工作上主要还是以纯lidar的算法开发,部署以及系统架构设计为主。对于多模态融合(这里主要是只指Lidar和Camer的融合)这方面研究甚少。最近借助和朋友们讨论论文的契机接触了一下这方面的知识,起步是晚了一点,但好歹是开了个头。下面就借助TransFusion论文及其开源代码来串一串这方面的知识。TransFusion文中指出已经存在的Lidar-Camera的融合方法大致可以分为3类:
Result-Level:这个很好理解,参考FPointNet网络图示。就是利用现有的2D检测器在图像上提取2D初始框,根据Camera成像原理,捕获2D框视锥内的点云,再利用点云分类模型(如:PointNet)做进一步分类。

这个方法的好处是显然的,遥想作者当年发论文的时候,图像的2D检测相对已经成熟,但是点云3D检测才刚刚起步(好吧,其实也是该作者开创了点云深度学习处理的先河),以2D box作为Query应该说是一个很不错的思路。很多后续论文在谈论FPointNet时说该方法受限于图像2D检测模型。如果2D检测露检则3D部分也不可能恢复。

Proposal-Level:提到Proposal我们很容易想到faster-rcnn这种经典网络,它由第一阶段中的RPN提供候Proposal,第二阶段利用proposal以及RoiPooling(或者后续该进型的RoiAlign等)操作提取proposal region-wise features后再对box做一次精修。具体到多模态的Proposal-Level的融合,你可以想象为其中一个模态的模型作为第一阶段先提供Proposal,然后各个模态以这个Proposal为媒介进行特征融合等。MV3D算是这方面的开山之作,其BEV下的lidar检测模型先提供一下proposal,然后这个proposal分别映射到Lidar BEV view,Lidar Front view以及Image View 这3张特征图上去提取region-wise features进行融合。此时的融合已经是一种基于Proposal的特征级融合了。有了这个融合后的特征,自然就可以继续再接分类,回归等任务。

Point-Level:原始lidar点云通常包含3个维度的坐标(x,y,z)信息再加上1维强度信息。但是借助Lidar和Camera之间的标定关系,可以建立point到pixel的联系。Point-Level的融合就是借助了这类联系对lidar点云的特征进行扩充。扩充的特征有可能是point对应pixel的分割label,如大名鼎鼎的PointPainting,操作又简单,又通用,提点能力也杠杠的。
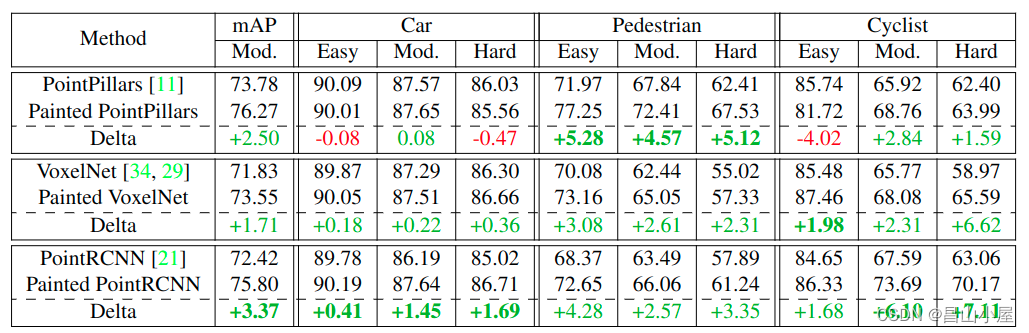
后来发展到既然你可以Painting分割的label,为什么我不可以Painting分割/检测的feature。既然你可以Painting某一层的feature,我为什么不可以painting multi-scale的feature等等。当然,还有更多的复杂一些的操作,涉及到不同view下的Painting,以及由点的Painting到voxel的Painting等等,但是总体思想不变。这种Point-Level的方法存在几个问题,一个就是对标定的准确性要求很高,因为就是点对点的。另外一个点云毕竟是稀疏的,如果只是利用了point2pixel部分的图像点的信息,则图像信息的利用是严重不充分的。毕竟你是需要额外整出一个模型来提取图像的分割label或者特征的,开销不小。此外,低质量图像带来的错误的分割label或者干扰性的特征反而会影响到点云的模型效果。说了这么多那TransFusion这篇论文有何特别之处,按作者原文的说法是"Our key idea is to reposition the focus of the fusion process,from hard-association to soft-association,leading to the robustness against degenerate image quality and sensor misalignment".字面意思就是TransFusion使用一种软关联机制(soft-association)取代以往融合方法中的硬关联机制,这样使得融合算法在图像质量退化和传感器没有严格对齐的情况下能更加鲁棒。至于这种软关联机制具体怎么实现,我觉得可以结合论文和代码先分析TransFusion-L这一纯Lidar的3D检测,再分析融合了图像后的完整的框架,可能会有更好的理解。
TransFusion-L
TransFusion多模态融合框架中纯lidar检测部分称其为TransFusion-L。从下表中可见,在nuScenes测试集上,单就纯Lidar的方法PK,TransFusion-L相比CenterPoint模型mAP和NDS都有大幅提升。

TransFusion-L的pipeline如下图所示,我从多模态pipeline中去掉了图像融合的元素。乍一看就是将CenterPoint的检测头换成了TransFormer的检测头,但是其中仍然有诸多创新之处。

他借鉴了最新的基于Transfomer的图像2D检测的方法,使用稀疏的object query通过transformer的方式来聚合特征并预测最终的目标。在object query的初始化上不仅作到了input-dependent,而且还具备category-aware。从论文后的对比实验来看这是2个极其重要的特性。表格中a)为完整的TransFusion-L,b)表示去掉了category-aware。mAP和NDS分别掉了5.7%和2.8%。d)表示去掉了input-dependent,e...这个结果就完全没法看了。即使通过增加Decoder Layers的层数来学习弥补也远落后于仅有一层Decode Layer的TransFusion-L。

那Input-Depentdent和Class-Aware分别又是什么呢?
Input-Dependent:
在DETR这一将Transformer用于目标检测的开山之作中首次引入了object queries的概念。

这些个object queries是可学习的embedding,从论文代码中可见query_embed初始是一个Shape为(num_queris, hidden_dim)的embedding,在模型训练过程中再不断迭代更新参数。

一旦模型训练完成query参数也就固定了,推理过程中与当前输入图像的内容并无关系,也就是不由当前图像内容计算得到。为什么这样的object query还能work呢?首先,上面也说了object query虽然是随机初始化,但是会随着网络训练而更新。不同object queries通过self-attention建模了patter与patter之间的关系,通过cross-attention又从transformer-encoder序列中对patter相关特征做了聚合。
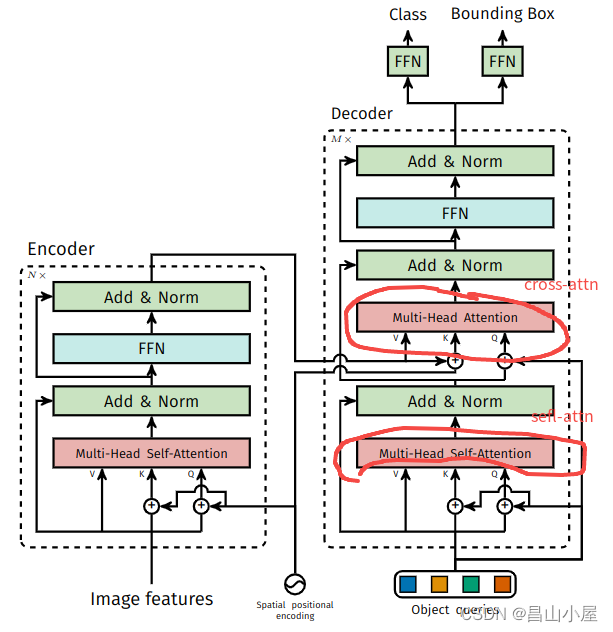
上面这种形式的object query称其为input-independent query。现在我们再来看TransFusion-L中的Input-Dependent的object query就好理解了,它再也不需要单独随机初始化一组object query embedding再通过训练网络来更新参数,而是直接使用LiDAR BEV Features来初始化。有个问题就是Lidar BEV Features是一个dense的feature map,而我们要选择的object query是稀疏的,最终哪些位置上的feature用来初始化query? 这个就交给heatmap来选择了。

这个操作很秀,通过heatmap筛选出热点,既保证了object query的稀疏性,同时又可以由热点位置的feature来进行初始化,同时热点的位置天然可以用于Position-Encoding(位置编码)加入到query中。输入图像的内容不同,得到的bev feature map不同,heatmap也不同,自然object query也不一样,所以就是Input-Dependent的了。通过这种方式初始化的query会更加贴近潜在目标的中心,而不需要像DETR那样通过multiple decoder layers堆叠来修正位置。
Class-Aware:heatmap中得到的热点除了位置和特征信息,同时还包含了分类信息。类似位置编码,对one-hot类别向量进行编码也加入到query特征中。加入了类别编码信息的query对self-attention阶段建模object-object之间的联系,以及cross-attention阶段建模object-context之间的联系大有裨益。
下面通过TransFusion检测头部分的代码对Input-Dependent和Class-Aware做进一步的理解。因为还是讨论TransFusion-L所以会先屏蔽图像融合部分的代码。
@HEADS.register_module()
class TransFusionHead(nn.Module):def __inti__(self,...):super(TransFusionHead,self).__init__()#......def forward_single(self, inputs, img_inputs, img_metas):#......def forward(self, feats, img_feats, img_metas):if img_feats is None:img_feats = [None]res = multi_apply(self.forward_single, feats, img_feats, [img_metas])assert len(res) == 1, "only support one level features."return res
TransFusion-L总的pipeline大该为Input-->预处理-->3D Backbone-->Height Compression-->2D Neck-->Head。为方便调试,假定batch为2,其它按默认配置设置则进入到head的feats维度为[2,512,128(H),128(W)]。其实在HeightCompression完成高度压缩以后就可以类似处理2D图像的feature map进行处理了。forward之后会立刻进入forward_single函数,也是整个head的核心。
源文件:mmdet3d/models/dense_heads/transfusion_head.py
1 def forward_single(self, inputs, img_inputs, img_metas): 2 """Forward function for CenterPoint.3 Args:4 inputs (torch.Tensor): Input feature map with the shape of5 [B, 512, 128(H), 128(W)]. (consistent with L748)6 7 Returns:8 list[dict]: Output results for tasks.9 """10 batch_size = inputs.shape[0]11 ##[2, 128, 128, 128])12 lidar_feat = self.shared_conv(inputs) ##3x3普通卷积13 14 #################################15 # 16 #################################17 lidar_feat_flatten = lidar_feat.view(batch_size, lidar_feat.shape[1], -1) # [BS, C, H*W]18 bev_pos = self.bev_pos.repeat(batch_size, 1, 1).to(lidar_feat.device) ##bev_pos只是网格坐标...19 20 if self.fuse_img:21 ##pass22 23 #################################24 # image guided query initialization25 #################################26 if self.initialize_by_heatmap:27 ##torch.Size([2, 10, 128, 128]) <==28 dense_heatmap = self.heatmap_head(lidar_feat)29 dense_heatmap_img = None30 if self.fuse_img:31 ###32 ###33 else:34 heatmap = dense_heatmap.detach().sigmoid()35 padding = self.nms_kernel_size // 236 local_max = torch.zeros_like(heatmap)37 # equals to nms radius = voxel_size * out_size_factor * kenel_size38 local_max_inner = F.max_pool2d(heatmap, kernel_size=self.nms_kernel_size, stride=1, padding=0)39 local_max[:, :, padding:(-padding), padding:(-padding)] = local_max_inner40 ## for Pedestrian & Traffic_cone in nuScenes41 if self.test_cfg['dataset'] == 'nuScenes':42 local_max[:, 8, ] = F.max_pool2d(heatmap[:, 8], kernel_size=1, stride=1, padding=0)43 local_max[:, 9, ] = F.max_pool2d(heatmap[:, 9], kernel_size=1, stride=1, padding=0)44 elif self.test_cfg['dataset'] == 'Waymo': # for Pedestrian & Cyclist in Waymo45 local_max[:, 1, ] = F.max_pool2d(heatmap[:, 1], kernel_size=1, stride=1, padding=0)46 local_max[:, 2, ] = F.max_pool2d(heatmap[:, 2], kernel_size=1, stride=1, padding=0)47 heatmap = heatmap * (heatmap == local_max)48 heatmap = heatmap.view(batch_size, heatmap.shape[1], -1)49 50 # top #num_proposals among all classes51 top_proposals = heatmap.view(batch_size, -1).argsort(dim=-1, descending=True)[..., :self.num_proposals]52 top_proposals_class = top_proposals // heatmap.shape[-1]53 54 top_proposals_index = top_proposals % heatmap.shape[-1]55 query_feat = lidar_feat_flatten.gather(index=top_proposals_index[:, None, :].expand(-1, lidar_feat_flatten.shape[1], -1), dim=-1)56 self.query_labels = top_proposals_class57 58 # add category embedding59 one_hot = F.one_hot(top_proposals_class, num_classes=self.num_classes).permute(0, 2, 1)60 query_cat_encoding = self.class_encoding(one_hot.float())61 query_feat += query_cat_encoding62 query_pos = bev_pos.gather(index=top_proposals_index[:, None, :].permute(0, 2, 1).expand(-1, -1, bev_pos.shape[-1]), dim=1)63 else:64 query_feat = self.query_feat.repeat(batch_size, 1, 1) # [BS, C, num_proposals]65 base_xyz = self.query_pos.repeat(batch_size, 1, 1).to(lidar_feat.device) # [BS, num_proposals, 2]66 67 #################################68 # transformer decoder layer (LiDAR feature as K,V)69 #################################70 ret_dicts = []71 for i in range(self.num_decoder_layers):72 prefix = 'last_' if (i == self.num_decoder_layers - 1) else f'{i}head_'73 74 # Transformer Decoder Layer75 # :param query: B C Pq :param query_pos: B Pq 3/676 query_feat = self.decoder[i](query_feat, lidar_feat_flatten, query_pos, bev_pos)77 78 # Prediction79 res_layer = self.prediction_heads[i](query_feat) ##FFN80 81 ##这个center是一个相对的偏移,所以要通过下面的方式计算出实际预测的center82 res_layer['center'] = res_layer['center'] + query_pos.permute(0, 2, 1)83 first_res_layer = res_layer84 if not self.fuse_img:85 ret_dicts.append(res_layer)86 87 # for next level positional embedding88 query_pos = res_layer['center'].detach().clone().permute(0, 2, 1)89 90 #################################91 # transformer decoder layer (img feature as K,V)92 #################################93 if self.fuse_img:94 pass95 96 if self.initialize_by_heatmap:97 ret_dicts[0]['query_heatmap_score'] = heatmap.gather(index=top_proposals_index[:, None, :].expand(-1, self.num_classes, -1), dim=-1) # [bs, num_classes, num_proposals]98 if self.fuse_img:99 ret_dicts[0]['dense_heatmap'] = dense_heatmap_img
100 else:
101 ret_dicts[0]['dense_heatmap'] = dense_heatmap
102
103 if self.auxiliary is False:
104 # only return the results of last decoder layer
105 return [ret_dicts[-1]]
106
107 # return all the layer's results for auxiliary superivison
108 new_res = {}
109 for key in ret_dicts[0].keys():
110 if key not in ['dense_heatmap', 'dense_heatmap_old', 'query_heatmap_score']:
111 new_res[key] = torch.cat([ret_dict[key] for ret_dict in ret_dicts], dim=-1)
112 else:
113 new_res[key] = ret_dicts[0][key]
114 return [new_res]
第12行,通过一个普通的3x3卷积将输入通道数从512压缩到128;
第18行,将self.bev_pos也就是bev下的feature map网格坐标复制batch份。self.bev_pos在初始__init__函数中通过create_2D_grid函数创建。create_2D_grid顾名思义就是创建2D的网格,他会返回一整张网格map的中心点坐标。
def create_2D_grid(x_size, y_size):meshgrid = [[0, x_size - 1, x_size], [0, y_size - 1, y_size]]batch_y, batch_x = torch.meshgrid(*[torch.linspace(it[0], it[1], it[2]) for it in meshgrid])batch_x = batch_x + 0.5batch_y = batch_y + 0.5coord_base = torch.cat([batch_x[None], batch_y[None]], dim=0)[None]coord_base = coord_base.view(1, 2, -1).permute(0, 2, 1)return coord_baseif __name__ == "__main__":x_size = 128y_size = 128coord_base = create_2D_grid(x_size,y_size)print('x_size:{},y_size:{}'.format(x_size,y_size))print('coord_base shape:', coord_base.shape)print('coord_base:', coord_base)运行:
x_size:128,y_size:128
coord_base shape: torch.Size([1, 16384, 2])
coord_base: tensor([[[ 0.5000, 0.5000],[ 1.5000, 0.5000],[ 2.5000, 0.5000],...,[125.5000, 127.5000],[126.5000, 127.5000],[127.5000, 127.5000]]])第26行,进入heatmap初始化逻辑中;
第28行,输入lidar bev特征图(2,128,128,128)通过若干卷积操作生成热力图(2,10,128,128)。我们以nuScenes数据集为例,10为类别数量;
第38行,使用torch function自带的max_pool2d函数,结合kernel_size(self.nms_kernel_size默认为3)等参数取heatmap局部邻域(kernel)内的最大之值;
第39行,因为heatmap做max_pool2d的时候padding为0,所以得到的local_max_inner的shape减了2,所以往local_max里面做填充的时候需要H,W维度需要给一个padding:(-padding)的范围;
第47行,经过该操作邻域内不是最热的地方就被置为0了;
第50行,通过对热度其实就是类别score由高到低排序,取出前self.num_proposals(默认200)的索引位置,保存到top_proposals中;
第51-52行,分别计算出top_proposal代表的类别和所在通道内的索引;
第55行,借助上一步计算得到的热点top_proposals_index从lidar_feat_flatten中收集特征,这些收集到的特征用于初始化object query。当然,在此基础上还会再sum上类别编码和位置编码特征;
第59-60行,就是完成object query的"class-aware"特性最重要的两步,将top_proposals_class的类别id做one-hot,并进行类别编码。所谓的self.class_encoding也就是一个一维的卷积;
第71-88行,这个就是经典的transformer decoder + ffn操作了。因为有了input-dependent和class-aware两大法宝的加持,decoder的层数(self.num_decoder_layers)可以直接缩减到一层了;
至此,TransFusion-L的核心部分就完成了,相比他的图像融合部分还是好理解的。我在浏览其它相关文章的时候也注意到图森有一篇思想比较相近的文章CenterFormer。
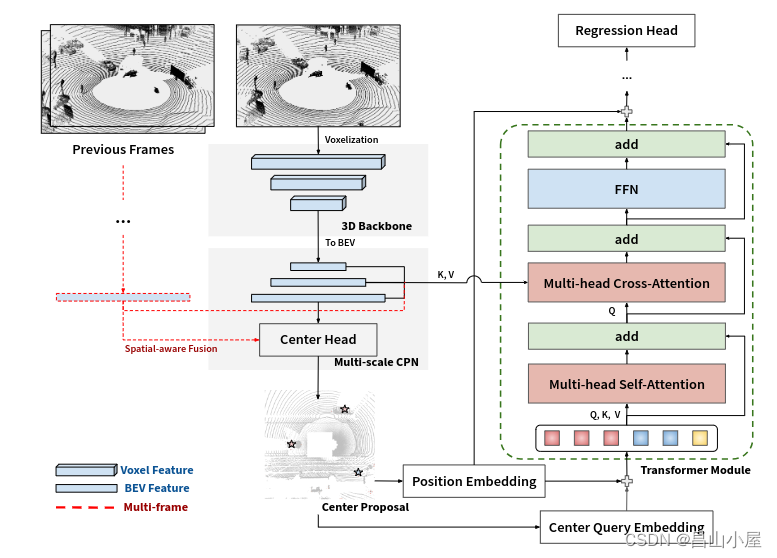
不考虑他mutli-frame的部分的话,主要是加入了一个multi-scale的概念。其实就是对2d neck网络部分以及K,V的选取方式做了调整。因为2d neck部分是一个multi scale的网络,object query就可以从不同scale的feature map上聚合K,V效果又可以有提升。


![[React源码解析] React的设计理念和源码架构 (一)](https://img-blog.csdnimg.cn/75242141fe5646f2a123486823875d6a.png)