文章目录
- NoSql概述
- NoSql年代
- 缓存 Memcached + MySQL+垂直拆分(读写分离)
- 分库分表+水平拆分+Mysql集群
- 最近
- 为什么要用
- NoSql
- NoSql的四大分类
- Redis
- 测试性能
- 五大数据类型
- key
- String
- Set
- Hash
- Zset
前言:本文为看狂神视频记录的笔记
NoSql概述
NoSql年代

问题:数据量过大、数据索引过大(B+Tree),机器内存不够、访问量(读写混合),服务器承受不了
缓存 Memcached + MySQL+垂直拆分(读写分离)
网站80%的情况下在读取,用MySQL太过繁琐;希望减轻数据库的压力,可以使用缓存保证效率
发展过程:优化数据结构和索引->文件缓存(IO)->Memcached(当时最热门技术)
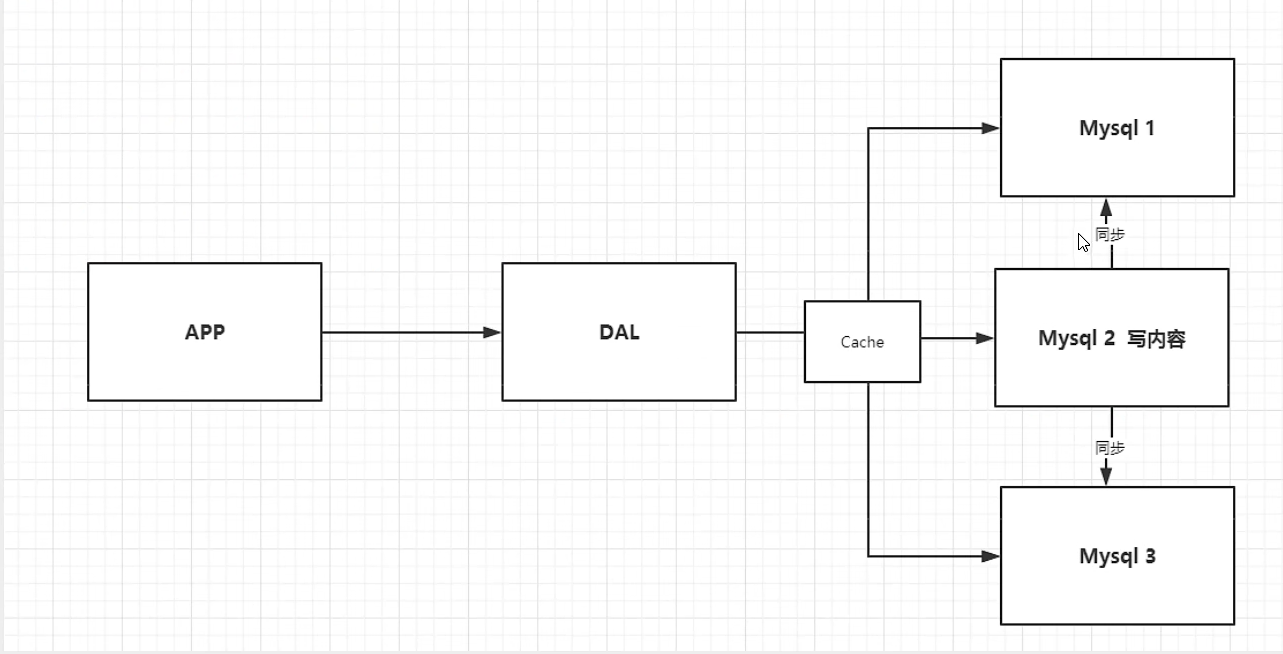
分库分表+水平拆分+Mysql集群
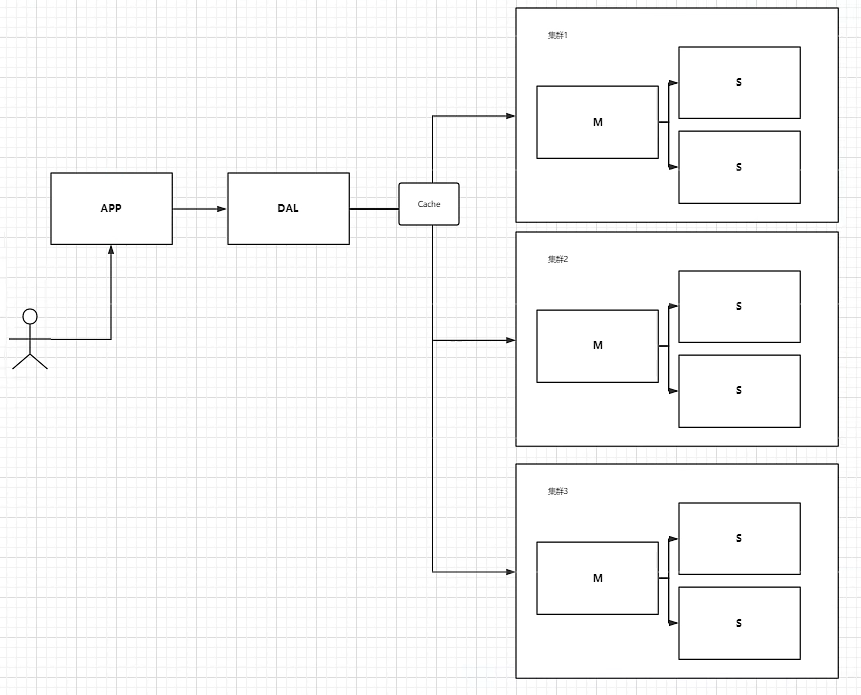
本质:数据库的读和写
早些年MyISAM:表锁,(读写时,所在的表被锁,十分影响并发性)
Innodb:行锁
最近
MySQL关系型数据库不够用,数据多且变化快
用:图型;JSON
MySQL有的使用他来存储较大文件,数据库很大,效率变低,如果有专门数据库负责,压力就会变小
目前一个基本的互联网项目
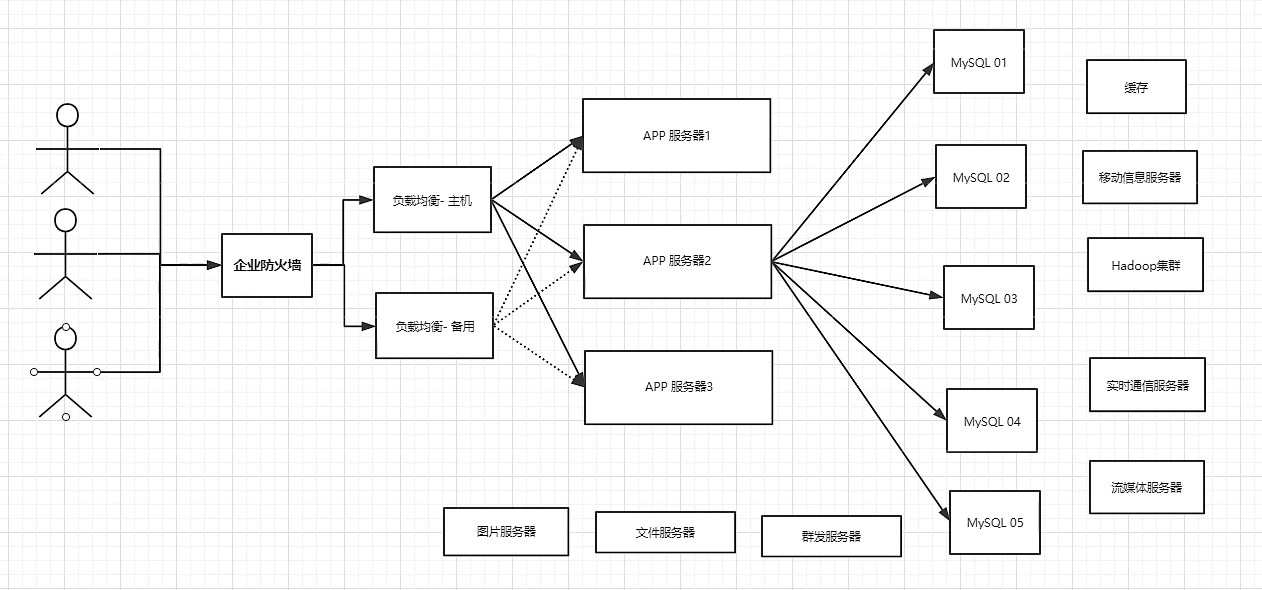
为什么要用
用户的个人信息、地理位置,用户自己产生的数据、用户日志爆炸式增长,nosql能很好的处理以上问题
NoSql
NoSql = Not Only Sql(不仅仅是Sql)
关系型数据库:表格,行,列
泛指非关系型数据库,传统关系型数据库很难对付web2.0时代,尤其是超大规模的高并发的社区。NoSql在当今大数据环境下发展十分迅速,Redis是发展最快的,而且是我们当下必须要掌握的一个技术!
很多的数据类型用户的个人信息,社交网络,地理位置。这些数据类型存储不需要一个固定的格式,不需要多余的操作就可以横向扩展!使用键值对来存放。
NoSql特点—解耦
1、方便扩展(数据之间没有关系,很好扩展)
2、大数据量高性能(NoSql的缓存记录级,是一种细粒度的缓存,性能会比较高,redis一秒写8万次读11万次)
3、数据类型是多样型(不需要设计数据库,随取随用)
4、传统的RDBMS和NoSql
传统的 RDBMS(关系型数据库)
- 结构化组织
- SQL
- 数据和关系都存在单独的表中
- 操作语言,定义语言
- 严格的一致性
- …
Nosql
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储,文档存储,图形数据库(社交关系)
- 最终一致性
- CAP定理和BASE (异地多活)
- 高性能,高可用,高可扩
- …
了解:3V+3高
- 大数据时代的3V:主要是描述问题的
1、海量Volume
2、多样Variety
3、实时Velocity
- 互联网需求的3高:主要是对程序的要求
1、高并发(Java JUC)
2、高可拓(随时水平拆分,机器不够了,扩展机器来解决)
3、高性能(保证用户体验和性能)
NoSql+RDBMS->《阿里巴巴的架构演进》
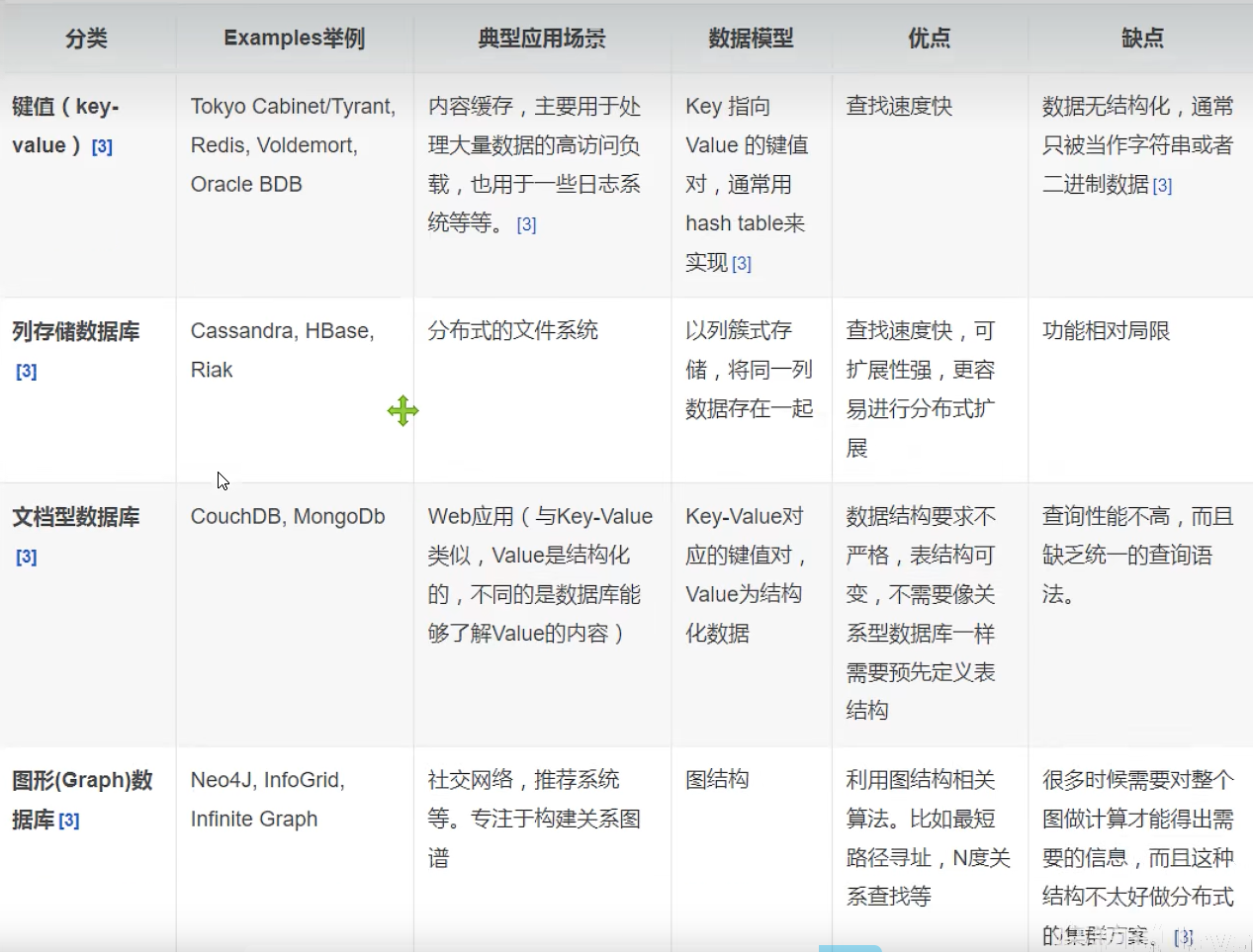
NoSql的四大分类
KV键值对
- 新浪:Redis
- 美团:Redis+Tair
- 阿里、百度:Redis+MemCache
文档型数据库:(bson格式和json一样)
- MongoDB
- mongodb基于分布式文件存储的数据库,C++编写,主要用来处理大量的文档
- MongoDB是一个介于关系型数据库和非关系型数据库中间的产品,MongoDB是非关系型数据库中功能最丰富,最想关系型数据库的。
- ConthDB
列存储数据库
- HBase
- 分布式文件系统
图关系数据库
不是存图形,放的是关系,比如朋友圈社交网络
- neo4j
- InfoGrid
- redisgraph
Redis
Redis是什么?
Redis(RemoteDictionaryServe),即远程字典服务
Redis能干嘛?
1、内存存储,持久化,内存中是断电即失,所以说持久化很重要(rdb、aof)
2、效率高,可以用于高速缓存
3、发布订阅系统
4、地图信息分析
5、计时器、计数器(浏览量! )
特性
1、多样的数据类型
2、持久化
3、集群
4、事物
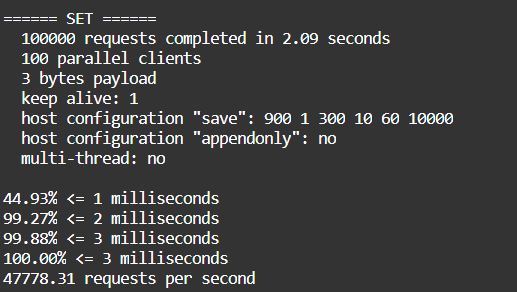
测试性能
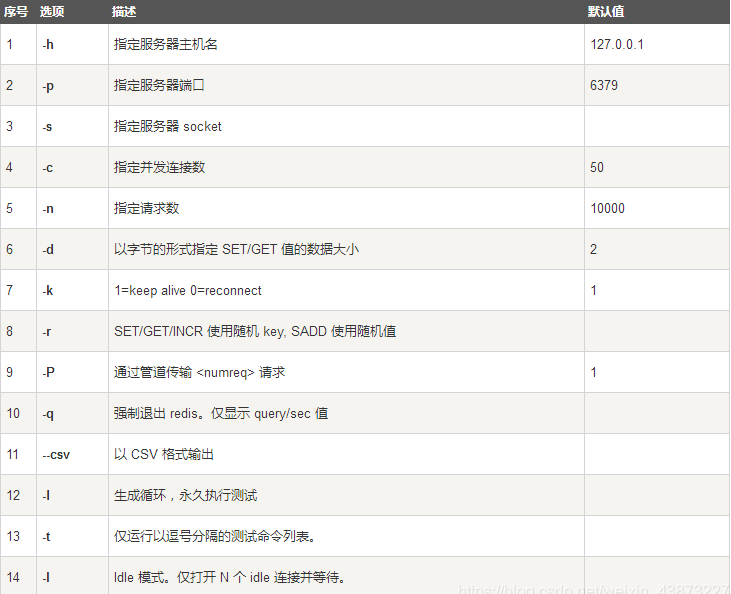
简单测试
# 测试:100个并发连接 100000请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
测试图
redis默认有16个数据库,默认使用第0个
127.0.0.1:6379> config get databases # 命令行查看数据库数量databases
1) "databases"
2) "16"127.0.0.1:6379> select 8 # 切换数据库 DB 8
OK
127.0.0.1:6379[8]> dbsize # 查看数据库大小
(integer) 0# 不同数据库之间 数据是不能互通的,并且dbsize 是根据库中key的个数。
127.0.0.1:6379> set name sakura
OK
127.0.0.1:6379> SELECT 8
OK
127.0.0.1:6379[8]> get name # db8中并不能获取db0中的键值对。
(nil)
127.0.0.1:6379[8]> DBSIZE
(integer) 0
127.0.0.1:6379[8]> SELECT 0
OK
127.0.0.1:6379> keys *
1) "counter:__rand_int__"
2) "mylist"
3) "name"
4) "key:__rand_int__"
5) "myset:__rand_int__"
127.0.0.1:6379> DBSIZE # size和key个数相关
(integer) 5keys * :查看当前数据库中所有的key。
flushdb:清空当前数据库中的键值对。
flushall:清空所有数据库的键值对。
Redis是单线程的,Redis是基于内存操作的。所以Redis的性能瓶颈不是CPU,而是机器内存和网络带宽。
那么为什么Redis的速度如此快呢,性能这么高呢?QPS达到10W+
Redis为什么单线程还这么快?
误区1:高性能的服务器一定是多线程的?
误区2:多线程(CPU上下文会切换!)一定比单线程效率高!
核心:Redis是将所有的数据放在内存中的,所以说使用单线程去操作效率就是最高的,多线程(CPU上下文会切换:耗时的操作!),对于内存系统来说,如果没有上下文切换效率就是最高的,多次读写都是在一个CPU上的,在内存存储数据情况下,单线程就是最佳的方案。
五大数据类型
Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。
key
在redis中无论什么数据类型,在数据库中都是以key-value形式保存,通过进行对Redis-key的操作,来完成对数据库中数据的操作。
exists key:判断键是否存在
del key:删除键值对
move key db:将键值对移动到指定数据库
expire key second:设置键值对的过期时间
type key:查看value的数据类型
127.0.0.1:6379> keys * # 查看当前数据库所有key
(empty list or set)
127.0.0.1:6379> set name qinjiang # set key
OK
127.0.0.1:6379> set age 20
OK
127.0.0.1:6379> keys *
1) "age"
2) "name"
127.0.0.1:6379> move age 1 # 将键值对移动到指定数据库
(integer) 1
127.0.0.1:6379> EXISTS age # 判断键是否存在
(integer) 0 # 不存在
127.0.0.1:6379> EXISTS name
(integer) 1 # 存在
127.0.0.1:6379> SELECT 1
OK
127.0.0.1:6379[1]> keys *
1) "age"
127.0.0.1:6379[1]> del age # 删除键值对
(integer) 1 # 删除个数127.0.0.1:6379> set age 20
OK
127.0.0.1:6379> EXPIRE age 15 # 设置键值对的过期时间(integer) 1 # 设置成功 开始计数
127.0.0.1:6379> ttl age # 查看key的过期剩余时间
(integer) 13
127.0.0.1:6379> ttl age
(integer) 11
127.0.0.1:6379> ttl age
(integer) 9
127.0.0.1:6379> ttl age
(integer) -2 # -2 表示key过期,-1表示key未设置过期时间127.0.0.1:6379> get age # 过期的key 会被自动delete
(nil)
127.0.0.1:6379> keys *
1) "name"127.0.0.1:6379> type name # 查看value的数据类型
string
关于TTL命令
Redis的key,通过TTL命令返回key的过期时间,一般来说有3种:
当前key没有设置过期时间,所以会返回-1.
当前key有设置过期时间,而且key已经过期,所以会返回-2.
当前key有设置过期时间,且key还没有过期,故会返回key的正常剩余时间.
关于重命名RENAME和RENAMENX
RENAME key newkey修改 key 的名称
RENAMENX key newkey仅当 newkey 不存在时,将 key 改名为 newkey 。
更多命令学习:https://www.redis.net.cn/order/
String
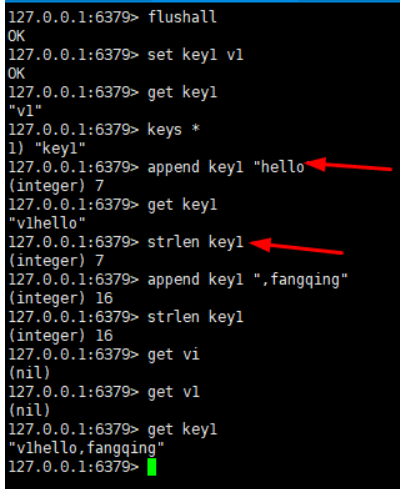
127.0.0.1:6379> set views 0 #初始浏览量为0
OK
127.0.0.1:6379> get views
"0"
127.0.0.1:6379> incr views #自增1,浏览量变为1
(integer) 1
127.0.0.1:6379> incr views
(integer) 2
127.0.0.1:6379> get views
"2"
127.0.0.1:6379> decr views #自减1
(integer) 1
127.0.0.1:6379> incrby views 10 #自增10
(integer) 11
127.0.0.1:6379> incrby views 10
(integer) 21
127.0.0.1:6379> decrby views 5 #自减5
(integer) 16
截取字符串getrange
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> set key1 "fang"
OK
127.0.0.1:6379> get key1
"fang"
127.0.0.1:6379> getrange key1 0 2 #截取012字符串
"fan"
127.0.0.1:6379> getrange key1 0 -1 #获取全部字符串
"fang"
127.0.0.1:6379>
替换setrange
127.0.0.1:6379> set key2 abcdefg
OK
127.0.0.1:6379> get key2
"abcdefg"
127.0.0.1:6379> setrange key2 1 xx
(integer) 7
127.0.0.1:6379> get key2
"axxdefg"
127.0.0.1:6379>
setex:设置过期时间
setnx :不存在在设置(在分布式锁中常常使用)**
127.0.0.1:6379> setex key3 30 "hello"
OK
127.0.0.1:6379> ttl key3
(integer) 17
127.0.0.1:6379> setnx mykey "redsi" #如果mykey存在,则创建失败。
(integer) 1
127.0.0.1:6379> keys *
1) "mykey"
2) "key2"
3) "key1"
127.0.0.1:6379> ttl key3
(integer) -2
127.0.0.1:6379> setnx mykey "MongDB"
(integer) 0
127.0.0.1:6379> get mykey
"redsi"
一次性获取,设置多个值:mset,mget
127.0.0.1:6379> keys *
(empty array)
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 #同时设置多个值
OK
127.0.0.1:6379> keys *
1) "k3"
2) "k2"
3) "k1"
127.0.0.1:6379> mget k1 k2 k3 #同时获取多个值
1) "v1"
2) "v2"
3) "v3"
127.0.0.1:6379> msetnx k1 v1 k4 v4 #msetnx是一个原子性操作,要么成功要么失败
(integer) 0
127.0.0.1:6379> get k4
(nil)
127.0.0.1:6379>
对象
mset user:1{name:zhangsan,age:3} #设置一个user:1对象 值为json字符来保存一个对象
这里的key设计:user:{id}:{field}
127.0.0.1:6379> mset user:1:name fang user:1:age 2
OK
127.0.0.1:6379> mget user:1:name user:1:age
1) "fang"
2) "2"
127.0.0.1:6379>
先get在set-------getset
127.0.0.1:6379> getset db redis #没有值则返回nil
(nil)
127.0.0.1:6379> get db
"redis"
127.0.0.1:6379> getset db mongodb #先获取原来的值再设置新的值
"redis"
127.0.0.1:6379> get db
"mongodb"
string类型的使用场景:value除了字符串还可以是数字
- 计数器
- 统计多单位数量
- 粉丝数
- 对象缓存存储
Set
redis里面可以把list完成栈,队列,阻塞队列!
所有的list命令以l开头
127.0.0.1:6379> lpush list one #将一个或多个值插入列表头部(左)尾部添加值为Rpush
(integer) 1
127.0.0.1:6379> lpush list two
(integer) 2
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> lrange list 0 -1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> lrange list 0 1
1) "three"
2) "two"
移除元素
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> LPOP list #移除list第一个元素
"three"
127.0.0.1:6379> RPOP list #移除list最后一个元素
"one"
lindex 通过下标获得值
127.0.0.1:6379> lindex list 1
"one"
127.0.0.1:6379> lindex list 0
"two"
llen返回列表长度
...
127.0.0.1:6379> lpush list three
(integer) 3
127.0.0.1:6379> llen list #返回列表长度
(integer) 3
移除指定值lrem
127.0.0.1:6379> LPUSH list three one four
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "four"
2) "one"
3) "three"
4) "two"
127.0.0.1:6379> LREM list 2 one #移除list中指定个数的value,2个one
(integer) 1
127.0.0.1:6379> LRANGE list 0 -1
1) "four"
2) "three"
3) "two"
trim 修剪list
127.0.0.1:6379> LRANGE LIST 0 -1
1) "four"
2) "one"
3) "three"
4) "two"
5) "five"
127.0.0.1:6379> LTRIM LIST 1 3 #通过下标截取指定长度, LIST已被改变
OK
127.0.0.1:6379> LRANGE LIST 0 -1
1) "one"
2) "three"
3) "two"
rpop lpush,将列表右边元素移到另一个列表的左边
...
127.0.0.1:6379> rpush mylist "2"
(integer) 3
127.0.0.1:6379> rpoplpush mylist myother #移除列表中最后一个元素,将他add到新列表中
"2"
127.0.0.1:6379> lrange mylist 0 -1
1) "0"
2) "1"
127.0.0.1:6379> lrange myother 0 -1
1) "2"
lset list 0 item将下标为0的元素替换为item
127.0.0.1:6379> exists list #判断列表是否存在
(integer) 0
127.0.0.1:6379> lset list 0 item #如果不存在列表。则会报错
(error) ERR no such key
127.0.0.1:6379> lpush list value1
(integer) 1
127.0.0.1:6379> lrange list 0 0
1) "value1"
127.0.0.1:6379> lset list 0 item #存在则更新下标
OK
127.0.0.1:6379> LSET list 1 other
(error) ERR index out of range
linsert 在指定值的前面或者后面插入具体值
127.0.0.1:6379> LPUSH list one
(integer) 1
127.0.0.1:6379> LPUSH list two
(integer) 2
127.0.0.1:6379> LINSERT list before two three
(integer) 3
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
3) "one"
127.0.0.1:6379> LINSERT list AFTER two five
(integer) 4
127.0.0.1:6379> LRANGE list 0 -1
1) "three"
2) "two"
3) "five"
4) "one"
小结:
1.实际上是一个双向链表
2.key不存在,创建新链表
3.移除所有元素,相当于空链表,代表不存在
4.在两边插入或者改动值,效率高,中间元素,相对效率低
可以做消息队列
Hash
redis hash是一个String类型的field和value映射表,hash特别适合用来存储对象
set是一个简化的hash,只变动key,而value使用默认值填充,可以将一个Hash表作为一个对象存储,表中存放对象的信息
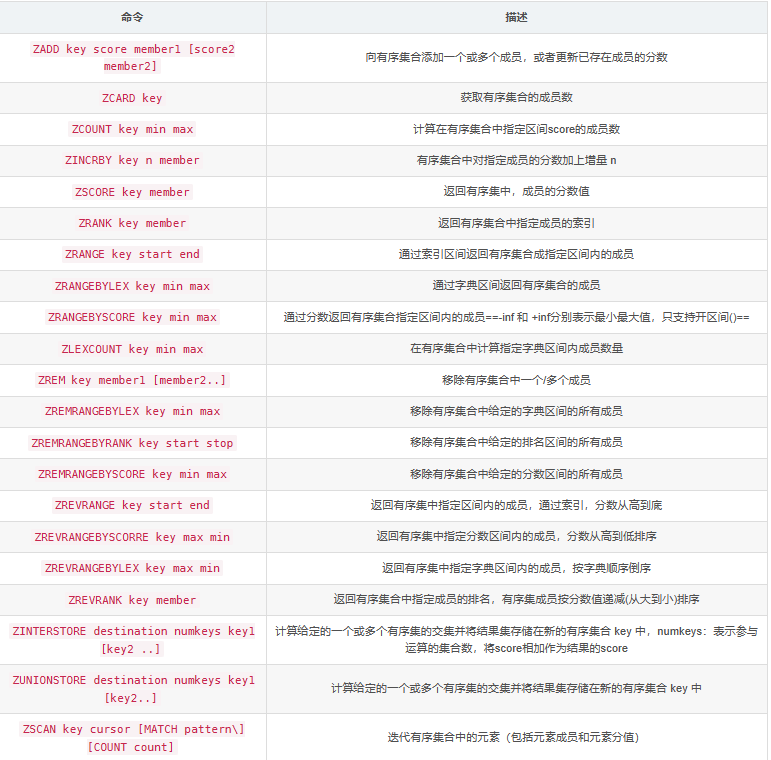
| 命令 | 作用 |
|---|---|
| HSET key field value | 将哈希表key的字段field的值设为value,重复设置则被覆盖,返回0 |
| HMSET key field1 value1[field2 value2]… | 同时将多个键值对设置到哈希表key中 |
| HSETNX key field value | 当字段不存在时,设置字段值 |
| HEXISTS key field | 查看哈希表key中field是否存在 |
| HGET key field value | 获取存储在field中的值 |
| HMGET key field1 [field2…] | 获取所有给定field的值 |
| HGETALL key | 获取在哈希表key的所有字段和值 |
| HKEYS key | 获取哈希表key中的所有field |
| HLEN key | 获取哈希表中字段的数量 |
| HVALS key | 获取所有的值 |
| HDEL key field1 [field2…] | 删除哈希表key中的一个或多个field |
| HINCRBY key field n | 为key中的指定field整数值加上增量n,并返回增量后结果一样只适用于整数型字段 |
| HINCRBYFLOAT key field n | 为key的指定字段的浮点数值加上增量n |
| HSCAN key cursor [MATCH pattern] [COUNT count] | 迭代哈希表中的键值对 |
Zset
有序集合,每一个元素都会关联一个double类型的分数,redis通过分数来为集合中的成员进行从小到大的排序。socre相同,按字典顺序排序
有序集合成员是唯一的,但分数是可以重复的
应用案例:
- set排序 存储班级成绩表 工资表排序!
- 普通消息,1.重要消息 2.带权重进行判断
- 排行榜应用实现,取Top N测试

![[NISACTF 2022]popchains - 反序列化+伪协议](https://img-blog.csdnimg.cn/bdc25a942cea4657b389febe43930bcc.png#pic_center)



![[引擎开发] 杂谈ue4中的Vulkan](https://img-blog.csdnimg.cn/310faa5172ee4827aa79e0c6e983bba1.png)