文章目录
- 1. 聚合函数
- 2. group by子句的使用
- 3. 日期函数
- 4. 字符串函
- 5. 数学函数
- 6. 其它函数
1. 聚合函数
COUNT([DISTINCT] expr) 返回查询到的数据的数量
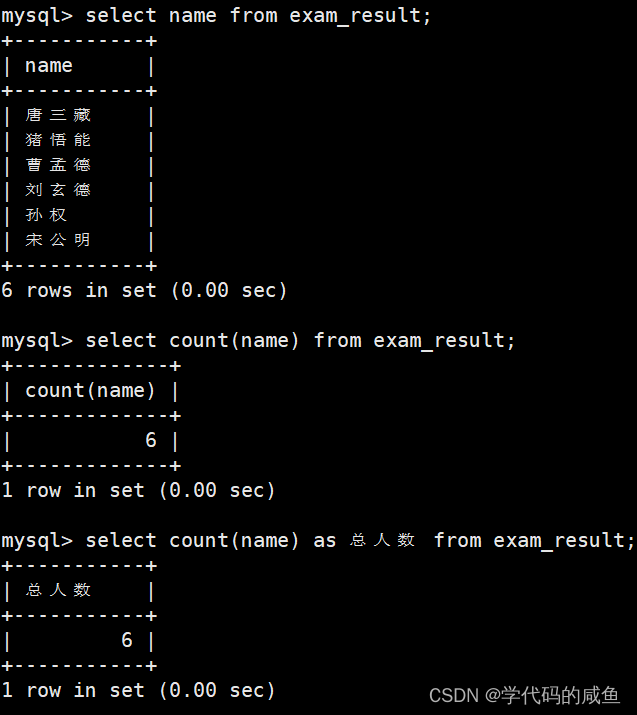
用SELECT COUNT(*) FROM students或者SELECT COUNT(1) FROM students也能查询总个数。
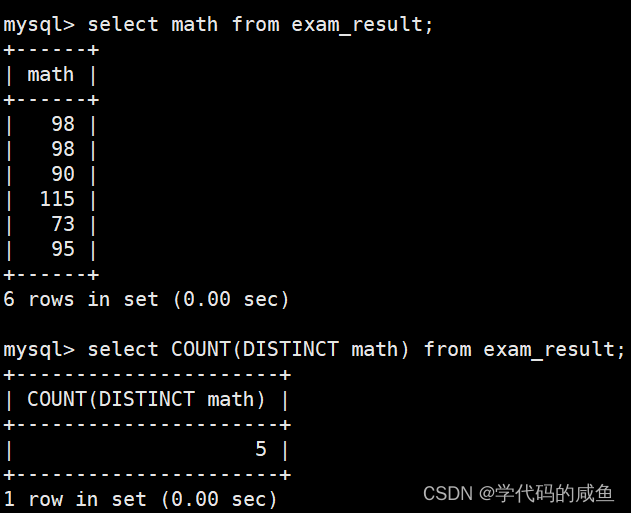
统计本次考试的数学成绩分数去重个数:
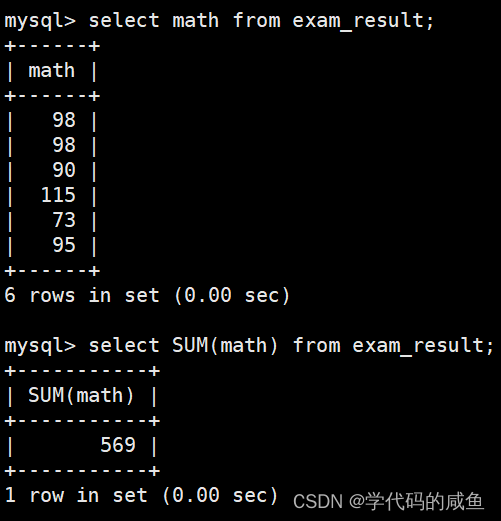
SUM([DISTINCT] expr) 返回查询到的数据的 总和,不是数字没有意义
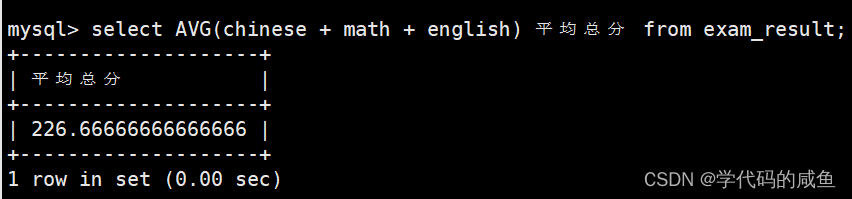
AVG([DISTINCT] expr) 返回查询到的数据的 平均值,不是数字没有意义
求每个同学的平均分排名:
MAX([DISTINCT] expr) 返回查询到的数据的 最大值,不是数字没有意义
返回英语最高分:
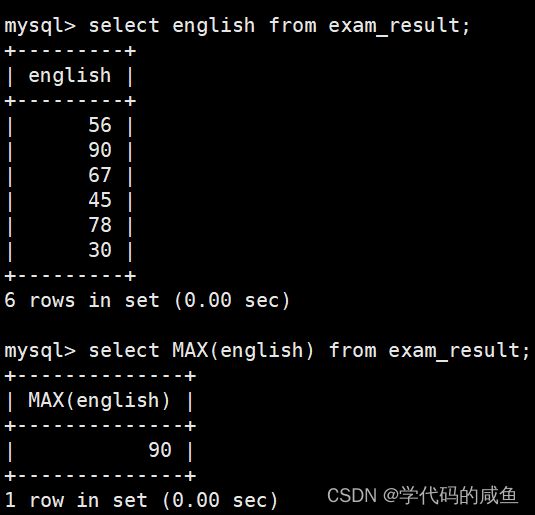
MIN([DISTINCT] expr) 返回查询到的数据的 最小值,不是数字没有意义
返回 > 70 分以上的数学最低分:
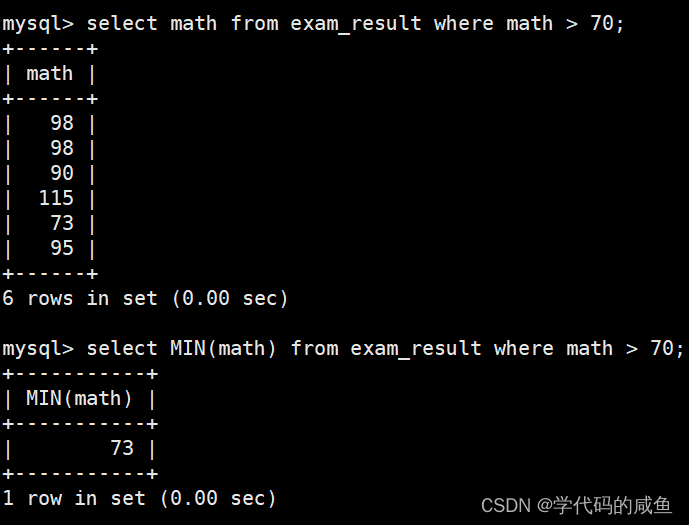
聚合统计一定是直接或者间接统计列方向的某些数据,它们的属性一定相同。
2. group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询:

举个例子:

下面我们把这个数据库备份放到我们的数据库中:
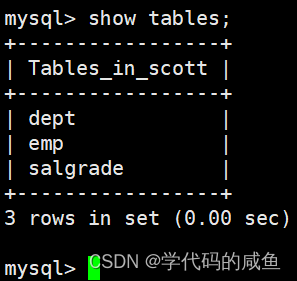
这里我们成功获取这3张表。
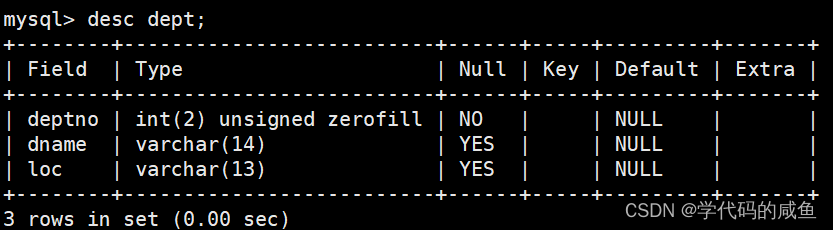
这是部门表,第一个字段是部门编号,第二个字段是部门名称,第三个字段是部门所在地点。
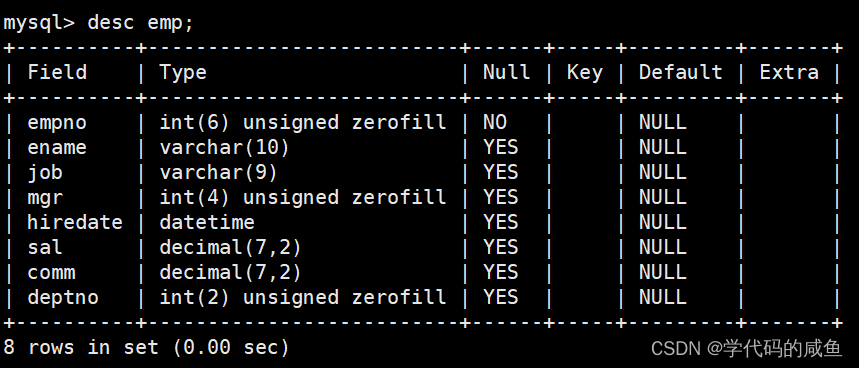
这是员工表,字段的意思依次是:雇员编号、雇员姓名、雇员职位、雇员领导编号、雇佣时间、工资月薪、奖金、部门编号。
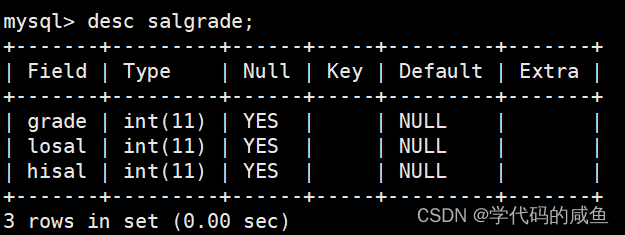
这是工资等级表,字段的意思依次是:等级、此等级最低工资、此等级最高工资。
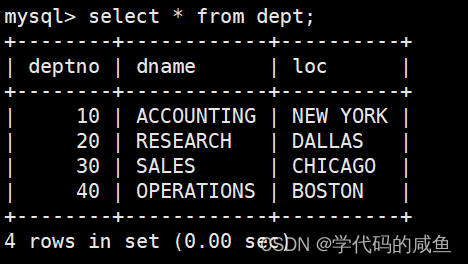
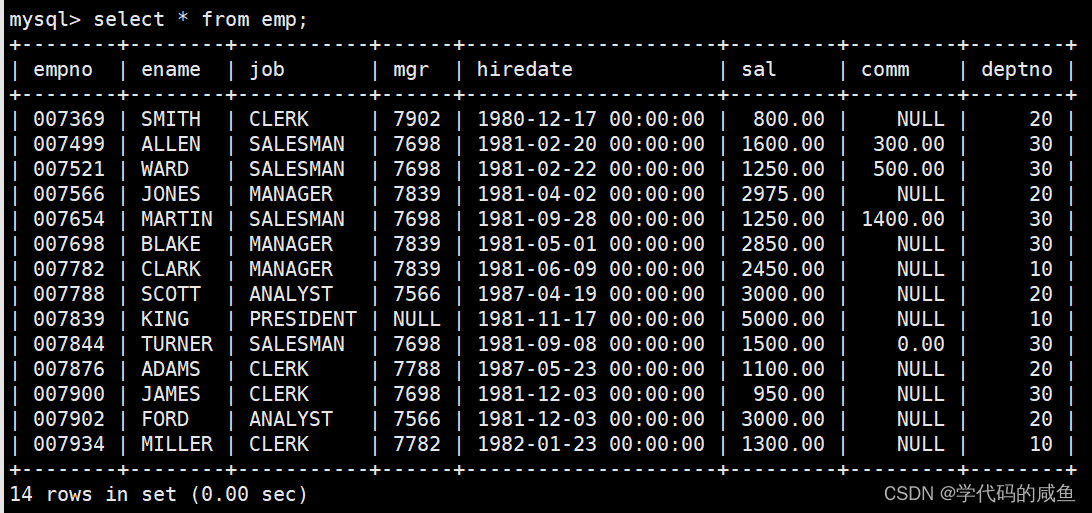

我们已经在这3张表中插入了数据。
如何显示每个部门的平均工资和最高工资?
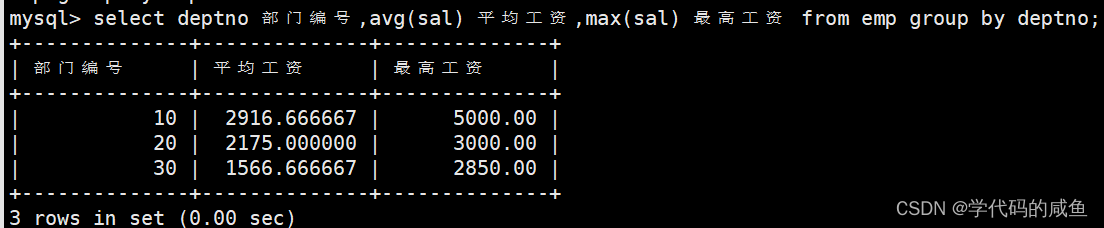
因为4号部门没有员工,所以就不显示。
如何显示每个部门的每种岗位的平均工资和最低工资?
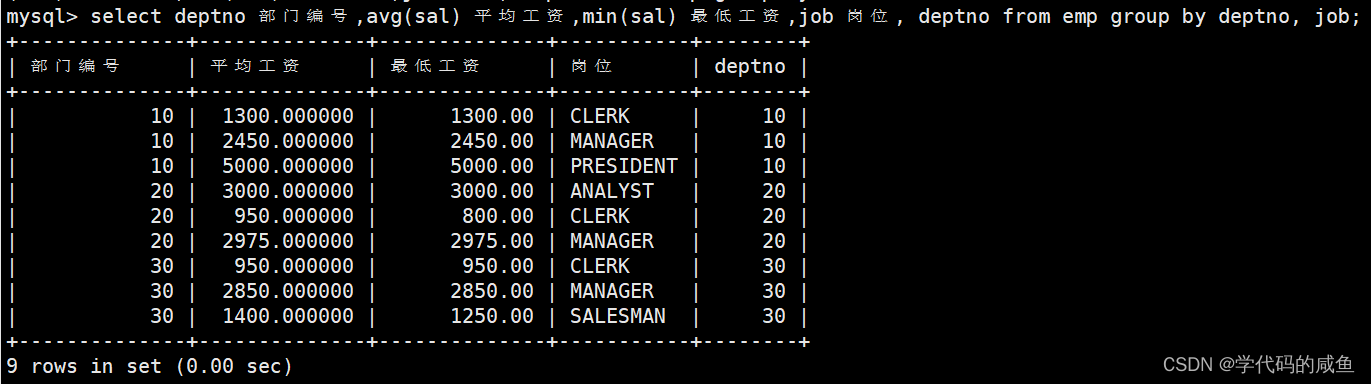
如何显示平均工资低于2000的部门和它的平均工资?
这里我们不能使用where来筛选了,需要使用having:

总结:
1.group by是通过分组这样的手段,为未来进行聚合统计提供基本信息的功能支持(group by一定是通过聚合统计来使用的)。
2.group by后面跟的都是分组的字段依据,只有在group by后面出现的字段,未来在聚合统计的时候,才能在select后面出现。
3.where和having它们两个是不冲突的,是互相补充的,having通常是在完成整个分组统计后,再进行筛选。where是在表中数据初步筛选的时候起作用的。
SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select> distinct > order by > limit
3. 日期函数
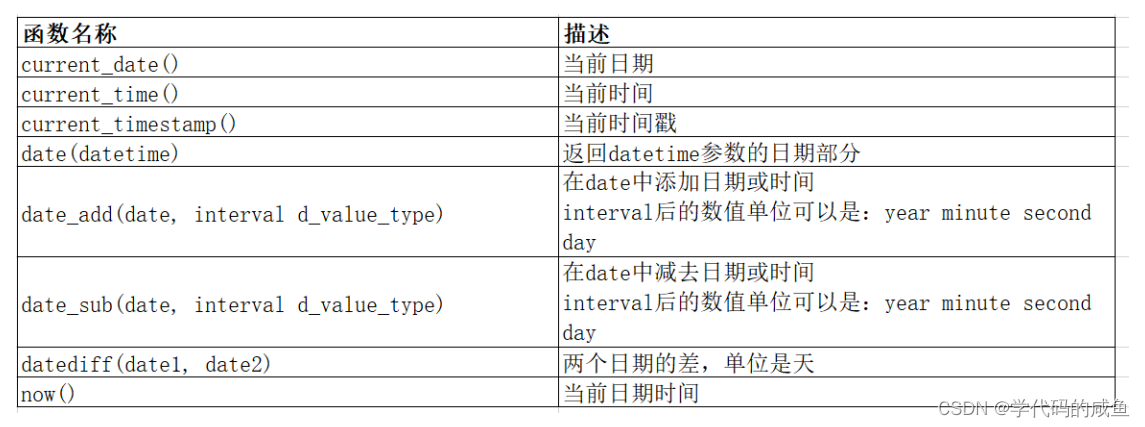
获得时间戳:
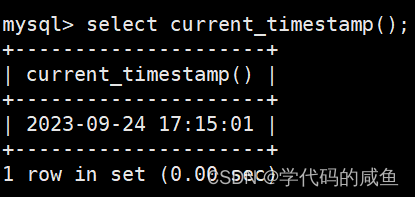
它的作用和now()一样。
在日期的基础上加天数:
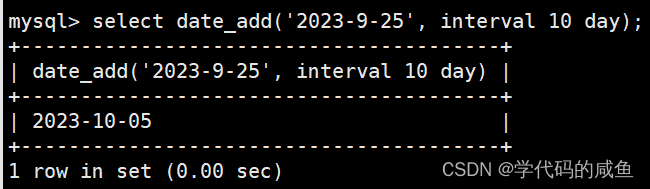
我们也可以加上年,分钟,秒。
计算两个日期之间相差多少天:
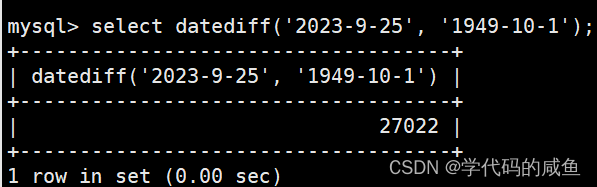
创建一个留言表:

插入数据:
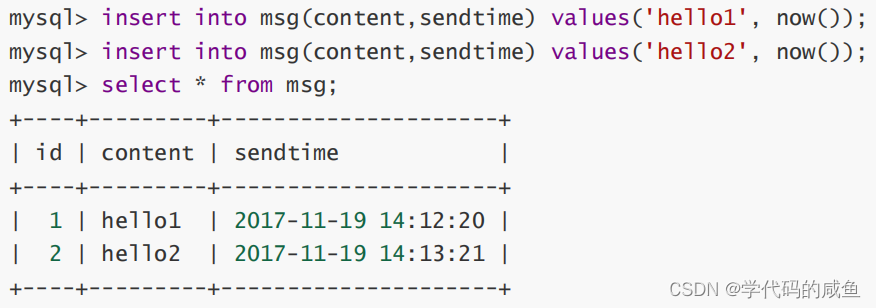
显示所有留言信息,发布日期只显示日期,不用显示时间:
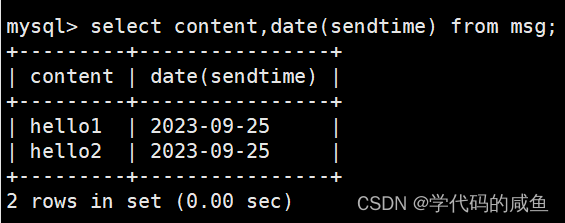
data函数会把我们的时间只保留日期格式。
请查询在2分钟内发布的帖子:
如果我们现在的时间减去2分钟的时间,在这个时间端就是2分钟内发布的帖子,换算一下就是发布的帖子+2分钟大于现在的时间。
select * from msg where date_add(sendtime, interval 2 minute) > now();
4. 字符串函
获取emp表的ename列的字符集:
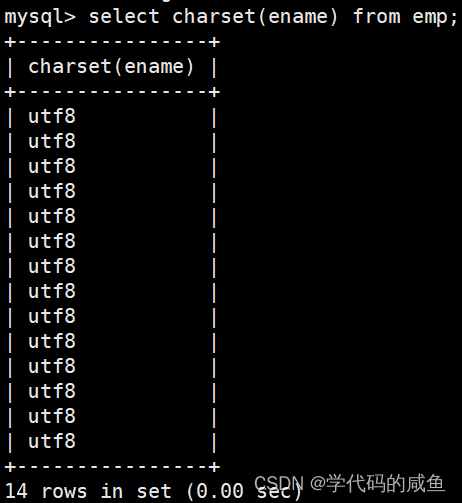
要求显示员工表中的信息,显示格式:“XXX的工作是XXX,薪水是XXX”:
求员工表中员工姓名占用的字节数:
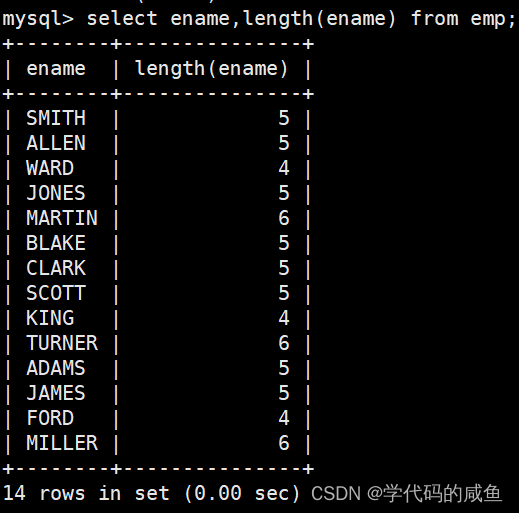
注意:length函数返回字符串长度,以字节为单位。如果是多字节字符则计算多个字节数,如果是单字节字符则算作一个字节。比如:字母,数字算作一个字节,中文表示多个字节数(与字符集编码有关)。
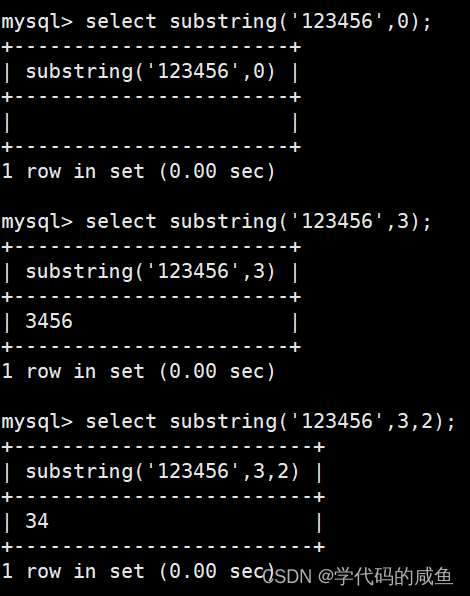
substring函数的作用是:取某个字符串的一部分,并且可以指定要取长度的大小,从1开始。
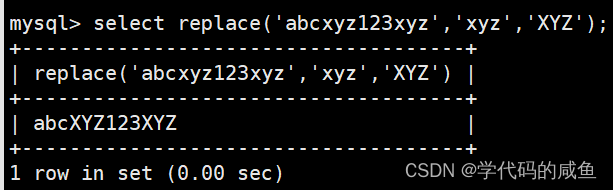
replace可以进行字符串的替换。
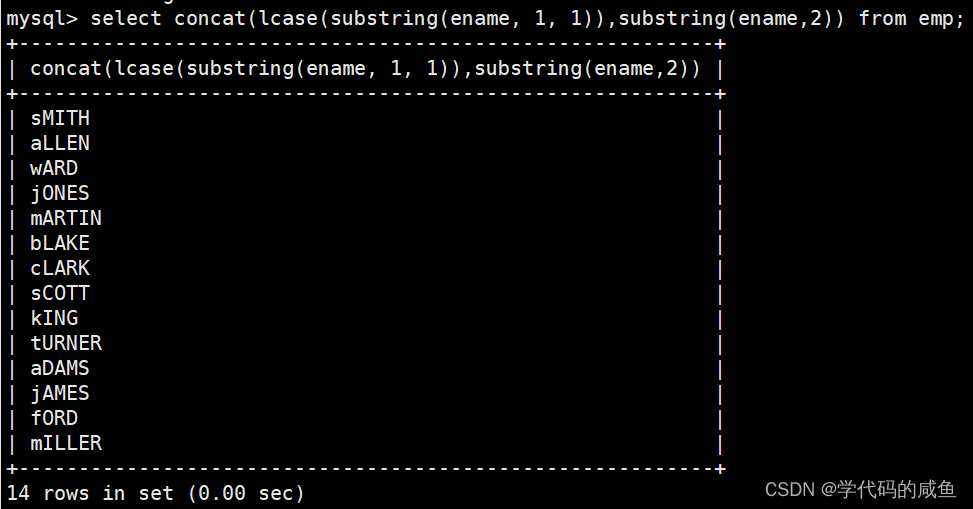
以首字母小写的方式显示所有员工的姓名:
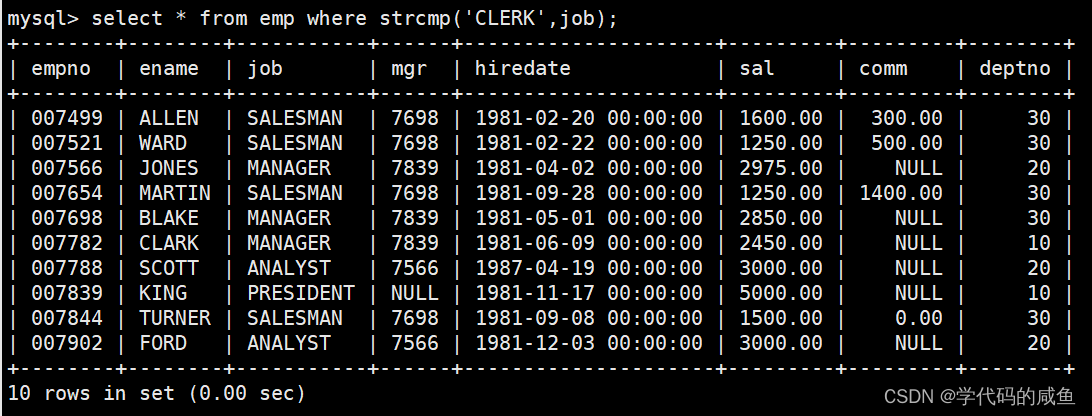
查出所有员工的工作是CLERK的:
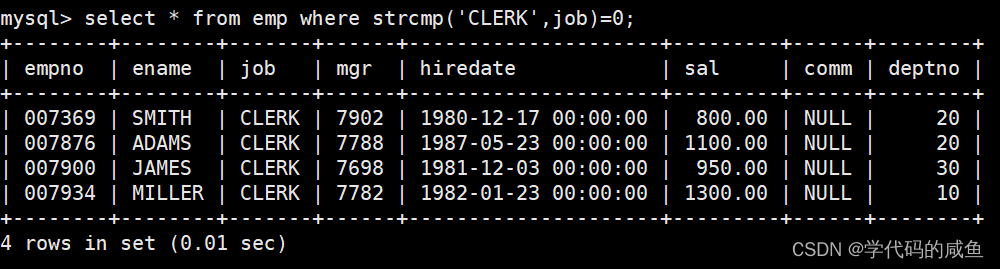
如果我们想查询的不是的话,我们就什么都不带。
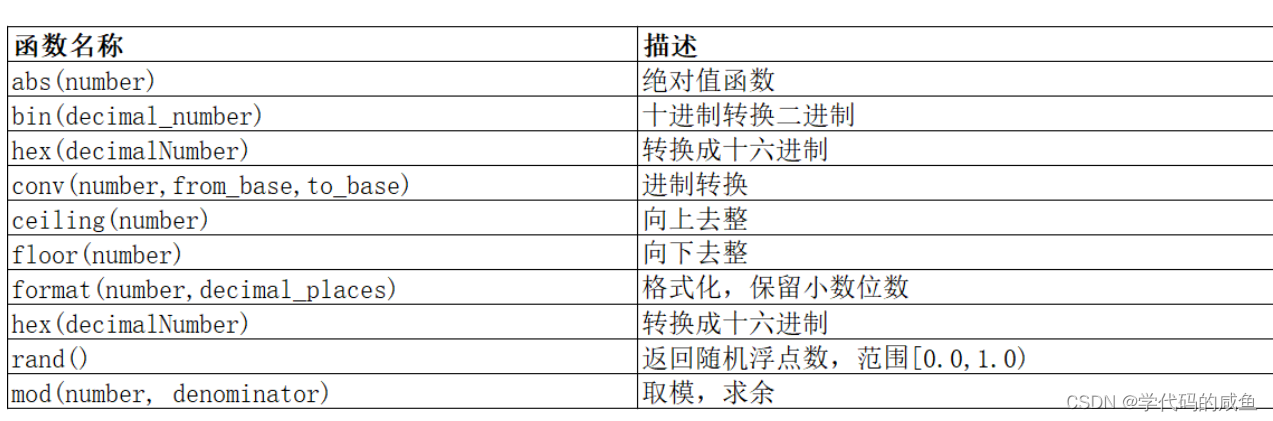
5. 数学函数
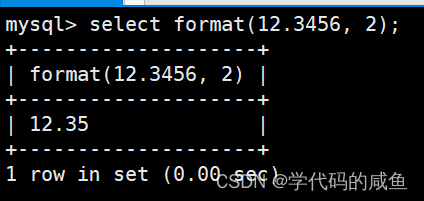
保留2位小数位数(小数四舍五入):
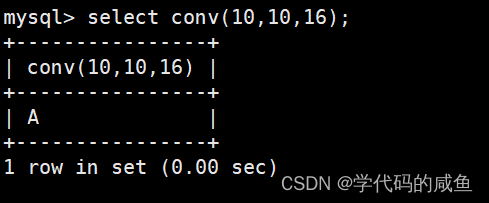
将10从10进制转成16进制:
6. 其它函数
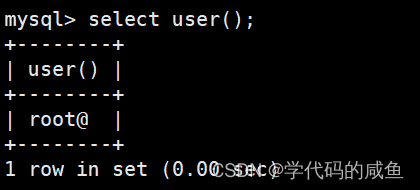
user() 查询当前用户:
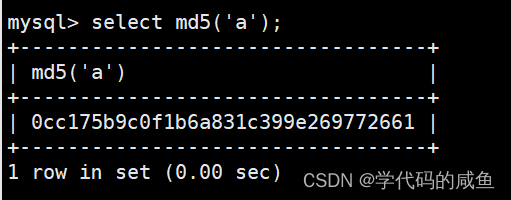
md5(str)对一个字符串进行md5摘要,摘要后得到一个32位字符串:
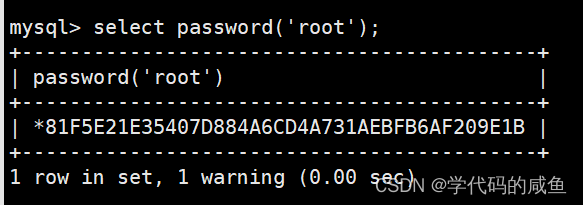
password()函数,MySQL数据库使用该函数对用户加密:
下面我们创建一个用户表,密码是加密的:
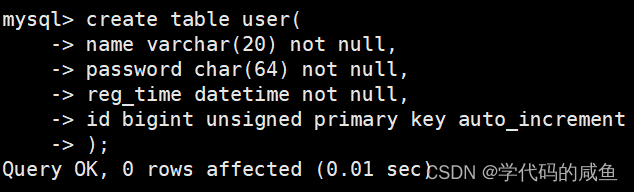
下面我们进行插入:
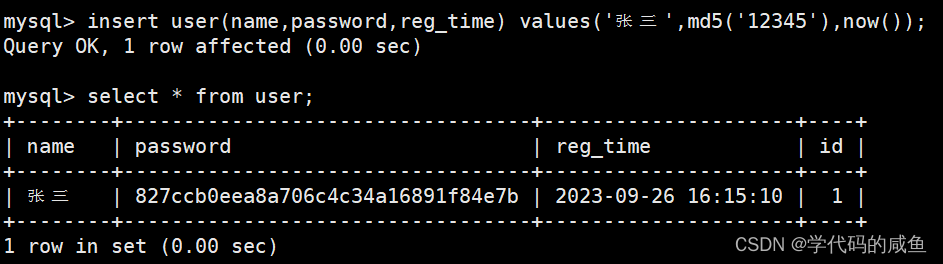
并且加密的,不会显示在MySQL中的历史语句中。
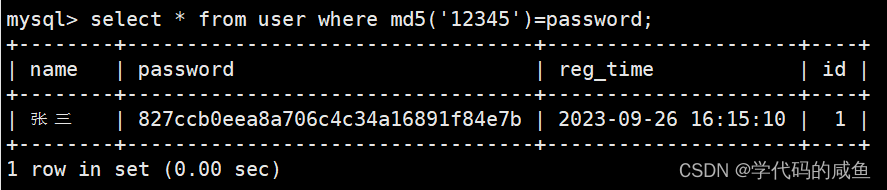
如果用户输入密码,怎么比较呢?
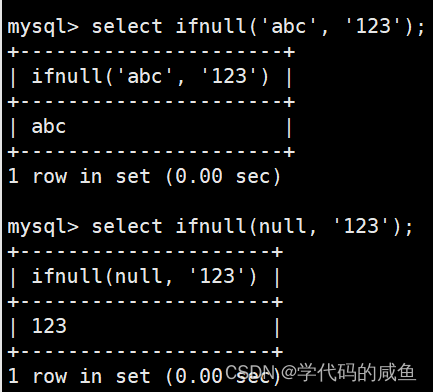
ifnull(val1, val2) 如果val1为null,返回val2,否则返回val1的值: