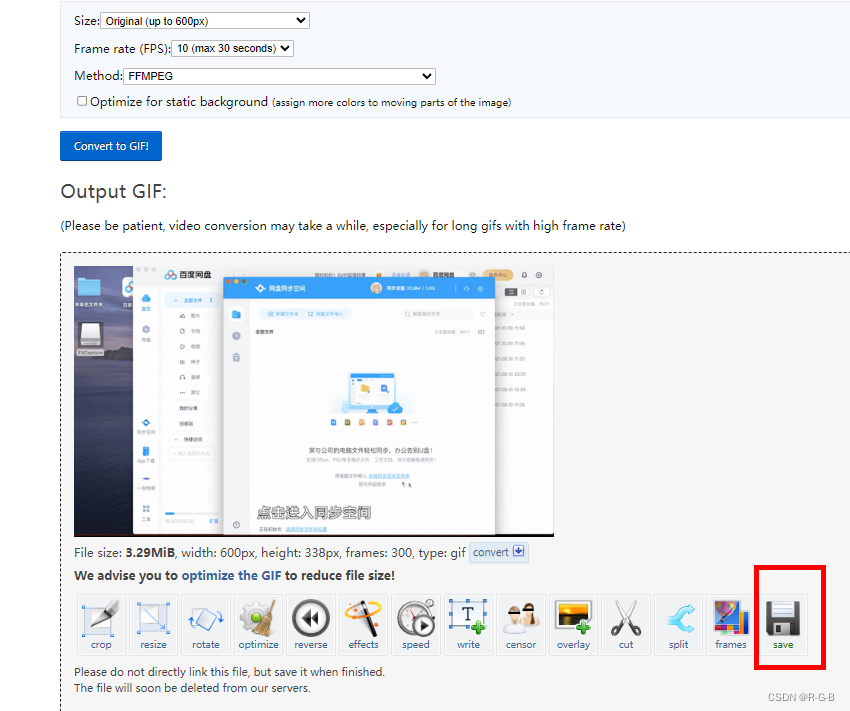
先了解一下MySQL的结构

下面我们重点讲一下存储引擎
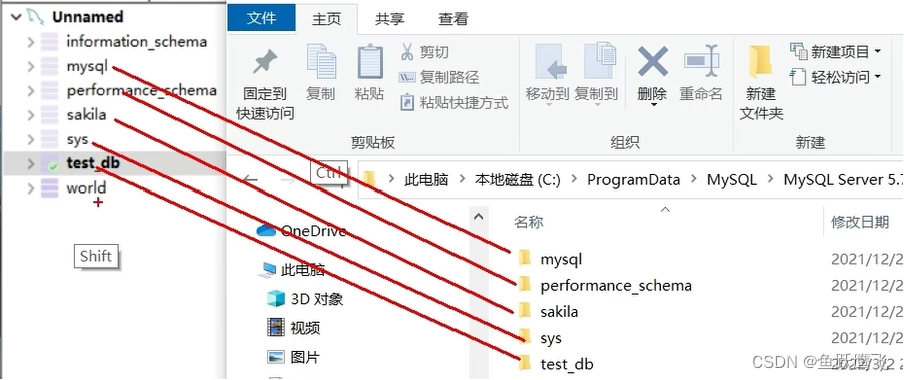
MySQL的数据库和存储数据的目录是一一对应的,这些数据库的文件就保存在磁盘中对应的目录里
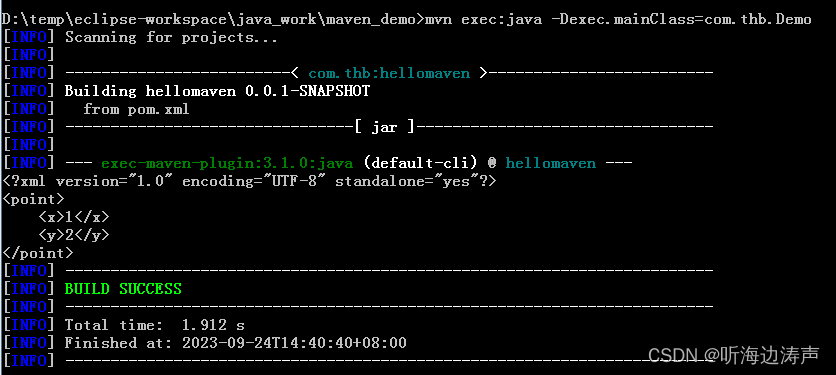
 下面我们来看一下对应的具体数据文件
下面我们来看一下对应的具体数据文件

.frm是表的结构,不管什么样的索引都会有
.ibd代表我们现在使用的存储引擎是InnoDB,ibd里面既有数据又有索引
下面我们把prodct_cn这个表的存储引擎改为MyIsam
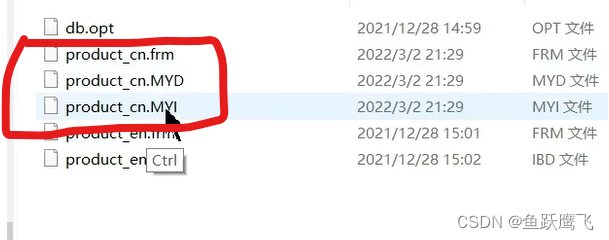
我们可以看到原来的ibd标成了现在的MYD和MYI, MYD是表的数据文件, MYI是表的索引文件
Mysql的索引是以数据结构为载体,以文件的形式落地的。
不管是MyISAM还是InnoDB存储引擎,内部使用的数据结构都是以B+树为载体的
B-Tree叫做B树,不是B减树
一次查询数据库的过程主要涉及到三个计算机的硬件:硬盘、内存、CPU
大概过程是把硬盘中的数据读取到内存中(树的根节点本身是缓存在内存里的),然后CPU从内存中读取数据进行计算,我们简单演示一下从0001-0010这棵树查找0007的过程
1.第一步先从磁盘读取根节点0004(实际上已经缓存了),这是第一次磁盘IO的过程,判断0007比根节点大,往右侧进行寻址
2.CPU进行调度把0006、0008这节点从磁盘读取到内存里,这是第二次磁盘IO的过程CPU从内存读取数据进行判断,发现0007大于0006但是小于0008,所以往二者之间的分支进行寻址
3.CPU进行调度把0007这个节点从磁盘中读取到内存中,CPU从内存中读取数据发现与查找目标一致,查询结束,这是第三次磁盘IO的过程。

根据冯诺依曼的计算机模型三种硬件的速度是这样的:磁盘<内存<CPU
磁盘是最慢的,所以我们要努力减少磁盘的IO
Mysql进行磁盘读取的时候不会只读取一个节点,而是会按照以数据页为最小单位(最小数据交互单元)进行读取(Windows的数据页为4k,MySQL的数据页为16k)。
数据页我们把他想象为一个个的格子,每次都要读取一个格子的数据,如果要读取的数据不到一个格子,则读取一个格子,超过一个格子小于2个格子,读取两个格子,以此类推。
好比我们有一个衣柜,原来是所有的东西都放在里面,找起来特别麻烦,然后呢产生了文件系统的概念(打成了一个个的格子),按照格子进行分类,每个给子的大小就是数据页的大小
mysql的数据页是16kb,比如我们刚才查找0007的过程,整个过程共读取了3个数据页,也就是48kb,这是单人单次查询的磁盘IO消耗
下面我们看一下B树的数据结构,每一个节点的大小(磁盘块大小)是固定的16kb,对于B树来说,这16kb的空间用来放三类数据:指针*(子节点的寻址地址,占用少量空间)、索引列的数据(比如id,占用的空间比较少)、数据(图中data的部分,这部分是特别耗空间的)。因为大小是固定的16kb,所以单条数据占用的空间越小,则磁盘块可以放的数据条数越多,比如如果单条数据是1kb,那一个磁盘块只能放16条数据,而如果是1b就可以放16000条数据,也就是存储同样数量的数据,如果单条数据越小,则需要的磁盘块(节点)越少,也就是基于同样的Max.Degree,树的高度会降低
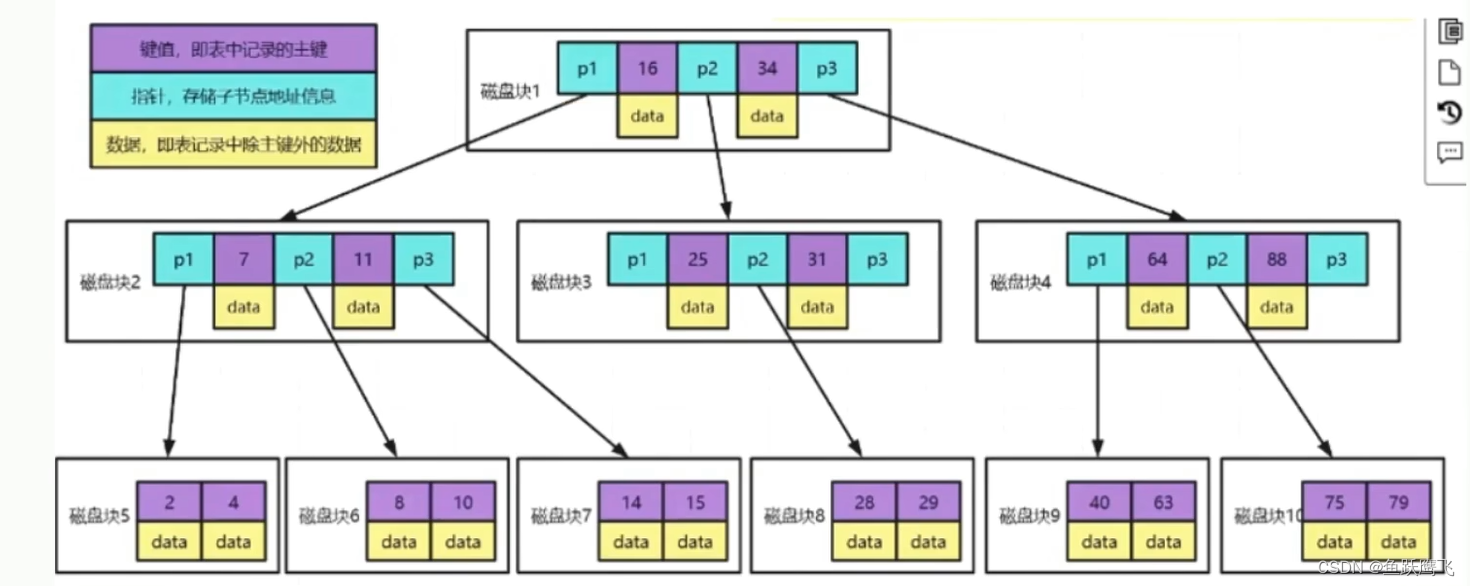
由此我们有了更适合做索引的B+树
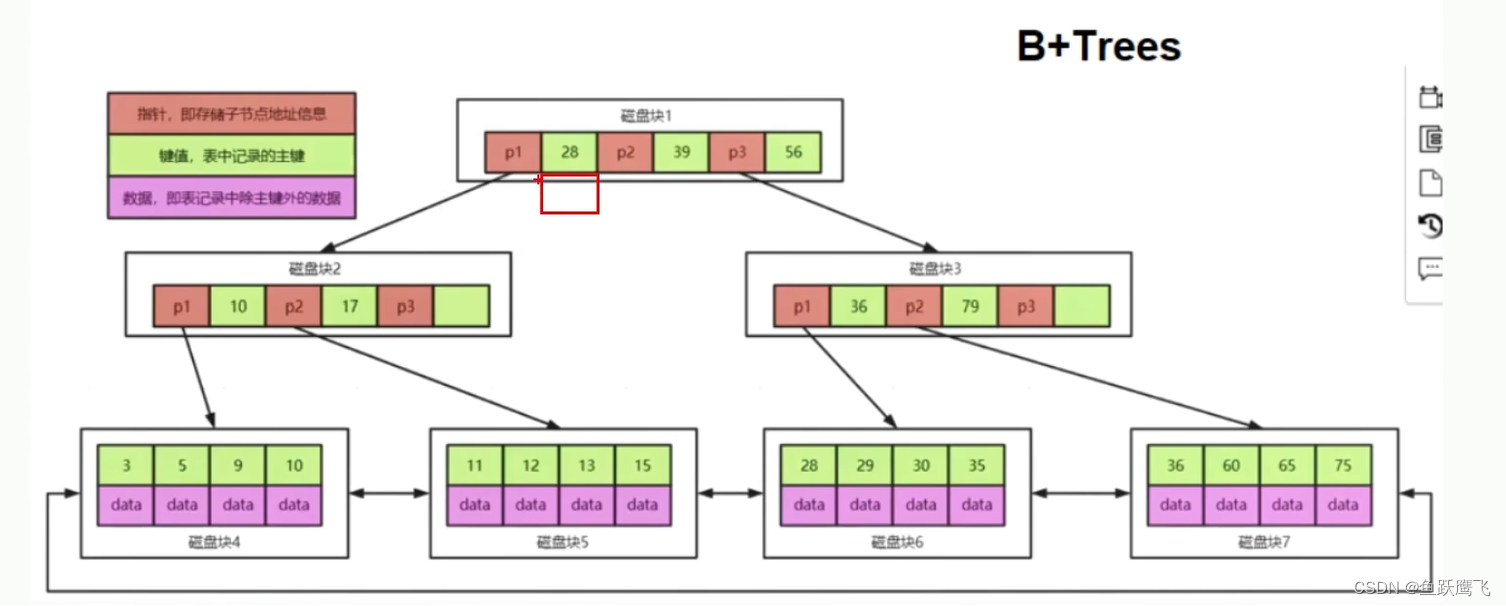
它与B树的最主要的区别在于:
B树每个节点都放了数据,而B+树只有叶子节点放了数据,其他的层的数据都只有指针和原始的索引列的值
相关面试题:为什么mysql单表最大2000万?依据是啥
参加小白debug的文章:
为什么大家说mysql数据库单表最大两千万?依据是啥? - 掘金
时间充足理解能力强的建议看原文,我这里把本面试题的重点解释一下
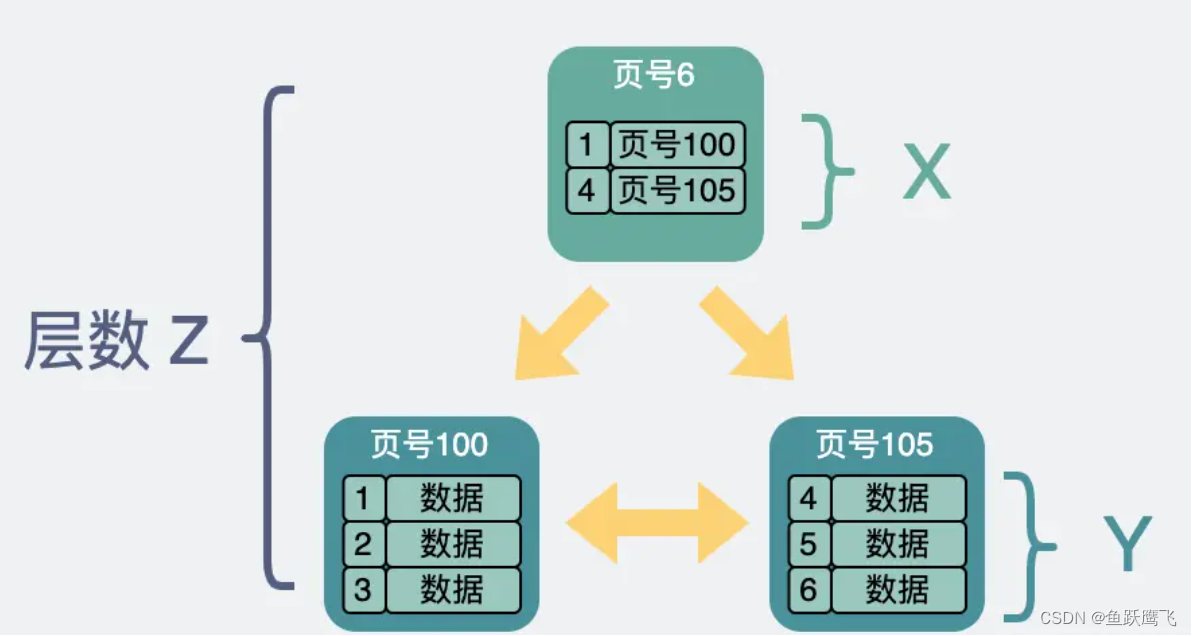
图中X, Y, Z的含义如下
X :非叶子节点内指向其他内存页的指针数量(B+树和B树数据结构中的Max.Degree)
Y :叶子节点能容纳的记录的数量
Z: B+树的层数
因为B+树只有叶子节点能存放数据,我们这里要先算一下叶子节点的数量
大家都学过最简单的树的数据结构:二叉树(特殊的多叉树,Max.Degree为2),Z层二叉树的节点数量是2^(Z-1)
图中的B+树叶子节点的数量应该是X^(Z-1)个,然后每个叶子节点(页)能放Y条数据,由此我们得出这棵B+树最多能放X^(Z-1)*Y条记录。
因为Mysql的页大小16kb,我们页头页尾那部分数据全加起来大概128Byte,加上页目录毛估占1k左右吧,也就是只有15k左右可以用来放数据(索引列的值)和指针,这里假设索引列是bigint类型(占8Byte),然后页号(指向前后页的指针)在源码中叫做FIL_PAGE_OFFSET(4Byte),二者大概是1:1的关系,相当于每条索引占用12Byte左右的空间,所以非叶子节点每页可以容纳15KByte/12Byte=1280条数据(图中的X),如果是3层B+树那图中的Z就是3.
那刚才的公式就是1280^(3-1)*Y
现在我们评估一下Y,对于叶子节点来说,每个页的大小也是16kb,但是叶子节点放的是真正的数据,占的空间会比较大一些,假设每一条数据1kb,那每个页只能放15条数据(我们页头页尾那部分数据全加起来大概128Byte,加上页目录毛估占1k),然后我们把Y=15代入上面的公式,可以得到3层的B+树可以放的数据记录的条数为1280^*(3-1)*15 = 24576000,这个可能就是我们平时传言的超过2000万要分库分表的依据。
但是这个不是绝对的,比如我们刚才评估每条数据占1kb,那如果数据比较简单,每条数据只需要200b呢,那刚才的3层B+树就可以容纳1.25亿条数据。
mysql的查询速度主要取决于B+树的高度(因为只有叶子节点有数据,所以一定要经历树的高度次IO,这里与B树不同,B树最少1次,最多树的高度次),所以具体可以容纳多少条数据而不影响性能需要根据具体的数据来分析。
如果面试聊到这里,怕是接着就要聊分库分表了