AI视野·今日CS.Robotics 机器人学论文速览
Fri, 29 Sep 2023
Totally 38 papers
👉上期速览✈更多精彩请移步主页

Interesting:
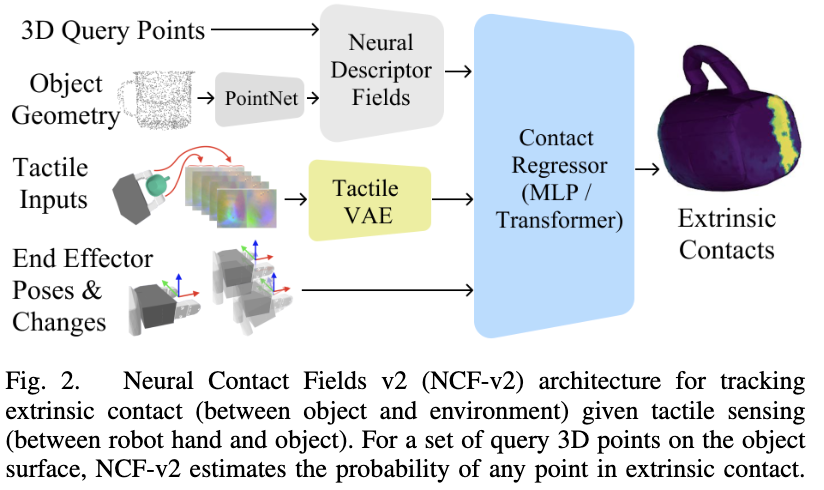
📚NCF,基于Neural Contact Fields神经接触场的方法实现有效的外部接触估计和插入操作。 (from FAIR )
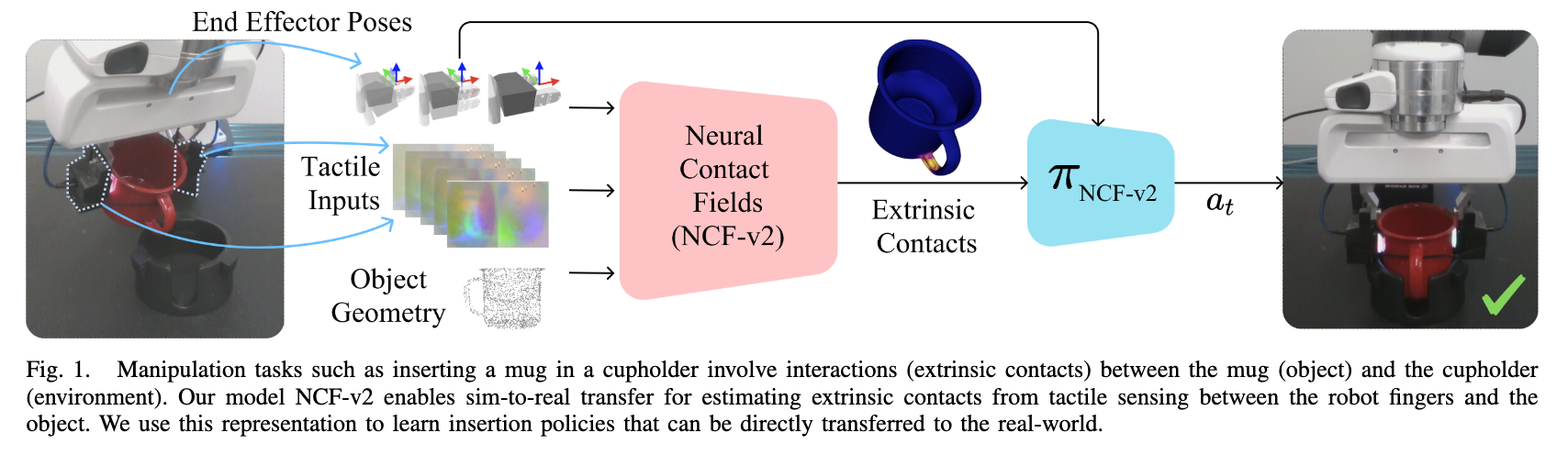
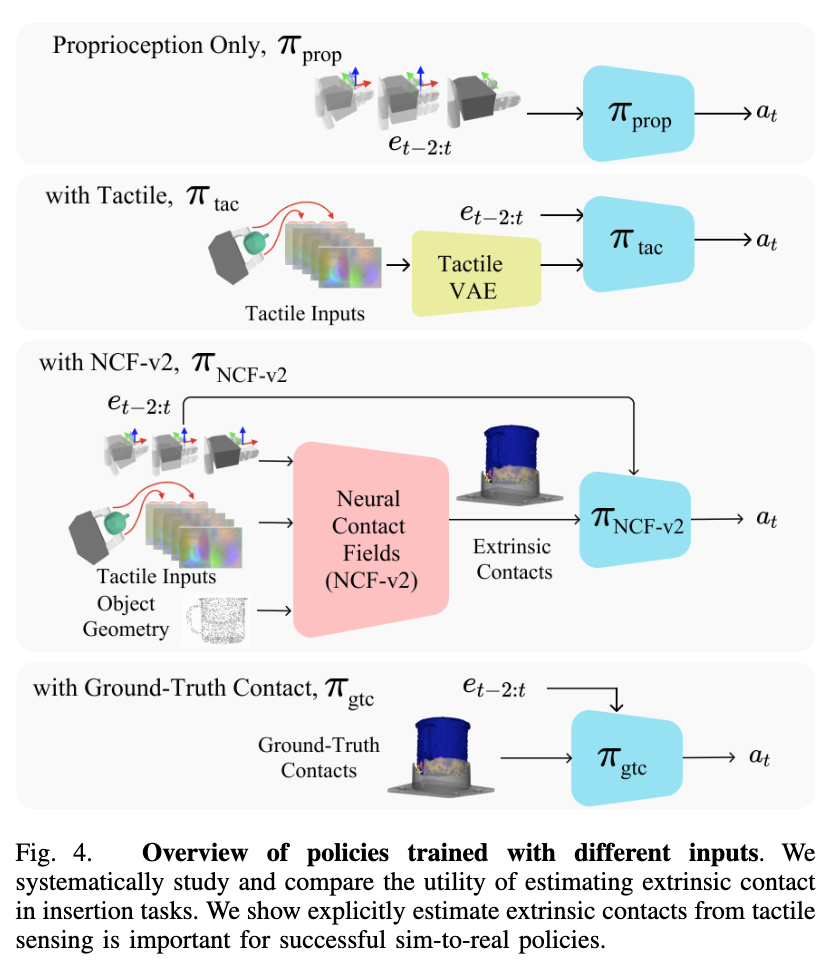
操作插入处理结果:

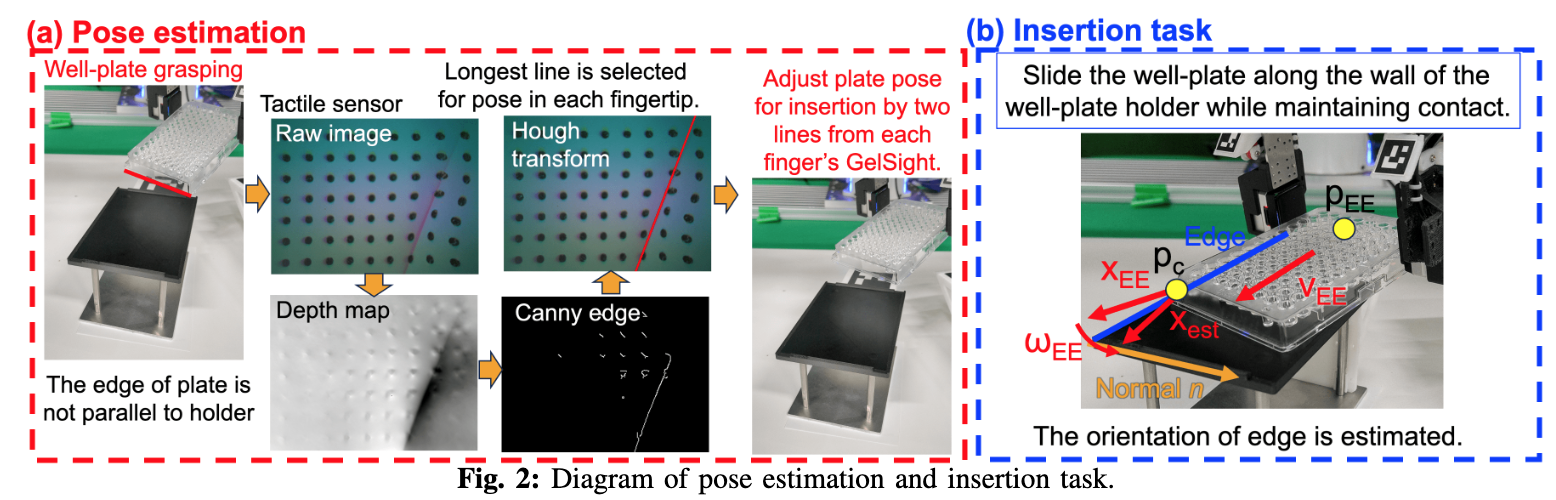
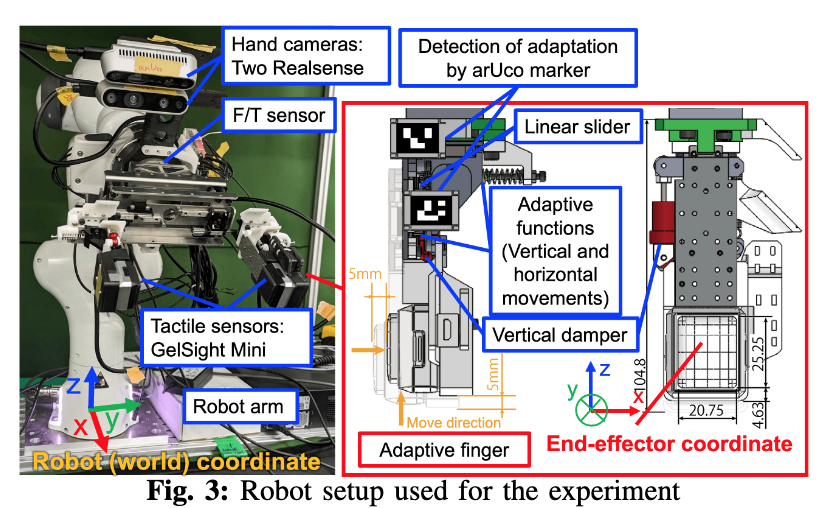
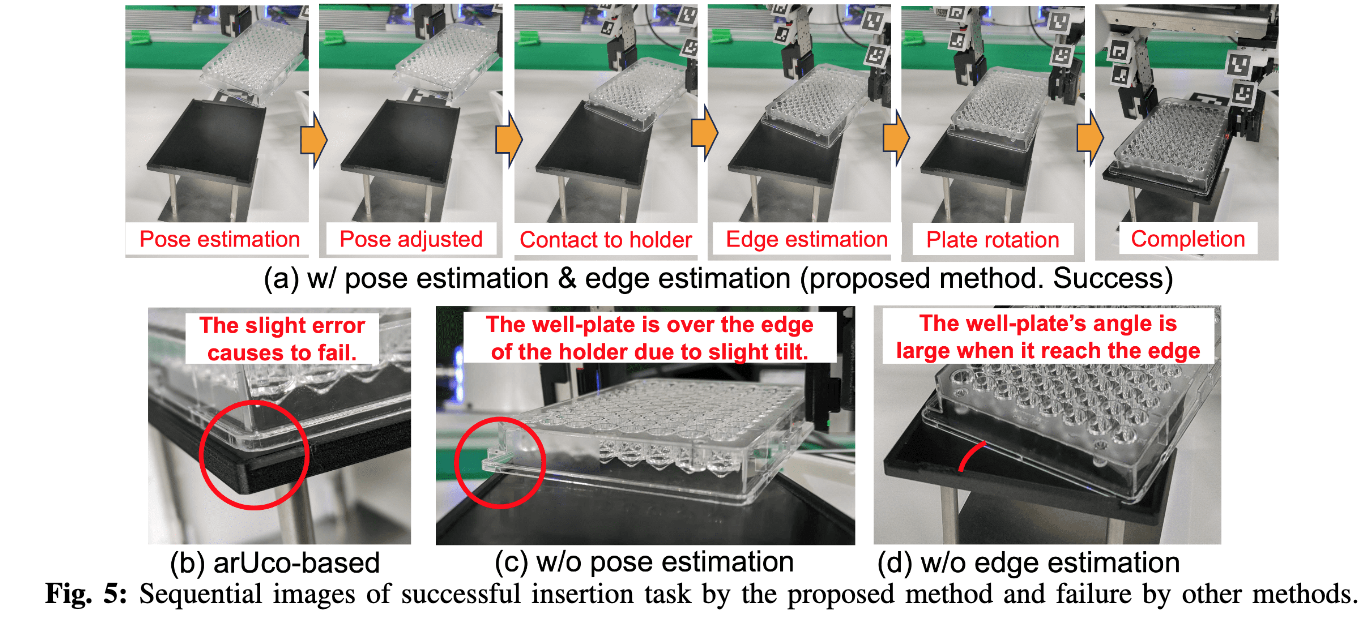
📚Laboratory Automation, 基于触觉的精细操作用于自适应孔板插入,实现化学实验自动化。(from MIT)

 website:
website:
https://drive.google.com/file/d/1UxyJ3XIxqXPnHcpfw-PYs5T5oYQxoc6i/view?usp=sharing
Daily Robotics Papers
| HyperPPO: A scalable method for finding small policies for robotic control Authors Shashank Hegde, Zhehui Huang, Gaurav S. Sukhatme 对于内存有限的高性能机器人的神经控制来说,参数较少的模型是必要的。找到这些较小的神经网络架构可能非常耗时。我们提出了 HyperPPO,一种策略强化学习算法,利用图超网络同时估计多个神经架构的权重。我们的方法估计的网络权重比常用网络小得多,但编码高性能策略。我们同时获得多个经过训练的策略,同时保持样本效率,并为用户提供选择满足其计算约束的网络架构的选择。我们表明,我们的方法可以很好地扩展更多的训练资源,从而更快地收敛到更高性能的架构。我们证明了 HyperPPO 估计的神经策略能够对 Crazyflie2.1 四旋翼飞行器进行分散控制。 |
| Perceiving Extrinsic Contacts from Touch Improves Learning Insertion Policies Authors Carolina Higuera, Joseph Ortiz, Haozhi Qi, Luis Pineda, Byron Boots, Mustafa Mukadam 诸如对象插入之类的机器人操作任务通常涉及对象与环境之间的交互,即外部接触。神经接触场的先前工作 NCF 使用夹具和物体之间的内在触觉感知来估计模拟中的外在接触。 |
| ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning Authors Qiao Gu, Alihusein Kuwajerwala, Sacha Morin, Krishna Murthy Jatavallabhula, Bipasha Sen, Aditya Agarwal, Corban Rivera, William Paul, Kirsty Ellis, Rama Chellappa, Chuang Gan, Celso Miguel de Melo, Joshua B. Tenenbaum, Antonio Torralba, Florian Shkurti, Liam Paull 为了使机器人能够执行各种任务,它们需要对世界进行 3D 表示,该表示在语义上丰富,但紧凑且高效,以实现任务驱动的感知和规划。最近的方法尝试利用大型视觉语言模型的特征来编码 3D 表示中的语义。然而,这些方法往往会生成具有每点特征向量的地图,这些地图在较大的环境中不能很好地扩展,也不包含环境中实体之间的语义空间关系,而这对于下游规划很有用。在这项工作中,我们提出了 ConceptGraphs,一种用于 3D 场景的开放词汇图结构化表示。 ConceptGraphs 是通过利用 2D 基础模型并通过多视图关联将其输出融合到 3D 来构建的。所得表示可推广到新颖的语义类,无需收集大型 3D 数据集或微调模型。我们通过许多下游规划任务演示了这种表示的实用性,这些任务通过抽象语言提示指定,并且需要对空间和语义概念进行复杂的推理。 |
| Semantic Scene Difference Detection in Daily Life Patroling by Mobile Robots using Pre-Trained Large-Scale Vision-Language Model Authors Yoshiki Obinata, Kento Kawaharazuka, Naoaki Kanazawa, Naoya Yamaguchi, Naoto Tsukamoto, Iori Yanokura, Shingo Kitagawa, Koki Shinjo, Kei Okada, Masayuki Inaba 对于日常生活支持机器人来说,检测环境的变化并执行任务非常重要。在计算机视觉的异常检测领域,概率论和深度学习方法已被用来计算图像距离。这些方法通过关注图像像素来计算距离。相比之下,本研究旨在利用当前开发的大规模视觉语言模型来检测日常生活环境中的语义变化。利用其视觉问答 VQA 模型,我们提出了一种通过对参考图像和当前图像应用多个问题并以句子形式获得答案来检测语义变化的方法。与异常检测中基于深度学习的方法不同,该方法不需要任何训练或微调,不受噪声影响,并且对现实世界中的语义状态变化敏感。在我们的实验中,我们通过使用移动机器人 Fetch Mobile Manipulator 将其应用于现实生活环境中的巡逻任务,证明了该方法的有效性。 |
| Active SLAM Utility Function Exploiting Path Entropy Authors Muhammad Farhan Ahmed, Vincent Fr mont, Isabelle Fantoni 在本文中,我们提出了主动 SLAM 的效用函数 SLAM,它利用地图熵和 D 最优性标准度量来加权目标边界候选。我们提出了一种用于前沿目标选择的效用函数,该函数通过利用路径熵来利用占用网格地图,并有利于未知地图位置以获得最大区域覆盖,同时保持较低的定位和映射不确定性。我们使用环境探索任务的各种图连接矩阵和地图效率指数来量化我们方法的效率。 |
| db-CBS: Discontinuity-Bounded Conflict-Based Search for Multi-Robot Kinodynamic Motion Planning Authors Akmaral Moldagalieva, Joaquim Ortiz Haro, Marc Toussaint, Wolfgang H nig 本文提出了一种多机器人运动动力学运动规划器,使具有不同动力学、驱动极限和形状的机器人团队能够在具有挑战性的环境中实现其目标。我们通过结合基于冲突的搜索 CBS(一种多智能体路径查找方法)和不连续性有界 A(单个机器人运动动力学运动规划器)来解决这个问题。我们的方法 db CBS 在三个级别上运行。最初,我们使用图形搜索来计算单个机器人的轨迹,该搜索允许预先计算的运动基元之间存在有界的不连续性。第二层识别机器人之间的碰撞,并通过对第一层施加约束来解决它们。第三级也是最后一级使用具有不连续性的结果解决方案作为关节空间轨迹优化的初始猜测。以减少的不连续范围重复该过程。我们的方法是随时、概率完整、渐近最优的,并且可以快速找到接近最优的解决方案。 |
| QwenGrasp: A Usage of Large Vision Language Model for Target-oriented Grasping Authors Xinyu Chen, Jian Yang, Zonghan He, Haobin Yang, Qi Zhao, Yuhui Shi 机器人系统理解人类语言并执行抓取动作的能力是机器人领域的一个关键挑战。在面向目标的抓取中,先前的研究实现了人类文本命令与目标物体图像的匹配。然而,这些作品很难理解复杂或灵活的指令。此外,这些作品缺乏自主评估指令可行性的能力,导致即使没有目标物体也盲目执行抓取任务。在本文中,我们介绍了一种名为 QwenGrasp 的组合模型,它将大型视觉语言模型与 6 DoF 抓取网络相结合。通过利用预先训练的大型视觉语言模型,我们的方法能够在具有自然人类语言环境的开放世界中工作,接受复杂而灵活的指令。此外,专门的抓取网络确保了生成的抓取姿势的有效性。在现实世界环境中进行的一系列实验表明,我们的方法表现出理解人类意图的卓越能力。 |
| Intrinsic Language-Guided Exploration for Complex Long-Horizon Robotic Manipulation Tasks Authors Eleftherios Triantafyllidis, Filippos Christianos, Zhibin Li 当前的强化学习算法在稀疏和复杂的环境中举步维艰,尤其是在需要大量不同序列的长范围操作任务中。在这项工作中,我们提出了大型语言模型 IGE LLM 框架的本质引导探索。通过利用法学硕士作为辅助内在奖励,IGE 法学硕士指导强化学习的探索过程,以解决复杂的长视野和稀疏奖励的机器人操作任务。我们在充满探索挑战的环境以及受到探索和长期视野挑战的复杂机器人操作任务中评估我们的框架和相关的内在学习方法。结果表明,IGE LLM i 比相关内在方法和在决策中直接使用 LLM 表现出明显更高的性能,ii 可以组合并补充现有的学习方法,突出其模块化性,iii 对不同的内在缩放参数相当不敏感,iv 保持鲁棒性 |
| Online Estimation of Articulated Objects with Factor Graphs using Vision and Proprioceptive Sensing Authors Russell Buchanan, Adrian R fer, Jo o Moura, Abhinav Valada, Sethu Vijayakumar 从洗碗机到橱柜,人类每天都会与铰接物体互动,而对于协助完成常见操作任务的机器人来说,它必须学习铰接的表示。最近的深度学习方法可以根据先前(可能是模拟的)经验中铰接对象的可供性,提供基于先验的强大视觉。相比之下,许多作品通过观察运动中的物体来估计关节,要求机器人已经与物体进行交互。在这项工作中,我们建议通过引入一种在线估计方法来利用两全其美的方法,该方法将神经网络中基于视觉的可供性预测与分析模型中的交互式运动传感相结合。我们的工作的优点是在触摸物体之前使用视觉来预测关节模型,同时还能够在交互过程中通过运动感测快速更新模型。在本文中,我们使用共享自主权来实现一个完整的系统,用于机器人打开铰接物体,特别是仅从视觉中看不到铰接的物体。我们在真实的机器人上实现了我们的系统,并进行了几次自主闭环实验,其中机器人必须打开一扇未知关节的门,同时在线估计关节。 |
| CasIL: Cognizing and Imitating Skills via a Dual Cognition-Action Architecture Authors Zixuan Chen, Ze Ji, Shuyang Liu, Jing Huo, Yiyu Chen, Yang Gao 让机器人能够有效地模仿长期任务(如运动、操纵等)的专业技能,是一个长期存在的挑战。现有的机器人模仿学习 IL 方法仍然难以在复杂任务中实现次优性能。在本文中,我们考虑如何在人类认知先验的范围内解决这一挑战。启发式地,我们通过引入直观的人类认知先验,将通常的动作概念扩展到双认知高级动作低级架构,并通过人类机器人交互提出一种新颖的技能IL框架,称为基于认知动作的技能模仿学习CasIL,用于机器人代理可以有效地认知和模仿原始视觉演示中的关键技能。 CasIL 支持认知和动作模仿,而高水平技能认知明确指导低水平原始动作,为整个技能 IL 过程提供稳健性和可靠性。我们在 MuJoCo 和 RLBench 基准测试以及四足机器人运动的避障和点目标导航任务上评估了我们的方法。 |
| DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models Authors Licheng Wen, Daocheng Fu, Xin Li, Xinyu Cai, Tao Ma, Pinlong Cai, Min Dou, Botian Shi, Liang He, Yu Qiao 自动驾驶的最新进展依赖于数据驱动的方法,这些方法被广泛采用,但面临着数据集偏差、过度拟合和不可解释性等挑战。从人类驾驶的知识驱动本质中汲取灵感,我们探索了如何将类似的功能注入自动驾驶系统的问题,并总结了一个集成交互环境、驾驶员代理和记忆组件的范例来解决这个问题。利用具有涌现能力的大型语言模型,我们提出了DiLu框架,该框架结合了推理和反射模块,使系统能够基于常识知识进行决策并不断发展。大量的实验证明了DiLu具有积累经验的能力,并且在泛化能力上比基于强化学习的方法具有显着的优势。此外,DiLu能够直接从现实世界的数据集中获取经验,这凸显了其部署在实际自动驾驶系统上的潜力。 |
| GAMMA: Generalizable Articulation Modeling and Manipulation for Articulated Objects Authors Qiaojun Yu, Junbo Wang, Wenhai Liu, Ce Hao, Liu Liu, Lin Shao, Weiming Wang, Cewu Lu 橱柜和门等铰接式物体在日常生活中很常见。然而,直接操纵 3D 关节对象具有挑战性,因为它们具有不同的几何形状、语义类别和动力学约束。之前的工作主要集中在识别和操纵具有特定关节类型的铰接物体。他们可以估计关节参数或区分合适的抓取姿势以促进轨迹规划。尽管这些方法在某些类型的铰接物体上取得了成功,但它们缺乏对看不见的物体的通用性,这极大地阻碍了它们在更广泛的场景中的应用。在本文中,我们提出了一种针对关节对象的通用关节建模和操纵的新颖框架 GAMMA,它从不同类别的各种关节对象中学习关节建模和掌握姿势可供性。此外,GAMMA采用自适应操纵来迭代减少建模误差并增强操纵性能。我们使用 PartNet Mobility 数据集训练 GAMMA,并通过 SAPIEN 模拟和现实世界 Franka 机器人手臂的综合实验进行评估。结果表明,在看不见的跨类别关节对象中,GAMMA 显着优于 SOTA 关节建模和操作算法。我们将开源模拟机器人和真实机器人中的所有代码和数据集,以便在最终版本中重现。 |
| Off-the-shelf bin picking workcell with visual pose estimation: A case study on the world robot summit 2018 kitting task Authors Frederik Hagelskj r, Kasper H j Lorenzen, Dirk Kraft 2018 年世界机器人峰会装配挑战赛包括四项不同的任务。配套任务需要分箱拣选,是获得分数最少的任务。然而,垃圾箱拣选是一项至关重要的技能,可以显着提高机器人设置的灵活性,因此是一个重要的研究领域。近年来,传感器技术和姿态估计算法取得了进步。 |
| Sensorless Physical Human-robot Interaction Using Deep-Learning Authors Shilin Shan, Quang Cuong Pham 几十年来,物理人机交互一直是人们感兴趣的领域。协作任务(例如关节顺应性)需要高质量的关节扭矩传感。虽然外部扭矩传感器很可靠,但它们也存在价格昂贵且容易受到冲击的缺点。为了解决这些问题,人们进行了研究,仅使用内部信号(例如关节状态和电流测量值)来估计外部扭矩。然而,对摩擦滞后近似的关注还不够,这对于涉及广泛的动态到静态转换的任务至关重要。在本文中,我们提出了一种基于深度学习的方法,利用新颖的长期记忆方案来实现动态识别,准确地逼近静态滞后。我们还对众所周知的残差学习架构进行了修改,在保持高精度的同时减少推理时间。 |
| Laboratory Automation: Precision Insertion with Adaptive Fingers utilizing Contact through Sliding with Tactile-based Pose Estimation Authors Sameer Pai, Kuniyuki Takahashi, Shimpei Masuda, Naoki Fukaya, Koki Yamane, Avinash Ummadisingu 微孔板是化学和生物实验中常用的设备,其厚度为几厘米,其中有孔。我们要解决的任务是将它们放置在带有几毫米高凹槽的孔板支架上。我们的插入任务有以下几个方面: 1 孔板和孔板支架的位置和姿态的检测存在不确定性, 2 所需的精度在毫米到亚毫米的数量级, 3 孔板支架未紧固,并受外力移动,4槽浅,5槽宽度小。为了解决这些挑战,我们开发了一种自适应手指夹持器,可以精确检测手指位置,用于 1 , b 使用触觉传感器估计抓取物体的姿态,用于 1 , c 一种通过滑动孔板同时保持接触来将孔板插入目标支架的方法2 4 与保持器的边缘,并估计边缘的方向并对齐孔板,使得保持器在与 5 的边缘保持接触时不会移动。 |
| Learning to Terminate in Object Navigation Authors Yuhang Song, Anh Nguyen, Chun Yi Lee 本文解决了自主导航系统中目标导航的关键挑战,特别关注基于深度强化学习 DRL 的方法中具有长最佳情节长度的环境中的目标接近和情节终止问题。虽然传统的 DRL 方法在环境探索和对象定位方面有效,但由于缺乏深度信息,常常难以实现最佳路径规划和终止识别。为了克服这些限制,我们提出了一种新颖的方法,即深度推理终止代理 DITA,它结合了称为判断模型的监督模型来隐式推断对象深度并与强化学习联合决定终止。我们并行训练我们的判断模型和强化学习,并通过奖励信号有效地监督前者。我们的评估表明,该方法表现出卓越的性能,在所有房间类型中,我们的成功率比基准方法提高了 9.3,在长剧集环境中获得了 51.2 的改进,同时保持了稍微更好的按路径长度 SPL 加权的成功率。 |
| D$^3$Fields: Dynamic 3D Descriptor Fields for Zero-Shot Generalizable Robotic Manipulation Authors Yixuan Wang, Zhuoran Li, Mingtong Zhang, Katherine Driggs Campbell, Jiajun Wu, Li Fei Fei, Yunzhu Li 场景表示一直是机器人操纵系统中至关重要的设计选择。理想的表示应该是 3D、动态和语义的,以满足不同操作任务的需求。然而,以前的作品往往同时缺乏这三个属性。在这项工作中,我们引入了 D 3 Fields 动态 3D 描述符字段。这些字段捕获底层 3D 环境的动态并对语义特征和实例掩码进行编码。具体来说,我们将工作空间中的任意 3D 点投影到多视图 2D 视觉观察上,并插入从基础模型派生的特征。由此产生的融合描述符字段允许使用具有不同上下文、样式和实例的 2D 图像来实现灵活的目标规范。为了评估这些描述符字段的有效性,我们以零样本的方式将我们的表示应用于广泛的机器人操作任务。通过对现实世界场景和模拟的广泛评估,我们证明了 D 3 场对于零射击机器人操作任务来说既可推广又有效。 |
| Comparing Active Learning Performance Driven by Gaussian Processes or Bayesian Neural Networks for Constrained Trajectory Exploration Authors Sapphira Akins, Frances Zhu 自主能力不断增强的机器人提高了我们的太空探索能力,特别是在原地探索和采样方面,以代替人类探险家。目前,人类驾驶机器人来实现科学目标,但根据机器人的位置,人类操作员和机器人之间的信息交换和驾驶命令可能会导致任务完成的过度延迟。具有科学目标和探索策略的自主机器人不会产生通信延迟,并且可以更快地完成任务。主动学习算法提供了这种智能探索的能力,但底层模型结构改变了主动学习算法在准确形成对环境的理解方面的性能。在本文中,我们研究了由高斯过程或贝叶斯神经网络驱动的主动学习算法之间的性能差异,用于在轨迹受限的代理(例如行星表面漫游者)上编码的探索策略。这两种主动学习策略在模拟环境中与科学盲策略进行了测试,以预测感兴趣的变量沿多个数据集的空间分布。感兴趣的性能指标包括均方根 RMS 误差的模型精度、训练时间、模型收敛、收敛之前的总行驶距离以及收敛之前的样本总数。用高斯过程编码的主动学习策略需要更少的计算来训练,更快地收敛到准确的模型,并提出更短距离的轨迹,除了在一些复杂的环境中,贝叶斯神经网络在大数据范围内实现更准确的模型,因为到他们更具表现力的功能基础。 |
| Stackelberg Game-Theoretic Trajectory Guidance for Multi-Robot Systems with Koopman Operator Authors Yuhan Zhao, Quanyan Zhu 引导轨迹规划涉及领导者机器人代理战略性地指导跟随者机器人代理协作到达指定目的地。然而,当领导者缺乏对追随者决策模型的完整了解时,这项任务就变得非常具有挑战性。需要基于学习的方法来有效地设计合作计划。为此,我们开发了一种基于 Koopman 算子的 Stackelberg 博弈论方法来应对这一挑战。我们首先通过动态 Stackelberg 博弈的视角制定引导轨迹规划问题。然后,我们利用库普曼算子理论来获取基于学习的线性系统模型,该模型近似跟随者的反馈动态。基于这个学习模型,领导者采用后退地平线规划设计一条无碰撞轨迹来引导跟随者。我们使用模拟来阐述我们的方法在生成学习模型方面的有效性,与其他学习技术相比,该模型可以准确预测追随者的多步骤行为。 |
| Differentiable Robot Neural Distance Function for Adaptive Grasp Synthesis on a Unified Robotic Arm-Hand System Authors Yiting Chen, Xiao Gao, Kunpeng Yao, Lo c Niederhauser, Yasemin Bekiroglu, Aude Billard 抓取是机器人与环境交互的一项基本技能。虽然抓取执行需要手和手臂的协调运动以实现无碰撞和安全的抓握,但许多抓取综合研究独立地解决手臂和手的运动规划,导致在实际环境中可能无法实现抓取。确定集成手臂配置的挑战源于其计算复杂性和高维性质。我们通过提出一种新颖的可微机器人神经距离函数来解决这一挑战。我们的方法擅长捕获各种关节配置的复杂几何形状,同时保持可微性。事实证明,这种创新的表示方式有助于有效解决具有严格接触限制的下游任务。利用这一点,我们引入了一种自适应抓取合成框架,该框架充分利用统一手臂手系统的潜力来完成各种抓取任务。与基线方法相比,我们的神经关节空间距离函数的误差减少了 84.7。我们在统一机械臂手系统上验证了我们的方法,该系统由 7 DoF 机械臂和 16 DoF 多指机械手组成。 |
| A Modular Bio-inspired Robotic Hand with High Sensitivity Authors Chao Liu, Andrea Moncada, Hanna Matusik, Deniz Irem Erus, Daniela Rus 虽然平行夹持器和多指机器人手已得到很好的发展,并且在结构化环境中普遍使用,但设计一种高度铰接的机器人手,使其能够与人手相媲美,以处理各种日常操作和抓取任务,仍然是机器人技术中的一个挑战。灵活性通常需要更多的执行器,但也会导致更复杂的机构设计,并且制造和维护成本更高。软材料在与物理世界交互时能够提供合规性和安全性,但难以建模。这项工作提出了一种混合生物启发的机器人手,结合了软物质和刚性元素。传感被集成到刚体中,从而提供了一种简单的高灵敏度姿态估计方法。所提出的手采用模块化结构,允许快速制造和编程。制造过程经过精心设计,以便可以用低成本材料制造全手并以有效的方式组装。 |
| Task-Oriented Koopman-Based Control with Contrastive Encoder Authors Xubo Lyu, Hanyang Hu, Seth Siriya, Ye Pu, Mo Chen 我们提出了面向任务的基于库普曼的控制,它利用端到端强化学习和对比编码器在迭代循环中同时学习库普曼潜在嵌入、运算符和相关线性控制器。 |
| Infer and Adapt: Bipedal Locomotion Reward Learning from Demonstrations via Inverse Reinforcement Learning Authors Feiyang Wu, Zhaoyuan Gu, Hanran Wu, Anqi Wu, Ye Zhao 由于机器人动力学和交互环境的复杂性,让双足步行机器人学习如何在高度不平坦、动态变化的地形上进行机动是一项挑战。最近在演示学习方面取得的进展已经显示出复杂环境中机器人学习的有希望的结果。虽然专家策略的模仿学习已经得到了很好的探索,但学习专家奖励函数的研究在很大程度上还没有在腿运动中得到探索。本文采用最先进的逆强化学习 IRL 技术来解决复杂地形上的双足运动问题。我们提出了学习专家奖励函数的算法,然后我们分析了学习到的函数。通过非线性函数近似,我们发现了对专家运动策略的有意义的见解。 |
| WiDEVIEW: An UltraWideBand and Vision Dataset for Deciphering Pedestrian-Vehicle Interactions Authors Jia Huang, Alvika Gautam, Junghun Choi, Srikanth Saripalli 对行人和骑自行车者等道路使用者的稳健、准确的跟踪和定位对于确保自动驾驶汽车安全有效的导航至关重要,特别是在具有复杂车辆行人交互的城市驾驶场景中。可用于研究车辆行人交互的现有数据集大多以图像为中心,因此容易受到视觉故障的影响。在本文中,我们研究超宽带 UWB 作为道路使用者定位的附加模式,以便更好地理解车辆行人交互。我们推出了 WiDEVIEW,这是第一个集成 LiDAR、三个 RGB 摄像头、GPS IMU 和 UWB 传感器的多模态数据集,用于捕获城市自动驾驶场景中的车辆行人交互。地面实况图像注释以 2D 边界框的形式提供,并且数据集根据标准 2D 对象检测和跟踪算法进行评估。使用 LiDAR 作为地面实况,在视距和非视距条件下的典型交通场景中评估了 UWB 的可行性。我们确定 UWB 距离数据的精度与 LiDAR 相当,误差为 0.19 米,并且在视线条件下可靠的锚标签距离数据可达 40 米。非视线条件下的 UWB 性能取决于障碍物树木与建筑物的性质。此外,我们还针对易受间歇性视力障碍影响的场景提供了 UWB 性能的定性分析。 |
| OceanChat: Piloting Autonomous Underwater Vehicles in Natural Language Authors Ruochu Yang, Mengxue Hou, Junkai Wang, Fumin Zhang 在融合大型语言模型法学硕士和机器人技术的趋势研究中,我们的目标是为人工智能系统的创新开发铺平道路,使自主水下航行器AUV能够以直观的方式与人类无缝交互。我们提出了 OceanChat,这是一个利用闭环 LLM 引导任务和运动规划框架来解决野外 AUV 任务的系统。法学硕士将抽象的人类命令转化为高级目标,而任务规划器进一步将目标转化为具有逻辑约束的任务序列。为了帮助 AUV 理解任务序列,我们利用运动规划器合并 AUV 接收到的实时拉格朗日数据流,从而将任务序列映射到可执行的运动计划。考虑到水下环境的高度动态和部分已知的性质,开发了事件触发的重新规划方案以增强系统对不确定性的鲁棒性。我们还构建了一个模拟平台 HoloEco,可为各种 AUV 应用生成逼真的模拟。实验评估验证了所提出的系统可以在成功率和计算时间方面实现改进的性能。 |
| DynaCon: Dynamic Robot Planner with Contextual Awareness via LLMs Authors Gyeongmin Kim, Taehyeon Kim, Shyam Sundar Kannan, Vishnunandan L. N. Venkatesh, Donghan Kim, Byung Cheol Min 移动机器人通常依靠预先存在的地图来进行有效的路径规划和导航。然而,当这些地图不可用时,特别是在不熟悉的环境中,就必须采用不同的方法。本文介绍了 DynaCon,这是一种新颖的系统,旨在为移动机器人提供导航过程中的情境感知和动态适应性,从而消除对传统地图的依赖。 DynaCon 将实时反馈与对象服务器、提示工程和导航模块集成在一起。通过利用大型语言模型 LLM 的功能,DynaCon 不仅可以理解给定数字序列中的模式,而且还擅长将对象分类到匹配的空间中。这有利于充满情境意识的动态路径规划器。我们通过一项实验验证了 DynaCon 的有效性,其中机器人使用推理成功导航到其目标。 |
| Enabling Large-scale Heterogeneous Collaboration with Opportunistic Communications Authors Fernando Cladera, Zachary Ravichandran, Ian D. Miller, M. Ani Hsieh, C. J. Taylor, Vijay Kumar 在团队规模有限且没有外部基础设施的大规模环境中进行多机器人协作具有挑战性,因为支持复杂任务所需的软件框架必须能够应对不可靠和间歇性的通信链路。在这项工作中,我们提出了用于异构协作的 MOCHA 多机器人机会通信,这是一种弹性多机器人协作框架,可以在缺乏连续通信的情况下实现大规模探索。 MOCHA 基于八卦通信协议,该协议允许机器人在通信链路可用时进行机会性交互,在点对点的基础上传播信息。我们通过使用商用现成 COTS 通信硬件进行现实世界实验来演示 MOCHA 的性能。我们进一步探索系统在模拟中的可扩展性,随着机器人数量的增加和通信范围的变化评估我们的方法的性能。最后,我们演示了 MOCHA 如何与自主机器人的规划堆栈紧密集成。我们展示了一种通信感知规划算法,用于高空空中机器人执行协作任务,同时最大化与地面机器人共享的信息量。 |
| Accelerating Motion Planning via Optimal Transport Authors An T. Le, Georgia Chalvatzaki, Armin Biess, Jan Peters 对于机器人、自动驾驶等许多学科来说,运动规划仍然是一个悬而未决的问题,因为规划时间长等问题阻碍了实时、高效的决策。一类致力于提供平滑解决方案的方法是基于梯度的轨迹优化。然而,这些方法可能会受到不良局部最小值的影响,而对于许多设置,它们可能由于无法轻松访问目标梯度而不适用。针对这些问题,我们引入了通过最佳传输 MPOT 进行运动规划,这是一种无梯度方法,即使对于高维任务,也可以在高度非线性成本上优化一批平滑轨迹,同时通过高斯过程动力学先验通过规划作为推理角度来施加平滑度。为了促进批量轨迹优化,我们引入了一种原始的零阶和高度并行化的更新规则 Sinkhorn Step,它使用正则多面体族作为其搜索方向,每个正则多面体以轨迹路点为中心,充当局部邻域,有效地充当信任区域,Sinkhorn Step 将当地路径点运送到低成本区域。我们从理论上证明,Sinkhorn Step 将优化参数引导至非凸目标函数上的局部最小值区域。 |
| Hybrid Volitional Control of a Robotic Transtibial Prosthesis using a Phase Variable Impedance Controller Authors Ryan R. Posh, Jonathan A. Tittle, David J. Kelly, James P. Schmiedeler, Patrick M. Wensing 对于机器人经胫骨假体控制,胫骨的整体运动学可用于监测步态周期的进展并命令平滑和连续的驱动。在这项工作中,这些全局胫骨运动学用于定义相位可变阻抗控制器 PVIC ,然后将其实现为混合意志控制框架 PVI HVC 内的非意志基础控制器。通过旁路适配器在机器人脚踝假肢上行走的一个身体健全的人的步态进展估计和生物力学性能与三种控制方案(被动基准控制器、PVIC 和 PVI HVC)进行了比较。每个控制器的不同驱动对全局胫骨运动学有直接影响,但每个控制器的估计步态百分比与地面真实步态百分比之间的平均偏差分别为 1.6 、 1.8 和 2.1 。 PVIC 和 PVI HVC 都与健全的运动学和动力学参考产生了良好的一致性。按照设计,当用户使用低意志意图时,PVI HVC 结果与 PVIC 的结果相似,但当用户在后期姿势命令高意志输入时,会产生更高的峰值跖屈、峰值扭矩和峰值功率。这种额外的扭矩和功率还允许用户自愿、连续地完成水平行走以外的活动,例如上升坡道、避开障碍物、踮起脚尖站立和轻拍脚。 |
| Scalable Multi-Robot Collaboration with Large Language Models: Centralized or Decentralized Systems? Authors Yongchao Chen, Jacob Arkin, Yang Zhang, Nicholas Roy, Chuchu Fan 最近的一系列工作表明,预先训练的大型语言模型 LLM 可以成为各种单一机器人任务的有效任务规划器。通过提示技术(例如上下文学习或状态反馈重新提示),法学硕士的规划绩效得到显着提高,从而使上下文窗口的代币预算变得更加重要。一个尚未探索但自然的下一个方向是研究法学硕士作为多机器人任务规划器。然而,长视野、异构多机器人规划带来了新的协调挑战,同时也突破了上下文窗口长度的限制。因此,找到代币高效的法学硕士规划框架至关重要,该框架还能够推理多机器人协调的复杂性。在这项工作中,我们比较了四种多智能体通信框架(集中式、分散式和两种混合式)的任务成功率和令牌效率,应用于四种依赖于协调的多智能体 2D 任务场景(智能体数量不断增加)。我们发现混合框架在所有四项任务中实现了更好的任务成功率,并且可以更好地扩展到更多代理。我们进一步演示了 3D 模拟中的混合框架,其中考虑了视觉到文本问题和动态误差。 |
| Context-Aware Entity Grounding with Open-Vocabulary 3D Scene Graphs Authors Haonan Chang, Kowndinya Boyalakuntla, Shiyang Lu, Siwei Cai, Eric Jing, Shreesh Keskar, Shijie Geng, Adeeb Abbas, Lifeng Zhou, Kostas Bekris, Abdeslam Boularias 我们提出了一个开放词汇 3D 场景图 OVSG,这是一个正式框架,用于通过基于自由格式文本的查询来支持各种实体,例如对象实例、代理和区域。与传统的基于语义的对象定位方法不同,我们的系统促进了上下文感知实体定位,允许进行查询,例如拿起厨房桌子上的杯子或导航到某人坐的沙发。与现有的 3D 场景图研究相比,OVSG 支持自由格式文本输入和开放词汇查询。通过使用 ScanNet 数据集和自收集数据集的一系列比较实验,我们证明我们提出的方法显着超越了以前基于语义的定位技术的性能。 |
| MotionLM: Multi-Agent Motion Forecasting as Language Modeling Authors Ari Seff, Brian Cera, Dian Chen, Mason Ng, Aurick Zhou, Nigamaa Nayakanti, Khaled S. Refaat, Rami Al Rfou, Benjamin Sapp 对道路代理未来行为的可靠预测是自动驾驶车辆安全规划的关键组成部分。在这里,我们将连续轨迹表示为离散运动标记序列,并将多智能体运动预测作为该领域的语言建模任务。我们的模型 MotionLM 具有几个优点:首先,它不需要锚或显式潜变量优化来学习多模态分布。相反,我们利用单一标准语言建模目标,最大化序列标记的平均对数概率。其次,我们的方法绕过了事后交互启发法,其中个体代理轨迹生成是在交互评分之前进行的。相反,MotionLM 在单个自回归解码过程中生成交互式代理未来的联合分布。此外,模型的顺序分解可以实现临时因果条件推出。 |
| HOI4ABOT: Human-Object Interaction Anticipation for Human Intention Reading Collaborative roBOTs Authors Esteve Valls Mascaro, Daniel Sliwowski, Dongheui Lee 机器人越来越融入我们的生活,协助我们完成各种任务。为了确保人类和机器人之间的有效协作,他们必须理解我们的意图并预测我们的行动。在本文中,我们提出了一种用于协作机器人的人机交互 HOI 预期框架。我们提出了一种高效且稳健的基于 Transformer 的模型来检测和预测视频中的 HOI。这种增强的预期使机器人能够主动协助人类,从而实现更高效、更直观的协作。我们的模型在 VidHOI 数据集中的 HOI 检测和预测方面优于最先进的结果,mAP 分别增加了 1.76 和 1.04,同时速度提高了 15.4 倍。我们通过真实机器人的实验结果展示了我们方法的有效性,证明机器人预测 HOI 的能力是更好的人机交互的关键。 |
| An Enhanced Low-Resolution Image Recognition Method for Traffic Environments Authors Zongcai Tan, Zhenhai Gao 目前,低分辨率图像识别在智能交通感知领域面临着重大挑战。与高分辨率图像相比,低分辨率图像尺寸小、质量低、缺乏细节,导致传统神经网络识别算法的准确率显着下降。低分辨率图像识别的关键在于有效的特征提取。因此,本文深入研究了残差模块的基本维度及其对特征提取和计算效率的影响。基于实验,我们引入了一种双分支残差网络结构,该结构利用残差网络的基本架构和通用特征子空间算法。此外,它还利用中间层特征来提高低分辨率图像识别的准确性。此外,我们采用知识蒸馏来减少网络参数和计算开销。 |
| A Comprehensive Review on Tree Detection Methods Using Point Cloud and Aerial Imagery from Unmanned Aerial Vehicles Authors Weijie Kuang, Hann Woei Ho, Ye Zhou, Shahrel Azmin Suandi, Farzad Ismail 无人机被认为是尖端技术,具有极高的成本效益和灵活的使用场景。尽管许多论文对无人机在农业中的应用进行了综述,但对树木检测应用的综述仍然不足。本文重点研究应用于无人机采集的无人机数据的树木检测方法。有两种数据,点云和图像,分别由光探测和测距激光雷达传感器和相机获取。在利用点云数据的检测方法中,本文主要按照LiDAR和数字航空摄影DAP对这些方法进行分类。对于直接使用图像的检测方法,本文通过是否使用深度学习DL方法来回顾这些方法。我们的综述总结并分析了基于LiDAR和基于DAP的点云数据的应用的比较和组合。还介绍了这些方法的性能、相对优点和应用领域。同时,本文还统计了近年来使用不同方法进行的树木检测研究的数量。从我们的统计数据来看,到 2022 年,随着基于 DL 的检测研究数量增加到树木检测研究总数的 45 个,在图像上使用 DL 方法的检测任务已成为主流趋势。因此,这篇综述可以帮助和 |
| Leveraging Untrustworthy Commands for Multi-Robot Coordination in Unpredictable Environments: A Bandit Submodular Maximization Approach Authors Zirui Xu, Xiaofeng Lin, Vasileios Tzoumas 我们研究在不可预测和部分可观察的环境中具有不可信外部命令的多代理协调问题。这些命令是向机器人建议的动作,并且不可信,因为它们的性能保证(如果有)是未知的。此类命令可能由人类操作员或机器学习算法生成,尽管不可信,但通常可以提高机器人在复杂的多机器人任务中的性能。我们受到复杂的多机器人任务的激励,例如目标跟踪、环境测绘和区域监控。由于机器人之间的信息重叠,此类任务通常被建模为子模最大化问题。我们提供了一种算法,Meta Bandit Sequential Greedy MetaBSG,即使外部命令任意糟糕,它也能保证性能。 MetaBSG 利用元算法来学习机器人是否应该遵循命令,或者利用最近开发的子模块协调算法 Bandit Sequential Greedy BSG 1 ,即使在不可预测和部分可观察的环境中,该算法也能保证性能。特别是,MetaBSG 渐进地可以从命令和 BSG 算法中获得更好的性能,事后根据最优时变多机器人动作量化其次优性。因此,MetaBSG 可以被解释为增强不可信命令的鲁棒性。 |
| Symbolic Imitation Learning: From Black-Box to Explainable Driving Policies Authors Iman Sharifi, Saber Fallah 当前的模仿学习 IL 方法主要基于深度神经网络,为从现实世界数据中获取驾驶策略提供了有效的手段,但在可解释性和泛化性方面存在重大限制。这些缺点在自动驾驶等安全关键应用中尤其令人担忧。在本文中,我们通过引入符号模仿学习 SIL 来解决这些局限性,这是一种突破性的方法,采用归纳逻辑编程 ILP 来学习透明、可解释且可从可用数据集中推广的驾驶策略。利用现实世界的高维数据集,我们将我们的方法与流行的基于神经网络的 IL 方法进行严格的比较分析。我们的结果表明,SIL 不仅增强了驾驶政策的可解释性,而且还显着提高了其在不同驾驶情况下的适用性。 |
| Model Predictive Planning: Towards Real-Time Multi-Trajectory Planning Around Obstacles Authors Matthew T. Wallace, Brett Streetman, Laurent Lessard 本文提出了一种称为模型预测规划 MPP 的运动规划方案,旨在优化穿过障碍物环境的轨迹。该方法涉及路径规划、通过二次规划求解来细化轨迹以及实时选择最佳轨迹。该论文重点介绍了三项技术创新:基于光线追踪的轨迹细化路径、该技术与多路径规划器的集成以克服局部极小值造成的困难,以及在轨迹优化中实现时间尺度分离的方法。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com