文章目录
- 基于管道持久化存储操作
- scrapy的使用步骤
- 1.先转到想创建工程的目录下:cd ...
- 2.创建一个工程
- 3.创建之后要转到工程目录下
- 4.在spiders子目录中创建一个爬虫文件
- 5.执行工程
- setting文件中的参数
- 基于管道持久化存储的步骤:
- 持久化存储1:保存到本地txt文档。
- 1. 数据解析
- 2. 在item类中定义相关的属性
- 3. 将解析的数据封装存储到item类型的对象
- 4. 将item类型的对象提交给管道进行持久化存储的操作
- 5. 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
- 6. 在配置文件中开启管道
- 运行结果:
- 持久化存储2:保存到数据库中。
- 前言
- 安装mysql
- 安装navicat
- 使用终端操作数据库
- 如何使用navicat新建数据库&新建表
- 1234步与持久化存储1完全相同。
- 5. 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
- 6. 在配置文件中开启管道
- 运行结果
- 后记:
基于管道持久化存储操作
这个也是在基于scrapy框架的基础上实现的,所以scrapy的基本使用命令也是需要遵从的
scrapy的使用步骤
1.先转到想创建工程的目录下:cd …
2.创建一个工程
scrapy startproject 工程名 (XXPro:XXproject)
3.创建之后要转到工程目录下
cd 工程名
4.在spiders子目录中创建一个爬虫文件
这里不需要切换目录,在项目目录下即可。
www.xxx.com是要爬取的网站。
scrapy genspider 爬虫文件名 www.xxx.com
5.执行工程
在pycharm中直接执行是不管用的,无效。应该再在终端中执行
scrapy crawl 爬虫文件名 # 执行的是爬虫文件
setting文件中的参数
项目下有一个settings文件,里面的文件介绍如下:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False#显示指定类型的日志信息 而不显示其他乱七八糟的
LOG_LEVEL = 'ERROR'# 设置用户代理 浏览器类型
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"# 取消注释改行,意味着开启管道存储。
# 300表示优先级,数值越小优先级越高
ITEM_PIPELINES = {"weiboPro.pipelines.WeiboproPipeline": 300,
}基于管道持久化存储的步骤:
1. 数据解析
2. 在item类中定义相关的属性
3. 将解析的数据封装存储到item类型的对象
4. 将item类型的对象提交给管道进行持久化存储的操作
5. 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
6. 在配置文件中开启管道
持久化存储1:保存到本地txt文档。
这个并不是很难。主要是理清他的思路是什么。
在工程目录下的爬虫文件(这里是weibo.py)写好保证能够爬取到信息之后,主要是将管道文件写好(pipelines.py)。
按照上面的6步走:
1. 数据解析
即爬取数据的过程
# (weibo.py爬虫文件)
# 不使用数据库,只保存到本地import scrapy
from weiboPro.items import WeiboproItem
# 导包失败:右键项目目录 => 将目标标记为 => 源代码根目录# 爬取微博失败了,返回为空。改为爬取B站了。
# 爬取B站的视频的名称和作者
class WeiboSpider(scrapy.Spider):name = "weibo"# allowed_domains = ["weibo.com"]start_urls = ["https://www.bilibili.com/"]def parse(self, response):author = []title = []div_list = response.xpath('//*[@id="i_cecream"]/div[2]/main/div[2]/div/div[1]/div')print("数据长度为", len(div_list))for div in div_list:# xpath返回的是列表,但是列表元素一定是Selector类型的对象# extract可以将Selector对象中data参数存储的字符串提取出来author = div.xpath('.//div[@class="bili-video-card__info--right"]//a/span[@class="bili-video-card__info--author"]/text()').extract() # xpath要从上一层的xpath开始找,必须在最前面加个. !!# 对列表调用extract后,将列表的每一个Selector对象中的data对应的字符串提取了出来title=div.xpath('.//div[@class="bili-video-card__info--right"]/h3/a/text()').extract()# author, title解析到的为list,将其转为str# 将列表转为字符串: .join方法author = ''.join(author)title = ''.join(title)print('当前抽取的author', author)print('当前抽取的title', title)print(len(author), len(title))# 3,4两步都在循环内,所以是每执行一次循环将item对象提交给管道并存储到本地# 3.将解析的数据封装存储到item类型的对象item = WeiboproItem()item['author'] = authoritem['title'] = title# 4. 将item类型的对象提交给管道进行持久化存储的操作yield item
2. 在item类中定义相关的属性
找到项目目录下的items.py文件,在里面定义相关的属性
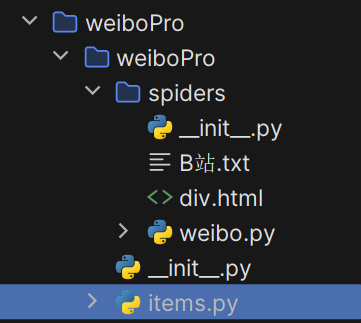
class WeiboproItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 在item类中定义相关的属性author = scrapy.Field()title = scrapy.Field()3. 将解析的数据封装存储到item类型的对象
4. 将item类型的对象提交给管道进行持久化存储的操作
3,4两步在1.中已经体现,具体代码为:
# 3.将解析的数据封装存储到item类型的对象item = WeiboproItem()item['author'] = authoritem['title'] = title# 4. 将item类型的对象提交给管道进行持久化存储的操作yield item
5. 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
在这里重写了父类的两个方法:open_spider()和close_spider()方法。
open_spider()方法在开始爬虫时被调用一次,close_spider()方法在爬虫结束时被调用一次。这样实现了yield多次时,只打开关闭一次文件。
process_item()是将得到的item对象中的数据保存到本地。
# pipelines.py 管道文件
class WeiboproPipeline:fp = Nonedef open_spider(self, spider):# 重写父类的方法,只在开始爬虫时被调用一次print("开始爬虫")self.fp = open('./B站.txt', 'w', encoding='utf-8')def process_item(self, item, spider):author = item['author']title = item['title']print("当前写入的是:" + author + ":" + title + "\n")self.fp.write(author + ":" + title + "\n")return itemdef close_spider(self, spider):# 重写父类的方法,在爬虫结束时被调用一次print("结束爬虫")self.fp.close()
6. 在配置文件中开启管道
打开项目weiboPro路径下的settings.py文件,将ITEM_PIPELINES字典取消注释,即可开启管道。
ITEM_PIPELINES = {"weiboPro.pipelines.WeiboproPipeline": 300,
}
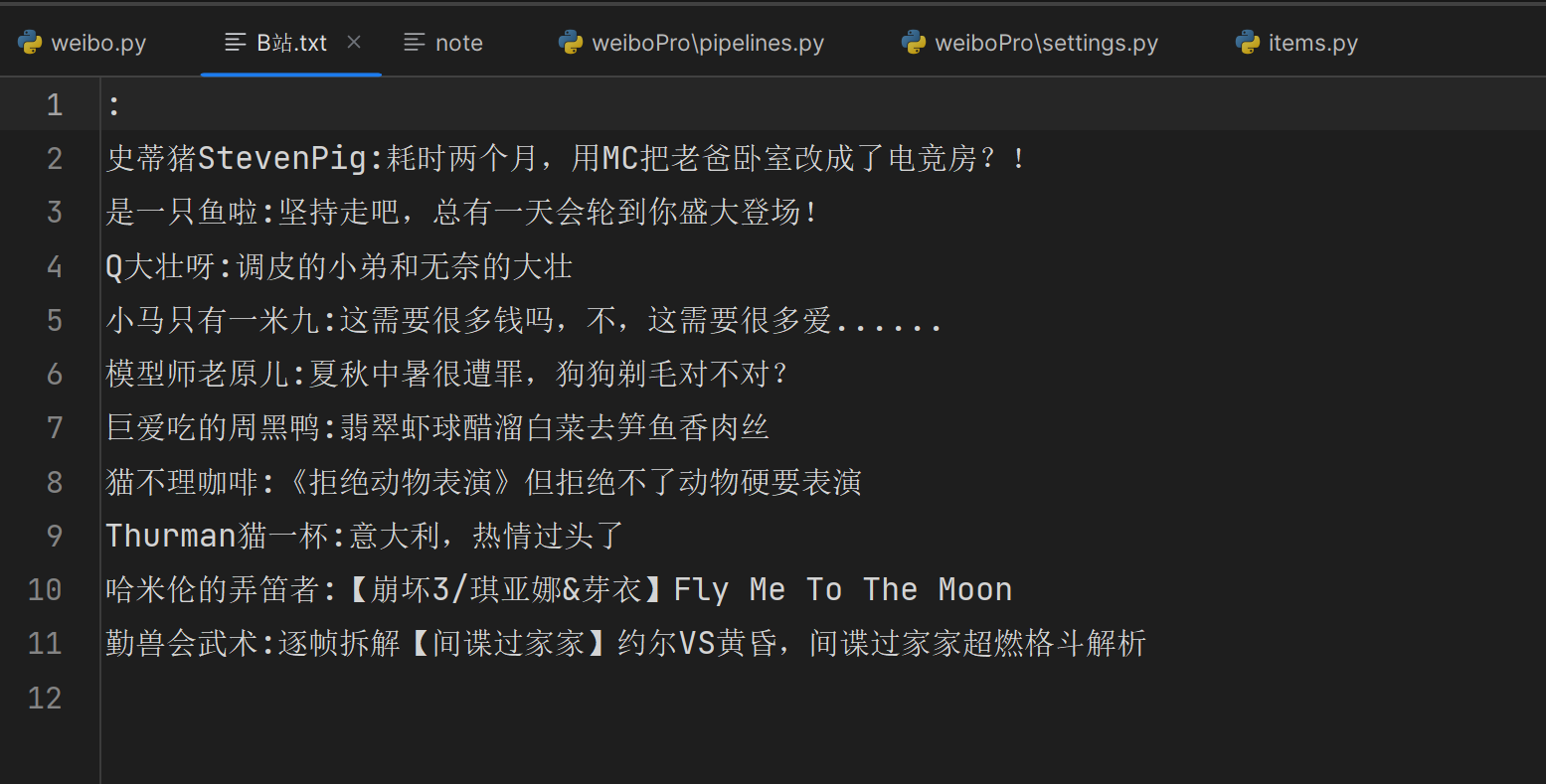
运行结果:
运行结束之后,会在本地生成B站.txt文件,其中包含爬取的author和title
持久化存储2:保存到数据库中。
前言
安装mysql
安装navicat
这里需要安装mysql,我还另外安装了navicat。安装好mysql之后,要新建连接,按照步骤操作即可。
使用终端操作数据库
这里需要mysql库。这个库是用来对数据库进行远程连接的,所以必须要有打开的数据库,打开的表才可以。
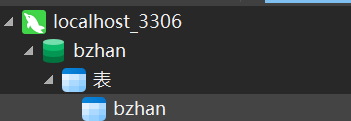
如何使用navicat新建数据库&新建表
建立好之后,再按照上面的6步按部就班来就可以。
1234步与持久化存储1完全相同。
5. 在管道类的process_item中要将其接受到的item对象中存储的数据进行持久化存储操作
这里的管道文件中的每一个管道类(如持久化存储1的WeiboproPipeline)对应将一组数据存储到一个平台或者载体中。上面的是保存到本地,所以我们还需要将再写一个类来将数据持久化存储到数据库中。
我也有好多东西不理解为什么要这么写
# 管道文件中一个管道类对应将一组数据存储到一个平台或者载体中
class mysqlPileLine:# 每写一个管道类要将这个类写到settings.py的ITEM_PIPELINES中。connect = Nonecursor = Nonedef open_spider(self, spider):# 重写父类的方法,在爬虫开始时调用一次# 创建连接:pymysql.Connectself.connect = pymysql.Connect(host='127.0.0.1', port=3306, user='root', password='liu1457154996', db='bzhan', charset='utf8') # db表示数据库的名称,我上面创建的数据库名称叫bzhan,即上图中的绿色圆柱def process_item(self, item, spider):# 创建游标self.cursor = self.connect.cursor()try:self.cursor.execute('INSERT INTO bzhan (author, title) VALUES ("%s", "%s")' % (item['author'], item['title'])) # 这里的bzhan是bzhan数据库下的表的名称self.connect.commit()print("成功写入数据库", item['author'], item['title'])except Exception as e:print(e)self.connect.rollback()return itemdef close_item(self, spider):self.cursor.close() # 关闭游标self.connect.close() # 关闭连接
6. 在配置文件中开启管道
在上面的基础上开启mysqlPileLine管道。
ITEM_PIPELINES = {"weiboPro.pipelines.WeiboproPipeline": 300,"weiboPro.pipelines.mysqlPileLine": 301,
}
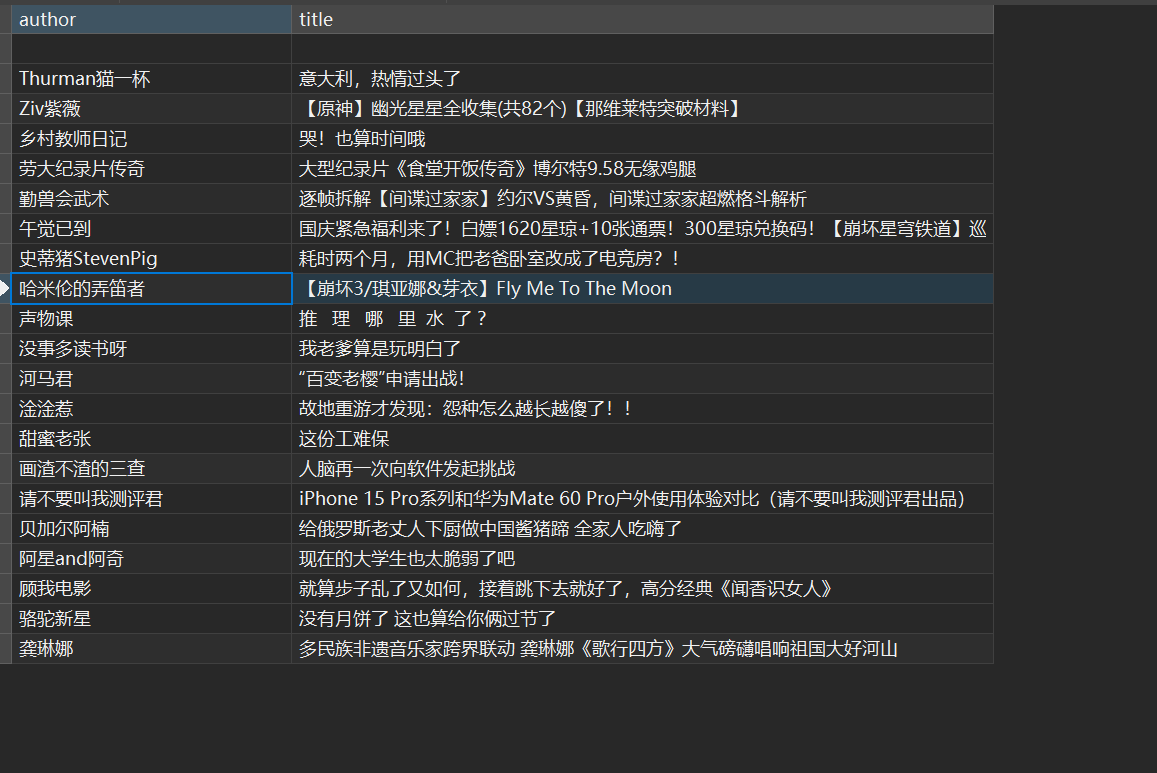
运行结果
在终端中输入scrapy crwal weibo后,得到数据库中的结果如下:
后记:
- 面试题:将爬取到的数据一份存储到本地一份存储到数据库,如何实现?
- 管道文件中一个管道类对应的是将数据存储到一种平台
- 爬虫文件提交的item只会给管道文件中第一个被执行的管道类接受
- process_item中的return item表示将item传递给下一个即将被执行的管道类




![[论文笔记]UNILM](https://img-blog.csdnimg.cn/img_convert/2d1261c204cbcbe50002d7933098b7ce.png)