- 公开视频 -> 链接点击跳转公开课程
- 博客首页 -> 链接点击跳转博客主页
Visual Studio逆向工程配置
基础环境搭建
- Visual Studio 官方下载地址
- 安装配置选项(后期可随时通过VS调整)
- 使用C++的桌面开发

- 拓展可选选项

MASM汇编框架
配置MASM汇编项目
- 创建新项目
- 选择空项目
- 设置项目名称与路径
- 设置生成依赖项
- 添加项目源文件
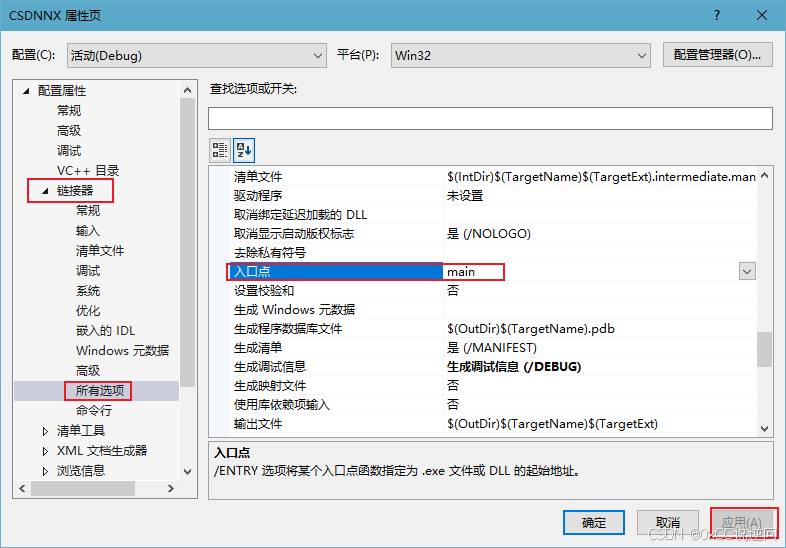
- 设置程序入口点
- 测试汇编框架
.586 .model flat,stdcall option casemap:none.data.codemain procret main endpend