文章目录
- 操作mysql
- 客户端与 mysql 服务之间的小九九
- 了解 mysql
- 基本 SQL 语句
- 语法书写规范
- SQL分类
- DDL
- 库
- 表
- 查
- 增
- mysql数据类型
- 数值类型
- 字符类型
- 日期类型
- 示例
- 修改(表操作)
- DML
- 添加数据
- 删除数据
- 修改数据
- DQL
- 查询多个字段
- 条件查询
- 聚合函数
- 分组查询
- 排序查询
- 分页查询
- DQL语句的执行顺序
- DCL
- 用户权限
- 权限控制分配
- 函数
- 常用字符串函数
- 练习
- 常见数值函数
- 练习
- 常见日期函数
- 练习
- 流程函数
- 练习
操作mysql
下载mysql我就不写文章了,怎么卸载倒是有一篇(在我的博客中)
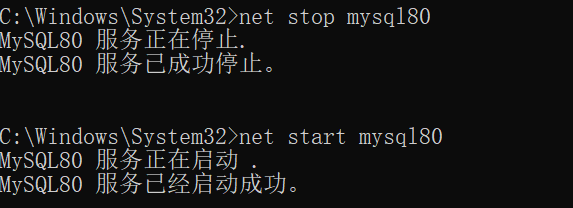
下载完成mysql之后我们可以通过管理员的身份来运行cmd命令窗口,我们可以通过以下两条命令来启动 mysql 或者停止 mysql 服务
# net stop mysql80 它的作用是停止 mysql 服务
# net start mysql80 它的作用是开启 mysql 服务
现在我们只是启动了 mysql ,他现在还没有和我们的客户端进行一个连接,我们现在需要让 mysql 连接到我们的客户端,有三种连接方式,新手推荐都练习一下,有益于理解mysql 与客户端之间的一些联系
- 首先我们可以通过
MySQL 8.0 Command Line Client这个软件来进行连接 - 我们可以通过命令行来跑 mysql连接服务 或者说连接 mysql ,如果是命令行就需要配置一下环境变量了,否则 window 无法寻找到 连接 mysql 的程序。
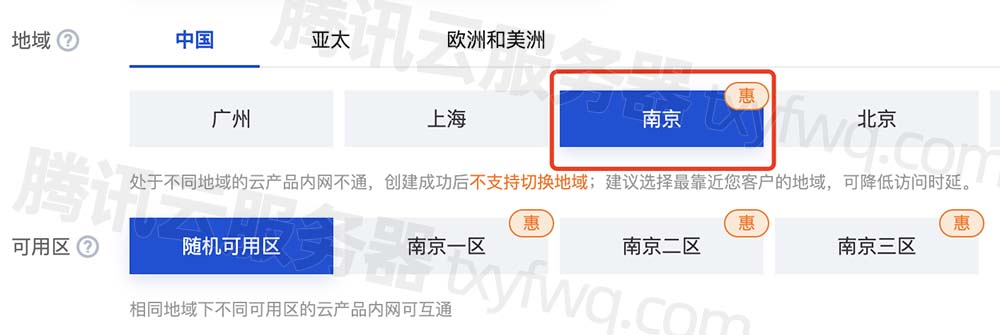
配置地址为:

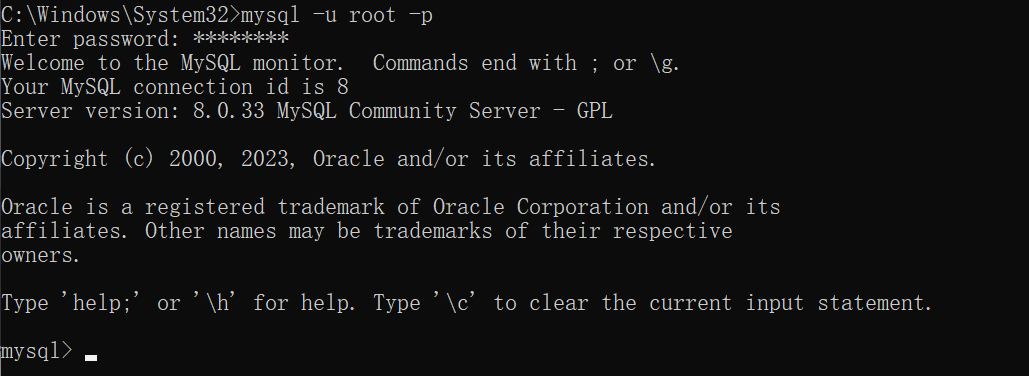
然后我们可以执行该命令来让客户端连接 mysql 服务:mysql [-h 127.0.1.1] [-p 3306] -u root -p
3. 我们还可以使用可视化管理工具进行连接,这个比较简单,就不进行截图演示了。
客户端与 mysql 服务之间的小九九
首先客户端会向 mysql 服务器发送 sql 语句,表面上是让 mysql 去执行语句做出操作,其实mysql内部是很奇妙的,首先 mysql 接受到客户端传来的 sql 语句会直接给到内部的 DBMS 数据库管理系统,它是会去操作以及维护数据库的,它可操作以及维护多个数据库 ,每个数据库可包含多个表,每个表可包含多个字段。
了解 mysql
mysql 数据库是一种关系型数据库,所谓关系型数据库也就是通过表结构来存储数据的数据库,反之则为非关系型数据库,例如 mongodb 就是一种非关系型数据库(NoSQL)
官方的解释是:关系型数据库是建立在关系模型基础上,有多张互相连接的二维表组成的数据库。
关系型数据库格式统一,方便维护;同时 SQL语言标准统一,使用方便。这便是它的优点。
基本 SQL 语句
语法书写规范
- 首先 mysql 语句单行多行书写都可以,但是该语句结束时必须使用分号结尾
; - 可使用空格或缩进来增强可读性
- 不区分大小写,只是关键字建议大写,这是比较规范的
- 单行注释
-- 注释内容,# 注释内容 - 多行注释
/* 注释内容 */
SQL分类
- DDL(Data Definition Language): 数据定义语言,用来定义数据库对象(数据库,表,字段)
- DML(Data Manipulation Language): 数据操作语言,用来对数据表中的数据进行增删改
- DQL(Data Query Language): 数据查询语言,用来查询数据库中表的记录
- DCL(Data Control Language): 数据控制语言,用来创建数据库用户、控制数据库的访问权限
DDL
库
- 查询
- 查询所有数据库:
SHOW DATABASES; - 查询当前数据库:
SELECT DATABASE();
- 创建
CREATE DATABASE [ IF NOT EXISTS ] 数据库名称 [DEFAULT CHARSET 字符集] [COLLATE 排序规则];
- 删除
DROP DATABASE [ IF EXISTS] 数据库名称;
- 使用某数据库
USE 数据库名称;
表
查
- 查询当前数据库所有表
SHOW TABLES;
- 查询表结构
DESC 表名;
- 查询指定表的建表语句
SHOW CREATE TABLE 表名;
增
CREATE TABLE 表名称(字段1 数据类型[ COMMENT 字段1注释],字段1 数据类型[ COMMENT 字段1注释],字段1 数据类型[ COMMENT 字段1注释],字段1 数据类型[ COMMENT 字段1注释]) [COMMENT 表注释];
最后一个字段后面不加逗号
mysql数据类型
数值类型
- TINYINT(小整数值) : 占用一个字节;有符号范围时(-128,127);无符号范围时(0,255)
- SMALLINF(大整数值) : 占用两个字节;有符号范围时(-32768,32767);无符号范围时(0,65535)
- MEDIUMINF(大整数值) : 占用三个字节;有符号范围时(-8388608,8388607);无符号范围时(0,16777215)
- INF / INFEGER(大整数值) : 占用四个字节;有符号范围时(-2147483648,217483647);无符号范围时(0,4294967295)
- BIGINT(极大整数值) : 占用八个字节;有符号范围时(-2 ^ 63,2 ^ 63 - 1);无符号范围时(0,2 ^ 64 - 1)
- FLOAT(单精度浮点数值) : 占用四个字节
- DOUBLE(双精度浮点数值) : 占用八个字节
- DECIMAL(小数值【精确定点数】)
有符号标识:SIGNED;无符号标识:UNSIGNED
当我们对分数或者年龄等做记录的时候就不需要用到有符号的负数了,我们可以这样写: age TINYINT UNSIGNED
对于浮点数我们可以这样限定它的范围:score double(限制位数,小数位数)
字符类型
字符类型有很多,我就列出一下,不会全部介绍,因为常用到的也就是 char、以及 varchar
- char: 0-255 bytes 定长字符串
- varchar:0-65535 bytes 变长字符串
定长意思就是已经开辟了这么大的空间,无论在实际操作中是存多少字符,它也是这么长的,有一点浪费空间的意思
而变长则是需要判断实际字符长度在分配空间
各有各的长处,变长性能比较差,但却不浪费空间,char浪费空间却性能胜与 varchar。
- TINYBLOB:不超过255个字符的二进制数据
- TINYTEXT:短文本字符串
- BLOB:二进制形式的长文本数据
- TEXT:长文本数据
- MEDIUMBLOB:二进制形式的中等长度文本数据
- MEDIUMTEXT:中等长度文本数据
- LONGBOLB:二进制格式极大文本数据
LONGTEXT:超大文本数据
日期类型
- DATE: YYYY-MM-DD (日期)
- TIME: HH:MM:SS (时间)
- YEAR: YYYY (年)
- DATETIME: YYYY-MM-DD HH:MM:SS (混合日期)
- TIMESTAMP: YYYY-MM-DD HH:MM:SS (混合日期【时间戳】)
示例
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| carbon |
| examination_pro |
| information_schema |
| mysql |
| performance_schema |
| sys |
| testdb |
+--------------------+
7 rows in set (0.00 sec)mysql> use testdb;
Database changed
mysql> select database();
+------------+
| database() |
+------------+
| testdb |
+------------+
1 row in set (0.00 sec)mysql> show tables;
+------------------+
| Tables_in_testdb |
+------------------+
| user |
+------------------+
1 row in set (0.02 sec)mysql> desc user;
+-----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+-------+
| name | varchar(10) | YES | | NULL | |
| workno | varchar(10) | YES | | NULL | |
| id | int | YES | | NULL | |
| gender | char(1) | YES | | NULL | |
| idcard | char(18) | YES | | NULL | |
| entrydate | date | YES | | NULL | |
+-----------+-------------+------+-----+---------+-------+
6 rows in set (0.01 sec)mysql> show create table user;
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table|
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| user | CREATE TABLE `user` (`name` varchar(10) DEFAULT NULL COMMENT '用户名称',`workno` varchar(10) DEFAULT NULL COMMENT '工号',`id` int DEFAULT NULL COMMENT '编号',`gender` char(1) DEFAULT NULL COMMENT '性别',`idcard` char(18) DEFAULT NULL COMMENT '身份证号',`entrydate` date DEFAULT NULL COMMENT '入职时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='员工表' |
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)mysql>
修改(表操作)
-
添加字段
ALTER TABLE 表名 ADD 字段名 类型(长度)[COMMENT 注释] [约束]; -
修改字段
- 修改数据类型
ALTER TABLE 表名 MODIFY 字段名 新的数据类型(长度); - 修改字段名称和字段类型
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束];
- 删除字段
ALTER TABLE 表名 DROP 字段名;
- 修改表名称
ALTER TABLE 表名 RENAME TO 新表名;
- 删除表
- 删除表
DROP TABLE [ IF EXISTS ] 表名; - 删除指定表,并且重新创建该表
TRUNCATE TABLE 表名;
DML
添加数据
-
给指定字段添加数据
INSERT INTO 表名 (字段名1,字段名2,...) VALUES(值1,值2,...); -
给全部字段添加数据
INSERT INTO 表名 VALUES(值1,值2,...); -
批量添加数据
INSERT INTO 表名 (字段名1,字段名2,...) VALUES(值1,值2,...),(值1,值2,...),(值1,值2,...);
INSERT INTO 表名 VALUES(值1,值2,...),(值1,值2,...),(值1,值2,...);
删除数据
DELETE FROM 表名 [WHERE 条件] ;
修改数据
UPDATE 表名 SET 字段名1 = '修改之后的值1',字段名2 = '修改之后的值2,... [WHERE 条件];'
DQL
查询多个字段
-
查询
SELECT 字段名1,字段名2,字段名3,... FROM 表名;
SELECT * FROM 表名; -
别名
SELECT 字段1 [ AS 别名1 ],字段2 [ AS 别名2 ],字段3 [ AS 别名3 ],... FROM 表名; -
去除重复记录
SELECT DISTINCT 字段列表 FROM 表名;
条件查询
SELECT 字段列表 FROM 表名 WHERE 条件列表;
- 条件:
– <
– >
– >=
– <=
– =
– <> 或者 != 【表示不等于】
– BETWEEN…AND… 【再某个范围之内(包含最大值以及最小值)】
– IN 【在in之后的列表中的值,多选一】
– LIKE 占位符 【模糊查询 _匹配单个字符,%匹配多个字符】
– IS NULL 【是NULL】
– IS NOT NULL 【不为NULL】
– AND 或者 && 【并且】
– OR 或者 || 【或】
– NOT 或者 ! 【非,不是】
聚合函数
SELECT 聚合函数(字段列表) FROM 表名;
聚合函数:
- count :统计数量
- max : 最大值
- min:最小值
- avg:平均值
- sum:求和
null值不参与聚合运算
分组查询
SELECT 字段列表 FROM 表名 [ WHERE 条件] GROUP BY 分组字段名 [ HAVING 分组后过滤条件 ];
都是过滤条件 where 和 having 的区别在哪里呢?
- 执行的时机不同:where 是在分组之前进行过滤,不满足 where 中的条件的话,不参与分组;而 having 是在分组之后进行过滤的
- 判断条件不同:where 不能对聚合函数进行判断,having 可以对聚合函数进行判断
排序查询
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1,字段2 排序方式2;
排序方式包含:
- ASC (升序)
- DESC (降序)
分页查询
SELECT 字段列表 FROM 表名 LIMIT 起始索引,每页查询条数;
DQL语句的执行顺序
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
- ORDER BY
- LIMIT
DCL
用户权限
- 查询用户
USE mysql;
SELECT * FROM user;
- 创建用户
CREATE USER '用户名'@'主机名' IDENTIFIEN BY '密码'; - 修改用户密码
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';
- 删除用户
DROP USER'用户名'@'主机名';
主机名如果为local host 那么该数据库只能在当前主机访问,也就是当前操作电脑上可以访问;如果主机名命名为 % 那么表示该数据库可以在任意主机上访问
权限控制分配
当我们有了多个用户权限,自然要给不同的用户分配不同的权限,而所分配的权限也就是该用户可执行的操作,例如查询、插入、修改、删除(库 / 表),简称CRUD。
如果要给予所有权限,那么可使用 ALL 或者 ALL PRIVILEGES
- 查询权限
SHOW GRANTS FOR '用户名'@'主机名'; - 授予权限
CRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名'; - 撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';
如果要操作该数据库的所有表的权限,那么我们可以将表名写做:*来表示通配该数据库所有表
同样的所有数据库也可以表示为 *
函数
常用字符串函数
- 字符串的拼接,将多个字符串拼接为一个字符串
CONCAT(STR1,STR2,STR3...)
- 字符串全部转小写
LOWER(str)
- 字符串全部转大写
UPPER(str)
- 左填充,用字符串pad对str左边进行填充,达到n个字符长度
LPAD(str,n,pad)
- 右填充,用字符串pad对str右边进行填充,达到n个字符长度
RPAD(str,n,pad)
- 去掉字符串左右两边的空格
TRIM(str)
- 返回字符串 str 从 start 位置起的 len 个长度的字符串
SUBSTRING(str,start,len)
练习
SELECT CONCAT('Hello ',' MySQL') AS '字符串拼接';SELECT LOWER(CONCAT('Hello',' MySQL')) AS '字符串转小写';SELECT UPPER(CONCAT('Hello',' MySQL')) AS '字符串转大写';SELECT LPAD(UPPER(CONCAT('Hello',' MySQL')),18,'_') AS '左填充字符串';SELECT RPAD(UPPER(CONCAT('Hello',' MySQL')),18,'_') AS '右填充字符串';SELECT TRIM(CONCAT(' Hello ',' MySQL ')) AS '字符串去除两边空格';SELECT SUBSTRING(RPAD(UPPER(CONCAT('Hello',' MySQL')),18,'_'),5,3) AS '字符串截取';
# 这里需要注意索引值从1开始
常见数值函数
- 向上取整
CEIL(x)
- 向下取整
FLOOR(x)
- 返回 x / y 的模
MOD(x,y)
- 返回 0~1内的随机数
RAND()
- 求参数 x 的四舍五入的值,保留 y 位小数
ROUND(x,y)
练习
SELECT CEIL(200.1) AS '向上取整';
SELECT FLOOR(200.9) AS '向下取整';
SELECT MOD(12,7) AS '求模';
SELECT RAND() AS '随机数';
SELECT ROUND(RAND() * 200,3) AS '四舍五入';
常见日期函数
- 返回当前日期
CURDATE()
- 返回当前时间
CURTIME()
- 返回当前日期和时间
NOW()
- 获取指定的date年份
YEAR(date)
- 获取指定的date月份
MONTH(date)
- 获取指定的date日期
DAY(data)
- 返回一个日期/时间值加上一个时间间隔expr后的时间值
DATE_ADD(date,INTERVAL expr type)
- 返回起始时间date1和结束时间date2之间的天数
DATEDIFF(date1,date2)
练习
SELECT CURDATE() AS '当前日期';
SELECT CURTIME() AS '当前时间';
SELECT NOW() AS '当前日期和时间';SELECT YEAR('1999-01-06') AS '指定日期年份';SELECT MONTH('1999-01-06') AS '指定日期月份';SELECT DAY('1999-01-06') AS '指定日期';SELECT DATE_ADD('1989-01-01',INTERVAL 70 MONTH) AS '时间推进';SELECT DATE_ADD('1989-01-01',INTERVAL -70 DAY) AS '时间推进';SELECT DATEDIFF('2023-10-2','2001-10-19') AS '间隔天数';
流程函数
- 如果 value 为 true,返回第一个值,否则返回第二个值
IF(value,x,y)
- 如果 value 不为空,返回第一个值,否则返回第二个值
IFNULL(value1,value2)
- 如果 value1 为 true,返回res1,否则返回default默认值
CASE WHEN [value1] THEN [res1] ...ELSE[default] END
- 如果 value1 的值等于 val1,返回res1,否则返回default默认值
CASE [value1] WHEN [val] THEN [res1] ...ELSE[default] END
练习
SELECT IF((CEIL(RAND() * 10) + 1 = 8),1,0) AS '判断';SELECT IFNULL((SELECT workno FROM emp WHERE username = '王小二'),'为空') AS '判断NULL';SELECT username,(CASE age WHEN 23 THEN '符合23岁的标准' WHEN 24 THEN '勉强接受' ELSE '不符合标准' END) AS '标准' FROM emp;SELECT CASE WHEN ((SELECT age FROM emp WHERE username = '王小二') = 23) THEN '符合23岁的标准' ELSE '不符合标准' END AS '标准';