Flume概述
一个高可用(稳定),高可靠(稳定),分布式的海量日志采集,聚合和传输的系统。Flume基于流式架构,灵活简单。日志文件即txt文件,不能传输音频,视频,office等其他文件。Flume最主要的作用是实时读取服务器本地磁盘的数据,将数据写入到HDFS。
-
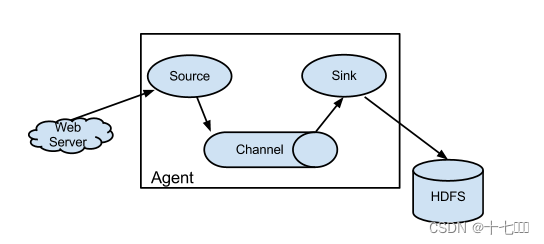
Web Server一般为java后台程序
-
Agent
- Source: 对接各种web server程序,从中读取数据
- Channel:用来作为缓冲区,平衡读取和写入速度的不一致问题。
- Memory Channel: 速度快,容易丢失
- File Channel: 速度慢,不容易丢失
- Sink: 对接各种传输终点,Sink不断轮询Channel中的事件且批量的移除它们到对应系统中
-
文件系统:比如HDFS,传输的终点
-
Event: Flume数据传输的基本单元
安装部署
- 官网下载:http://flume.apache.org/
- 解压后修改文件名称为flume
- 修改conf 下log4j2.xml确定打印的位置,日志会跟随运行路径放置flume日志。
<Properties><Property name="LOG_DIR">/opt/module/flume/logs</Property></Properties>
入门案例
1. 监控端口数据官方案例
- 安装netcat工具,该工具用于端口传话
sudo yum install -y nc - 一个窗口使用
nc -lk 端口号,监听端口 - 另一个窗口使用
nc localhost 44444连接端口 - 配置
flume configuration文件
# 给组件命名,默认 agent 叫 a1
a1.sources = r1
a1.sinks = k1
a1.channels = c1# 配置 source 的类型、主机名、端口号
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444# 配置 sink
a1.sinks.k1.type = logger# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000 # 1000个event
a1.channels.c1.transactionCapacity = 100 # 批次大小,达到该值就发送# 绑定 the source and sink to the channel
a1.sources.r1.channels = c1 # source可以连多个channel
a1.sinks.k1.channel = c1 # sink不能连多个channel
- 创建job目录,创建conf文件。命令时建议为
发送者_flume_接收者.conf - 运行Flume,
bin/flume-ng agent -c conf/ -f-file job/nc_flume_log.conf -n a1 - 配置log4j2.xml文件,添加一个属性让日志同时打印到控制台,方便查看。
<AppenderRef ref="Console" />
2. 实时监控目录下的多个追加文件
- 创建符合条件的flume配置文件
- 执行配置文件taildir_flume_log.conf,开启监控
- 向监控文件追加文件,
echo >> file1.txt - 运行flume监听,
bin/flume-ng agent -c conf/ -f-file job/taildir_flume_log.conf -n a1 - 可以关闭该监听服务后,继续追加,然后重写开启监听,会发现之前添加的内容也可以查看到,这个就是断点续传。监听读取后会生成对应的监听日志
taildir_position.json - 如果监控文件改名后仍然符合监控正则,该文件的数据会全部重传。这个机制在底层实现上不仅判断了inode的值,还判断了文件名是否改变。后期可以修改源码,改为只判断Inode即可。
- HDFS sink存在小文件问题,每10个event一个文件,或者每30秒一个文件。可以通过修改sink的参数来解决改问题:
- hdfs.rollinterval: 默认是30秒,置为0时表示不判断时间。一般企业中建议设置为3600秒
- hdfs.rollSize: 一般设置为134217700,超过128M生成一个文件
- hdfs.rollCount: 设置为0
Flume原理
1. 事务
put事务流程
在Source和Channel之间有事务来保证put操作的完整性。source能够保证数据没有提交成功时,不会修改当前发送数据的偏移量,只有当source成功将数据放到channel中时,source才会更新当前的偏移量。当channel内存空间不足时,即put失败,会回滚数据,即不更新当前数据的偏移量。
pull事务流程
在channel和sink节点之间进行的拉取操作也有可能失败,只有当数据成功放到sink中,才会将channl中的数据进行删除。否则,事务会将数据回滚到数据还未拉取前的状态,来保证数据的不丢失性。
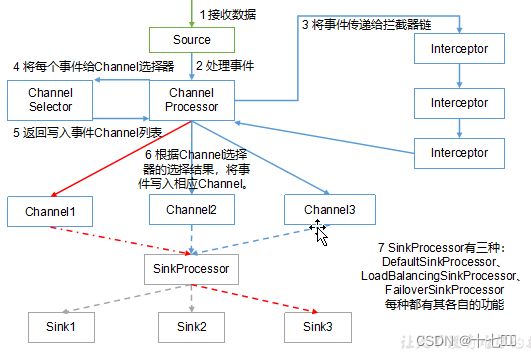
2. Flume Agent内部原理
- 拦截器清除数据,排除错误数据,添加解析部分数据,比如Header头信息
- channel选择器:
- 副本选择器,同一数据发送多份
- 多路复用选择器, 同一数据拆分发送
- sinkProcessor处理器:
- 默认处理器:
由于都在同一机器上运行,后两种处理器没有任何意义 - 负载均衡处理器
- 竞争失败处理器
- 默认处理器:
如果有flume的连接传输,启动时需要先开启下游flume,再开启上游flume。关闭时需要先关闭上游flume,再关闭下游flume。