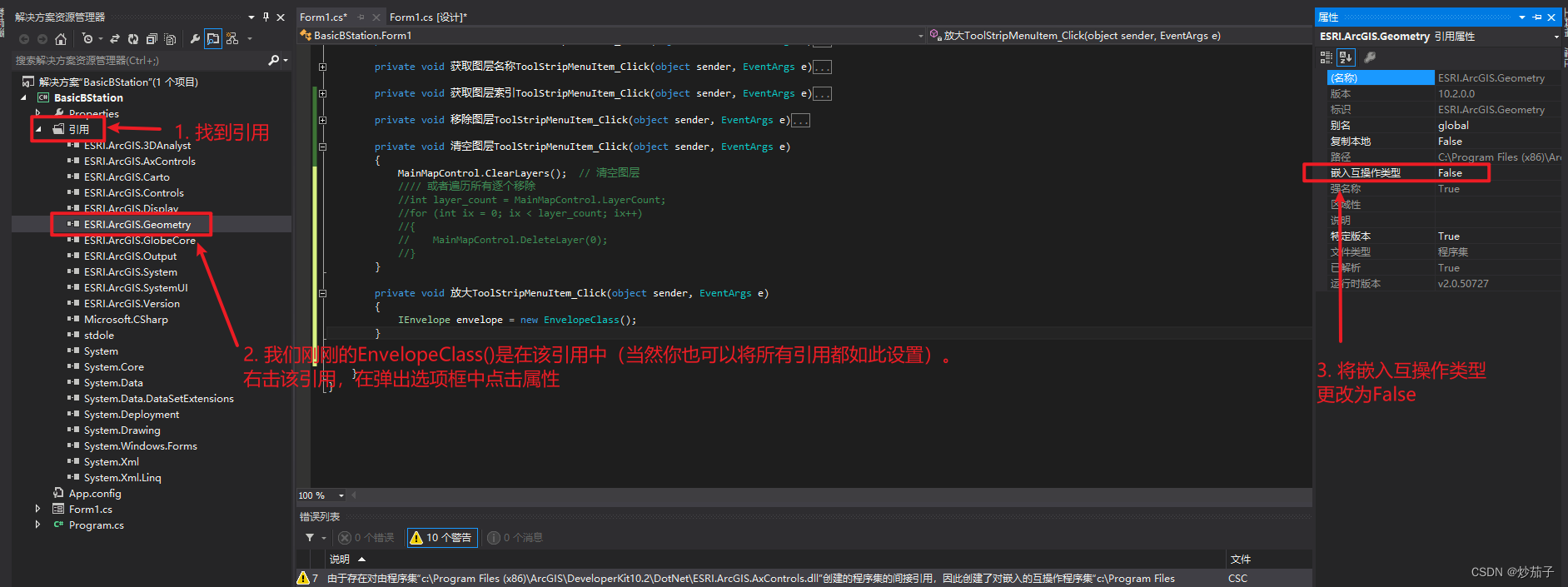
AI视野·今日CS.CV 计算机视觉论文速览
Tue, 3 Oct 2023 (showing first 100 of 167 entries)
Totally 100 papers
👉上期速览✈更多精彩请移步主页

Daily Computer Vision Papers
| GPT-Driver: Learning to Drive with GPT Authors Jiageng Mao, Yuxi Qian, Hang Zhao, Yue Wang 我们提出了一种简单而有效的方法,可以将 OpenAI GPT 3.5 模型转变为自动驾驶车辆的可靠运动规划器。运动规划是自动驾驶的核心挑战,旨在规划安全舒适的驾驶轨迹。现有的运动规划器主要利用启发式方法来预测驾驶轨迹,但这些方法在面对新奇和未见过的驾驶场景时表现出不足的泛化能力。在本文中,我们提出了一种新的运动规划方法,该方法利用了大型语言模型法学硕士固有的强大推理能力和泛化潜力。我们方法的基本见解是将运动规划重新表述为语言建模问题,这是以前未探讨过的观点。具体来说,我们将规划器的输入和输出表示为语言标记,并利用 LLM 通过坐标位置的语言描述生成驾驶轨迹。此外,我们提出了一种新颖的提示推理微调策略来激发法学硕士的数字推理潜力。通过这种策略,法学硕士可以用自然语言描述高精度的轨迹坐标及其内部决策过程。我们在大规模 nuScenes 数据集上评估了我们的方法,并且广泛的实验证实了我们基于 GPT 的运动规划器的有效性、泛化能力和可解释性。 |
| DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model Authors Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kenneth K.Y. Wong, Zhenguo Li, Hengshuang Zhao 过去十年,自动驾驶在学术界和工业界都得到了快速发展。然而,其有限的可解释性仍然是一个尚未解决的重大问题,严重阻碍了自动驾驶汽车的商业化和进一步发展。以前使用小语言模型的方法由于缺乏灵活性、泛化能力和鲁棒性而未能解决这个问题。最近,多模态大语言模型法学硕士因其通过文本处理和推理非文本数据(例如图像和视频)的能力而受到了研究界的广泛关注。在本文中,我们提出了 DriveGPT4,这是一种利用法学硕士的可解释的端到端自动驾驶系统。 DriveGPT4能够解释车辆动作并提供相应的推理,并回答人类用户提出的各种问题以增强交互。此外,DriveGPT4 以端到端方式预测车辆低电平控制信号。这些功能源于专为自动驾驶设计的定制视觉指令调整数据集。据我们所知,DriveGPT4 是第一个专注于可解释的端到端自动驾驶的作品。当对传统方法和视频理解法学硕士进行多项任务评估时,DriveGPT4 表现出了卓越的定性和定量性能。此外,DriveGPT4 可以以零射击方式进行推广,以适应更多未见过的场景。 |
| LEAP: Liberate Sparse-view 3D Modeling from Camera Poses Authors Hanwen Jiang, Zhenyu Jiang, Yue Zhao, Qixing Huang 多视图 3D 建模需要相机姿势吗?现有方法主要假设可以获取准确的相机姿势。虽然这种假设可能适用于密集视图,但准确估计稀疏视图的相机姿势通常难以捉摸。我们的分析表明,噪声估计姿势会导致现有稀疏视图 3D 建模方法的性能下降。为了解决这个问题,我们提出了 LEAP,一种新颖的无姿势方法,从而挑战了相机姿势必不可少的普遍观念。 LEAP 放弃基于姿势的操作并从数据中学习几何知识。 LEAP 配备了一个神经体积,该神经体积在场景之间共享,并被参数化以编码几何和纹理先验。对于每个传入场景,我们通过以特征相似性驱动的方式聚合 2D 图像特征来更新神经体积。更新后的神经体积被解码到辐射场中,从而能够从任何角度进行新颖的视图合成。在以对象为中心的数据集和场景级数据集上,我们表明,当使用最先进的姿势估计器预测姿势时,LEAP 显着优于先前的方法。值得注意的是,LEAP 的性能与之前使用地面真实姿势的方法相当,同时运行速度比 PixelNeRF 快 400 倍。我们展示了 LEAP 泛化到新的物体类别和场景,并学习与极几何非常相似的知识。 |
| Conditional Diffusion Distillation Authors Kangfu Mei, Mauricio Delbracio, Hossein Talebi, Zhengzhong Tu, Vishal M. Patel, Peyman Milanfar 生成扩散模型为文本到图像的生成提供了强大的先验,从而成为图像编辑、恢复和超分辨率等条件生成任务的基础。然而,扩散模型的一个主要限制是采样时间慢。为了应对这一挑战,我们提出了一种新颖的条件蒸馏方法,旨在借助图像条件补充扩散先验,从而只需很少的步骤即可进行条件采样。我们通过联合学习直接在单个阶段中蒸馏无条件预训练,大大简化了前两阶段分别涉及蒸馏和条件微调的程序。此外,我们的方法实现了一种新的参数高效蒸馏机制,该机制仅使用少量附加参数与共享冻结无条件主干相结合来蒸馏每个任务。跨多个任务(包括超分辨率、图像编辑和深度图像生成)的实验表明,我们的方法在相同采样时间内优于现有的蒸馏技术。 |
| HumanNorm: Learning Normal Diffusion Model for High-quality and Realistic 3D Human Generation Authors Xin Huang, Ruizhi Shao, Qi Zhang, Hongwen Zhang, Ying Feng, Yebin Liu, Qing Wang 最近采用扩散模型的文本到 3D 方法在 3D 人类生成方面取得了重大进展。然而,由于文本到图像扩散模型的局限性,这些方法面临着挑战,该模型缺乏对 3D 结构的理解。因此,这些方法很难实现高质量的人类生成,从而产生平滑的几何形状和卡通般的外观。在本文中,我们观察到使用法线贴图对文本到图像扩散模型进行微调,使其能够适应文本到法线扩散模型,从而增强 3D 几何的 2D 感知,同时保留从大规模数据集学到的先验知识。因此,我们提出了 HumanNorm,一种通过学习法线扩散模型(包括法线适应扩散模型和法线对齐扩散模型)来生成高质量和逼真的 3D 人体的新方法。法线适应扩散模型可以生成与具有视图相关文本的提示相对应的高保真法线图。法线对齐扩散模型学习生成与法线贴图对齐的彩色图像,从而将物理几何细节转换为真实的外观。利用所提出的法线扩散模型,我们设计了渐进式几何生成策略和从粗到细的纹理生成策略,以提高 3D 人体生成的效率和鲁棒性。全面的实验证实了我们的方法能够生成具有复杂几何形状和逼真外观的 3D 人体,在几何形状和纹理质量方面显着优于现有的文本到 3D 方法。 |
| CLIPSelf: Vision Transformer Distills Itself for Open-Vocabulary Dense Prediction Authors Size Wu, Wenwei Zhang, Lumin Xu, Sheng Jin, Xiangtai Li, Wentao Liu, Chen Change Loy 对比语言图像预训练 CLIP 的成功推动了包括对象检测和图像分割在内的开放词汇密集预测任务的发展。 CLIP 模型,特别是那些包含视觉转换器 ViT 的模型,在零样本图像分类中表现出了卓越的泛化能力。然而,当将 CLIP 的视觉语言对齐从全局图像表示转移到局部区域表示以进行开放词汇密集预测任务时,CLIP ViT 会遭受从完整图像到局部图像区域的域转移。在本文中,我们开始深入分析 CLIP 模型中的区域语言对齐,这对于下游开放词汇密集预测任务至关重要。随后,我们提出了一种名为 CLIPSelf 的方法,它将 CLIP ViT 的图像级识别能力适应局部图像区域,而不需要任何区域文本对。 CLIPSelf 使 ViT 能够通过将从其密集特征图中提取的区域表示与相应图像裁剪的图像级表示对齐来进行自我蒸馏。借助增强的 CLIP ViT,我们在跨各种基准的开放词汇对象检测、语义分割和全景分割方面实现了最先进的性能。 |
| Pixel-Aligned Recurrent Queries for Multi-View 3D Object Detection Authors Yiming Xie, Huaizu Jiang, Georgia Gkioxari, Julian Straub 我们提出 PARQ 是一种多视图 3D 对象检测器,具有转换器和像素对齐的循环查询。与之前使用可学习特征或仅将 3D 点位置编码为解码器中的查询的工作不同,PARQ 利用从 3D 空间中的参考点初始化的外观增强查询,并通过循环交叉注意操作更新其 3D 位置。结合像素对齐特征和交叉注意力,使模型能够编码必要的 3D 到 2D 对应关系并捕获输入图像的全局上下文信息。 |
| Sequential Data Generation with Groupwise Diffusion Process Authors Sangyun Lee, Gayoung Lee, Hyunsu Kim, Junho Kim, Youngjung Uh 我们提出了分组扩散模型GDM,它将数据分为多个组,并在前向扩散过程中以一个时间间隔扩散一组。 GDM 在一个时间间隔从一组顺序生成数据,从而产生几个有趣的属性。首先,作为扩散模型的扩展,GDM 概括了某些形式的自回归模型和级联扩散模型。作为一个统一的框架,GDM 允许我们研究在以前的工作中被忽视的设计选择,例如数据分组策略和生成顺序。此外,由于一组初始噪声仅影响一组生成的数据,因此潜在空间现在具有分组可解释的含义。我们可以进一步将 GDM 扩展到频域,其中前向过程依次扩散每组频率分量。将数据的频带划分为组允许潜在变量成为分层表示,其中各个组在不同的抽象级别对数据进行编码。 |
| DST-Det: Simple Dynamic Self-Training for Open-Vocabulary Object Detection Authors Shilin Xu, Xiangtai Li, Size Wu, Wenwei Zhang, Yining Li, Guangliang Cheng, Yunhai Tong, Kai Chen, Chen Change Loy 开放词汇对象检测 OVOD 旨在检测训练期间观察到的类别集之外的对象。这项工作提出了一种简单而有效的策略,利用预先训练的视觉语言模型 VLM(例如 CLIP)的零样本分类能力,直接对所有可能的新类别的建议进行分类。与之前在训练期间忽略新类并仅依赖区域提议网络 RPN 进行新对象检测的工作不同,我们的方法根据特定的设计标准有选择地过滤提议。所得到的已识别提案集在训练阶段充当新类别的伪标签。它使我们的自我训练策略能够以自我训练的方式提高新类的召回率和准确性,而不需要额外的注释或数据集。我们进一步提出了一种简单的离线伪标签生成策略来改进对象检测器。对 LVIS、V3Det 和 COCO 等三个数据集的实证评估表明,在推理过程中不会产生额外的参数或计算成本,而在基准性能上有了显着的改进。特别是,与之前的 F VLM 相比,我们的方法在 LVIS 数据集上实现了 1.7 2.0 的改进,在最近具有挑战性的 V3Det 数据集上实现了 2.3 3.8 的改进。我们的方法还将 COCO 上的强基线提高了 6 mAP。 |
| EXTRACTER: Efficient Texture Matching with Attention and Gradient Enhancing for Large Scale Image Super Resolution Authors Esteban Reyes Saldana, Mariano Rivera 最近基于参考的图像超分辨率 RefSR 改进了 SOTA 深度方法,引入了注意力机制,通过从参考高分辨率图像传输高分辨率纹理来增强低分辨率图像。主要思想是在特征空间中使用 LR 和参考图像对搜索补丁之间的匹配,并使用深层架构合并它们。然而,现有方法缺乏对纹理的精确搜索。它们将图像分成尽可能多的补丁,导致内存使用效率低下,并且无法管理大图像。在此,我们提出了一种具有更高效内存使用的深度搜索,可显着减少图像块的数量,并为每个低分辨率块在高分辨率参考块上找到 k 个最相关的纹理匹配,从而实现准确的纹理匹配。 |
| Towards Distribution-Agnostic Generalized Category Discovery Authors Jianhong Bai, Zuozhu Liu, Hualiang Wang, Ruizhe Chen, Lianrui Mu, Xiaomeng Li, Joey Tianyi Zhou, Yang Feng, Jian Wu, Haoji Hu 数据不平衡和开放式分布是真实视觉世界的两个固有特征。尽管在单独应对每个挑战方面已经取得了令人鼓舞的进展,但很少有工作致力于将它们结合到现实世界的场景中。虽然之前的几项工作都集中在对封闭集样本进行分类并在测试过程中检测开放集样本,但能够将未知对象分类为人类仍然至关重要。在本文中,我们正式定义了一个更现实的任务,即与分布无关的广义类别发现 DA GCD,在长尾开放世界环境中为封闭集类和开放集类生成细粒度预测。为了解决这一具有挑战性的问题,我们提出了一个自平衡协同建议对比框架 BaCon,它由对比学习分支和伪标签分支组成,协同工作提供交互式监督来解决 DA GCD 任务。特别是,对比学习分支提供可靠的分布估计来规范伪标记分支的预测,进而通过自平衡知识转移和提出的新颖对比损失来指导对比学习。我们将 BaCon 与两个密切相关领域的最先进方法进行比较:不平衡半监督学习和广义类别发现。 BaCon 的有效性通过所有基线的卓越性能和跨各种数据集的综合分析得到证明。 |
| NEUCORE: Neural Concept Reasoning for Composed Image Retrieval Authors Shu Zhao, Huijuan Xu 组合图像检索结合参考图像和文本修饰符来识别所需的目标图像是一项具有挑战性的任务,并且要求模型理解视觉和语言模态及其交互。现有方法侧重于整体多模态交互建模,而忽略了参考图像和文本修饰符之间的组合和互补属性。为了更好地利用多模态输入的互补性进行有效的信息融合和检索,我们将多模态理解移至概念级别的细粒度,并学习多模态概念对齐来识别参考或目标图像中对应的视觉位置文本修饰符。最后,我们提出了一个 NEURal CONcept REasoning NEUCORE 模型,该模型结合了多模态概念对齐和对齐概念上的渐进式多模态融合。具体来说,考虑到文本修饰符可能引用参考图像中不存在且需要添加到目标图像中的语义概念,我们学习了多实例下文本修饰符与参考图像和目标图像的串联之间的多模态概念对齐具有图像和句子级别弱监督的学习框架。此外,基于对齐的概念,为了形成输入模态的判别性融合特征以进行准确的目标图像检索,我们提出了一种渐进融合策略,该策略具有由所关注的语言语义概念实例化的统一执行架构。 |
| Less is More: Toward Zero-Shot Local Scene Graph Generation via Foundation Models Authors Shu Zhao, Huijuan Xu 人类本质上通过选择性视觉感知来识别物体,将视野中的特定区域转化为结构化的符号知识,并根据人类目标分配有限的注意力资源来推理区域之间的关系。虽然对人类来说很直观,但由于需要复杂的认知能力和常识知识,当代感知系统在提取结构信息方面却步履蹒跚。为了填补这一空白,我们提出了一项名为“局部场景图生成”的新任务。与传统的场景图生成任务不同,传统的场景图生成任务包括生成图像中的所有对象和关系,我们提出的任务旨在利用部分对象及其关系抽象相关结构信息,以促进需要高级理解和推理能力的下游任务。相应地,我们引入了零镜头局部场景图生成优雅,这是一个利用以其强大的感知和常识推理而闻名的基础模型的框架,其中基础模型之间的协作和信息通信产生了优异的结果,并实现了零镜头局部场景图生成,而无需标记监督。此外,我们提出了一种新颖的开放式评估指标,实体级 CLIPScorE ECLIPSE,通过超越其有限的标签空间来超越以前的封闭集评估指标,提供更广泛的评估。 |
| Streaming Motion Forecasting for Autonomous Driving Authors Ziqi Pang, Deva Ramanan, Mengtian Li, Yu Xiong Wang 轨迹预测是自主导航中广泛研究的问题。然而,现有的基准评估基于轨迹的独立快照的预测,这不能代表在连续数据流上运行的现实世界应用程序。为了弥补这一差距,我们引入了一个基准,该基准不断查询流数据的未来轨迹,我们将其称为流预测。我们的基准本质上捕获了代理的消失和重新出现,从而提出了预测被遮挡代理的紧急挑战,这是一个安全关键问题,但基于快照的基准却忽视了这一问题。此外,在连续时间戳的背景下进行预测自然要求相邻时间戳的预测之间具有时间一致性。基于这个基准,我们进一步提供流预测的解决方案和分析。我们提出了一种称为 Predictive Streamer 的即插即用元算法,可以将任何基于快照的预测器调整为流式预测器。我们的算法通过用多模态轨迹传播被遮挡代理的位置来估计被遮挡代理的状态,并利用可微滤波器来确保时间一致性。遮挡推理和时间一致性策略都显着提高了预测质量,导致被遮挡智能体的端点误差减小了 25 个,轨迹波动减小了 10 20 个。我们的工作旨在通过强调在其固有的流媒体设置中解决运动预测的重要性来引起社区的兴趣。 |
| Towards reporting bias in visual-language datasets: bimodal augmentation by decoupling object-attribute association Authors Qiyu Wu, Mengjie Zhao, Yutong He, Lang Huang, Junya Ono, Hiromi Wakaki, Yuki Mitsufuji 当人们认为某些知识是普遍理解的,因此不需要明确阐述时,报告偏见就会出现。在本文中,我们关注视觉语言数据集中广泛存在的报告偏差,具体表现为对象属性关联,这可能随后降低在其上训练的模型的性能。为了减轻这种偏差,我们提出了一种双模态增强 BiAug 方法,通过对象属性解耦来灵活地合成具有丰富的对象属性配对的视觉语言示例,并构建跨模态硬负例。我们将大型语言模型 LLM 与接地物体检测器结合使用来提取目标物体。随后,LLM 为每个对象生成详细的属性描述,并生成相应的硬负对应项。然后使用修复模型根据这些详细的对象描述创建图像。通过这样做,合成的示例明确地补充了要学习的省略的对象和属性,并且硬负对引导模型区分对象属性。我们的实验证明 BiAug 在对象属性理解方面表现出色。此外,BiAug 还提高了 MSCOCO 和 Flickr30K 等通用基准上零样本检索任务的性能。 BiAug 改进了收集文本图像数据集的方式。 |
| ZeroI2V: Zero-Cost Adaptation of Pre-trained Transformers from Image to Video Authors Xinhao Li, Limin Wang 将图像模型适应视频领域正在成为解决视频识别任务的有效范例。由于图像模型的参数数量巨大且可有效迁移,执行全面的微调效率较低,甚至没有必要。因此,最近的研究正在将重点转向参数高效的图像到视频的自适应。然而,这些适应策略不可避免地会引入额外的计算成本来处理视频中的域间隙和时间建模。在本文中,我们的目标是提出一种零成本适应范例 ZeroI2V,将图像变换器转移到视频识别任务,即在推理过程中向适应模型引入零额外成本。为了实现这一目标,我们提出了两种核心设计。首先,为了捕捉视频中的动态并降低实现图像到视频自适应的难度,我们利用自注意力的灵活性并引入时空双头注意力 STDHA,它有效地赋予图像转换器零额外参数的时间建模能力,并且计算。其次,为了处理图像和视频之间的域差距,我们提出了一种线性适应策略,该策略利用轻量级密集放置的线性适配器将冻结图像模型完全转移到视频识别。由于其定制的线性设计,所有新添加的适配器都可以在训练后通过结构重新参数化轻松地与原始模块合并,从而在推理过程中实现零额外成本。 |
| Color and Texture Dual Pipeline Lightweight Style Transfer Authors ShiQi Jiang 样式转移方法通常会生成参考样式的颜色和纹理耦合的单一风格化输出,并且在处理具有重复纹理的参考图像时,颜色转移方案可能会引入失真或伪影。为了解决这个问题,我们提出了一种颜色和纹理双管道轻量级风格传输CTDP方法,该方法采用双管道方法同时输出颜色和纹理传输的结果。此外,我们设计了一个掩码总变异损失来抑制颜色传输结果中的伪影和小纹理表示,而不影响内容的语义部分。更重要的是,我们首次能够将强度可控的纹理结构添加到颜色转移结果中。最后,我们对框架的纹理生成机制进行了特征可视化分析,发现对输入图像进行平滑处理几乎可以完全消除这种纹理结构。在对比实验中,CTDP 生成的颜色和纹理传输结果均达到了最先进的性能。 |
| Efficient Remote Sensing Segmentation With Generative Adversarial Transformer Authors Luyi Qiu, Dayu Yu, Xiaofeng Zhang, Chenxiao Zhang 大多数实现高分割精度的深度学习方法都需要深度网络架构,这些架构过于笨重和复杂,无法在存储和内存空间有限的嵌入式设备上运行。为了解决这个问题,本文提出了一种高效的生成对抗变换器 GATrans,用于实现高精度语义分割,同时保持极其有效的尺寸。该框架利用全局变压器网络GTNet作为生成器,通过残差连接有效地提取多级特征。 GTNet 采用具有逐渐线性计算复杂性的全局变换器块,根据可学习的相似性函数重新分配全局特征。为了关注对象级和像素级信息,GATrans 通过结合结构相似性损失来优化目标函数。 |
| 3DHR-Co: A Collaborative Test-time Refinement Framework for In-the-Wild 3D Human-Body Reconstruction Task Authors Jonathan Samuel Lumentut, Kyoung Mu Lee 利用参数化姿势和形状表示的 3D 人体重建(简称 3DHR)领域近年来取得了重大进展。然而,应用 3DHR 技术来处理现实世界的多样化场景(即野外数据)仍然面临局限性。主要的挑战是,由于各种因素,在野外场景中策划准确的 3D 人体姿势地面实况 GT 仍然很难获得。最近的 3DHR 测试时间细化方法利用初始 2D 现成人类关键点信息来支持野外数据缺乏 3D 监督。然而,我们观察到,仅额外的 2D 监督就可能导致常见 3DHR 主干网的过度拟合问题,从而使 3DHR 测试时间细化任务看起来很棘手。我们通过提出一种策略来应对这一挑战,该策略可以在协作方法下补充 3DHR 测试时间细化工作。具体来说,我们最初应用预适应方法,该方法通过在单个框架中协作各种 3DHR 模型来直接改进其初始输出。然后,该方法进一步与特定设置下的测试时间适应工作相结合,最大限度地减少过度拟合问题,以进一步提高 3DHR 性能。整个框架被称为 3DHR Co,在实验方面,我们表明所提出的工作可以显着提高常见经典 3DHR 主干的分数,最高可达 34 mm 姿态误差抑制,使它们在野外排名中名列前茅基准数据。这样的成就表明我们的方法有助于揭示常见经典 3DHR 主干的真正潜力。 |
| Offline Tracking with Object Permanence Authors Xianzhong Liu, Holger Caesar 为了减少手动标记自动驾驶数据集的昂贵劳动力成本,另一种方法是使用离线感知系统自动标记数据集。然而,对象可能会暂时被遮挡。数据集中的此类遮挡场景很常见,但在离线自动标记中尚未得到充分探索。在这项工作中,我们提出了一种专注于被遮挡的对象轨迹的离线跟踪模型。它利用了对象持久性的概念,这意味着即使不再观察到对象,对象也会继续存在。该模型包含三个部分:标准在线跟踪器、关联遮挡前后轨迹的重新识别Re ID模块以及补全碎片轨迹的轨迹补全模块。 Re ID模块和跟踪完成模块使用矢量化地图作为输入之一,通过遮挡来细化跟踪结果。该模型可以有效地恢复被遮挡的物体轨迹。 |
| Faster and Accurate Neural Networks with Semantic Inference Authors Sazzad Sayyed, Jonathan Ashdown, Francesco Restuccia 深度神经网络 DNN 通常会带来巨大的计算负担。虽然已经提出了结构化剪枝和移动特定 DNN 等方法,但它们会导致严重的准确性损失。在本文中,我们利用潜在表示中的内在冗余来减少计算负载,同时性能损失有限。我们表明,语义相似的输入共享许多过滤器,特别是在较早的层中。因此,语义上相似的类可以被聚类以创建聚类特定的子图。为此,我们提出了一个名为语义推理 SINF 的新框架。简而言之,SINF i 使用一个小的附加分类器识别对象所属的语义簇,并且 ii 执行从与该语义簇相关的基础 DNN 中提取的子图进行推理。为了提取每个簇特定的子图,我们提出了一种名为“判别能力得分 DCS”的新方法,该方法找到具有区分特定语义簇成员的能力的子图。 DCS独立于SINF,可以应用于任何DNN。我们针对在 CIFAR100 数据集上训练的 VGG16、VGG19 和 ResNet50 DNN 上的 DCS 性能与 6 种最先进的修剪方法进行了基准测试。我们的结果表明,i SINF 将 VGG19、VGG16 和 ResNet50 的推理时间分别减少了 35、29 和 15,而精度损失仅为 0.17、3.75 和 6.75 ii DCS 分别实现了 3.65、4.25 和 2.36 的更好精度与 VGG16、VGG19 和 ResNet50 相对于现有判别分数 iii 当用作剪枝标准时,DCS 实现了高达 8.13 的准确度增益,比 ICLR 2023 上发表的现有最先进的工作少了 5.82 个参数 iv 当考虑每簇准确度时 |
| Generating 3D Brain Tumor Regions in MRI using Vector-Quantization Generative Adversarial Networks Authors Meng Zhou, Matthias W Wagner, Uri Tabori, Cynthia Hawkins, Birgit B Ertl Wagner, Farzad Khalvati 医学图像分析极大地受益于深度学习的进步,特别是在生成对抗网络 GAN 的应用中,用于生成可以增强训练数据集的真实且多样化的图像。然而,此类方法的有效性通常受到临床环境中可用数据量的限制。此外,常见的基于 GAN 的方法是生成整个图像体积,而不仅仅是感兴趣的区域 ROI。使用 MRI 进行的基于深度学习的脑肿瘤分类研究表明,与整个图像体积相比,对肿瘤 ROI 进行分类更容易。在这项工作中,我们提出了一种新颖的框架,该框架使用矢量量化 GAN 和结合屏蔽令牌建模的变压器来生成高分辨率和多样化的 3D 脑肿瘤 ROI,这些 ROI 可以直接用作脑肿瘤 ROI 分类的增强数据。我们将我们的方法应用于两个不平衡的数据集,其中我们增强了多模式脑肿瘤分割挑战 BraTS 2019 数据集的少数类 1,以生成新的低级别神经胶质瘤 LGG ROI,以与高级神经胶质瘤 HGG 2 类内部儿科 LGG pLGG 数据集肿瘤 ROI 进行平衡BRAF V600E 突变遗传标记,以与 BRAF Fusion 遗传标记类别保持平衡。我们表明,所提出的方法在定性和定量测量方面均优于各种基线模型。生成的数据用于平衡脑肿瘤类型分类任务中的数据。使用增强数据,我们的方法在 BraTS 2019 数据集上的 AUC 超过基线模型 6.4,在我们的内部 pLGG 数据集上超过基线模型 4.3。结果表明,生成的肿瘤 ROI 可以有效解决数据不平衡问题。 |
| Reconstructing 3D Human Pose from RGB-D Data with Occlusions Authors Bowen Dang, Xi Zhao, Bowen Zhang, He Wang 我们提出了一种从带有遮挡的 RGB D 图像重建 3D 人体的新方法。最重要的挑战是由于身体和环境之间的遮挡而导致 RGB D 数据的不完整性,从而导致严重的人体场景穿透而导致令人难以置信的重建。为了重建语义和物理上合理的人体,我们建议根据场景信息和先验知识来减少解空间。我们的关键思想是通过考虑遮挡的身体部位和可见的身体部位,分别对遮挡的身体部位不穿透场景的所有合理姿势进行建模,并使用深度数据约束可见的身体部位,来约束人体的解决方案空间。具体来说,第一个组件是由神经网络实现的,该神经网络估计名为自由区域的候选区域,这是一个从开放空间中划分出来的区域,在该区域内可以安全地搜索不可见身体部位的姿势,而无需担心渗透。第二个组件使用扫描身体点云的截断阴影体积来约束可见的身体部位。此外,我们建议使用体积匹配策略来将人体与受限区域相匹配,该策略比表面匹配具有更好的性能。 |
| Making LLaMA SEE and Draw with SEED Tokenizer Authors Yuying Ge, Sijie Zhao, Ziyun Zeng, Yixiao Ge, Chen Li, Xintao Wang, Ying Shan 大型语言模型法学硕士的巨大成功扩大了多模态的潜力,为通用人工智能AGI的逐步发展做出了贡献。真正的 AGI 智能体不仅应该具备执行预定义的多任务的能力,还应该在开放世界环境中展现出应急能力。然而,尽管最近的多模式法学硕士取得了相当大的进步,但它们在有效统一理解和生成任务方面仍然存在不足,更不用说开放世界的涌现能力了。我们认为,克服当前僵局的关键在于使文本和图像能够在统一的自回归 Transformer 中互换表示和处理。为此,我们引入了 SEED,这是一种精心设计的图像标记器,使法学硕士能够同时进行“查看”和“绘图”。我们确定了两个关键的设计原则 1 图像标记应该独立于 2D 物理补丁位置,而是以 1D 因果依赖性生成,表现出与 LLM 中从左到右的自回归预测机制一致的内在相互依赖性。 2 图像标记应捕获与单词语义抽象程度一致的高级语义,并在标记器训练阶段针对区分性和重建进行优化。借助 SEED 代币,LLM 能够在其原始训练方案下执行可扩展的多模式自回归,即下一个单词预测。因此,SEED LLaMA 是通过对交错的文本和视觉数据进行大规模预训练和指令调整而产生的,在广泛的多模态理解和生成任务中展示了令人印象深刻的性能。 |
| Self-distilled Masked Attention guided masked image modeling with noise Regularized Teacher (SMART) for medical image analysis Authors Jue Jiang, Harini Veeraraghavan 分层移位窗口变换器 Swin 是普通视觉变换器的计算效率更高且更准确的替代方案。基于蒙版图像建模 MIM 的预训练对于提高模型向各种下游任务的可迁移性非常有效。然而,由于缺乏明确的全局注意力,Swin 很难实现更准确、更高效的注意力引导 MIM 方法。因此,我们在架构上增强了 Swin 的语义类注意力,以实现自监督注意力引导与 MIM 的协同蒸馏。我们还引入了噪声注入动量教师,通过教师输入的补丁丢失来实现,以提高训练的正则化和准确性。我们的方法称为 underline 自蒸馏 underline m 问 underline 注意力 MIM 与噪声 underline 正则化 underline 教师 SMART,使用来自多个疾病部位的 10,412 个未标记 3D 计算机断层扫描 CT 进行预训练,这些数据来源于机构和公共数据集。我们评估了 SMART 的多项下游任务,包括分析肺癌 LC 患者的 3D CT,任务 I 预测晚期 LC n 200 个内部数据集中的免疫治疗反应,ii 任务 II 预测早期 LC 手术前 n 156 个公共数据集中的 LC 复发, iii 任务 III LC 分割 n 200 个内部数据集、21 个公共数据集,以及 iv 任务 IV 胸部和腹部器官的无监督聚类 n 1,743 个公共数据集下划线,无需微调。 SMART 预测免疫治疗反应的 AUC 为 0.916,LC 复发的 AUC 为 0.793,分段 LC 的 Dice 准确度为 0.81,聚类器官的类间聚类距离为 5.94,表明 Swin 在医学图像分析中注意力引导 MIM 的能力 |
| Segment Any Building Authors Lei Li 遥感图像中建筑物的识别和分割一直是学术研究的重点。这项工作强调了使用不同数据集和高级表示学习模型来构建遥感图像分割的有效性。通过融合各种数据集,我们扩大了学习资源的范围,并在多个数据集上取得了典范的表现。我们创新的联合培训流程展示了我们的方法在城市规划、灾害管理和环境监测等各个关键领域的价值。我们的方法涉及结合数据集融合技术和预训练模型的提示,为构建分割任务树立了新的先例。 |
| [Re] CLRNet: Cross Layer Refinement Network for Lane Detection Authors Viswesh N, Kaushal Jadhav, Avi Amalanshu, Bratin Mondal, Sabaris Waran, Om Sadhwani, Apoorv Kumar, Debashish Chakravarty 以下工作是用于车道检测的 CLRNet 跨层细化网络的可重复性报告。基本代码由作者提供。该论文提出了一种新颖的跨层细化网络,利用高级和低级特征进行车道检测。 |
| Neural Processing of Tri-Plane Hybrid Neural Fields Authors Adriano Cardace, Pierluigi Zama Ramirez, Francesco Ballerini, Allan Zhou, Samuele Salti, Luigi Di Stefano 在神经场用于存储和通信 3D 数据的吸引人的特性的推动下,直接处理它们以解决分类和零件分割等任务的问题已经出现,并在最近的工作中得到了研究。早期的方法采用由在整个数据集上训练的共享网络参数化的神经场,实现了良好的任务性能,但牺牲了重建质量。为了改进后者,后来的方法侧重于参数化为大型多层感知器 MLP 的单个神经场,然而,由于权重空间的高维性、固有的权重空间对称性以及对随机初始化的敏感性,这些神经场的处理具有挑战性。因此,结果明显不如通过处理显式表示(例如点云或网格)所获得的结果。与此同时,混合表示,特别是基于三平面的混合表示,已经成为实现神经场的更有效和高效的替代方案,但它们的直接处理尚未得到研究。在本文中,我们证明了三平面离散数据结构编码了丰富的信息,可以通过标准深度学习机器有效地处理。我们定义了一个广泛的基准,涵盖各种领域,例如占用率、有符号无符号距离,以及首次的辐射场。 |
| Strength in Diversity: Multi-Branch Representation Learning for Vehicle Re-Identification Authors Eurico Almeida, Bruno Silva, Jorge Batista 本文提出了一种高效、轻量级的多分支深度架构来改进车辆重新识别V ReID。 |
| Ground-A-Video: Zero-shot Grounded Video Editing using Text-to-image Diffusion Models Authors Hyeonho Jeong, Jong Chul Ye 最近视频编辑方面的努力在单属性编辑或风格迁移任务中展示了有希望的结果,无论是通过在文本视频数据上训练文本到视频 T2V 模型还是采用免训练方法。然而,当面对多属性编辑场景的复杂性时,它们表现出一些缺点,例如省略或忽略预期的属性更改、修改输入视频的错误元素以及未能保留输入视频中应保持完整的区域。为了解决这个问题,我们在这里提出了一种新颖的基础引导视频到视频翻译框架,称为 Ground A Video,用于多属性视频编辑。 Ground A Video 以免训练的方式实现了输入视频的时间一致的多属性编辑,没有上述缺点。我们方法的核心是引入交叉帧门控注意力,它将基础信息以时间一致的方式合并到潜在表示中,以及调制交叉注意力和光流引导反向潜在平滑。大量的实验和应用表明,Ground A Video 的零镜头能力在编辑精度和帧一致性方面优于其他基线方法。 |
| LoCUS: Learning Multiscale 3D-consistent Features from Posed Images Authors Dominik A. Kloepfer, Dylan Campbell, Jo o F. Henriques 对于机器人等自主代理来说,一个重要的挑战是维持一个空间和时间一致的世界模型。它必须通过遮挡、以前未见过的视图和长期视野(例如循环闭合和重新识别)来维持。如何在没有监督的情况下训练这种多功能的神经表示仍然是一个悬而未决的问题。我们的想法是,训练目标可以被构建为一个补丁检索问题,给定场景一个视图中的图像补丁,我们希望以高精度检索并召回映射到同一现实世界的其他视图中的所有补丁地点。一个缺点是,这一目标并不能通过实现完美精确召回的场景所独有来促进特征的可重用性,表示在其他场景的上下文中将没有用处。我们发现,通过仔细构建检索集,忽略映射到遥远位置的补丁,可以平衡检索和可重用性。类似地,我们可以通过调整空间容差来轻松调节学习特征的规模,例如点、物体或房间,以将检索视为积极的。我们在基于单一统一排名的目标中针对平滑的平均精度 AP 进行优化。该目标还可以作为选择地标或关键点(如具有高 AP 的补丁)的标准。 |
| Leveraging Cutting Edge Deep Learning Based Image Matching for Reconstructing a Large Scene from Sparse Images Authors Georg B kman, Johan Edstedt |
| Unsupervised Roofline Extraction from True Orthophotos for LoD2 Building Model Reconstruction Authors Weixiao Gao, Ravi Peters, Jantien Stoter 本文讨论了根据大规模城市环境的 2D 和 3D 数据重建 LoD2 建筑模型。传统方法涉及使用激光雷达点云,但由于快速发展地区获取此类数据的成本高且间隔时间长,研究人员已开始探索使用倾斜航空图像生成的点云。然而,将此类点云用于基于传统平面检测的方法可能会导致严重错误,并将噪声引入重建的建筑模型中。为了解决这个问题,本文提出了一种使用线检测从真实正射影像中提取屋顶线的方法,以在 LoD2 级别重建建筑模型。该方法能够提取相对完整的屋顶线,而不需要预先标记的训练数据或预先训练的模型。这些线可以直接用于LoD2建筑模型重建过程。该方法在重建建筑物的准确性和完整性方面优于现有的基于平面检测的方法和最先进的深度学习方法。 |
| Improved Crop and Weed Detection with Diverse Data Ensemble Learning in Agriculture Authors Muhammad Hamza Asad, Saeed Anwar, Abdul Bais 现代农业严重依赖于特定地点的农场管理实践,需要对田间作物和杂草进行准确检测、定位和量化,这可以使用深度学习技术来实现。在这方面,作物和杂草特定的二元分割模型已显示出前景。然而,不受控制的现场条件限制了它们从一个领域到另一个领域的表现。为了提高语义模型的泛化能力,现有方法增强并综合了农业数据,以解决不受控制的田间条件。然而,鉴于现场条件千差万别,这些方法都有局限性。为了克服这种条件下模型恶化的挑战,我们建议利用其他作物和杂草的特定数据来解决我们的特定目标问题。为了实现这一目标,我们提出了一种新颖的集成框架。我们的方法涉及利用在不同数据集上训练的不同作物和杂草模型并采用师生配置。通过使用基础模型的同构堆叠和可训练的元架构来组合它们的输出,我们在未见过的测试数据上实现了油菜作物和地肤杂草的显着改进,超越了单一语义分割模型的性能。我们认为 UNET 元架构在这方面是最有效的。最后,通过消融研究,我们证明并验证了我们提出的模型的有效性。我们观察到,包括在其他目标作物和杂草上训练的基础模型可以帮助概括模型以捕获不同的田间条件。 |
| Unsupervised motion segmentation in one go: Smooth long-term model over a video Authors Etienne Meunier, Patrick Bouthemy 人类有能力连续分析视频并立即提取主要运动成分。运动分割方法通常逐帧进行。我们希望超越这种经典范例,一次性对视频序列执行运动分割。它将成为下游计算机视觉任务的显着附加值,并且可以为无监督视频表示学习提供借口标准。从这个角度来看,我们提出了一种以完全无监督的方式运行的新颖的长期时空模型。它将连续光流 OF 场的体积作为输入,并在视频上传递一定体积的相干运动片段。更具体地说,我们设计了一个基于变压器的网络,其中我们利用数学上建立良好的框架,即 Evidence Lower Bound ELBO 来推断损失函数。损失函数结合了涉及时空参数运动模型的流重建项,以一种新颖的方式结合了 x,y 空间维度的多项式二次运动模型和视频序列时间维度的 B 样条曲线,以及强制时间维度的正则化项面具上的一致性。我们报告了四个 VOS 基准的实验,并提供了令人信服的定量结果。 |
| Learnable Cross-modal Knowledge Distillation for Multi-modal Learning with Missing Modality Authors Hu Wang, Yuanhong Chen, Congbo Ma, Jodie Avery, Louise Hull, Gustavo Carneiro 在多模态模型中,模态缺失的问题既关键又重要。对于多模态任务来说,某些模态比其他模态贡献更大是很常见的,如果缺少这些重要模态,模型性能就会显着下降。当前的多模态方法尚未探索这一事实,这些方法通过特征重建或来自其他模态的盲特征聚合来从丢失的模态中恢复表示,而不是从性能最佳的模态中提取有用的信息。在本文中,我们提出了一种可学习的跨模态知识蒸馏 LCKD 模型,用于自适应地识别重要模态并从中提取知识,以从跨模态的角度帮助其他模态解决缺失的模态问题。我们的方法引入了教师选举程序,根据教师在某些任务上的单一模式表现来选择最合格的教师。然后,在每个任务的教师和学生模态之间进行跨模态知识蒸馏,将模型参数推至对所有任务都有利的点。因此,即使在测试期间缺少某些任务的教师模式,可用的学生模式也可以基于从自动选择的教师模式中学到的知识来很好地完成任务。 |
| Incorporating Supervised Domain Generalization into Data Augmentation Authors Shohei Enomoto, Monikka Roslianna Busto, Takeharu Eda 随着深度学习在户外环境中的应用不断增加,需要增强其鲁棒性,以在面对分布变化(例如压缩伪影)时保持准确性。由于其易用性和众多优点,数据增强是一种广泛使用的提高鲁棒性的技术。然而,它需要更多的训练周期,使得用有限的计算资源训练大型模型变得困难。为了解决这个问题,我们将数据增强视为有监督领域泛化SDG,并受益于SDG方法、对比语义对齐CSA损失,以提高数据增强的鲁棒性和训练效率。所提出的方法仅在模型训练期间增加损失,并且可以用作现有数据增强方法的插件。 |
| A New Real-World Video Dataset for the Comparison of Defogging Algorithms Authors Alexandra Duminil, Jean Philippe Tarel, Roland Br mond 用于去除噪声、去模糊或超分辨率的视频恢复在图像处理和计算机视觉领域引起了越来越多的关注。然而,由于缺乏包含深度学习和基准测试所需的清晰和有雾条件下的视频的数据集,因此使用数据驱动的除雾方法进行视频恢复的工作很少。最近为此目的提出了一个名为 REVIDE 的新数据集。在本文中,我们通过提出一个新的现实世界 VIdeo 数据集来实现相同的方法,用于比较除雾算法 VIREDA,以及各种雾密度和无雾的地面实况。这个小型数据库可以作为除雾算法的测试基地。还提到了仍在开发中的视频去雾算法,其关键思想是使用时间冗余来最大限度地减少帧之间的伪影和曝光变化。 |
| Controlling Vision-Language Models for Universal Image Restoration Authors Ziwei Luo, Fredrik K. Gustafsson, Zheng Zhao, Jens Sj lund, Thomas B. Sch n CLIP 等视觉语言模型对零样本或无标签预测的各种下游任务显示出巨大影响。然而,当涉及低级视觉(例如图像恢复)时,由于输入损坏,它们的性能会急剧恶化。在本文中,我们提出了一种退化感知视觉语言模型 DA CLIP,以更好地将预训练的视觉语言模型转移到低级视觉任务,作为图像恢复的通用框架。更具体地说,DA CLIP 训练一个额外的控制器,该控制器采用固定的 CLIP 图像编码器来预测高质量的特征嵌入。通过交叉注意力将嵌入集成到图像恢复网络中,我们能够引导模型学习高保真图像重建。控制器本身还将输出与输入的真实损坏相匹配的降级特征,从而产生针对不同降级类型的自然分类器。此外,我们还构建了一个带有合成字幕的混合退化数据集,用于 DA CLIP 训练。我们的方法在特定退化和统一图像恢复任务上都取得了最先进的性能,展示了利用大规模预训练视觉语言模型促进图像恢复的有前途的方向。 |
| Multi-task Learning with 3D-Aware Regularization Authors Wei Hong Li, Steven McDonagh, Ales Leonardis, Hakan Bilen 深度神经网络已成为设计模型的标准构建块,这些模型可以执行多个密集计算机视觉任务,例如深度估计和语义分割,因为它们能够捕获跨任务的高维特征空间中的复杂相关性。然而,在非结构化特征空间中学习的跨任务相关性可能非常嘈杂,并且容易过度拟合,从而损害性能。我们建议通过引入结构化 3D 感知正则化器来解决这个问题,该正则化器通过将从图像编码器提取的特征投影到共享 3D 特征空间来连接多个任务,并通过可微渲染将它们解码到任务输出空间中。 |
| LS-VOS: Identifying Outliers in 3D Object Detections Using Latent Space Virtual Outlier Synthesis Authors Aldi Piroli, Vinzenz Dallabetta, Johannes Kopp, Marc Walessa, Daniel Meissner, Klaus Dietmayer 基于 LiDAR 的 3D 物体检测器在自动驾驶应用中实现了前所未有的速度和准确性。然而,与其他神经网络类似,它们通常偏向于高置信度预测或返回不存在真实物体的检测。这些类型的检测可能会导致环境感知不太可靠,严重影响自动驾驶车辆的功能和安全性。我们通过提出 LS VOS 来解决这个问题,这是一个用于识别 3D 对象检测中异常值的框架。我们的方法建立在虚拟异常值合成 VOS 的理念之上,它在训练过程中融入了异常值知识,使模型能够学习更紧凑的决策边界。特别是,我们提出了一种新的合成方法,该方法依赖于自动编码器网络的潜在空间来生成与分布特征具有可参数化相似程度的离群特征。 |
| Towards Robust 3D Object Detection In Rainy Conditions Authors Aldi Piroli, Vinzenz Dallabetta, Johannes Kopp, Marc Walessa, Daniel Meissner, Klaus Dietmayer LiDAR 传感器用于自动驾驶应用,以准确感知环境。然而,它们会受到雪、雾、雨等恶劣天气条件的影响。这些日常现象会给测量带来不必要的噪声,严重降低基于激光雷达的感知系统的性能。在这项工作中,我们提出了一个框架,用于提高基于 LiDAR 的 3D 物体探测器对道路喷雾的鲁棒性。我们的方法使用最先进的恶劣天气检测网络来过滤掉激光雷达点云中的喷雾,然后将其用作物体检测器的输入。这样,检测到的物体就较少受到场景中恶劣天气的影响,从而对环境有更准确的感知。除了恶劣天气过滤之外,我们还探索使用雷达目标来进一步过滤误报检测。 |
| Semi-Blind Image Deblurring Based on Framelet Prior Authors M. Zarebnia, R. Parvaz 图像模糊问题是图像处理领域研究最多的课题之一。图像模糊是由多种因素引起的,例如手或相机抖动。为了恢复模糊图像,需要了解点扩散函数PSF的信息。而且由于在大多数情况下不可能准确计算 PSF,因此我们正在处理近似内核。本文研究半盲图像去模糊问题。由于去模糊问题的模型是病态问题,因此不可能直接解决该问题。解决这个问题最有效的方法之一是使用全变分TV方法。在该算法中,通过使用框架变换和分数计算,对TV方法进行了改进。 |
| Data Efficient Training of a U-Net Based Architecture for Structured Documents Localization Authors Anastasiia Kabeshova, Guillaume Betmont, Julien Lerouge, Evgeny Stepankevich, Alexis Berg s 结构化文档分析和识别对于现代在线登机流程至关重要,而文档本地化是实现可靠关键信息提取的关键步骤。虽然深度学习已成为用于解决文档分析问题的标准技术,但在训练或微调深度学习模型时,工业中的实际应用仍然面临标记数据和计算资源的有限可用性。为了应对这些挑战,我们提出了 SDL Net 一种新颖的类似 U Net 的编码器解码器架构,用于结构化文档的本地化。我们的方法允许在包含各种文档类样本的通用数据集上对 SDL Net 的编码器进行预训练,并实现解码器的快速且数据高效的微调,以支持新文档类的本地化。 |
| Trained Latent Space Navigation to Prevent Lack of Photorealism in Generated Images on Style-based Models Authors Takumi Harada, Kazuyuki Aihara, Hiroyuki Sakai 最近对 StyleGAN 变体的研究表明,它在各种生成任务中都具有良好的性能。在这些模型中,传统上会操纵和搜索潜在代码以获取所需的图像。然而,由于缺乏有关训练的潜在空间的几何形状的知识,这种方法有时会导致生成的图像缺乏真实感。在本文中,我们展示了一种简单的无监督方法,该方法提供训练有素的局部潜在子空间,实现潜在代码导航,同时保留生成图像的真实感。具体来说,该方法识别密集映射的潜在空间并限制局部潜在子空间内的潜在操作。实验结果表明,即使潜在代码被显着且重复地操纵,局部潜在子空间内生成的图像仍能保持真实感。此外,实验表明该方法可以应用于各种类型的基于样式的模型的潜在代码优化。 |
| Enhanced Winter Road Surface Condition Monitoring with Computer Vision Authors Risto Ojala, Alvari Sepp nen 冬季条件给自动驾驶应用带来了一些挑战。冬季的一个关键挑战是准确评估路面状况,因为路面状况对摩擦的影响是安全可靠地控制车辆的关键参数。本文提出了一种深度学习回归模型 SIWNet,能够根据相机图像估计路面摩擦特性。 SIWNet 通过在架构中包含不确定性估计机制来扩展现有技术。这是通过在网络中包含一个额外的头来实现的,该头会估计预测间隔。预测区间头使用最大似然损失函数进行训练。该模型使用 SeeingThroughFog 数据集进行训练和测试,该数据集具有相应的道路摩擦传感器读数和来自仪表车辆的图像。获得的结果突出了 SIWNet 预测区间估计的功能,同时该网络也实现了与先前技术水平相似的点估计精度。 |
| How Close are Other Computer Vision Tasks to Deepfake Detection? Authors Huy H. Nguyen, Junichi Yamagishi, Isao Echizen 在本文中,我们挑战了传统观念,即监督式 ImageNet 训练模型具有很强的通用性,适合用作深度伪造检测中的特征提取器。我们提出了一种新的测量方法,即模型可分离性,用于直观和定量地评估模型以无监督方式分离数据的原始能力。我们还提出了一个系统基准,用于使用预先训练的模型确定深度伪造检测和其他计算机视觉任务之间的相关性。我们的分析表明,预先训练的人脸识别模型比其他模型与 Deepfake 检测的关系更密切。此外,使用自监督方法训练的模型比使用监督方法训练的模型在分离方面更有效。在小型深度伪造数据集上对所有模型进行微调后,我们发现自监督模型可以提供最佳结果,但存在过度拟合的风险。 |
| Every Dataset Counts: Scaling up Monocular 3D Object Detection with Joint Datasets Training Authors Fulong Ma, Xiaoyang Yan, Yuxuan Liu, Ming Liu 单目 3D 物体检测在自动驾驶中发挥着至关重要的作用。然而,现有的单目 3D 检测算法依赖于从 LiDAR 测量得出的 3D 标签,获取新数据集的成本高昂,并且在新环境中部署具有挑战性。具体来说,本研究调查了在各种 3D 和 2D 数据集上训练单目 3D 对象检测模型的流程。所提出的框架包括三个组件:1 能够在各种相机设置下运行的鲁棒单目 3D 模型;2 一种选择性训练策略,以适应具有不同类别注释的数据集;3 一种使用 2D 标签的伪 3D 训练方法,以增强包含以下内容的场景中的检测性能:只有二维标签。通过这个框架,我们可以在各种开放 3D 2D 数据集的联合集上训练模型,以获得具有更强泛化能力的模型,并在仅具有 2D 标签的新数据集上增强性能。 |
| Harnessing the Power of Multi-Lingual Datasets for Pre-training: Towards Enhancing Text Spotting Performance Authors Alloy Das, Sanket Biswas, Ayan Banerjee, Saumik Bhattacharya, Josep Llad s, Umapada Pal 当部署到现实世界条件时,对广泛领域的适应能力对于场景文本识别模型至关重要。然而,现有最先进的 SOTA 方法通常仅通过对自然场景文本数据集进行预训练来合并场景文本检测和识别,而不会直接利用多个域之间的中间特征表示。在这里,我们研究领域自适应场景文本识别问题,即在多领域源数据上训练模型,使其可以直接适应目标领域,而不是专门针对特定领域或场景。此外,我们研究了名为 Swin TESTR 的变压器基线,重点解决规则和任意形状场景文本的场景文本识别问题以及详尽的评估。结果清楚地证明了中间表示在跨多个领域的文本识别基准上实现显着性能的潜力,例如:语言、合成到真实以及文档。 |
| PC-NeRF: Parent-Child Neural Radiance Fields under Partial Sensor Data Loss in Autonomous Driving Environments Authors Xiuzhong Hu, Guangming Xiong, Zheng Zang, Peng Jia, Yuxuan Han, Junyi Ma 重建大规模 3D 场景对于自动驾驶汽车至关重要,尤其是在部分传感器数据丢失的情况下。尽管最近开发的神经辐射场 NeRF 在隐式表示方面显示出了引人注目的结果,但使用部分丢失的 LiDAR 点云数据进行大规模 3D 场景重建仍需要探索。为了弥补这一差距,我们提出了一种新颖的 3D 场景重建框架,称为父子神经辐射场 PC NeRF。该框架包括两个模块,即父 NeRF 和子 NeRF,以同时优化场景级、片段级和点级场景表示。通过利用子 NeRF 的分段级表示功能,可以更有效地利用传感器数据,即使观察有限,也可以快速获得场景的近似体积表示。经过大量实验,我们提出的 PC NeRF 被证明可以在大规模场景中实现高精度 3D 重建。此外,PC NeRF可以有效解决部分传感器数据丢失的情况,并且在训练时间有限的情况下具有较高的部署效率。 |
| RT-GAN: Recurrent Temporal GAN for Adding Lightweight Temporal Consistency to Frame-Based Domain Translation Approaches Authors Shawn Mathew, Saad Nadeem, Alvin C. Goh, Arie Kaufman 在为内窥镜视频开发新的无监督域翻译方法时,通常从最初适用于没有时间一致性的单个帧的方法开始。一旦单个帧模型最终确定,就会通过修改后的深度学习架构添加额外的连续帧,以训练新模型以实现时间一致性。然而,向时间一致的深度学习模型的转变需要更多的计算和内存资源来进行训练。在本文中,我们提出了一种具有可调时间参数的轻量级解决方案 RT GAN Recurrent Temporal GAN,用于为基于单个帧的方法添加时间一致性,从而将训练要求降低 5 倍。我们证明了我们的方法在两个具有挑战性的问题上的有效性结肠镜检查胃皱襞分割中的用例表明遗漏的表面和真实的结肠镜检查模拟器视频生成。 |
| Can Pre-trained Networks Detect Familiar Out-of-Distribution Data? Authors Atsuyuki Miyai, Qing Yu, Go Irie, Kiyoharu Aizawa 分布式 OOD 检测对于安全敏感的机器学习应用至关重要,并且已被广泛研究,产生了大量文献中开发的方法。然而,大多数 OOD 检测研究并未使用预先训练的模型,而是从头开始训练骨干网。近年来,通过轻量级调整将知识从大型预训练模型转移到下游任务已成为分布 ID 分类器训练的主流。为了弥合 OOD 检测实践和当前分类器之间的差距,独特且关键的问题是信息网络已知的样本通常作为 OOD 输入。我们认为此类数据可能会显着影响大型预训练网络的性能,因为这些 OOD 数据的可区分性取决于预训练算法。在这里,我们将此类 OOD 数据定义为 PT OOD Pre Trained OOD 数据。在本文中,我们旨在从预训练算法的角度揭示PT OOD对预训练网络的OOD检测性能的影响。为了实现这一目标,我们利用线性探测调整(最常见的有效调整方法)探索监督和自监督预训练算法的 PT OOD 检测性能。通过我们的实验和分析,我们发现 PT OOD 在特征空间中的低线性可分离性严重降低了 PT OOD 检测性能,并且自监督模型比有监督预训练模型更容易受到 PT OOD 的影响,即使是最先进的检测方法。为了解决这个漏洞,我们进一步提出了一种针对大规模预训练模型的独特解决方案,利用预训练模型的强大实例判别表示,并在独立于 ID 决策边界的特征空间中检测 OOD。 |
| Action Recognition Utilizing YGAR Dataset Authors Shuo Wang, Amiya Ranjan, Lawrence Jiang 高质量动作视频数据的稀缺是动作识别研究和应用的瓶颈。尽管在这一领域已经做出了巨大的努力,但可用数据类型的范围仍然存在差距,更灵活和更全面的数据集可以帮助弥合。在本文中,我们提出了一种新的 3D 动作数据模拟引擎,并生成 3 组样本数据来演示其当前功能。通过新的数据生成过程,我们展示了其在图像分类、动作识别方面的应用,以及演变成一个允许探索更复杂的动作识别任务的系统的潜力。 |
| Large Scale Masked Autoencoding for Reducing Label Requirements on SAR Data Authors Matt Allen, Francisco Dorr, Joseph A. Gallego Mejia, Laura Mart nez Ferrer, Anna Jungbluth, Freddie Kalaitzis, Ra l Ramos Poll n 卫星遥感有助于监测和减轻人为气候变化的影响。从这些传感器获得的大规模、高分辨率数据可用于为干预和政策决策提供信息,但这些干预措施的及时性和准确性受到光学数据使用的限制,光学数据无法在夜间运行,并且会受到恶劣天气条件的影响。合成孔径雷达 SAR 提供了光学数据的强大替代方案,但其相关的复杂性限制了传统深度学习的标记数据生成范围。在这项工作中,我们对覆盖 8.7 个地球陆地表面积的 SAR 振幅数据应用了自监督预训练方案(掩模自动编码),并调整了对监测气候变化植被覆盖预测和土地覆盖分类至关重要的两个下游任务的预训练权重。我们表明,使用这种预训练方案将下游任务的标签要求降低了一个数量级以上,并且这种预训练在地理上具有普遍性,当在预训练集之外的区域进行下游调整时,性能增益会增加。 |
| Sharingan: A Transformer-based Architecture for Gaze Following Authors Samy Tafasca, Anshul Gupta, Jean Marc Odobez 凝视是人类从小就发展起来的一种强大的非语言交流和社交互动形式。因此,对这种行为进行建模是一项重要的任务,可以使从机器人到社会学等广泛的应用领域受益。特别是,注视跟踪被定义为对图像中的人正在注视的像素级 2D 位置的预测。先前在这个方向上的努力主要集中在基于 CNN 的架构上来执行该任务。在本文中,我们介绍了一种基于 Transformer 的新型架构,用于 2D 凝视预测。我们试验了 2 个变体,第一个变体保留了每次预测一个人的注视热图的相同任务公式,而第二个变体将问题转化为 2D 点回归,并允许我们使用单个前向执行多人注视预测经过。这种新架构在 GazeFollow 和 VideoAttentionTarget 数据集上实现了最先进的结果。 |
| Completing Visual Objects via Bridging Generation and Segmentation Authors Xiang Li, Yinpeng Chen, Chung Ching Lin, Rita Singh, Bhiksha Raj, Zicheng Liu 本文提出了一种新的对象完成方法,其主要目标是从部分可见的组件重建完整的对象。我们的方法名为 MaskComp,通过生成和分段的迭代阶段来描述完成过程。在每次迭代中,提供对象掩模作为促进图像生成的附加条件,作为回报,生成的图像可以通过融合图像分割来产生更准确的掩模。我们证明了一代和一个分割阶段的组合可以有效地充当掩模降噪器。通过生成阶段和分割阶段之间的交替,部分对象掩模逐渐细化,提供精确的形状指导并产生出色的对象完成结果。 |
| Towards a Universal Understanding of Color Harmony: Fuzzy Approach Authors Pakizar Shamoi, Muragul Muratbekova, Assylzhan Izbassar, Atsushi Inoue, Hiroharu Kawanaka 如今,和谐水平预测越来越受到关注。颜色在影响人类审美反应方面起着至关重要的作用。在本文中,我们使用基于模糊的颜色模型探索颜色和谐,并解决其普遍性问题。在我们的实验中,我们使用一个数据集,其中包含来自时尚、艺术、自然、室内设计和品牌徽标五个不同领域的有吸引力的图像。我们的目标是使用模糊方法识别这些图像中的和谐模式和主要调色板。它非常适合这项任务,因为它可以处理与美学和色彩和谐评估相关的固有主观性和上下文可变性。我们的实验结果表明,色彩和谐在很大程度上是普遍存在的。此外,我们的研究结果表明,色彩和谐不仅受到色轮上色调关系的影响,还受到颜色饱和度和强度的影响。在具有高和谐水平的调色板中,我们观察到普遍遵守色轮原则,同时保持中等水平的饱和度和强度。 |
| Propagating Semantic Labels in Video Data Authors David Balaban, Justin Medich, Pranay Gosar, Justin Hart 语义分割结合了两个子任务:识别像素级图像掩模以及将语义标签应用于这些掩模。最近,所谓的基础模型引入了在非常大的数据集上训练的通用模型,这些模型可以专门化并应用于更具体的任务。 Segment Anything Model SAM 就是这样的一种模型,它执行图像分割。 CLIPSeg 和 MaskRCNN 等语义分割系统是在配对片段和语义标签的数据集上进行训练的。然而,手动标记自定义数据非常耗时。这项工作提出了一种对视频中的对象进行分割的方法。一旦在视频帧中找到对象,该片段就可以传播到未来的帧,从而减少手动注释工作。该方法的工作原理是将 SAM 与 Motion SfM 的 Structure 相结合。输入到系统的视频首先使用 SfM 重建为 3D 几何形状。然后使用 SAM 对视频帧进行分段。然后将 SAM 识别的线段投影到重建的 3D 几何结构上。在后续视频帧中,标记的 3D 几何体将重新投影到新的视角中,从而减少 SAM 的调用次数。评估系统性能,包括 SAM 和 SfM 组件的贡献。性能通过三个主要指标计算时间、带有手动标签的掩模 IOU 以及跟踪损失的数量进行评估。 |
| SMOOT: Saliency Guided Mask Optimized Online Training Authors Ali Karkehabadi, Avesta Sasan 深度神经网络是理解复杂模式和做出决策的强大工具。然而,它们的黑匣子性质阻碍了对其内部工作原理的完整理解。显着性引导训练SGT方法试图根据输出突出模型训练中的突出特征来缓解这个问题。这些方法使用反向传播和修改梯度来引导模型寻找最相关的特征,同时保持对预测精度的影响可以忽略不计。 SGT 通过部分屏蔽输入使模型的最终结果更易于解释。这样,考虑模型的输出,我们可以推断输入的每个部分如何影响输出。在图像作为输入的特定情况下,掩蔽被应用于输入像素。然而,掩蔽策略和我们掩蔽的像素数量被视为超参数。掩蔽策略的设置是否合适可以直接影响模型的训练。在本文中,我们重点关注这个问题并提出我们的贡献。我们提出了一种新方法来根据训练期间的输入、准确性和模型损失来确定蒙版图像的最佳数量。该策略可以防止信息丢失,从而获得更好的准确度值。此外,通过将模型的性能整合到策略公式中,我们表明我们的模型代表了更有意义的显着特征。 |
| Counterfactual Image Generation for adversarially robust and interpretable Classifiers Authors Rafael Bischof, Florian Scheidegger, Michael A. Kraus, A. Cristiano I. Malossi 神经图像分类器很有效,但本质上难以解释,并且容易受到对抗性攻击。除其他外,这两个问题的解决方案都以反事实示例生成的形式存在,以增强可解释性或对抗性地增加训练数据集以提高鲁棒性。然而,现有方法仅解决其中一个问题。我们提出了一个统一的框架,利用图像到图像转换生成对抗网络 GAN 来生成反事实样本,突出显示可解释性的显着区域,并充当对抗样本来增强数据集以提高鲁棒性。这是通过将分类器和鉴别器组合成一个模型来实现的,该模型将真实图像归为各自的类并将生成的图像标记为假图像。我们通过评估在混凝土裂缝语义分割任务上生成的可解释性掩模以及模型针对水果缺陷检测问题的投影梯度下降 PGD 攻击的弹性来评估该方法的有效性。我们生成的显着性图具有高度描述性,尽管仅在分类标签上进行训练,但与经典分割模型相比,仍实现了有竞争力的 IoU 值。 |
| Mind the Gap: Federated Learning Broadens Domain Generalization in Diagnostic AI Models Authors Soroosh Tayebi Arasteh, Christiane Kuhl, Marwin Jonathan Saehn, Peter Isfort, Daniel Truhn, Sven Nebelung 开发能够很好地推广到未见过的数据集的强大人工智能模型具有挑战性,并且通常需要大型且可变的数据集,最好来自多个机构。在联邦学习 FL 中,模型在多个持有本地数据集但不交换数据的站点上进行协作训练。到目前为止,训练策略(即本地与协作)对解释胸部 X 光片的人工智能模型的域和域外性能诊断的影响尚未得到评估。因此,我们使用来自全球五个机构的 610,000 张胸片,评估了诊断性能作为训练策略(即本地与协作)、网络架构(即基于卷积与基于变压器)、泛化性能(即域内与域外)的函数。 ,影像学发现,即心脏肥大、胸腔积液、肺炎、肺不张、实变、气胸,且无异常,数据集大小,即从 18,000 到 213,921 张 X 线照片,以及数据集多样性。大型数据集不仅显示 FL 的性能提升很小,而且在某些情况下甚至表现出下降。相比之下,较小的数据集显示出显着的改进。因此,域性能主要由训练数据大小驱动。然而,域外性能更多地依赖于训练多样性。当在不同的外部机构之间进行协作训练时,AI 模型始终超过了针对域外任务进行本地训练的模型,这凸显了 FL 在利用数据多样性方面的潜力。 |
| Top-down Green-ups: Satellite Sensing and Deep Models to Predict Buffelgrass Phenology Authors Lucas Rosenblatt, Bin Han, Erin Posthumus, Theresa Crimmins, Bill Howe 一种被称为水牛草的入侵草种导致了美国西南部的严重野火和生物多样性丧失。我们解决了预测水牛草绿化的问题,即除草处理的准备情况。为了做出预测,我们探索了结合卫星传感和深度学习的时间、视觉和多模态模型。 |
| HOH: Markerless Multimodal Human-Object-Human Handover Dataset with Large Object Count Authors Noah Wiederhold, Ava Megyeri, DiMaggio Paris, Sean Banerjee, Natasha Kholgade Banerjee 我们提出了 HOH 人体对象人体移交数据集,这是一个包含 136 个对象的大型对象计数数据集,以加速数据驱动的移交研究、人类机器人移交实施以及根据人交互的 2D 和 3D 数据估计移交参数的人工智能 AI。 HOH 包含多视图 RGB 和深度数据、骨架、融合点云、抓握类型和惯用手标签、对象、给予者手和接收者手 2D 和 3D 分割、给予者和接收者舒适度评级以及配对对象元数据和对齐的 2,720 个 3D 模型跨越 136 个对象和 20 个给予者接收者对 40 的切换交互,由 40 个参与者组织角色逆转。我们还展示了使用 HOH 训练的神经网络执行抓取、定向和轨迹预测的实验结果。作为唯一完全无标记的切换捕获数据集,HOH 代表了自然的人类切换交互,克服了需要特定身体跟踪且缺乏高分辨率手部跟踪的标记数据集的挑战。 |
| Logical Bias Learning for Object Relation Prediction Authors Xinyu Zhou, Zihan Ji, Anna Zhu 场景图生成 SGG 旨在自动将图像映射到语义结构图,以更好地理解场景。它因其提供对象和关系信息的能力而引起了广泛关注,从而为下游任务提供了图形推理。然而,由于数据和训练方法的偏差,它在实践中面临着严重的局限性。在本文中,我们提出了一种基于因果推理的更合理有效的对象关系预测策略。为了进一步评估我们策略的优越性,我们提出了一个对象增强模块来进行消融研究。 Visual Gnome 150 VG 150 数据集上的实验结果证明了我们提出的方法的有效性。 |
| You Do Not Need Additional Priors in Camouflage Object Detection Authors Yuchen Dong, Heng Zhou, Chengyang Li, Junjie Xie, Yongqiang Xie, Zhongbo Li 由于伪装物体与其周围环境高度相似,伪装物体检测 COD 提出了重大挑战。尽管当前的深度学习方法在检测伪装物体方面取得了重大进展,但其中许多方法严重依赖额外的先验信息。然而,在现实世界场景中,获取此类额外的先验信息既昂贵又不切实际。因此,需要开发一种不依赖于额外先验的伪装物体检测网络。在本文中,我们提出了一种新颖的自适应特征聚合方法,该方法有效地结合多层特征信息来生成引导信息。与之前依赖边缘或排名先验的方法相比,我们的方法直接利用从图像特征中提取的信息来指导模型训练。 |
| Comics for Everyone: Generating Accessible Text Descriptions for Comic Strips Authors Reshma Ramaprasad 连环漫画是一种流行的、富有表现力的视觉叙事形式,可以传达幽默、情感和信息。然而,BLV 盲人或低视力群体无法接触到它们,他们无法感知漫画的图像、布局和文本。我们在本文中的目标是为视障群体创建易于理解的连环漫画的自然语言描述。我们的方法由两个步骤组成,首先,我们使用计算机视觉技术提取有关漫画图像的面板、字符和文本的信息,其次,我们使用这些信息作为附加上下文来提示多模态大语言模型 MLLM 生成描述。我们在由人类专家注释的漫画集上测试我们的方法,并使用定量和定性指标来衡量其性能。 |
| Exchange means change: an unsupervised single-temporal change detection framework based on intra- and inter-image patch exchange Authors Hongruixuan Chen, Jian Song, Chen Wu, Bo Du, Naoto Yokoya 变化检测 CD 是利用多时相遥感图像研究生态系统和人类活动动态的一项关键任务。虽然深度学习在 CD 任务中显示出有希望的结果,但它需要大量标记和配对的多时间图像才能实现高性能。对大规模多时相遥感图像进行配对和注释既昂贵又耗时。为了使基于深度学习的 CD 技术更加实用和更具成本效益,我们提出了一种基于图像内和图像间补丁交换 I3PE 的无监督单时间 CD 框架。 I3PE 框架允许在未配对和未标记的单时间遥感图像上训练深度变化检测器,这些图像在现实世界应用中很容易获得。 I3PE 框架包括四个步骤 1 图像内补丁交换方法基于基于对象的图像分析方法和自适应聚类算法,通过交换图像内的补丁,从单个时间图像生成伪双时图像对和相应的变化标签 2 图像间斑块交换方法可以通过在图像之间交换斑块来生成更多类型的土地覆盖变化 3 提出了由多种图像增强方法组成的模拟管道,以模拟真实情况下由不同成像条件引起的事件前后图像之间的辐射差异 4 自监督基于伪标签的学习用于进一步提高变化检测器在无监督和半监督情况下的性能。对两个大型数据集的大量实验表明,I3PE 优于代表性的无监督方法,并且相对于 SOTA 方法,F1 值提高了 10.65 和 6.99。 |
| A Hierarchical Graph-based Approach for Recognition and Description Generation of Bimanual Actions in Videos Authors Fatemeh Ziaeetabar, Reza Safabakhsh, Saeedeh Momtazi, Minija Tamosiunaite, Florentin W rg tter 视频中双手操作动作的细致入微的理解和详细描述性内容的生成对于机器人、人机交互和视频内容分析等学科非常重要。这项研究描述了一种新颖的方法,将基于图的建模与分层注意力机制相结合,从而提高视频描述的精度和综合性。为了实现这一目标,我们首先使用场景图对对象和动作之间的时空相互依赖进行编码,然后在第二步中将其与新颖的三级架构结合起来,使用图注意力网络 GAT 创建分层注意力机制。 3 级 GAT 架构允许识别本地以及全局上下文元素。这样可以对同一视频片段并行生成具有不同语义复杂度的多个描述,从而提高动作识别和动作描述的判别准确性。我们的方法的性能是使用多个 2D 和 3D 数据集进行实证测试的。通过将我们的方法与最先进的方法进行比较,在评估动作识别和描述生成时,我们在准确性、精确度和上下文相关性方面始终获得更好的性能。在大量的消融实验中,我们还评估了模型不同组成部分的作用。通过我们的多层次方法,系统获得不同的语义描述深度,通常也可以在不同人的描述中观察到。 |
| Liveness Detection Competition -- Noncontact-based Fingerprint Algorithms and Systems (LivDet-2023 Noncontact Fingerprint) Authors Sandip Purnapatra, Humaira Rezaie, Bhavin Jawade, Yu Liu, Yue Pan, Luke Brosell, Mst Rumana Sumi, Lambert Igene, Alden Dimarco, Srirangaraj Setlur, Soumyabrata Dey, Stephanie Schuckers, Marco Huber, Jan Niklas Kolf, Meiling Fang, Naser Damer, Banafsheh Adami, Raul Chitic, Karsten Seelert, Vishesh Mistry, Rahul Parthe, Umit Kacar 活体检测 LivDet 是一项向学术界和业界开放的国际竞赛系列,旨在评估和报告演示攻击检测 PAD 的最新技术水平。 LivDet 2023 非接触式指纹竞赛是第一届基于非接触式指纹的 PAD 算法和系统竞赛。该竞赛是非接触式指纹 PAD 的重要基准,为算法和系统的非接触式指纹 PAD 的最新技术提供独立评估,并提供通用评估协议,其中包括各种演示攻击仪器的手指照片PAI 和 live Fingers 向生物识别研究社区提供标准算法和系统评估协议,以及对学术界和工业界最新算法与新旧 Android 智能手机的比较分析。获胜算法的平均总体 PAI 的 APCER 为 11.35,BPCER 为 0.62。获胜系统的 APCER 为 13.0.4(所有智能手机测试的所有 PAI 的平均值),BPCER 为所有测试智能手机的 1.68。还测试了做出基于单个手指的 PAD 决策的四个手指系统。 |
| Reformulating Vision-Language Foundation Models and Datasets Towards Universal Multimodal Assistants Authors Tianyu Yu, Jinyi Hu, Yuan Yao, Haoye Zhang, Yue Zhao, Chongyi Wang, Shan Wang, Yinxv Pan, Jiao Xue, Dahai Li, Zhiyuan Liu, Hai Tao Zheng, Maosong Sun 最近的多模态大语言模型 MLLM 表现出令人印象深刻的感知图像和遵循开放式指令的能力。 MLLM 的功能取决于两个关键因素:模型架构,以促进视觉模块和大型语言模型的特征对齐;以及用于人类指令遵循的多模态指令调整数据集。 i 对于模型架构,大多数现有模型都会引入外部桥接模块来连接视觉编码器和语言模型,这需要额外的特征对齐预训练。在这项工作中,我们发现紧凑的预训练视觉语言模型本质上可以充当视觉和语言之间的开箱即用的桥梁。基于此,我们提出了Muffin框架,它直接采用预先训练的视觉语言模型来充当视觉信号的提供者。 ii 对于多模态指令调优数据集,现有方法忽略了不同数据集之间的互补关系,只是简单地混合来自不同任务的数据集。相反,我们提出 UniMM Chat 数据集,它探索数据集的互补性,以生成 110 万条高质量且多样化的多模态指令。我们合并来自不同数据集的描述同一图像的信息,并将其转换为知识密集型对话数据。实验结果证明了Muffin框架和UniMM Chat数据集的有效性。 Muffin 在广泛的视觉语言任务上实现了最先进的性能,显着超越了 LLaVA 和 InstructBLIP 等最先进的模型。 |
| Beyond Task Performance: Evaluating and Reducing the Flaws of Large Multimodal Models with In-Context Learning Authors Mustafa Shukor, Alexandre Rame, Corentin Dancette, Matthieu Cord 继大型语言模型 LLM 的成功之后,大型多模态模型 LMM(例如 Flamingo 模型及其后续竞争对手)已经开始成为通向通用智能体的自然步骤。然而,与最近的 LMM 的交互揭示了当前评估基准很难捕捉到的主要局限性。事实上,任务表现(例如 VQA 准确性)本身并不能提供足够的线索来了解其真实能力、局限性以及此类模型在多大程度上符合人类期望。为了完善我们对这些缺陷的理解,我们偏离了当前的评估范式,提出了 EvALign ICL 框架,其中我们 1 在 5 个不同的轴幻觉、弃权、组合性、可解释性和指令遵循性。我们对这些轴的评估揭示了 LMM 的主要缺陷。为了有效解决这些问题,并受到法学硕士在情境中学习 ICL 的成功的启发,2我们探索 ICL 作为解决方案,并研究它如何影响这些限制。基于我们的 ICL 研究,3我们进一步推动了 ICL,并提出了新的多模式 ICL 方法,例如多任务 ICL、事后链 ICL 和自我校正 ICL。我们的研究结果如下 1 尽管 LMM 取得了成功,但它仍然存在仅通过扩展无法解决的缺陷。 2 ICL 对 LMM 缺陷的影响是微妙的,尽管它可以有效提高可解释性、弃权和指令遵循能力,但 ICL 不会提高作文能力,实际上甚至会放大幻觉。 3 拟议的 ICL 变体作为事后方法有望有效解决其中一些缺陷。 |
| RegBN: Batch Normalization of Multimodal Data with Regularization Authors Morteza Ghahremani, Christian Wachinger 近年来,由于神经网络在多模态数据集成方面取得的巨大成功,人们对集成多源传感器捕获的高维数据的兴趣激增。然而,异构多模态数据的集成提出了重大挑战,因为此类异构数据源之间的混杂效应和依赖性引入了不需要的可变性和偏差,导致多模态模型的性能不佳。因此,在融合之前对从数据模态中提取的低级或高级特征进行标准化变得至关重要。本文介绍了一种多模态数据标准化的新方法,称为 RegBN,它结合了正则化。 RegBN 使用 Frobenius 范数作为正则项来解决不同数据源之间混杂因素和潜在依赖关系的副作用。所提出的方法可以很好地推广到多种模式,并且消除了对可学习参数的需要,从而简化了训练和推理。我们在来自五个研究领域的八个数据库上验证了 RegBN 的有效性,涵盖语言、音频、图像、视频、深度、表格和 3D MRI 等多种模式。所提出的方法展示了跨不同架构(例如多层感知器、卷积神经网络和视觉变换器)的广泛适用性,使得多模态神经网络中的低级和高级特征能够有效标准化。 |
| Win-Win: Training High-Resolution Vision Transformers from Two Windows Authors Vincent Leroy, Jerome Revaud, Thomas Lucas, Philippe Weinzaepfel Transformer 已成为最先进视觉架构的标准,在图像级别和密集像素任务上实现了令人印象深刻的性能。然而,为高分辨率像素任务训练视觉变换器的成本高昂。典型的解决方案归结为分层架构、快速且近似的注意力或低分辨率作物的训练。后一种解决方案不会限制架构选择,但在以明显高于训练所用分辨率进行测试时,会导致性能明显下降,因此需要临时且缓慢的后处理方案。在本文中,我们提出了一种用于高分辨率视觉变换器的高效训练和推理的新策略,其关键原理是在训练期间屏蔽大部分高分辨率输入,仅保留 N 个随机窗口。这使得模型能够学习每个窗口内令牌之间的本地交互,以及来自不同窗口的令牌之间的全局交互。因此,该模型可以在测试时直接处理高分辨率输入,无需任何特殊技巧。我们证明,当使用相对位置嵌入(例如旋转嵌入)时,该策略是有效的。它的训练速度比全分辨率网络快 4 倍,并且与现有方法相比,在测试时使用起来也很简单。我们将此策略应用于语义分割的密集单目任务,并发现具有 2 个窗口的简单设置效果最佳,因此我们的方法被命名为 Win Win。 |
| Finger-UNet: A U-Net based Multi-Task Architecture for Deep Fingerprint Enhancement Authors Ekta Gavas, Anoop Namboodiri 几十年来,指纹识别在安全、取证和其他生物识别应用中一直很普遍。然而,高质量指纹的可用性具有挑战性,使得识别变得困难。指纹图像可能会因脊线结构不良和噪声或对比度较低的背景而降级。因此,指纹增强在指纹识别验证流程的早期阶段起着至关重要的作用。在本文中,我们研究并改进了编码器解码器风格架构,并建议对 U Net 进行直观修改,以有效增强低质量指纹。我们研究了使用离散小波变换 DWT 进行指纹增强,并使用小波注意模块而不是最大池化,这证明对我们的任务是有利的。此外,我们用深度可分离卷积替换常规卷积,这显着减少了模型的内存占用,而不会降低性能。我们还证明,将领域知识与指纹细节预测任务相结合可以通过多任务学习来改进指纹重建。此外,我们还集成了方向估计任务来传播脊方向的知识,以进一步提高性能。 |
| GhostEncoder: Stealthy Backdoor Attacks with Dynamic Triggers to Pre-trained Encoders in Self-supervised Learning Authors Qiannan Wang, Changchun Yin, Zhe Liu, Liming Fang, Run Wang, Chenhao Lin 在计算机视觉领域,自监督学习 SSL 涉及利用大量未标记图像来训练预先训练的图像编码器。预先训练的图像编码器可以用作特征提取器,有助于为各种任务构建下游分类器。然而,SSL 的使用导致了与各种后门攻击相关的安全研究的增加。目前,SSL后门攻击中使用的触发模式大多是可见的或静态样本不可知的,这使得后门的隐蔽性较低,并显着影响攻击性能。在这项工作中,我们提出了 GhostEncoder,这是第一个针对 SSL 的动态隐形后门攻击。与使用可见或静态触发模式的现有 SSL 后门攻击不同,GhostEncoder 利用图像隐写技术将隐藏信息编码为良性图像并生成后门样本。然后,我们在操作数据集上微调预训练的图像编码器以注入后门,使基于后门编码器的下游分类器能够继承目标下游任务的后门行为。我们在三个下游任务上对 GhostEncoder 进行了评估,结果表明 GhostEncoder 在图像上提供了实用的隐秘性,并以高攻击成功率欺骗了受害者模型,而不会影响其实用性。 |
| Scene-aware Human Motion Forecasting via Mutual Distance Prediction Authors Chaoyue Xing, Wei Mao, Miaomiao Liu 在本文中,我们解决场景感知 3D 人体运动预测问题。这项任务的一个关键挑战是通过对人类场景交互进行建模来预测与场景一致的未来人类运动。虽然最近的工作已经证明,对人类场景交互的显式约束可以防止鬼运动的发生,但它们仅对部分人类运动提供约束,例如人类的全局运动或接触场景的几个关节,而使其余运动不受约束。为了解决这个限制,我们建议根据人体与场景之间的相互距离来模拟人体场景交互。这种相互距离限制了局部和全局人体运动,从而导致全身运动受限预测。具体来说,相互距离约束由两个部分组成:人体网格上每个顶点到场景表面的有符号距离,以及基本场景点到人体网格的距离。我们开发了一个具有两个预测步骤的管道,首先根据过去的人体运动序列和场景预测未来的相互距离,然后根据预测的相互距离预测未来的人体运动调节。在训练过程中,我们明确鼓励预测姿势和相互距离之间的一致性。 |
| Skip-Plan: Procedure Planning in Instructional Videos via Condensed Action Space Learning Authors Zhiheng Li, Wenjia Geng, Muheng Li, Lei Chen, Yansong Tang, Jiwen Lu, Jie Zhou 在本文中,我们提出了 Skip Plan,一种用于教学视频中的程序规划的压缩动作空间学习方法。目前的程序规划方法都坚持每个时间步的状态动作对预测并相邻地生成动作。尽管它与人类直觉一致,但这种方法始终与高维状态监督和动作序列的错误累积作斗争。在这项工作中,我们将程序规划问题抽象为数学链模型。通过跳过动作链中的不确定节点和边,我们通过两种方式将长而复杂的序列函数转换为短但可靠的序列函数。首先,我们跳过所有中间状态监督,只关注动作预测。其次,我们通过跳过不可靠的中间动作,将相对较长的链分解为多个较短的子链。通过这种方式,我们的模型探索了压缩动作空间中动作序列内的各种可靠的子关系。 |
| Pink: Unveiling the Power of Referential Comprehension for Multi-modal LLMs Authors Shiyu Xuan, Qingpei Guo, Ming Yang, Shiliang Zhang 多模态大语言模型 MLLM 在许多视觉语言任务中表现出了卓越的能力。尽管如此,大多数 MLLM 仍然缺乏识别图像中特定对象或区域的参考理解 RC 能力,限制了它们在细粒度感知任务中的应用。本文提出了一种增强 MLLM 的 RC 能力的新方法。我们的模型使用其边界框的坐标来表示图像中的引用对象,并将坐标转换为特定格式的文本。这允许模型将坐标视为自然语言。此外,我们通过释放现有数据集中注释的潜力,以低成本构建具有各种设计的 RC 任务的指令调优数据集。为了进一步提高模型的 RC 能力,我们提出了一种自一致引导方法,将数据集的密集对象注释扩展到高质量的引用表达式边界框对。该模型使用参数高效的调优框架进行端到端训练,该框架允许两种模态都从多模态指令调优中受益。该框架需要更少的可训练参数和训练数据。传统视觉语言和 RC 任务的实验结果证明了我们方法的优越性能。例如,在零样本设置下,我们的模型在 VSR 上比 Instruct BLIP 的绝对精度提高了 12.0,在 RefCOCO val 上比 Kosmos 2 提高了 24.7。我们还在 MMBench 排行榜上名列前茅。 |
| CPIPS: Learning to Preserve Perceptual Distances in End-to-End Image Compression Authors Chen Hsiu Huang, Ja Ling Wu 有损图像编码标准(例如 JPEG 和 MPEG)已成功实现了人类多媒体数据消费的高压缩率。然而,随着物联网设备、无人机和自动驾驶汽车的日益普及,机器而不是人类正在处理更多捕获的视觉内容。因此,寻求一种不仅满足人类视觉而且满足图像处理和机器视觉任务的高效压缩表示至关重要。从生物系统中的有效编码假设和神经科学中的感觉皮层建模中汲取灵感,我们重新利用压缩的潜在表示来优先考虑语义相关性,同时保留感知距离。 |
| Diving into the Depths of Spotting Text in Multi-Domain Noisy Scenes Authors Alloy Das, Sanket Biswas, Umapada Pal, Josep Llad s 当在现实世界的嘈杂环境中使用时,泛化到多个域的能力对于任何自主场景文本识别系统都是至关重要的。然而,现有的最先进方法在自然场景数据集上采用预训练和微调策略,这些策略没有利用跨其他复杂领域的特征交互。在这项工作中,我们探索和研究与领域无关的场景文本识别问题,即在多领域源数据上训练模型,使其可以直接泛化到目标领域,而不是专门针对特定领域或场景。在这方面,我们向社区提供了一个名为 Under Water Text UWT 的文本识别验证基准,用于嘈杂的水下场景,以建立一个重要的案例研究。此外,我们还设计了一种高效的基于超分辨率的端到端变压器基线,称为 DA TextSpotter,它在常规和任意形状的场景文本识别基准方面,在准确性和模型效率方面均实现了与现有文本识别架构相当或更好的性能。 |
| Seal2Real: Prompt Prior Learning on Diffusion Model for Unsupervised Document Seal Data Generation and Realisation Authors Jiancheng Huang, Yifan Liu, Yi Huang, Shifeng Chen 在文档处理中,印章相关任务有着非常大的商业应用,比如印章分割、印章真伪判别、印章去除、印章下的文字识别等。然而,这些与印章相关的任务高度依赖于带标签的文档印章数据集,导致这些任务的工作量非常少。为了解决这些印章相关任务缺乏标记数据集的问题,我们提出了 Seal2Real,一种生成大量标记文档印章数据的生成方法,并构建了包含 20K 带标签图像的 Seal DB 数据集。在 Seal2Real 中,我们提出了一种基于预先训练的稳定扩散模型的即时先验学习架构,该模型通过无监督训练将先验生成能力迁移到我们的印章生成任务中。真实的密封生成能力极大地促进了下游密封相关任务在真实数据上的执行。 |
| Enabling Neural Radiance Fields (NeRF) for Large-scale Aerial Images -- A Multi-tiling Approaching and the Geometry Assessment of NeRF Authors Ningli Xu, Rongjun Qin, Debao Huang, Fabio Remondino 神经辐射场 NeRF 提供了有利于 3D 重建任务的潜力,包括航空摄影测量。然而,大规模航空资产的推断几何形状的可扩展性和准确性并没有得到很好的记录,因为此类数据集通常会导致非常高的内存消耗和缓慢的收敛速度。在本文中,我们的目标是在大规模航空数据集上扩展 NeRF并提供 NeRF 的全面几何评估。具体来说,我们引入了位置特定采样技术以及多相机平铺 MCT 策略,以减少 RAM 图像加载、GPU 内存表示训练期间的内存消耗,并提高平铺内的收敛速度。 MCT 将大帧图像分解为具有不同相机型号的多个平铺图像,允许将这些小帧图像根据特定位置的需要输入到训练过程中,而不会损失准确性。我们在代表性方法 Mip NeRF 上实现了我们的方法,并将其几何性能与两个典型航空数据集上的三摄影测量 MVS 管道与 LiDAR 参考数据进行了比较。 |
| Self-supervised Learning of Contextualized Local Visual Embeddings Authors Thalles Santos Silva, Helio Pedrini, Ad n Ram rez Rivera 我们提出了上下文化局部视觉嵌入 CLoVE,这是一种基于自监督卷积的方法,可以学习适合密集预测任务的表示。 CLoVE 偏离了当前的方法,并优化了单个损失函数,该函数在从卷积神经网络 CNN 编码器的输出特征图学习到的上下文局部嵌入级别上运行。为了学习上下文嵌入,CLoVE 提出了一个归一化的多头自注意力层,它根据相似性结合图像不同部分的局部特征。我们在多个数据集上对 CLoVE 的预训练表示进行了广泛的基准测试。 CLoVE 在 4 个密集预测下游任务中达到了基于 CNN 的架构的最先进性能,包括对象检测、实例分割、关键点检测和密集姿态估计。 |
| Assessing the Generalizability of Deep Neural Networks-Based Models for Black Skin Lesions Authors Luana Barros, Levy Chaves, Sandra Avila 黑色素瘤是最严重的皮肤癌类型,因为它能够引起转移。它在黑人中更为常见,通常影响手掌、脚底和指甲等肢端区域。深度神经网络在改善临床护理和皮肤癌诊断方面显示出巨大的潜力。然而,主流研究主要依赖于白色肤色的数据集,忽略了报告不同患者肤色的诊断结果。在这项工作中,我们评估了从黑人个体中常见的肢端区域提取的皮肤病变图像中的监督和自监督模型。此外,我们精心策划了包含肢端区域皮肤病变的数据集,并评估有关菲茨帕特里克量表的数据集,以验证在黑色皮肤上的性能。我们的结果暴露了这些模型的普遍性较差,揭示了它们对白色皮肤病变的良好性能。忽视创建多样化的数据集(需要开发专门的模型)是不可接受的。深度神经网络在改善诊断方面具有巨大潜力,特别是对于接触皮肤科的人群而言。 |
| Exploring SAM Ablations for Enhancing Medical Segmentation in Radiology and Pathology Authors Amin Ranem, Niklas Babendererde, Moritz Fuchs, Anirban Mukhopadhyay 医学成像在各种医疗状况的诊断和治疗计划中发挥着至关重要的作用,放射学和病理学严重依赖于精确的图像分割。 Segment Anything Model SAM 已成为解决不同领域的细分挑战的一个有前途的框架。在本白皮书中,我们深入研究 SAM,分解其基本组成部分并揭示它们之间复杂的相互作用。我们还探索了 SAM 的微调,并评估其对分割结果的准确性和可靠性的深远影响,重点关注放射学(特别是脑肿瘤分割)和病理学(特别是乳腺癌分割)中的应用。通过一系列精心设计的实验,我们分析了SAM在医学成像领域的潜在应用。 |
| Black-box Attacks on Image Activity Prediction and its Natural Language Explanations Authors Alina Elena Baia, Valentina Poggioni, Andrea Cavallaro 可解释的 AI XAI 方法旨在描述深度神经网络的决策过程。早期的 XAI 方法产生视觉解释,而较新的技术产生包括文本信息和视觉表示的多模态解释。 Visual XAI 方法已被证明容易受到白盒和灰盒对抗性攻击,攻击者完全或部分了解并访问目标系统。由于多模态 XAI 模型的漏洞尚未得到检验,因此在本文中,我们首次评估了基于自我理性化图像的活动识别模型生成的自然语言解释对黑盒攻击的鲁棒性。我们产生不受限制的空间变异扰动,破坏预测与相应解释之间的关联,从而误导模型生成不忠实的解释。 |
| Small Visual Language Models can also be Open-Ended Few-Shot Learners Authors Mohammad Mahdi Derakhshani, Ivona Najdenkoska, Cees G. M. Snoek, Marcel Worring, Yuki M. Asano 我们提出了自上下文适应 SeCAt,这是一种自我监督方法,可以解锁小型视觉语言模型的开放式少数镜头能力。我们提出的适应算法明确地从符号但自我监督的训练任务中学习。具体来说,我们的方法以自我监督的方式模仿图像标题,基于对大量图像进行聚类,然后为聚类分配语义上不相关的名称。通过这样做,我们构建了 self context ,一个由图像和伪标题对的交错序列组成的训练信号,以及一个查询图像,模型被训练以产生正确的伪标题。我们在多个多模态少镜头数据集上展示了 SeCAt 的性能和灵活性,涵盖了各种粒度。通过使用具有大约 1B 参数的模型,我们超越了较大模型(例如 Frozen 和 FROMAGe)的少数射击能力。 |
| The Sparsity Roofline: Understanding the Hardware Limits of Sparse Neural Networks Authors Cameron Shinn, Collin McCarthy, Saurav Muralidharan, Muhammad Osama, John D. Owens 我们介绍了 Sparsity Roofline,这是一种用于评估神经网络稀疏性的视觉性能模型。 Sparsity Roofline 联合建模网络准确性、稀疏性和预测推理加速。我们的方法不需要实现优化内核并对其进行基准测试,并且预测的加速比等于相应的密集和稀疏内核同样优化时测量到的加速比。我们通过一种用于预测稀疏网络性能的新颖分析模型来实现这一目标,并使用在一系列稀疏模式和程度上修剪的几种现实世界计算机视觉架构来验证预测的加速。我们通过两个案例研究展示了我们的模型的实用性和易用性:1我们展示了机器学习研究人员如何预测未实现或未优化的块结构稀疏模式的性能,2我们展示了硬件设计人员如何预测新稀疏性的性能影响硬件中的模式和稀疏数据格式。 |
| Diff-DOPE: Differentiable Deep Object Pose Estimation Authors Jonathan Tremblay, Bowen Wen, Valts Blukis, Balakumar Sundaralingam, Stephen Tyree, Stan Birchfield 我们引入了 Diff DOPE,这是一种 6 DoF 姿态细化器,它将图像、对象的 3D 纹理模型和对象的初始姿态作为输入。该方法使用可微渲染来更新物体姿态,以最小化图像和模型投影之间的视觉误差。我们证明,这个简单但有效的想法能够在姿势估计数据集上实现最先进的结果。我们的方法与最近的方法不同,其中姿势细化器是在大型合成数据集上训练的深度神经网络,用于将输入映射到细化步骤。相反,我们使用可微分渲染可以让我们完全避免训练。我们的方法以不同的随机学习率并行执行多个梯度下降优化,以避免对称对象、相似外观或错误步长的局部最小值。可以使用各种模式,例如 RGB、深度、强度边缘和对象分割掩模。 |
| UniLVSeg: Unified Left Ventricular Segmentation with Sparsely Annotated Echocardiogram Videos through Self-Supervised Temporal Masking and Weakly Supervised Training Authors Fadillah Maani, Asim Ukaye, Nada Saadi, Numan Saeed, Mohammad Yaqub 超声心动图已成为一般心脏健康评估不可或缺的临床成像方式。从计算射血分数等生物标志物到患者心力衰竭的概率,心脏及其结构的准确分割使医生能够更精确地计划和执行治疗。然而,由于不同的原因,实现准确和稳健的左心室分割既耗时又具有挑战性。这项工作介绍了一种从稀疏注释的超声心动图视频中进行一致的左心室 LV 分割的新方法。我们通过 1 个使用时间掩蔽的自监督学习 SSL 和 2 个弱监督训练来实现这一目标。我们研究了两种不同的分割方法:3D 分割和新颖的 2D 超图像 SI。我们展示了我们提出的方法如何在大规模数据集 EchoNet Dynamic 上获得 93.32 95 CI 93.21 93.43 的骰子分数,同时效率更高,从而超越最先进的解决方案。为了展示我们方法的有效性,我们提供了广泛的消融研究,包括预训练设置和各种深度学习骨干。此外,我们还讨论了我们提出的方法如何通过在训练过程中合并未标记的框架来实现高数据效用。 |
| Human-Producible Adversarial Examples Authors David Khachaturov, Yue Gao, Ilia Shumailov, Robert Mullins, Ross Anderson, Kassem Fawaz 迄今为止,视觉对抗示例仅限于数字世界中的像素级图像操作,或者需要在物理现实世界中生产复杂的设备,例如 2D 或 3D 打印机。我们提出了第一种为现实世界生成人类可生成的对抗性示例的方法,该方法只需要一支记号笔就可以了。我们称它们为 textbf 对抗性标签。首先,在差分渲染的基础上,我们证明可以仅用线条构建有效的对抗性示例。我们发现,只需绘制 4 条线,我们就可以在 54.8 的案例中扰乱基于 YOLO 的模型,如果将其增加到 9 条线,就会扰乱 81.8 的测试案例。接下来,我们设计了一种改进的方法,使线条放置不受人类绘图错误的影响。我们在数字和模拟世界中彻底评估我们的系统,并证明我们的标签可以由未经训练的人类应用。我们通过进行用户研究来证明我们的方法在生成现实世界对抗性示例方面的有效性,其中参与者被要求使用数字等效物作为指导在印刷图像上绘制。我们进一步评估有针对性和非针对性攻击的有效性,并讨论各种权衡和方法限制,以及我们工作的实际和道德影响。 |
| DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models Authors Zhiyao Sun, Tian Lv, Sheng Ye, Matthieu Gaetan Lin, Jenny Sheng, Yu Hui Wen, Minjing Yu, Yong jin Liu 由语音驱动的风格 3D 面部动画的生成提出了重大挑战,因为它需要学习语音、风格和相应的自然面部运动之间的多对多映射。然而,现有方法要么采用语音到运动映射的确定性模型,要么使用单热编码方案对风格进行编码。值得注意的是,一种热门编码方法无法捕获样式的复杂性,从而限制了泛化能力。在本文中,我们提出了 DiffPoseTalk,这是一种基于扩散模型与风格编码器相结合的生成框架,可从短参考视频中提取风格嵌入。在推理过程中,我们采用无分类器指导来指导基于语音和风格的生成过程。我们将其扩展为包括头部姿势的生成,从而增强用户感知。此外,我们还通过在野生视听数据集中使用高质量的重建 3DMM 参数来训练我们的模型,解决了扫描 3D 说话人脸数据的短缺问题。我们广泛的实验和用户研究表明,我们的方法优于最先进的方法。 |
| Technical Report of 2023 ABO Fine-grained Semantic Segmentation Competition Authors Zeyu Dong 在本报告中,我们描述了我们向 2023 年 ABO 细粒度语义分割竞赛提交的技术细节,作者为 Zeyu Dong 团队,用户名为 ZeyuDong。任务是预测五个类别的凸形状的语义标签,这些类别由可在线购买的真实产品的高质量、标准化 3D 模型组成。通过使用 DGCNN 作为骨干对五个类别的不同结构进行分类,我们进行了大量的实验,发现带有热重启的学习率随机梯度下降以及为不同类别设置不同的因子率对模型的性能贡献最大。 |
| PixArt-$α$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis Authors Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie1, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, Zhenguo Li 最先进的文本到图像 T2I 模型需要大量的训练成本,例如数百万个 GPU 小时,严重阻碍了 AIGC 社区的根本创新,同时增加了二氧化碳排放。本文介绍了 PIXART alpha ,这是一种基于 Transformer 的 T2I 扩散模型,其图像生成质量可与最先进的图像生成器(例如 Imagen、SDXL 甚至 Midjourney)竞争,达到接近商业应用的标准。此外,它还支持高达 1024px 分辨率的高分辨率图像合成,训练成本较低,如图 1 和图 2 所示。为了实现这一目标,提出了三个核心设计 1 训练策略分解 我们设计了三个不同的训练步骤,分别优化像素依赖性、文本图像对齐和图像美学质量 2 高效的 T2I Transformer 我们将交叉注意模块合并到 Diffusion Transformer DiT 中,以注入文本条件并简化计算密集型条件分支 3 高信息量数据 我们强调文本图像对中概念密度的重要性,利用大型视觉语言模型自动标记密集的伪字幕,以辅助文本图像对齐学习。因此,PIXART alpha 的训练速度明显超过现有的大规模 T2I 模型,例如,PIXART alpha 仅需要 10.8 秒的 Stable Diffusion v1.5 训练时间 675 vs. 6,250 A100 GPU 天,节省近 300,000 26,000 vs. 320,000,并减少90 二氧化碳排放量。此外,与更大的 SOTA 模型 RAPHAEL 相比,我们的训练成本仅为 1 。大量实验表明,PIXART alpha 在图像质量、艺术性和语义控制方面表现出色。 |
| MVC: A Multi-Task Vision Transformer Network for COVID-19 Diagnosis from Chest X-ray Images Authors Huyen Tran, Duc Thanh Nguyen, John Yearwood 使用基于计算机的算法进行医学图像分析引起了研究界的广泛关注,并在过去十年中取得了巨大进展。随着计算资源的最新进步和大规模医学图像数据集的可用性,已经开发了许多深度学习模型用于医学图像的疾病诊断。然而,现有技术侧重于单独的子任务,例如疾病分类和识别,而缺乏支持多任务诊断的统一框架。受 Vision Transformer 在局部和全局表示学习中的能力的启发,我们在本文中提出了一种新方法,即多任务 Vision Transformer MVC,用于同时对胸部 X 射线图像进行分类并从输入数据中识别受影响的区域。我们的方法基于 Vision Transformer 构建,但在多任务设置中扩展了其学习能力。我们评估了我们提出的方法,并将其与 COVID 19 胸部 X 射线图像基准数据集的现有基线进行了比较。 |
| SSIF: Learning Continuous Image Representation for Spatial-Spectral Super-Resolution Authors Gengchen Mai, Ni Lao, Weiwei Sun, Yuchi Ma, Jiaming Song, Chenlin Meng, Hongxu Ma, Jinmeng Rao, Ziyuan Li, Stefano Ermon 现有的数字传感器以固定的空间和光谱分辨率捕获图像,例如 RGB、多光谱和高光谱图像,每种组合都需要定制的机器学习模型。神经隐式函数通过以与分辨率无关的方式表示图像来部分克服空间分辨率的挑战。然而,它们仍然以固定的、预定义的光谱分辨率运行。为了应对这一挑战,我们提出了空间光谱隐式函数 SSIF,这是一种神经隐式模型,它将图像表示为空间域中连续像素坐标和光谱域中连续波长的函数。我们凭经验证明了 SSIF 在两个具有挑战性的空间光谱超分辨率基准上的有效性。我们观察到,即使允许基线在每个光谱分辨率下训练单独的模型,SSIF 始终优于最先进的基线。我们证明 SSIF 可以很好地推广到不可见的空间分辨率和光谱分辨率。 |
| Controlling Neural Style Transfer with Deep Reinforcement Learning Authors Chengming Feng, Jing Hu, Xin Wang, Shu Hu, Bin Zhu, Xi Wu, Hongtu Zhu, Siwei Lyu 控制神经风格迁移 NST 中的风格化程度有点棘手,因为它通常需要对超参数进行手工设计。在本文中,我们提出了第一个基于深度强化学习 RL 的架构,该架构将一步风格迁移分解为 NST 任务的逐步过程。我们基于强化学习的方法倾向于在早期步骤中保留内容图像的更多细节和结构,并在后续步骤中合成更多风格模式。这是一种用户易于控制的风格转移方法。此外,由于我们的基于强化学习的模型逐步执行风格化,因此它比现有的基于深度学习的单步模型具有轻量级且计算复杂度更低的特点。 |
| MonoGAE: Roadside Monocular 3D Object Detection with Ground-Aware Embeddings Authors Lei Yang, Jiaxin Yu, Xinyu Zhang, Jun Li, Li Wang, Yi Huang, Chuang Zhang, Hong Wang, Yiming Li 尽管最近大多数自动驾驶系统都专注于开发基于自我车辆传感器的感知方法,但有一种被忽视的替代方法,即利用智能路边摄像头来帮助将自我车辆感知能力扩展到视觉范围之外。我们发现大多数现有的单目 3D 物体检测器依赖于自我车辆的先验假设,即相机的光轴与地面平行。然而,路边摄像机安装在具有倾斜角度的杆子上,这使得现有方法对于路边场景来说不是最佳的。在本文中,我们介绍了一种具有地面感知嵌入的路边单目 3D 物体检测新框架,名为 MonoGAE。具体来说,由于路边场景中摄像头的固定安装,地平面是一个稳定且强的先验知识。为了减少地面几何信息和高维图像特征之间的域差距,我们采用带有地平面的监督训练范例来预测高维地面感知嵌入。这些嵌入随后通过交叉注意机制与图像特征集成。此外,为了提高探测器对摄像机安装姿势差异的鲁棒性,我们用一种新颖的像素级精化地平面方程图替换了地平面深度图。在广泛认可的路边摄像头 3D 检测基准上,我们的方法比所有以前的单目 3D 物体检测器表现出显着的性能优势。 |
| InstructCV: Instruction-Tuned Text-to-Image Diffusion Models as Vision Generalists Authors Yulu Gan, Sungwoo Park, Alexander Schubert, Anthony Philippakis, Ahmed M. Alaa 生成扩散模型的最新进展使得文本控制的合成具有令人印象深刻的质量的逼真和多样化的图像成为可能。尽管取得了这些显着的进步,但在计算机视觉中用于标准视觉识别任务的文本到图像生成模型的应用仍然有限。当前处理这些任务的实际方法是设计适合手头任务的模型架构和损失函数。在本文中,我们为计算机视觉任务开发了一个统一的语言界面,该界面抽象了任务特定的设计选择,并通过遵循自然语言指令来实现任务执行。我们的方法涉及将多个计算机视觉任务转换为文本到图像生成问题。这里,文本表示描述任务的指令,而生成的图像是视觉编码的任务输出。为了训练我们的模型,我们汇集了涵盖一系列任务的常用计算机视觉数据集,包括分割、对象检测、深度估计和分类。然后,我们使用大型语言模型来解释提示模板,这些模板传达要在每个图像上执行的特定任务,并通过此过程,我们创建一个包含输入和输出图像以及带注释指令的多模式和多任务训练数据集。遵循 InstructPix2Pix 架构,我们使用构建的数据集对文本到图像扩散模型进行指令调整,将其功能从生成模型转向指令引导的多任务视觉学习器。实验表明,我们的模型(称为 InstructCV)与其他通用视觉模型和任务特定视觉模型相比,具有竞争力。 |
| Deep Active Learning with Noisy Oracle in Object Detection Authors Marius Schubert, Tobias Riedlinger, Karsten Kahl, Matthias Rottmann 为复杂的计算机视觉任务(例如对象检测)获取注释是一项昂贵且耗时的工作,涉及大量人类工作人员或专家意见。因此,在保持算法性能的同时减少所需的注释量是机器学习从业者所期望的,并且已经通过主动学习算法成功实现了这一点。然而,影响模型性能的不仅仅是注释的数量,还有注释的质量。在实践中,查询新注释的预言机经常包含大量噪音。因此,通常需要清洁程序来检查和纠正给定的标签。此过程与初始注释本身的预算相同,因为它需要人类工作人员甚至领域专家。在这里,我们提出了一个复合主动学习框架,包括用于深度对象检测的标签审查模块。我们表明,利用部分注释预算来部分纠正活动数据集中的噪声注释可以导致模型性能的早期改进,特别是在与基于不确定性的查询策略结合使用时。标签错误建议的精确度对标签审核的测量效果有显着影响。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com