狗的服务器,再跳转到广告主的页面,一点击就把这个请求发送给了搜狗的计费服务器,搜狗就可以按照这个服务器上收到的数据来进行统计。
广告主那边也同时进行记录一些日志。
当然,一个广告主,可能在多个平台投放广告,广告主就可以通过Referer来区分当前的请求是哪个广告平台导入过来的流量
那么,是否可以有一种操作,把HTTP请求中的Referer给篡改了?本来是搜狗的,改成了别的
完全可以,而且还曾一度非常猖獗,那么谁有能力和动机去干这件事情呢?运营商(电信,移动,联通),运营商也有自己的广告平台,网络基础设备是运营商提供的,网络流量经过了运营商的设备,运营商的设备就可以对你的请求进行抓包,并且可以进行修改操作,运营商劫持事件在2015年前是非常普遍的,到如今基本就不存在这样的问题了,各大广告平台都使用了HTTPS协议进行加密了。
Cookie
Cookie就是浏览器给页面提供的一种能够持久化存储数据的机制(持久化:数据不会因为程序重启或者主机重启而丢失)

具体组织形式:
1.先按域名来组织,针对每个域名,分别分配一个小房间,假如我访问搜狗,浏览器就会给sogo这个域名记录一组cookie.
2.一个小房间里,又会按照键值对的方式来组织数据.
cookie里面保存身份信息,这件事就好比说去医院看病先办就诊卡,就诊卡里包含你的各种信息,后续看病的时候,只要先刷下就诊卡,就可以获取到你的信息,后面诸如拍片之类的只要拿就诊卡刷一下就知道要拍什么样的片了.
在上述过程中,我手里的就诊卡就是cookie,虽然就诊卡上面可以存储一些信息,但是保存的数据量是有限的,真正保存我的这些信息,并不是这张卡,而是放到了医院的服务器上,而卡上只需要存储我的一个身份标识(存一个用户id),这些关键信息,存储在服务器上,管这个东西称为”session“会话,服务器这里管理着很多的session,每个session里面都存储了用户的关键信息,每个session也有一个sessionID,就诊卡上其实存储的就是这个会话的id.
存储会话id,是cookie最重要的场景,这可以让访问服务器的后续页面的时候,能带上这个id从而让服务器能够知道当前用户的信息(服务器上保存用户信息这样的机制就称为session会话).
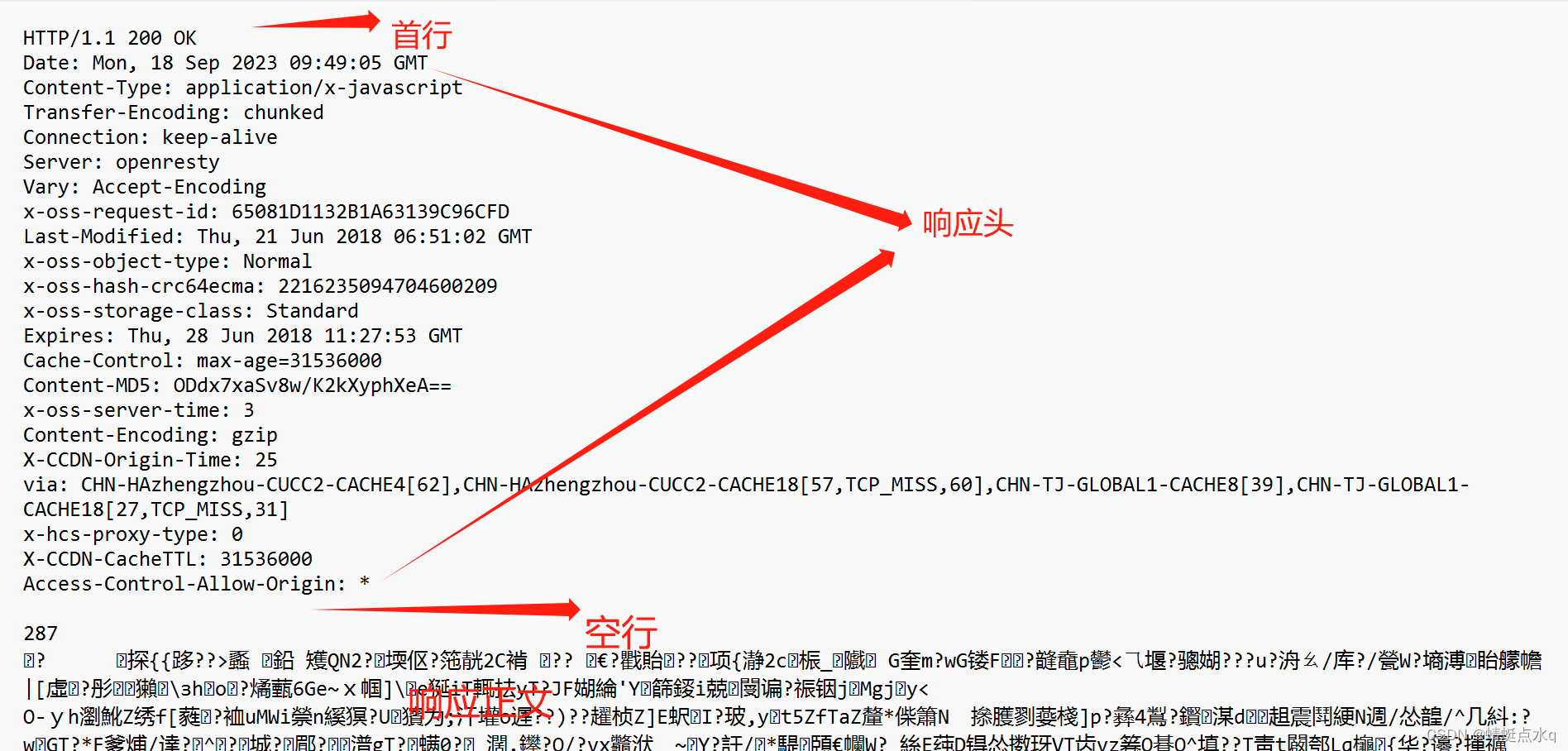
HTTP响应详解
-
首行:包含3个部分
1.版本号HTTP/1.1
2.200状态码,描述此响应成功还是失败
3.OK状态码的描述,通过一个/一组简单的单词,来描述当前状态码的含义 -
响应头(header)
也是一个键值对的结构,每个键值对占一行,每个键和值之间使用:空格来分割,header中的键值对个数也是不确定的,不同键值对表示不同含义. -
空行
表示响应头结束标记 -
响应正文(body)
服务器返回给客户端的具体的数据,这里的东西可能有各种不同的格式,其中,最常见的就是HTML.
状态码:
表示这次请求成功还是失败,原因为何
1XX(信息性状态码)表示接收的请求正在处理
2XX(成功状态码)表示请求正常处理完毕
3XX(重定向状态码)表示需要进行附加操作以完成请求
4XX(客户端错误状态码)表示服务器无法处理请求
5XX(服务器错误状态码)表示服务器处理请求出错
常见状态码 :
200 OK——客户端发来的请求在服务器端被正常处理
404 Not Found——服务器上无法找到请求的资源
403 Forbidden——对请求资源的访问被服务器拒绝了
405 Method Not Allowed——这个情况.你去外面的网站上抓包,很难遇到…但是如果后面自己写网站后台,这个就很容易出现
例如,尝试使用 GET 来访问人家的服务器,但是可能人家只支持 POST,于是就会返回 405
正文
里面的格式非常灵活,取决于响应头中的Content_Type
html
css
js
json
其余格式基本与请求中类似