前言
在公司的系统里,由于数据量较大,所以配置了多个数据源,它会根据用户所在的地区去查询那一个数据库,这样就产生了动态切换数据源的场景。
今天,就模拟一下在主库查询订单信息查询不到的时候,切换数据源去历史库里面查询。
实现效果
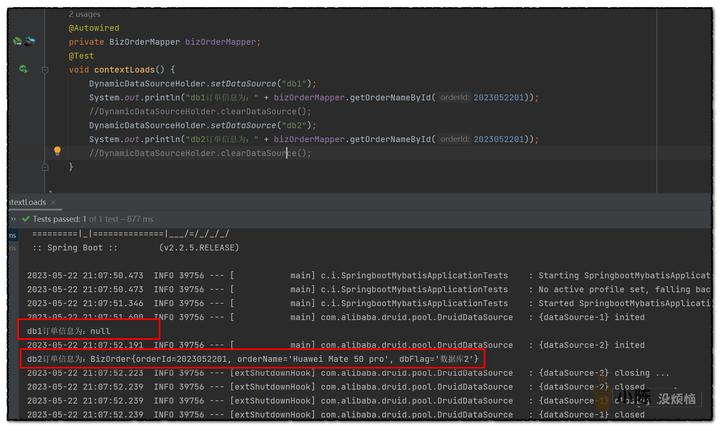
首先我们设置查询的数据库为db1,可以看到通过订单号没有查到订单信息,然后我们重置数据源,重新设置为db2,同样的订单号就可以查询到信息。
数据库准备
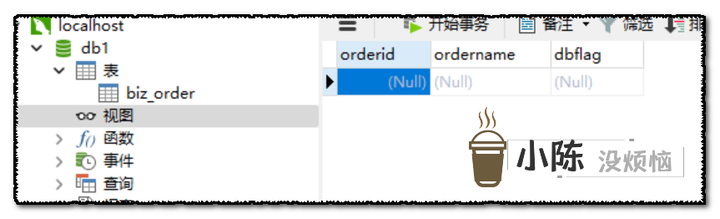
新建两个数据库db1和db2,db1作为主库,db2作为历史库
两个库中都有一个订单表biz_order,主库中没有数据,历史库中有我们要查询的数据。

代码编写
1.新建一个springboot项目,引入所需依赖
![]()
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><!--引入druid-替换默认数据库连接池--><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.15</version></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.2</version></dependency><!--mysql驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.30</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
![]()
2.application.yaml配置数据库信息
这里我们配置两个数据库的信息
![]()
spring:datasource:db1:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost/db1?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=falseusername: rootpassword: roottype: com.alibaba.druid.pool.DruidDataSourcedb2:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost/db2?characterEncoding=utf8&characterSetResults=utf8&autoReconnect=true&failOverReadOnly=falseusername: rootpassword: roottype: com.alibaba.druid.pool.DruidDataSource mybatis:mapper-locations: classpath:mapper/*.xml
![]()
3.创建数据源对象,并注入spring容器中
新建DynamicDataSourceConfig.java文件,在该配置文件中读取yaml配置的数据源信息,并且通过该信息构造数据源对象,然后通过@Bean注解注入到spring容器中。
![]()
package com.it1997.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
@Configuration
public class DynamicDataSourceConfig {@Bean("dataSource1")@ConfigurationProperties(prefix = "spring.datasource.db1")public DataSource oneDruidDataSource() {return DruidDataSourceBuilder.create().build();}@Bean("dataSource2")@ConfigurationProperties(prefix = "spring.datasource.db2")public DataSource twoDruidDataSource() {return DruidDataSourceBuilder.create().build();}@Beanpublic DataSourceTransactionManager dataSourceTransactionManager1(@Qualifier("dataSource1") DataSource dataSource1) {DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();dataSourceTransactionManager.setDataSource(dataSource1);return dataSourceTransactionManager;}@Beanpublic DataSourceTransactionManager dataSourceTransactionManager2(@Qualifier("dataSource2") DataSource dataSource2) {DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();dataSourceTransactionManager.setDataSource(dataSource2);return dataSourceTransactionManager;}
}
![]()
4.数据源配置上下文信息
新建DynamicDataSourceHolder.java文件,该文件通过ThreadLocal,实现为每一个线程创建一个保存数据源配置的上下文。并且提供setDataSource和getDataSource静态方法来设置和获取数据源的名称。
![]()
package com.it1997.config;
public class DynamicDataSourceHolder {private static final ThreadLocal<String> contextHolder = new ThreadLocal<>();public static void setDataSource(String dataSource) {contextHolder.set(dataSource);}public static String getDataSource() {return contextHolder.get();}public static void clearDataSource() {contextHolder.remove();}
}
![]()
5.重写数据源配置类
新建DynamicDataSource.java文件,该类继承AbstractRoutingDataSource 类,重写父类determineCurrentLookupKey和afterPropertiesSet方法。
这里我们重写父类中afterPropertiesSet方法(为什么要重写在这个方法,可以看文章最后对于druid的源码的讲解),在这个方法里我们将spring容器中的所有的数据源,都给放到map里,然后后续我们根据map中的key来获取不同的数据源,super.afterPropertiesSet();通过这个方法设置上数据源。
在类上加上@Primary注解,让spring容器优先使用我们自定义的数据源,否则还是会使用默认的数据源配置。
![]()
package com.it1997.config;
import org.springframework.context.annotation.Primary;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Component
@Primary
public class DynamicDataSource extends AbstractRoutingDataSource {@ResourceDataSource dataSource1;@ResourceDataSource dataSource2;@Overrideprotected Object determineCurrentLookupKey() {return DynamicDataSourceHolder.getDataSource();}@Overridepublic void afterPropertiesSet() {// 初始化所有数据源Map<Object, Object> targetDataSource = new HashMap<>();targetDataSource.put("db1", dataSource1);targetDataSource.put("db2", dataSource2);super.setTargetDataSources(targetDataSource);super.setDefaultTargetDataSource(dataSource1);super.afterPropertiesSet();}
}
![]()
druid数据源配置解读
点开我们刚刚继承的AbstractRoutingDataSource抽象类,可以看到它又继承了AbstractDataSource 实现了InitializingBean接口。
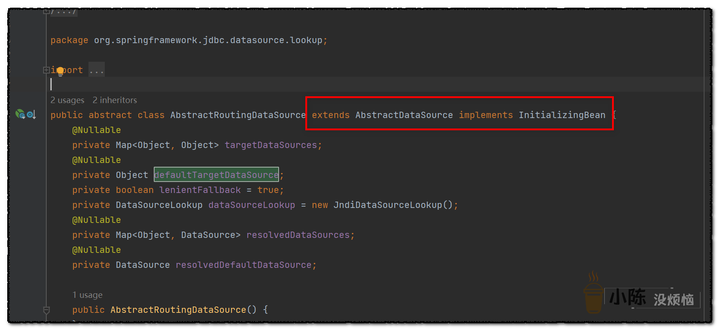
然后我们在看一下druid的数据源配置是怎么实现的,点开DruidDataSourceWrapper类,可以看到它也是继承了AbstractDataSource 实现了InitializingBean接口。并且,读取的是yaml文件中spring.datasource.druid下面配置的数据库连接信息。
而我们自定的一的数据源读取的是spring.datasource.db1下面配置的数据库连接信息。
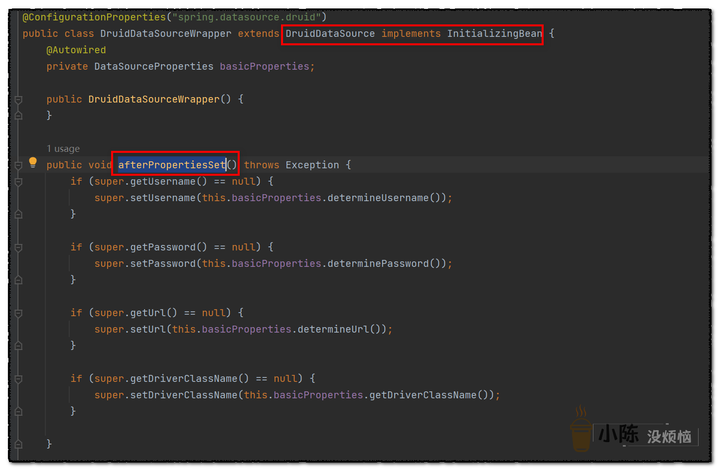
druid的数据源配置,实现了接口中afterPropertiesSet,在这个方法中设置了数据库的基本信息,例如,数据库连接地址、用户名、密码以及数据库连接驱动信息。