String
内部编码有三种:int、embstr、raw
int:如果一个字符串对象保存的是整数值,并且这个整数值可以用 long类型来表示(不超过 long 的表示范围,如果超过了 long 的表示范围,那么按照存储字符串的编码来存储,使用 embstr 编码),那么字符串对象会将整数值保存在字符串对象结构的 ptr 属性里面(将 void* 转换成 long),并将字符串对象的编码设置为int。
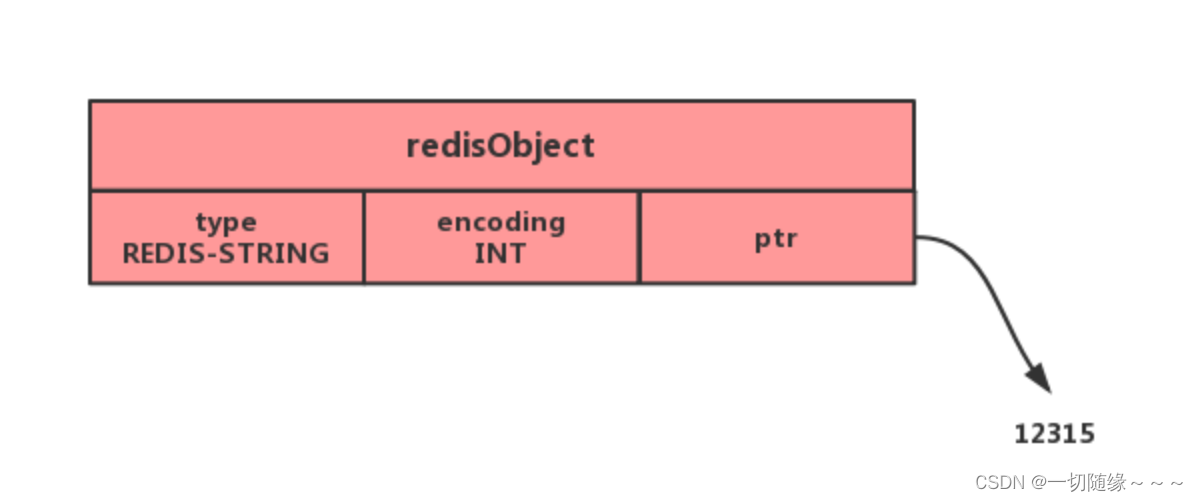
embstr:如果字符串对象保存的是一个字符串,并且这个字符申的长度小于等于多少字节(不同版本不一样),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为 embstr, embstr编码是专门用于保存短字符串的一种优化编码方式

raw:如果字符串对象保存的是一个字符串,并且这个字符串的长度大于多少字节(不同版本不一样),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为 raw:
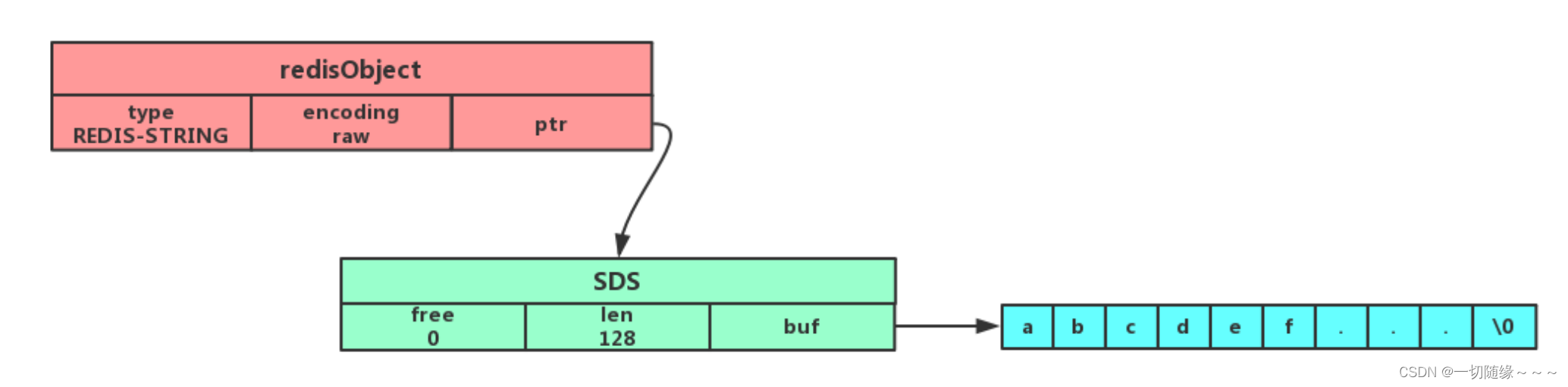
SDS(简单动态字符串)

可以看到 embstr 和 raw 编码都会使用 SDS 来保存值,但不同之处在于 embstr 会通过一次内存分配函数来分配一块连续的内存空间来保存 redisObject 和 SDS,而 raw 编码会通过调用两次内存分配函数来分别分配两块空间来保存 redisObject 和 SDS。Redis这样做会有很多好处:
● embstr 编码将创建字符串对象所需的内存分配次数从 raw 编码的两次降低为一次;
● 释放 embstr 编码的字符串对象同样只需要调用一次内存释放函数;
● 因为embstr编码的字符串对象的所有数据都保存在一块连续的内存里面可以更好的利用 CPU 缓存提升性能。
List
支持三种编码方式:
● ziplist:在Redis3.2版本之前,当List列表中每个字符串的长度都「小于64字节」并且List列表中「元素数量小于512个」时,List对象使用ziplist编码,其他情况使用linkedlist编码。ziplist是一种紧凑的、压缩的列表结构,可以节省内存,适用于小型列表。
● linkedlist:linkedlist是一种链表结构,支持任意大小的列表。但其内存占用会随着列表长度的增加而增加。
● quicklist:Redis 3.2 版本引入,quicklist 是一种由多个 ziplist 组成的列表结构,既能保证性能,又能节省内存,适用于大型列表。
Hash
Hash 类型的底层数据结构是由压缩列表或哈希表实现的:
● 如果哈希类型元素个数小于 512 个(默认值,可由 hash-max-ziplist-entries 配置),所有值小于 64 字节(默认值,可由 hash-max-ziplist-value 配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构;
● 如果哈希类型元素不满足上面条件,Redis 会使用哈希表作为 Hash 类型的底层数据结构。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
Set
Set 类型的底层数据结构是由哈希表或整数集合实现的:
● 如果集合中的元素都是整数且元素个数小于 512 (默认值,set-maxintset-entries配置)个,Redis 会使用整数集合作为 Set 类型的底层数据结构;
● 如果集合中的元素不满足上面条件,则 Redis 使用哈希表作为 Set 类型的底层数据结构。
ZSet
Zset 类型(有序集合类型)相比于 Set 类型多了一个排序属性 score(分值),对于有序集合 ZSet 来说,每个存储元素相当于有两个值组成的,一个是有序集合的元素值,一个是排序值。
有序集合保留了集合不能有重复成员的特性(分值可以重复),但不同的是,有序集合中的元素可以排序。
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
● 如果有序集合的元素个数小于 128 个,并且每个元素的值小于 64 字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构;
● 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。