博客中涉及代码已全部上传至Gitee,有需要请自行下载
目录
- 前言
- 通信基础
- 管道
- 匿名管道
- 第一步:创建管道
- 第二步:创建子进程
- 第三步:开始通信
- 第四步:结束通信
- 匿名管道通信代码实现
- 四种特殊情景
- 基于匿名管道的多进程控制
- 对象管理
- 体系构建
- 总结
前言
通信是指人与人或人与自然之间通过某种行为或媒介进行的信息交流与传递,从广义上指需要信息的双方或多方在不违背各自意愿的情况下采用任意方法、任意媒质,将信息从某方准确安全地传送到另方。在生活中,我们无时无刻都在于他人进行通信,通信的本质就是将我们的信息进行相互传递共享,让我们可以共同来配合做某一些事情来提高效率。

因此,我们的进程间也应该要进行相互的通信,相互的配合着做一些事情。
进程间通信(InterProcess Communication,IPC)是指在不同进程之间传播或交换信息。 IPC的方式通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享内存、Socket(套接字)等,其中 Socket和支持不同主机上的两个进程IPC。本篇文章介绍的是管道通信。
通信基础
我们知道进程与进程间是相互独立,互不影响的,但现在我们想让两个互不干扰的进程进行通信,首先就要打破这个性质,让两个进程间建立起一座通信的桥梁,而这个桥梁就是我们的管道。
管道
管道是一种半双工的通信方式,只能用于父进程与子进程的通信,或者同祖先的子进程(具有血缘关系的进程)之间的通信。在Linux中,管道是UNIX环境中历史最悠久的进程间通信方式之一。

而我们利用管道通信的本质就是打破进程间相互独立从而看不到同一份资源的窘境,管道的两端分别链接两个进程,一个进程将自己要发送的消息或者资源放到管道文件中,另一个进程就可以从管道文件中将消息和资源读取出来。这样一放一取的过程,我们就完成了两个进程间的通信。✌
匿名管道
第一步:创建管道
匿名管道,顾名思义就是没有名字的管道文件,匿名管道在系统中没有实名,它只是进程的一种资源,会随着进程的结束而被系统清除。
创建匿名管道我们可以使用系统给我们提供的系统调用接口pipe,接口的返回值是int类型,如果创建成功就返回0,失败就返回-1,并设置错误码。pipe接口只有一个输出型参数,是一个数组,给我们返回管道的文件描述符,pipefd[0]表示读端,pipefd[1]表示写端。之后我们就可以拿这两个文件描述符来做文章了。
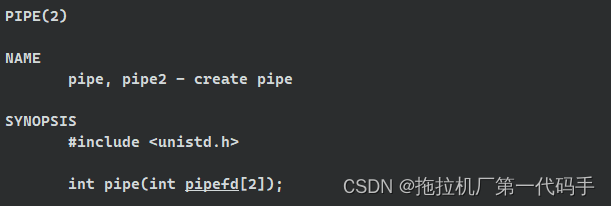

第二步:创建子进程
通过创建子进程,子进程会继承了父进程的各种属性(包括文件描述符表),从而子进程和父进程就看到了同一个管道文件,也是是看到了同一份资源!因为管道只支持单向通信,所以我们还需要关闭父子进程多余的读写端,让一个进程专门发送数据,一个进程专门读取数据。
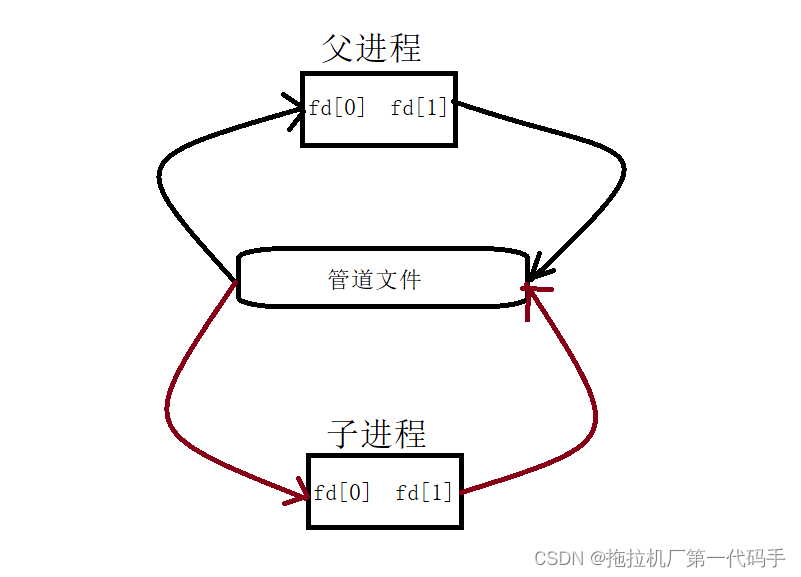
第三步:开始通信
在完成了前面两步之后,我们就已经让两个彼此没有交集的进程有了一丝丝的牵连,接下来我们就可以进行愉快的通信了。👏(额…单向的通信也算通信吗?)

第四步:结束通信
在通信结束后,我们还需要将自己相应的端口关闭,当管道文件的读写两端都没有进程链接时,管道文件会自动销毁,不需要我们去手动释放空间。在此我们还需要学习一个系统调用接口close。
close 函数的作用是关闭一个打开的文件描述符,释放对应的资源,包括操作系统中的文件表项等。如果文件描述符是打开的,它会被关闭;如果文件描述符已经关闭,调用 close 函数将没有任何影响,也不会报错。
在使用close函数时,我们只需要传入我们打开的文件描述符即可,当返回值为0时表示关闭成功,-1表示关闭失败,并设置错误码。
匿名管道通信代码实现
在上述一系列分析之后,成功搞清楚了匿名管道通信的具体流程,现在我们可以来设计这样一个程序,我们创建一个管道,在拿到相应的文件描述符后在创建一个子进程,关掉父进程的写端和子进程的读端。让父进程进行从管道读取,子进程向管道写入,在子进程写入5条消息后子进程退出,父进程读取完毕后也退出。
以下是这个简单设计的代码实现:
```cpp
#include <iostream>
#include <unistd.h>
#include <cerrno>
#include <string.h>
#include <cassert>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>int main()
{// 先让不同的进程看到同一份资源// 创建管道int pipefd[2];int ret = pipe(pipefd);if (ret == -1){std::cout << "pipe error" << errno << " : " << strerror(errno) << std::endl;}// 创建子进程pid_t pid = fork();if (pid == -1) // 创建失败{std::cout << errno << " : " << strerror(errno) << std::endl;exit(1);}// 创建子进程成功// 让子进程写,父进程读if (pid == 0){// 子进程// 关闭不需要的fdclose(pipefd[0]);// 开始通信 -- 向父进程写入数据for (int i = 0; i < 5; i++){std::cout << "我正在发送第 " << i + 1 << " 条数据" << std::endl;char buffer[] = "i am father";write(pipefd[1], buffer, sizeof(buffer) - 1); sleep(1);}close(pipefd[1]);std::cout << "发送完成,我退出了" << std::endl;exit(0);}// 父进程// 关闭不需要的fdclose(pipefd[1]);// for(int i = 0; i < 5; i++)while (true){char buffer[1024];ssize_t ret = read(pipefd[0], buffer, sizeof(buffer) - 1);buffer[ret] = '\0';if (ret > 0){std::cout << "这是我读到的数据 : " << buffer << std::endl;}else if (ret == 0){std::cout << "通信完毕,退出!" << std::endl;break;}else{std::cout << errno << "读取错误 : " << strerror(errno) << std::endl;exit(1);}sleep(1);}close(pipefd[0]);int status = 0;waitpid(pid, &status, 0);std::cout << "sig : " << (status & 0x7F) << std::endl;return 0;
}
运行结果正如我们设想的一样,子进程在发送完5条消息后退出,父进程也在读取完毕5条消息后退出。

四种特殊情景
- 读端一直读取,写端直接退出
如果管道的写端直接退出而读端仍在不断尝试读取数据时,如果管道中还有数据没有读取完毕,读端会继续读取管道中的数据,直到管道为空。当管道中写段关闭并且管道中没有数据时,read会返回0,我们可以从返回值判断通信的状况。
- 写端一直写入,读端直接退出
如果管道的写段一直在写入,而读端直接退出,写入的进程会收到OS发送的SIGPIPE信号从而终止进程。
- 读端快速读取,写端慢速写入
当读端读取速度大于写段的写入速度时,那么每一次读取会将上一次写端写入的所有数据一次性读取完毕。
- 读端慢速读取,写段快速写入
当写端的写入速度小于读端的读取速度时,在它将管道中的数据读取完后,下一次读取时会阻塞等待,一直到写端的下一次写入数据完毕时才会进行读取。
基于匿名管道的多进程控制
我们在上述代码中让子进程写入,父进程读取,那当然我们也可以让父进程写入,子进程进行读取。我们先创建一批管道和一批进程管道和进程一一对应,在记录下子进程的PID和对应写入的文件描述符后,当我们想让哪个子进程处理什么样的任务时,我们只需要向对应的文件描述符写入对应的任务号后,子进程就可以去执行对应的任务。这样我们就完成了基于匿名管道的多进程控制。
对象管理
我们可以用类来对子进程的PID和对应文件描述符进行封装,如下代码:
class EndPoint
{
public:pid_t _pid;int _fd;public:EndPoint(pid_t pid, int fd) : _pid(pid), _fd(fd){};~EndPoint(){};
};
然后在对需要执行的一批任务进行结构化管理,这里只是进行简单试验,所以任务只创建3个并只是简单的打印区分,如下代码:
using func = std::function<void(void)>;
void Mysql()
{std::cout << "PID : " << getpid() << " MySQL is running......." << std::endl;
}void Print()
{std::cout << "PID : " << getpid() << " Printing........." << std::endl;
}void Calculate()
{std::cout << "PID : " << getpid() << " Calculate........." << std::endl;
}
class Task
{
public:Task(){funcs.push_back(Mysql);funcs.push_back(Print);funcs.push_back(Calculate);}void Excute(int taskid){if (taskid >= 0 && taskid < funcs.size())funcs[taskid]();}~Task() {}public:std::vector<func> funcs;
};
体系构建
在将对应的任务和子进程管理好后,我们就可以对整个框架进行搭建,首先我们需要创建出一批管道和进程。关闭掉相应的读写端后将子进程的PID和写入端文件描述符构建出一个对象,再将这个对象加入到顺序表中进行统一管理。再继续就可以选取对应的进程和相应的任务,将这个任务号写入到匿名管道中让子进程进行读取执行。就此,我们可以写出如下的代码:
void CreateProccess(std::vector<EndPoint> &ep)
{std::vector<int> fds;for (int i = 0; i < PROCCESS_NUM; i++){// 创建管道int pipefd[2];int ret = pipe(pipefd);if (ret == -1){std::cout << errno << " : " << strerror(errno) << std::endl;exit(1);}// 创建子进程pid_t id = fork();assert(id >= 0);if (id == 0){for (auto &e : fds)close(e);// 子进程// 关闭多余文件描述符close(pipefd[1]);// 处理WaitTask(pipefd[0]);// 关闭剩下文件描述符close(pipefd[0]);exit(0);}// 父进程// 关闭多余文件描述符close(pipefd[0]);ep.push_back({id, pipefd[1]});fds.push_back(pipefd[1]);}
}void WaitTask(int fd)
{while (1){int taskid;ssize_t ret = read(fd, &taskid, sizeof(taskid));if (ret == sizeof(int)){t.Excute(taskid);}else if (ret == 0){std::cout << "exit........" << std::endl;break;}else{std::cout << "error" << std::endl;break;}}
}int Enum()
{int ret;std::cout << "---------------------------------" << std::endl;std::cout << "---0.数据库任务------1.打印任务---" << std::endl;std::cout << "---2.计算任务--------3.退出------" << std::endl;std::cout << "---------------------------------" << std::endl;std::cout << "---------------------------------" << std::endl;std::cout << "请输入你的选择 # " << std::endl;std::cin >> ret;return ret;
}void WaitProccess(std::vector<EndPoint> &ep)
{// 关闭父进程写端// wait子进程for (int i = ep.size() - 1; i >= 0; i--){close(ep[i]._fd);waitpid(ep[i]._pid, nullptr, 0);}
}int main()
{std::vector<EndPoint> ep; Task task; // 任务列表// 创建一批进程CreateProccess(ep);while (1){// 选取任务int ret = Enum();if (ret == 3)break;if (ret < 0 || ret > 3)continue;// int taskid = rand() % task.funcs.size();// 选择进程int pid = rand() % PROCCESS_NUM;// 发送给相应的进程执行write(ep[pid]._fd, &ret, sizeof(ret));}WaitProccess(ep);return 0;
}最后,我们就可以根据提示输入相应的任务号码让系统随机的选择进程去执行任务。

我们也可以进行修改最后让我们自己指定进程去执行,这个有兴趣的话也可以试试。
总结
匿名管道是一种在进程间进行通信的机制,通常用于在父子进程或者兄弟进程之间传递数据。以下是匿名管道的一些主要特性:
-
单向通信:匿名管道是单向的,分为读端和写端。一个进程可以写入数据到管道的写端,而另一个进程可以从管道的读端读取数据。这种单向性能确保了数据在两个进程之间的有序传递。
-
进程间通信:匿名管道通常用于父子进程或者兄弟进程之间的通信。父进程创建管道并传递给子进程,或者两个独立的进程可以通过继承同一个管道来进行通信。
-
基于文件描述符:匿名管道使用文件描述符来表示,通常通过系统调用 pipe() 来创建。一个管道有两个文件描述符,一个用于读取(管道的读端),另一个用于写入(管道的写端)。
-
阻塞式写入和读取:当管道的缓冲区满时,写入进程将被阻塞,直到有足够的空间可以写入数据。同样,如果管道为空,读取进程将被阻塞,直到有数据可供读取。
-
匿名性质:匿名管道不关联具体的文件系统路径,因此在进程间通信时,它们通常不需要文件系统中的实际文件。这种匿名性质使得进程可以轻松地进行通信而不必担心文件路径的问题。
-
生命周期:匿名管道通常在创建进程时被创建,而且只在相关进程存在时才有效。当相关进程终止时,管道也会被自动关闭和销毁。
-
数据传输有序:匿名管道用于有序的数据传输,保证写入管道的数据按顺序被读取。这是因为管道是一个先进先出(FIFO)的数据结构。
-
有限容量:匿名管道通常具有有限的缓冲区容量,一旦管道的缓冲区满了,进一步的写入操作将被阻塞,直到有读取进程将数据读取出来,腾出空间。
总的来说,匿名管道是一种用于进程间通信的轻量级、有序的机制,常用于父子进程或者兄弟进程之间的数据传递。然而,匿名管道只支持单向通信,且容量有限,因此在某些情况下可能需要考虑其他进程间通信方式,如命名管道、消息队列或共享内存等。