初学者很容易认为顺序表、链表、栈、队列是四种并列的数据结构,其实仔细想想并不是。
注意区分:
顺序表和链表是指数据的存储结构,是线性表的一种,顺序表一般指的就是数组,数据存储的逻辑顺序和物理顺序都是连续的,链表的数据在逻辑上是连续的,但是物理上并不是连续的。
而栈和队列应该算是一种数据的存取逻辑,栈是中先进后出的逻辑,队列是先进先出的逻辑;
栈这种数据存取的逻辑结构可以用顺序表这种数据存储结构来实现,也可以用链表来实现;同样的,队列可以用顺序表来实现,也可以用链表来实现。
一般的,我们的业务需求可能是需要一个栈或者一个队列,比如函数的入栈和出栈,就需要栈这种逻辑结构,比如操作系统中任务的调度,常常就需要用到队列这种逻辑结构;
那么,这两种逻辑结构是怎么来实现的?可以用顺序表或者链表。
由此我们可以看到,这里可以进行组合。
顺序表实现的栈,也就是顺序栈;
链表实现的栈,也就是链栈;
顺序表实现的队列,也就是顺序队列;
链表实现的队列,也就是链队列;
另外,链表还可以分为单链表,支持单向检索,双链表,支持双向检索,单向循环链表,支持到末尾后又回到开头,双向循环链表,支持顺时钟转和逆时钟转;
从另一个方面来考虑,我们可以把顺序表和链表理解成栈和队列的驱动,顺序表和链表,通常都会封装出增删改查等具体操作,然后栈和队列调用这些函数来实现业务中数据的存取逻辑。
等等。
这些具体是怎么回事呢?接下来分别记录一下。
顺序表
类似的内容很多,直接参考这篇吧
【数据结构】——顺序表介绍(独家介绍,小白必看!!)-CSDN博客
补充说明
✔.
理解顺序表结构体
一开始我的理解是,这里数据类型已经确定了,容量和大小不是应该给一个就可以了吗?
容量就=size*sizeof(int)
我以为size和capacity都是对数组的描述。
其实,这里不是这么理解的。
array是数组的首地址指针,也就是顺序表的句柄;
size指的是顺序表的有效长度,而不是数组的长度,千万注意;
capacity指的是数组的长度;
意思就是,我们建了个数组来实现顺序表,其中,数组的长度就是我后面顺序表能容纳元素的容量capacity,而size就是当前顺序表的长度,比如我往顺序表放一个数据,size就是1,放两个数据,size就是2……以此类推。
✔.
动态顺序表
因为数组在创建后大小就会固定下来,所以如果我们直接使用数组来实现顺序表,那么就不够灵活,无法实现扩容。
所以我们这里使用动态创建内容的方式。
在扩容时用realloc,当realloc的第一个参数为0时,其效果等同于malloc,用realloc可以完美实现最初开辟空间和增容的功能。
C 标准库 – <stdlib.h> | 菜鸟教程
✔.
顺序表常见操作
头插、尾插,头删、尾删、遍历、特定位置插入、查找特定元素的位置、求顺序表长度、删除特定位置的元素、排序、清空、销毁等等。
头插就是插入时将新元素插在表头部,尾插就是插入时将新元素插在表尾部。
同理,头删就是删除头部,尾删就是删除尾部。
✔.
顺序表首地址就表示该顺序表。
✔.
有些场景需要移动元素
比如头插,就需要将所有数据相应往后移动一个地址空间,头删,就需要将所有数据相应往前移动一个地址空间,再比如在指定位置插入,就需要将包括插入位置在内的所有之后的元素数据往后移动……总之就是,顺序表是从首地址开始的,并且每个位置都会有值。
而且,首地址是固定的,代表着顺序表本身。
链表不用整体移动数据是因为其存储时并不是连续的。
✔.
特定位置插入时,有多种情况,其中,头插和尾插可以直接调用头插和尾插函数。
就是说,能复用的函数就尽量复用。



链表
类似的内容很多,直接参考这两篇吧
单链表
【数据结构】——单链表超详细介绍(独家介绍,小白必看!!!)-CSDN博客
双链表
数据结构——双向链表-CSDN博客
补充说明
✔.
链表需要有一个元素来保存头指针,要不然链表就丢失了。我们需要用一个变量来存储指向首个有效结点的指针。这样的话是不算头结点的。
✔.
另外,有一种带头结点的链表。可以使得某些情况下的算法变得简洁高效,其实是因为可以让循环创建更加统一规整。
此时,头插法不是插在链表最前面,因为头结点永远在最前面,而是插入的位置是在头结点之后,第一个有效结点之前。
✔.
为了更好地管理链表,可以保存首尾结点的指针以及元素长度
如果没有这种管理,有些情况会较为复杂,比如尾插法时,如果没有预先保存尾部元素的指针,那么就需要从给定的头指针开始往后遍历判断,直到遍历到最后一个元素时才能执行插入操作。
这种情况下,直接传入List结构体变量指针来表示当前链表。
✔.任意位置插入
尾部插入时,有尾指针来管理。
那么任意位置插入呢?
任意位置按值插入时,需要先让链表是有序的,然后才能按值插入。
✔.
链表因为无法随机存取,所以有些时候需要遍历链表才能完成相应功能。
单链表向前操作比较麻烦,向后操作比较简单。
比如删除某个结点时,需要将目标结点的上一个结点的next重新赋值成目标结点的下一个结点,我们遍历查找到目标结点,可以根据结构体找到下一个结点,但是不能反向怎么找到上一个结点呢?
重新再遍历一遍?
我们换个思路
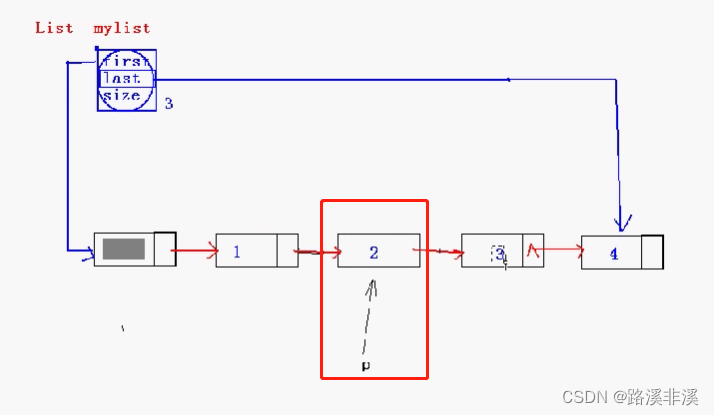
比如我们要删除这第二个结点
但是有个问题就是第二个结点的上一个结点不好找,除非重新遍历一遍。
现在我们不想遍历。
这样来操作,我们把第二个结点的下一个结点的数据复制到当前结点,然后就可以将这个问题转换成删除当前结点的下一个结点,即从删除第二个结点的问题,转变成了删除第三个结点的问题。
也就是说,将向前的问题转换成了向后的问题。
✔.
双链表
单链表头插头删效率十分的高,但是要在中间或者尾部进行插入删除操作时,需要找到前驱节点,而且单链表难以逆序,这导致单链表具有一定的局限性。
为了克服这单向性的缺点,我们的前辈们设计出了双向链表。
✔.
链表在删除结点后,需要free释放结点空间。
因为链表结点是一个一个地malloc出来的,所以要一个一个地释放。
顺序表是一次创建出来的,所以直接释放申请出来的指针即可。
也就是说,free和malloc是一一对应的。
✔.
销毁操作不应该由用户来进行。



栈

栈是限定仅在表尾进行插入和删除操作的线性表。
类似的内容很多,直接参考这篇吧
数据结构之——栈_数据结构栈_WenJieya的博客-CSDN博客
补充说明
✔.
栈的结构体
栈底地址,也就是该栈的地址;
栈容量;
栈顶地址,也可以用来表示当前栈大小;
✔.
栈顶的起始地址索引
栈顶索引top从0开始还是从-1开始,都可以,二者的区别是,如果从0开始,存数据时,需要先存数据,然后top指针+1,如果是从-1开始,则索引需要先+1再存数据,取数据时的过程正好相反。其他没啥区别。top指向的是下一个能存放数据的地址空间,等待数据来存。
✔.
两个辅助函数
判断栈满和判断栈空
✔.
栈动态扩容
✔.
栈的操作通常只有入栈和出栈,然后就是显示。



队列
类似的内容很多,直接参考这篇吧
【数据结构之队列系列】队列详解_结构体队列-CSDN博客
补充说明
✔.
栈和队列都是个受限的线性表。
链队列结构体如下:
✔.
队头指针等于队尾指针时,队列为空。
✔.
顺序队列
✔.
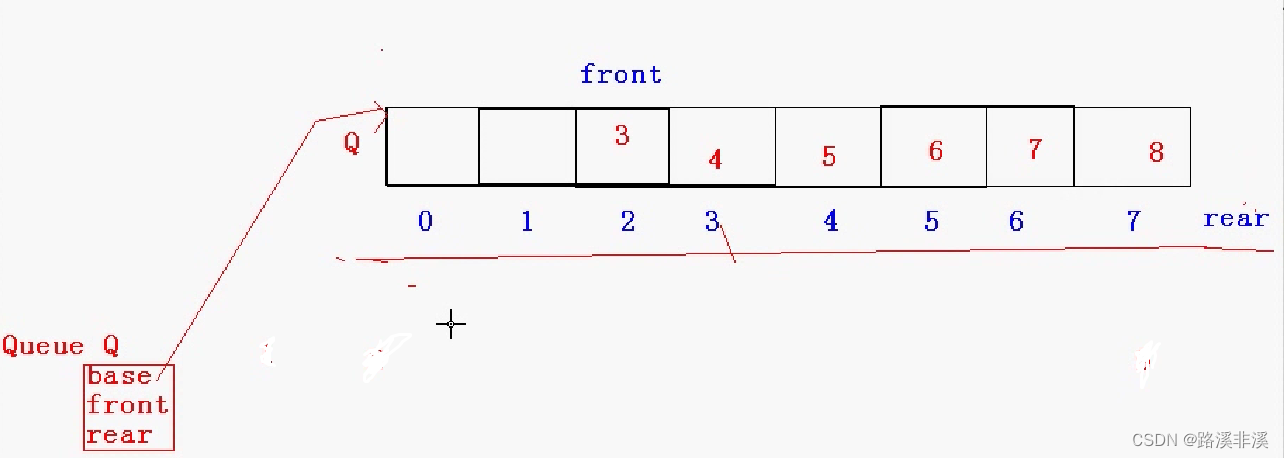
循环队列
针对以下这种情况
队尾已经到了容量最大指针处,但是队列头之前因为有些数据被取出所以还有空间可以使用,此时,如果再在队尾插入数据,其实已经越界了,为了更好地利用队列头空间,就可以设计一种循环队列。


相关视频可参考:
C语言代码实现严蔚敏数据结构
更多补充
几种常见的排序算法
冒泡排序
直接排序
快速排序
……
经典的十种排序算法 C语言版_c语言排序_Johnny-He的博客-CSDN博客