目录
一、DSL 查询文档语法
前言
1.1、DSL Query 基本语法
1.2、全文检索查询
1.2.1、match 查询
1.2.2、multi_match
1.3、精确查询
1.3.1、term 查询
1.3.2、range 查询
1.4、地理查询
1.4.1、geo_bounding_box
1.4.2、geo_distance
1.5、复合查询
1.5.1、相关性算分
1.5.2、function_score
1.5.3、boolean query
1.6、搜索结果处理
1.6.1、排序
1.6.2、分页
深度分页问题
深度分页问题的解决方案
1.6.3、高亮
1.6.4、搜索语法汇总语法
一、DSL 查询文档语法
前言
本文中的案例,继续延续上一章节的酒店数据.
1.1、DSL Query 基本语法
基本查询语法如下:
GET /索引库名/_search
{"query": {"查询类型": {"查询条件": "条件值"}}
}
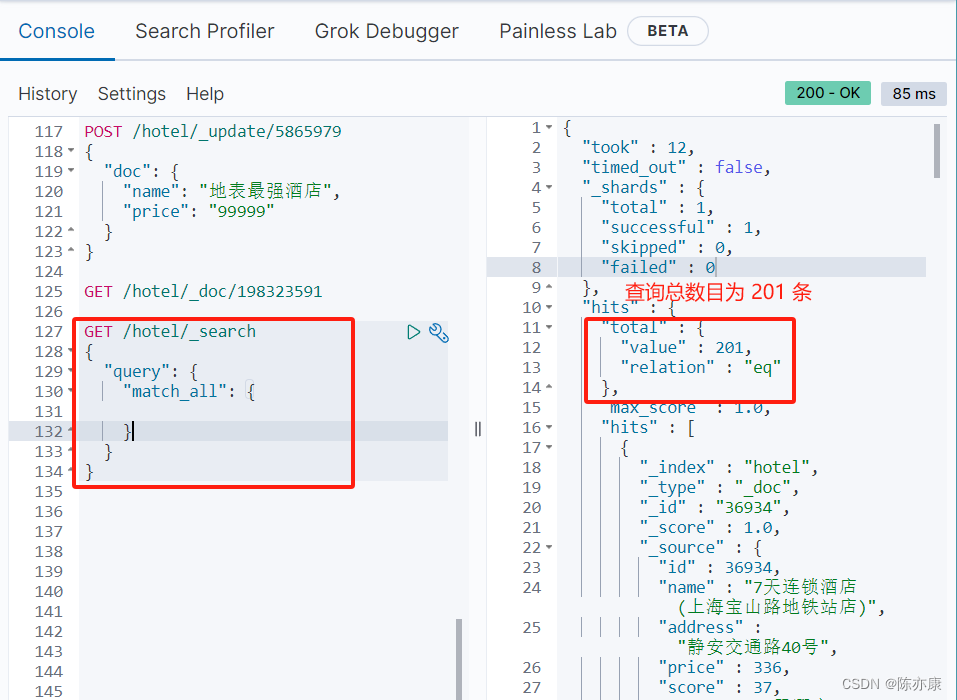
例如查询酒店所有数据(一般生产环境下不会这么做,因为数据量有可能非常大,所以查询非常耗时,因此一般用于测试用)
GET /hotel/_search
{"query": {"match_all": {//由于这里是查询所有数据,因此没有查询条件}}
}
1.2、全文检索查询
全文检索查询,会通过 分词器 对用户输入内容进行分词处理,然后去倒排索引库中匹配. 经常用于搜索框的搜索,例如百度搜索框.
1.2.1、match 查询
全文检索查询中的一种,会对用户输入内容进行分词,然后去倒排索引库中检索,语法如下:
GET /索引库名/_search
{"query": {"match": {"字段名": "TEXT文本内容"}}
}
例如查询 “如家酒店” 相关的数据.
GET /hotel/_search
{"query": {"match": {"all": "北京如家酒店"}}
}
Ps:all 这里通过 copy_to 拷贝了多个字段,例如 name、city....(具体上章有介绍)

1.2.2、multi_match
与 match 查询类似,只不过允许同时查询多个字段.
Ps:多个字段查询也意味着查询性能低下,建议可以使用 copy_to 将其他字段的索引拷贝到一个字段,可以提升查询效率.
语法如下:
GET /indexName/_search
{"query": {"multi_match": {"query": "TEXT","fields": ["字段名1", " 字段名2"]}}
}
例如根据 name、和 city 字段查询酒店数据.
GET /hotel/_search
{"query": {"multi_match": {"query": "上海如家酒店","fields": ["name", "city"]}}
}
1.3、精确查询
精确查询一般是查找 keyword、数值、日期、boolean 等类型字段,因此 不会 对搜索条件进行分词.
例如你在淘宝里买东西的时候,要通过一些信息进行筛选,比如 销量、信誉、价格升序... 这些词一般都是固定一个按钮,点击就会帮你做筛选.
1.3.1、term 查询
term 查询主要是根据 词条 精确值进行查询,一般搜索 keyword 类型、数值类型、布尔类型、日期类型字段.
语法如下:
// term查询
GET /索引名/_search
{"query": {"term": {"字段名": {"value": "字段值"}}}
}或者简化为GET /索引名/_search
{"query": {"term": {"字段名": "字段值"}}
}
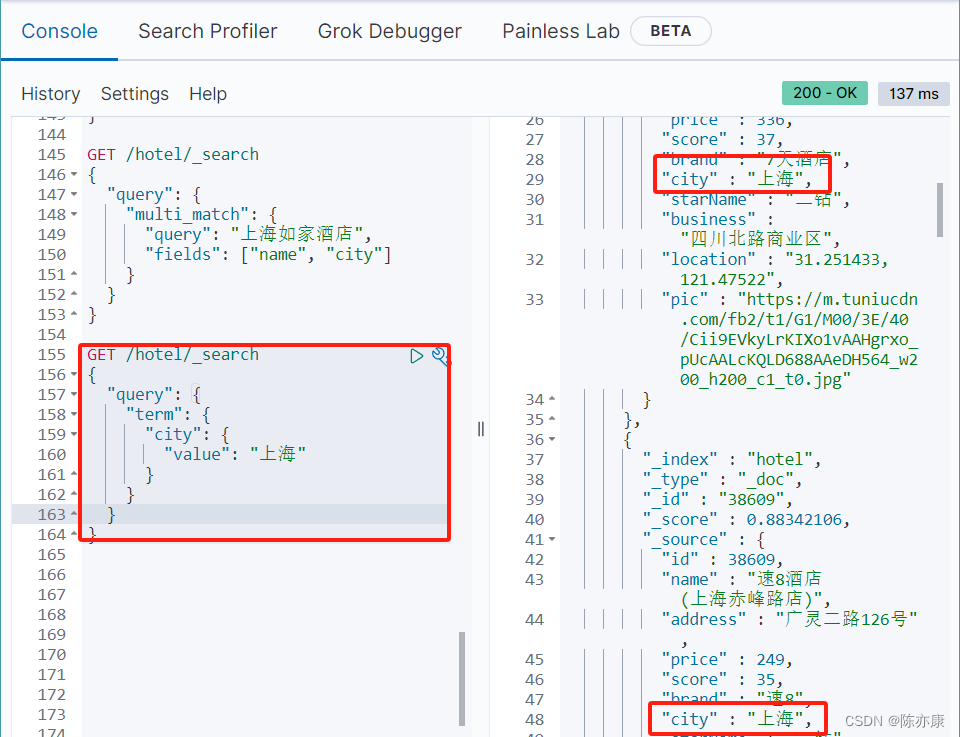
例如我要搜索在上海的所有酒店(这里 city 就是 keyword).
GET /hotel/_search
{"query": {"term": {"city": {"value": "上海"}}}
}或者GET /hotel/_search
{"query": {"term": {"city": "上海"}}
}
1.3.2、range 查询
根据数值的范围查询,可以是数值、日期的范围.
语法如下:
// range查询
GET /indexName/_search
{"query": {"range": {"字段名": {"gte": 10, //大于等于 10"lte": 20 //小于等于 20}}}
}或者GET /indexName/_search
{"query": {"range": {"字段名": {"gt": 10, //大于 10"lt": 20 //小于 20}}}
}
例如我要查询价格大于等于 161, 小于等于 300 的酒店.
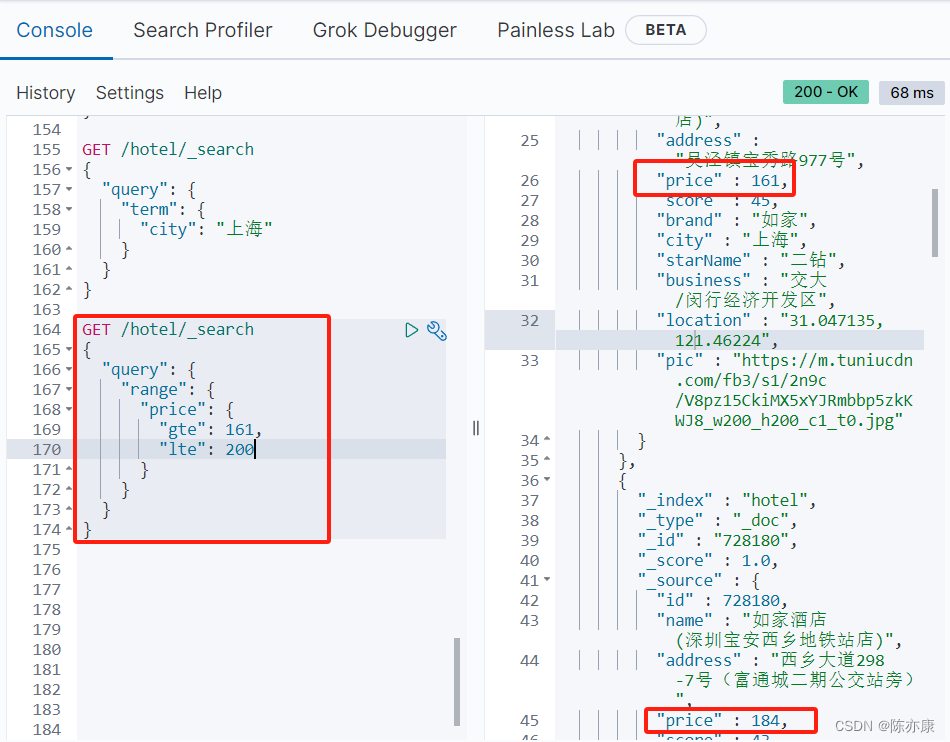
1.4、地理查询
根据经纬度查询,例如
- 滴滴:搜索附近的出租出.
- 携程:搜索附近的酒店.
- 微信:搜索附近的人.
1.4.1、geo_bounding_box
geo_bounding_box 用来查询 geo_point 值在某个矩形范围的所有文档.
// geo_bounding_box查询
GET /索引库名/_search
{"query": {"geo_bounding_box": {"字段名": {"top_left": {"lat": 31.1, //纬度"lon": 121.5 //经度},"bottom_right": {"lat": 30.9,"lon": 121.7}}}}
}
Ps:这个不是很常用
1.4.2、geo_distance
查询到指定中心点小于某个距离值的所有文档.

语法如下:
// geo_distance 查询
GET /索引库名/_search
{"query": {"geo_distance": {"distance": "15km",//半径长度"FIELD": "31.21,121.5" //纬度,经度}}
}
例如查询纬度 31.21,经度 121.5 ,半径 10km 画圆内的酒店.
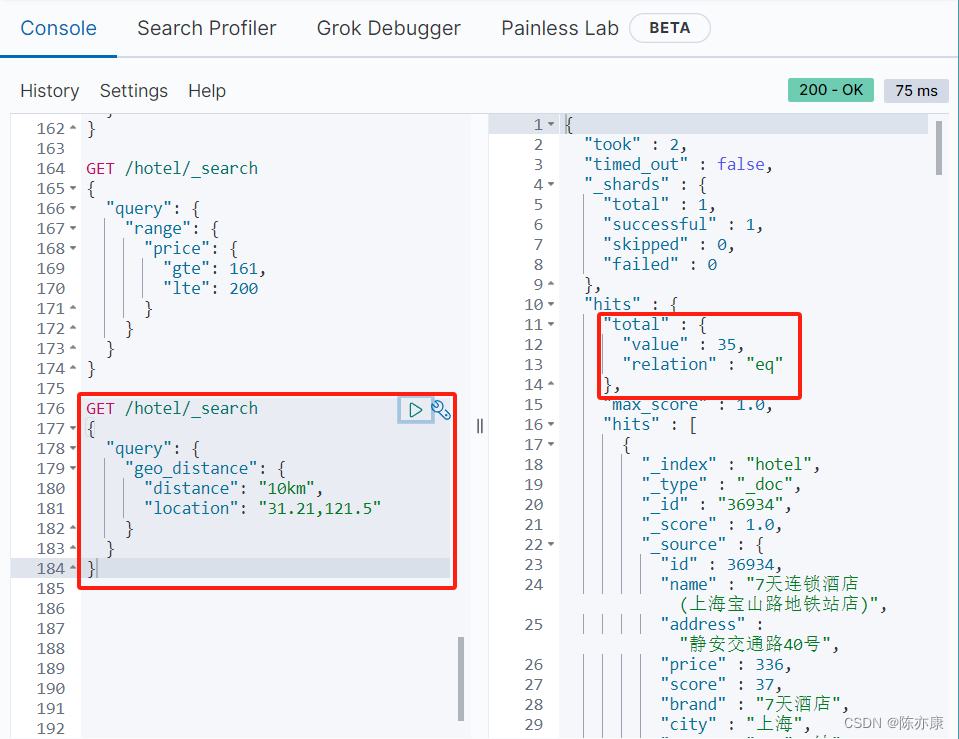
1.5、复合查询
复合查询,可以将其他简单的查询组合起来,实现更复杂的搜索逻辑.
例如 function score(算分函数查询),可以控制文档相关性算分,控制文档排名,比如你在百度搜索 “不孕不育”,指定的肯定是广告~ 为什么?人家给的钱到位~
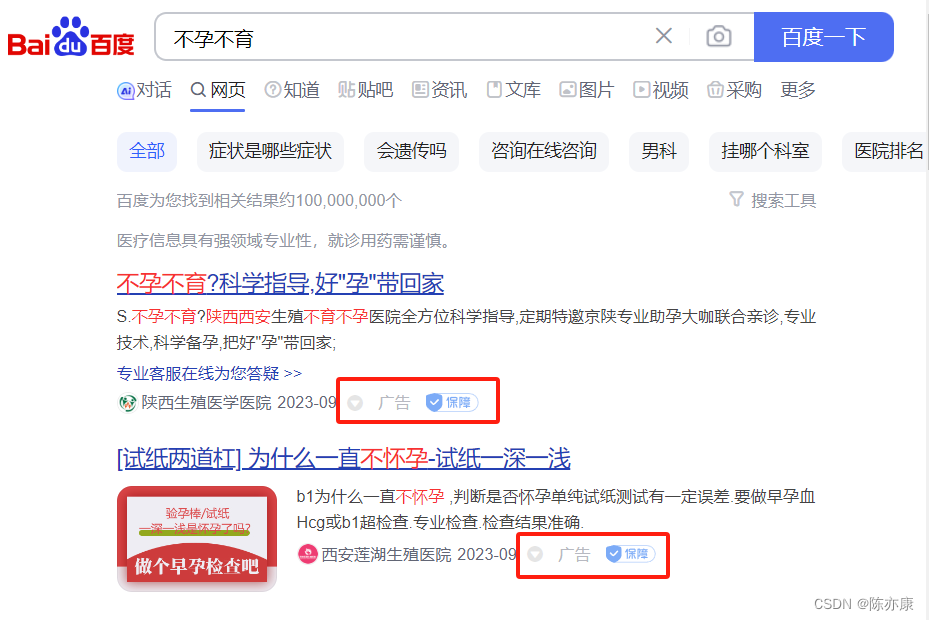
1.5.1、相关性算分
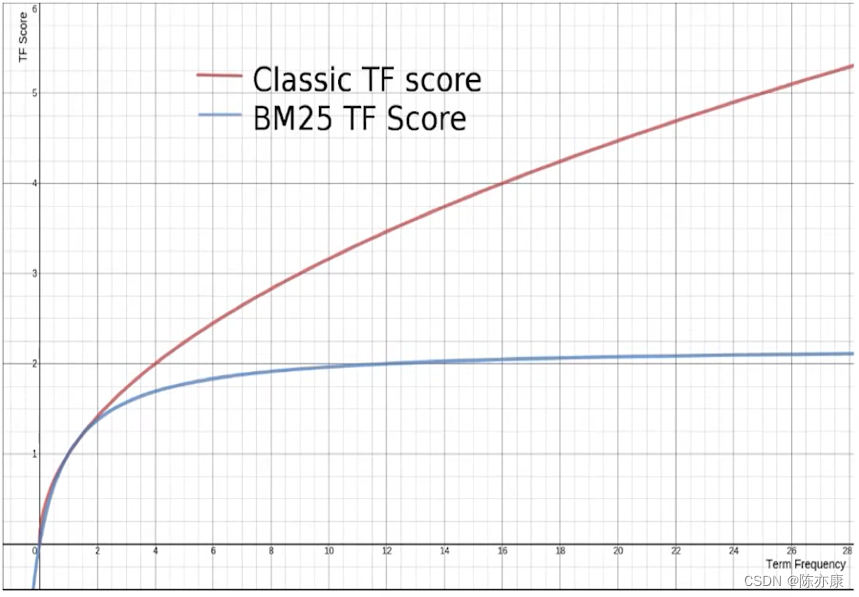
当我们使用 match 查询的时候,查询的结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列.
在 elasticsearch 5.0 之前,使用 TF-IDF 算法,会随着词频增加而越来越大.
在 elasticsearch 5.0 之后,使用 BM25 算法,分值会随着词频增加而增大,但增长曲线会趋于水平.
1.5.2、function_score
使用 function_score ,可以修改文档的相关性算分,根据新得的算分排序.
由于这里语法比较复杂,先给出个示例,如下
GET /hotel/_search
{"query": {"function_score": {"query": {"match": {"city": "上海"}},"functions": [{"filter": {"term": {"id": "1"}},"weight": 10}],"boost_mode": "multiply"}}
}- "query": {"match": {"city": "上海"}}:原始查询条件,搜索文档并根据相关性打分.
- "filter": {"term": {"id": "1"}}:过滤条件,符合条件的文档才会背重新算分.
- "weight": 10:算分函数,将来会与 query score 进行运算,得到新算分,常见的算分函数有
- weight:给一个常量值,作为函数的结果.
- field_value_factor:用文档中的某个字段值作为函数结果.
- random_score:随机生成一个值,作为函数的结果.
- script_score:自定义计算公式,公式结果作为函数结果.
- "boost_mode": "multiply":加权模式,定义 function score 和 query score 运算方式,包括
- multiply(默认):两者相乘.
- replace:sum、avg、max、min.
例如给 “如家” 这个品牌的酒店排名靠前一些.
那么这里只需要明确以下几个点即可:
- 品牌:"如家"
- 算分函数:weight 就可以.
- 加权:求和.
GET /hotel/_search
{"query": {"function_score": {"query": {"match_all": {}},"functions": [ //算分函数{"filter": {"term": { //需要满足的条件: 品牌必须是如家"brand": "如家"}},"weight": 3 //算分权重为 3}],"boost_mode": "sum" //加和算分}}
}
1.5.3、boolean query
布尔查询是一个或多个查询子句的组合. 子查询的组合方式有:
- must:必须匹配的查询条件,类似 “与”.
- should:选择性匹配的查询条件,类似 “或”.
- must_not:必须不匹配,不参与算分,类似 “非”.
- filter:必须匹配,不参与算分.
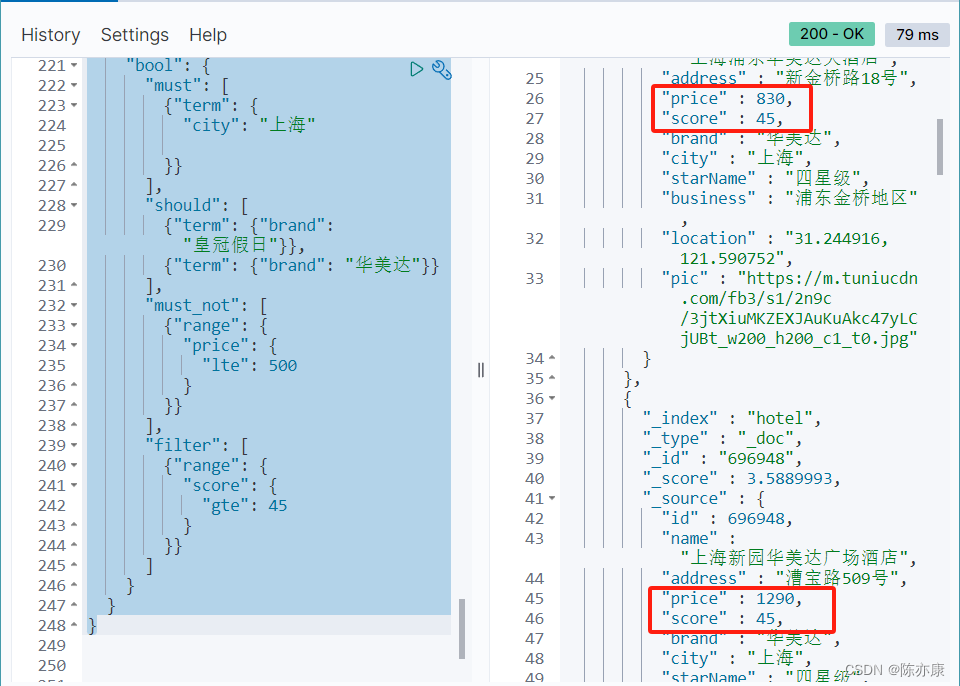
例如,查询城市在上海,品牌可以是 "皇冠假日" 或者是 “华美达”,价格必须不小于等于 500,并且评分大于等于 45 的.
GET /hotel/_search
{"query": {"bool": {"must": [{"term": {"city": "上海"}}],"should": [{"term": {"brand": "皇冠假日"}},{"term": {"brand": "华美达"}}],"must_not": [{"range": {"price": {"lte": 500}}}],"filter": [{"range": {"score": {"gte": 45}}}]}}
}
1.6、搜索结果处理
1.6.1、排序
es 支持对搜索结果进行排序处理,默认是根据相关度算分(_score)来排序. 可以排序的字段类型有(不分词):keyword 类型、数值类型、地理坐标类型、日期类型.
语法如下:
GET /索引库名/_search
{"query": {"match_all": {} //搜索内容},"sort": [{"字段名": "desc" // 排序字段和排序方式ASC、DESC}]
}
如果要根据经纬度排序,语法如下:
GET /索引库名/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance" : {"字段名" : "纬度,经度","order" : "asc","unit" : "km"}}]
}
例如对酒店用户评价降序排序,评价相同的按照价格升序排序.
GET /hotel/_search
{"query": {"match_all": {}},"sort": [{"score": {"order": "desc"},"price": {"order": "asc"}}]
}1.6.2、分页
elasticsearch 默认情况下只会返回 top 10 的数据. 如果要查询更多数据,就需要修改分页参数了.
在 es 中通过 from(偏移量,分页开始的位置,默认为 0) 和 size(期望获取的文档总数) 参数控制返回的分页结果,这里和 mysql 中的 limit 本质是一样的.
例如获取 20 ~ 29 这 10 条数据.
GET /hotel/_search
{"query": {"match_all": {}},"from": 20, // 分页开始的位置,默认为0"size": 10, // 期望获取的文档总数"sort": [{"price": "asc"}]
}
深度分页问题
ES 是支持分布式的,所以会存在深度分页的问题.
例如按照 price 排序后,获取 from = 990, size = 10 的数据.
1. 首先在每个数据分片上都排序并查询前 1000 条文档.
2. 将所有节点的数据聚合,在内从中重新排序选出前 1000 条文档.
3. 最后从这 1000 条文档中,选取 990 开始往后的 10 条数据.
打个比方,就类似于你在学校,有 10 个年级(10 个分片),你需要从这 10 个年级中找出排名前 100 的学生,那么由于考试的排名是以班级为单位的,因此,你就需要从每个班里都找出 排名前100 的学生,那么 10 个年级就意味着需要拿出 1000 个学生,然后再让他们进行一次考试,才能拿到排名前 10 的学生.
那么如果搜索页数过深,或者结果集过大,对 内存 和 CPU 的消耗也越高,因此 es 设定结果集查询的上显示 10000.
深度分页问题的解决方案
有两种办法,可以使得查询数据没有上限:
1. search after(官方推荐):分页的时候需要排序. 也就是说先对数据排序,接着当本次分页完成后,就从这次分页完成的下一个排序值开始,查询下一页数据.
但是这种方法的缺点就是 只能向后逐页查询,不支持随机翻页.
适合没有随机翻页需求的搜索,例如手机向下翻页.
2. scroll(es 7.1 后,官方已经不推荐使用了):原理就是将排序数据形成快照,保存再内存.
缺点很明显,就是消耗额外内存.
1.6.3、高亮
高亮就是指再搜索结果中把搜索关键字突出显示. 例如你在百度中搜索 "不孕不育",就会把搜索结果中所有出现 Java 关键字的内容标红.
原理如下:
- 给搜索结果中的关键字添加 HTML 标签处理.
- 在页面中给标签添加 css 样式.
语法如下:
GET /索引库/_search
{"query": {"match": {"字段名": "要搜索的文本" //注意!默认情况下,搜索的字段必须要于高亮的字段一致,否则不会高亮}},"highlight": {"fields": { // 指定要高亮的字段"字段名": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}
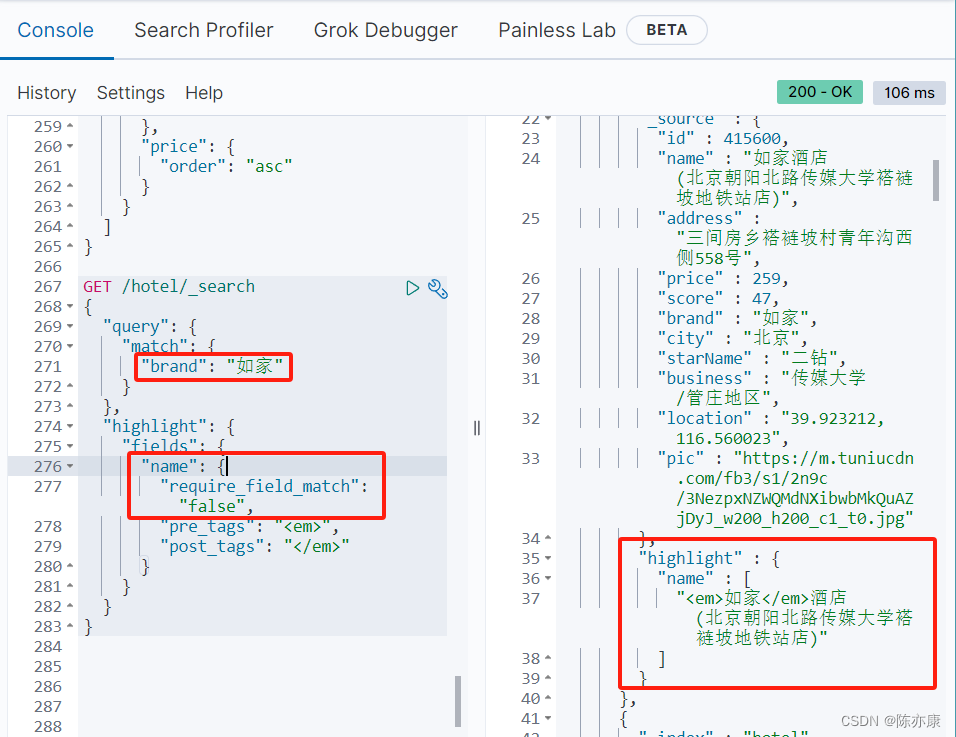
例如,我要搜索品牌是如家,并且让 "如家" 字段高亮.

Ps:默认情况下,es 中搜索的字段必须要于高亮的字段一致,否则不会高亮
但是如果你就是想让搜索的字段和高亮字段不一致,那可以添加 "require_field_match": "false" 的属性,如下:
1.6.4、搜索语法汇总语法
语法如下:
GET /hotel/_search
{"query": {"match": {"brand": "如家"}},"from": 20, // 分页开始的位置"size": 10, // 期望获取的文档总数"sort": [ { "price": "asc" }, // 升序排序{"_geo_distance" : { // 距离排序"location" : "31.04,121.61", "order" : "asc","unit" : "km"}}],"highlight": {"fields": { // 高亮字段"name": {"require_field_match": "false", //高亮字段不受查询字段限制"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}