GPT系列
GPT(Generative Pre-trained Transformer)是一系列基于Transformer架构的预训练语言模型,由OpenAI开发。以下是GPT系列的主要模型:
-
GPT:GPT-1是于2018年发布的第一个版本,它使用了12个Transformer编码器层和1.5亿个参数。GPT-1的训练数据包括了互联网上的大量文本。
-
GPT-2:GPT-2于2019年发布,是GPT系列的第二个版本。它比GPT-1更大更强大,使用了24个Transformer编码器层和1.5亿到15亿个参数之间的不同配置。GPT-2在生成文本方面表现出色,但由于担心滥用风险,OpenAI最初选择限制了其训练模型的发布。
-
GPT-3:GPT-3于2020年发布,是GPT系列的第三个版本,也是目前最先进和最强大的版本。它采用了1750亿个参数,拥有1750亿个可调节的权重。GPT-3在自然语言处理(NLP)任务中表现出色,可以生成连贯的文本、回答问题、进行对话等。
-
GPT-3.5:GPT-3.5是在GPT-3基础上进行微调和改进的一个变种,它是对GPT-3的进一步优化和性能改进。
GPT系列的模型在自然语言处理领域取得了巨大的成功,并在多个任务上展示出了强大的生成和理解能力。它们被广泛用于文本生成、对话系统、机器翻译、摘要生成等各种应用中,对自然语言处理和人工智能领域的发展有着重要的影响。
GPT系列是当前自然语言处理领域下最流行,也是商业化效果最好的自然语言大模型,并且他的论文也对NLP的领域产生巨大影响,GPT首次将预训练-微调模型真正带入NLP领域,同时提出了多种具有前瞻性的训练方法,被后来的BERT等有重大影响的NLP论文所借鉴。
目录
- GPT系列
- GPT-1模型架构
- 1. 无监督的预训练部分
- 2. 有监督的微调部分
- 3. 特定于任务的输入转换
GPT-1模型架构
GPT的训练过程由两个阶段组成。第一阶段是在大型文本语料库上学习高容量语言模型。接下来是微调阶段,我们使模型适应带有标记数据的判别任务。
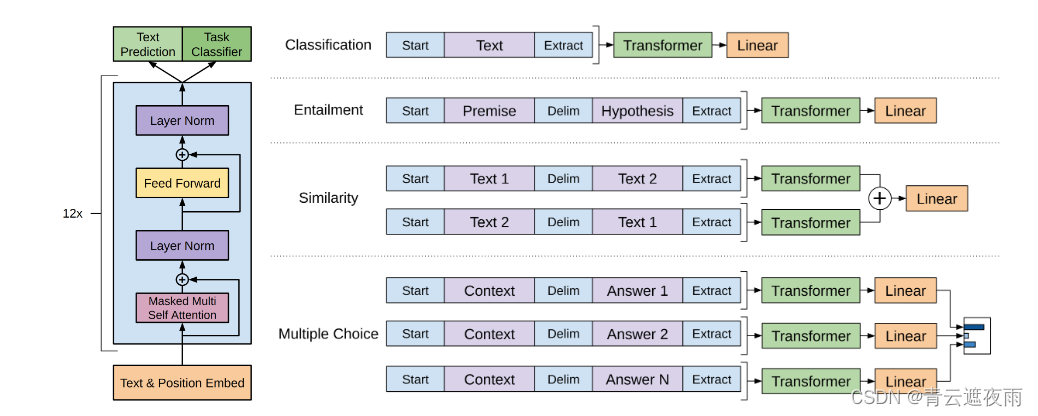
上图是GPT架构的整体示意图,左图是论文中所使用的 Transformer 架构,右图表示了用于对不同任务进行微调的输入转换。我们将所有结构化输入转换为Tokens序列,以便由我们的预训练模型进行处理,然后是线性+softmax层。
1. 无监督的预训练部分
给定一个无监督的标记语料库 U = u 1 , . . . , u n U = {u_1,. . . , u_n} U=u1,...,un,我们使用标准语言建模目标来最大化以下可能性:
L 1 ( U ) = ∑ i l o g P ( u i ∣ u i − k , . . . , u i − 1 ; θ ) L_1(U)=\sum_{i}logP(u_i|u_{i-k},...,u_{i-1};\theta) L1(U)=i∑logP(ui∣ui−k,...,ui−1;θ)
其中 k 是上下文窗口的大小,条件概率 P 使用参数为 θ 的神经网络进行建模。这些参数使用随机梯度下降进行训练。
在GPT的论文中,使用多层 Transformer 解码器作为语言模型,它是 Transformer的变体。该模型对输入上下文标记应用多头自注意力操作,然后是位置前馈层,以生成目标标记的输出分布:
h 0 = U W e + W p h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) i ∈ [ 1 , n ] P ( u ) = s o f t m a x ( h n W e T ) h_0=UW_{e}+W_p \\ h_l=transformer\_block(h_{l-1}) i\in[1,n]\\ P(u)=softmax(h_nW_e^T) h0=UWe+Wphl=transformer_block(hl−1)i∈[1,n]P(u)=softmax(hnWeT)
其中 U = ( u − k , . . . , u − 1 ) U = (u_{−k}, ..., u_{−1}) U=(u−k,...,u−1) 是标记的上下文向量,n 是层数, W e W_e We 是标记嵌入矩阵, W p W_p Wp 是位置嵌入矩阵。,对于所有的U,得到的所有的 P P P的对数和就是我们需要优化的目标,即上面说的 L 1 L_1 L1
2. 有监督的微调部分
当语言模型训练结束后,就可以将其迁移到具体的NLP任务中,假设将其迁移到一个文本分类任务中,记此时的数据集为 C C C,对于每一个样本,其输入为 x 1 , . . , x m x_1,..,x_m x1,..,xm ,输出为 y y y。对于每一个输入,经过预训练后的语言模型后,可以直接选取最后一层Transformer最后一个时间步的输出向量 h l m h_l^m hlm,然后在其后面接一层全连接层,即可得到最后的预测标签概率:
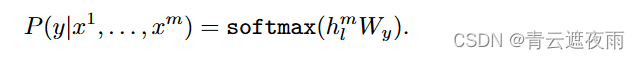
其中, W y W_y Wy为引入的全来凝结层的参数矩阵。因此,可以得到在分类任务中的目标函数:
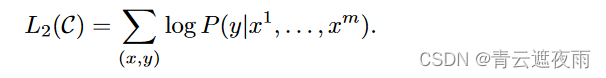
在具体的NLP任务中,作者在fine-tuning时也把语言模型的目标引入到目标函数中,作为辅助函数,作者发现这样操作可以提高模型的通用能力,并且加速模型手来你,其形式如下:
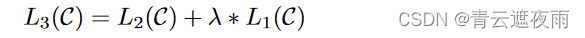
其中 λ一般取0.5。
3. 特定于任务的输入转换
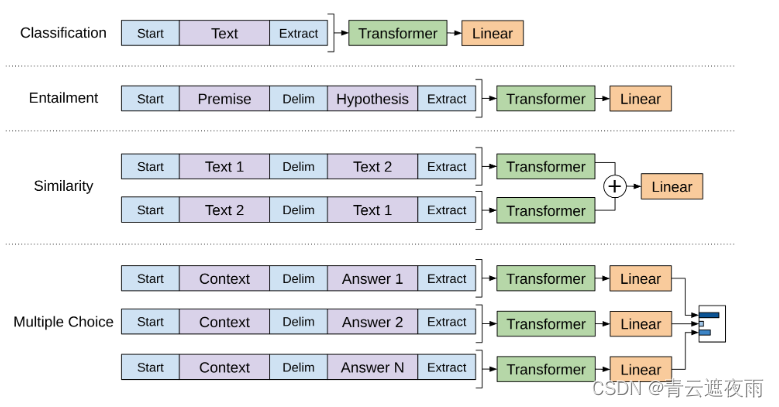
不过,上面这个例子知识对与文本分类任务,如果是对于其他任务,比如文本蕴涵、问答、文本相似度等,那么GPT该如何进行微调呢?
文本蕴涵:对于文本蕴涵任务(文本间的推理关系,问题-答案),作者用一个$负号将文本和假设进行拼接,并在拼接后的文本前后加入开始符 start 和结束符 end,然后将拼接后的文本直接传入预训练的语言模型,在模型再接一层线性变换和softmax即可。
文本相似度:对于文本相似度任务,由于相似度不需要考虑两个句子的顺序关系,因此,为了反映这一点,作者将两个句子分别与另一个句子进行拼接,中间用“$”进行隔开,并且前后还是加上起始和结束符,然后分别将拼接后的两个长句子传入Transformer,最后分别得到两个句子的向量表示 h l m h_l^m hlm,将这两个向量进行元素相加,然后再接如线性层和softmax层。
问答和尝试推理:对于问答和尝试推理任务,首先将本经信息与问题进行拼接,然后再将拼接后的文本一次与每个答案进行拼接,最后依次传入Transformer模型,最后接一层线性层得到每个输入的预测值。
具体的方法可以查看下图,可以发现,对这些任务的微调主要是:
- 增加线性层的参数
- 增加起始符、结束符和分隔符三种特殊符号的向量参数
注意:GPT1主要还是针对文本分类任务和标注性任务,对于生成式任务,比如问答,机器翻译之类的任务,其实并没有做到太好效果的迁移,但是GPT-2的提出主要针对生成式的任务。我们放到下期再讲。