一、起源
- 2010至2014年间,由柏林工业大学、柏林洪堡大学和哈索普拉特纳研究所联合发起名Stratosphere的研究项目。
- 2014年4月,项目贡献给Apache基金会,成为孵化项目。更名为Flink
- 2014年12月,成为基金会顶级项目
- 2015年9月,发布第一个稳定版本0.9
- Flink1.7,第一个完全支持Scala2.12 -2018年
- 最新-Flink1.17
后续版本flink持续更新中,后续我们的案例以flink1.15来实现
二、简介
定义:Apache Flink是一个分布式处理引擎,用于对无界和有界流进行有状态处理。
优点:低延迟、高吞吐、结果的准确性和良好的容错性
重点关键词:分布式、无界和有界、状态处理
解释:
分布式:运算过程分布在不同的节点甚至机器进行。
有界与无界:在flink的世界观众,一切都是流。有界只是流指定了起点和终点,数据是固定的;无界则数据源源不断的产生,没有结束边界。

三、用途
用途十分广泛,如:
- 电商和市场营销
数据报表、广告投放、业务流程需要 - 物联网(IOT)
传感器实时采集和显示、实时报警,交通运输业 - 电信业
基站流量调配 - 银行和金融业
实时结算和通知推送,实时监测异常行为 - 其它应用:实时数仓和ETL、复杂事件处理
四、Flink的特点和优势
- 分层API
底层的状态操作、ProcessFunction等 (属于大招)
中间层:流API操作,窗口等操作。
顶层:Table和SQL API
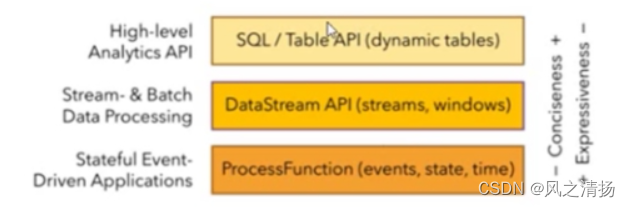
顶层API一直在完善中,一般使用中间层就足够了,特殊需求需要使用底层API。 - 事件驱动
由一个事件驱动,周期性地保存磁盘(checkpoint),计算结果可以持久化到外部设备。即来一条处理一条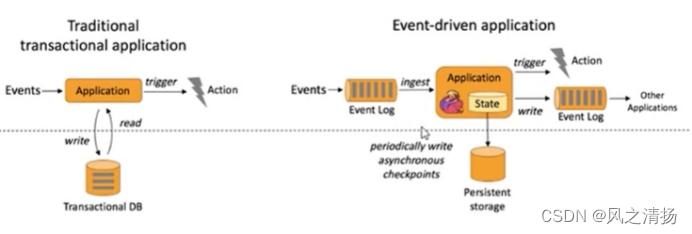
传统的事务应用(如Web应用)也是一种事件驱动型。 - 基于流的世界观
此特点上述过程已叙述。
Flink的具体优势:
- 时间语义丰富: 支持事件时间(event-time)和处理时间(process-time)、注入时间(IngestionTime)
- 精确一次(exactly-once)的状态一致性保证。
- 低延迟,每秒处理几百万
- 高可用,7*24不间断运行
- 与多个存储介质兼容(Kafka/ES/Hive/Mysql)
下一篇以应用实例来进行讲解

![[LLM+AIGC] 01.应用篇之中文ChatGPT初探及利用ChatGPT润色论文对比浅析(文心一言 | 讯飞星火)](https://img-blog.csdnimg.cn/884dddb999f9445187be8174b7f6b9e3.jpeg#pic_center)