文章目录
- 前言
- 多线程环境使用 ArrayList
- 多线程环境使用队列
- 多线程环境使用哈希表
- 1. HashTable
- 2. ConcurrentHashMap
前言
前面我们学习了很多的Java集合类,像什么ArrayList、Queue、HashTable、HashMap等等一些常用的集合类,之前使用这些都是在单线程中使用的,而如今我们学习了多线程之后就要考虑这些集合在多线程中使用是否会发生一些线程不安全的问题。
原来的集合类大部分都是线程不安全的,除了Vector、Stack、HashTable,是线程安全的(但是这些都不建议使用了,因为Java官方已经将这些集合类标记了,随时都有可能被删除),其他的集合类就是线程不安全的。
多线程环境使用 ArrayList
因为 ArrayList 在多线程环境下可能涉及到同时读和写的操作从而导致线程不安全。为了解决在使用 ArrayList 线程不安全的问题,有以下几种解决方法。
- 自己使用同步机制(使用 synchronized 或者 ReentrantLock 加锁等)
- Collections.synchronizedList(new ArrayList); 使用这个集合类就是在相关方法前面进行 synchronized 加锁
synchronizedList 是标准库提供的一个基于 synchronized 进行线程同步的 List.
synchronizedList 的关键操作上都带有 synchronized
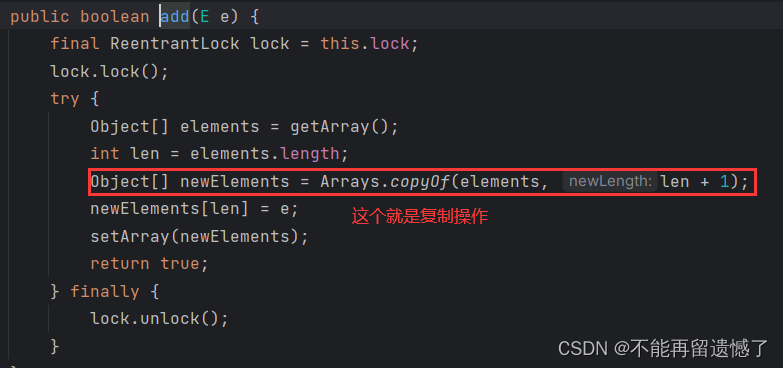
- 使用 CopyOnWriteArrayList
CopyOnWriteArrayList 即写时复制容器,当进行写操作的时候,不是直接添加进容器中,而是先Copy复制出一个容器,将新元素添加进新容器中。当添加完成之后就将原容器的引用指向新容器。这样就可以保证在写的时候,不需要进行加锁,也可以读,并且读的数据是正确的。
CopyOnWriteArrayList 容器的优缺点:
优点:
- 线程安全:CopyOnWriteArrayList 是线程安全的,你可以在多线程环境中无需额外的同步或锁定就能使用它。
- 读操作无需锁定:由于它使用了写时复制策略,所以读取操作(例如 get 和 iterator)可以在没有锁定的情况下进行,这使得它非常适合读多写少的场景。
- 避免阻塞:CopyOnWriteArrayList 使用了一种称为 “乐观锁” 的策略,这意味着它不会在执行修改操作时阻塞读取操作。
缺点:
- 写操作开销大:每次修改操作都会复制整个底层数组,这在数组较大时可能会导致显著的性能开销。因此,CopyOnWriteArrayList 不适合写操作频繁的场景。
- 内存消耗大:由于每次写操作都会复制整个数组,这可能会导致大量的内存消耗。
- 迭代器一致性:CopyOnWriteArrayList 的迭代器是弱一致性的(weakly consistent)。这意味着如果你在迭代过程中修改了列表(除非是通过迭代器自己的 remove 方法),那么迭代器可能不会反映这些修改。
总的来说,CopyOnWriteArrayList 是一种非常有用的工具,但是你应该清楚它的适用场景:读多写少,且数据大小适中。如果你在一个写操作频繁或者数据非常大的场景中使用它,可能会遇到性能问题。
多线程环境使用队列
因为队列先进先出的特性,所以主要的线程安全问题就是当队列为空的时候读取和队列为满的时候插入,为了解决队列在多线程中会出现的问题,主要就是使用了阻塞队列的方法使队列为空时读取数据和队列为满时的插入数据操作进入阻塞等待状态。
- ArrayBlockingQueue
基于数组实现的阻塞队列 - LinkedBlockingQueue
基于链表实现的阻塞队列 - PriorityBlockingQueue
基于堆实现的带优先级的阻塞队列 - TransferQueue
最多只包含一个元素的阻塞队列
多线程环境使用哈希表
在多线程环境下使用哈希表可以使用:
- HashTable
- ConcurrentHashMap
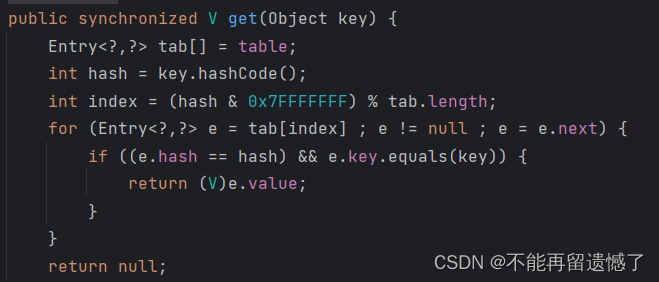
1. HashTable
HashTable 只是给一些关键方法加上了 synchronized 锁,是直接加在方法上的,也就相当于给 HashTable 对象加锁。

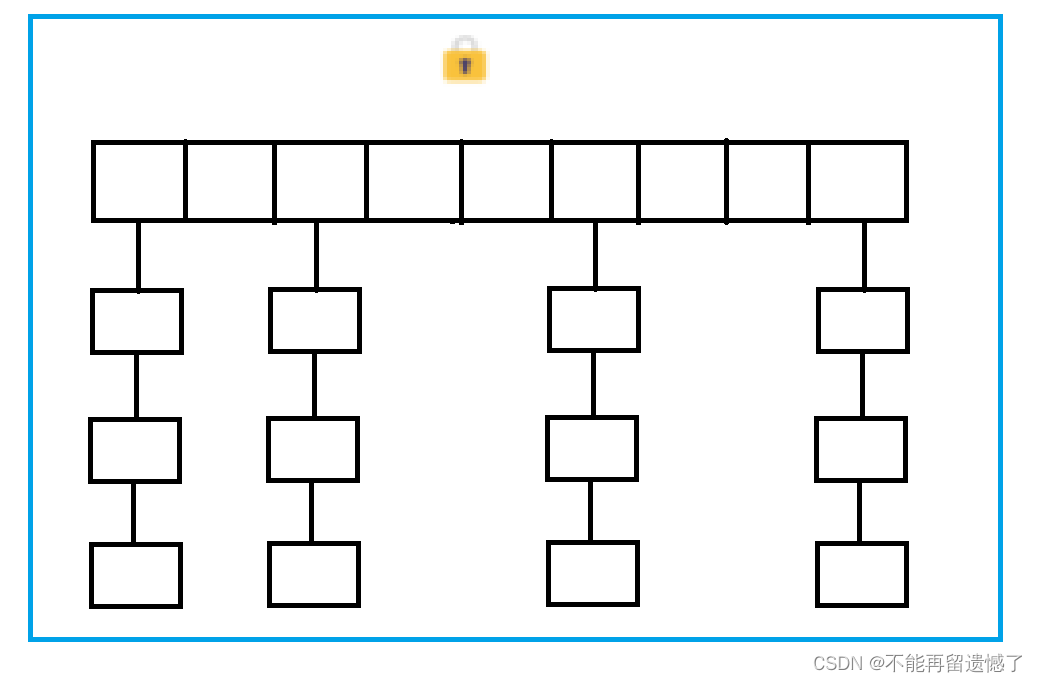
对整个对象加锁就意味着:
- 如果多线程访问同一个 Hashtable 就会直接造成锁冲突.
- size 属性也是通过 synchronized 来控制同步, 也是比较慢的.
- 一旦触发扩容, 就由该线程完成整个扩容过程. 这个过程会涉及到大量的元素拷贝, 效率会非常低.
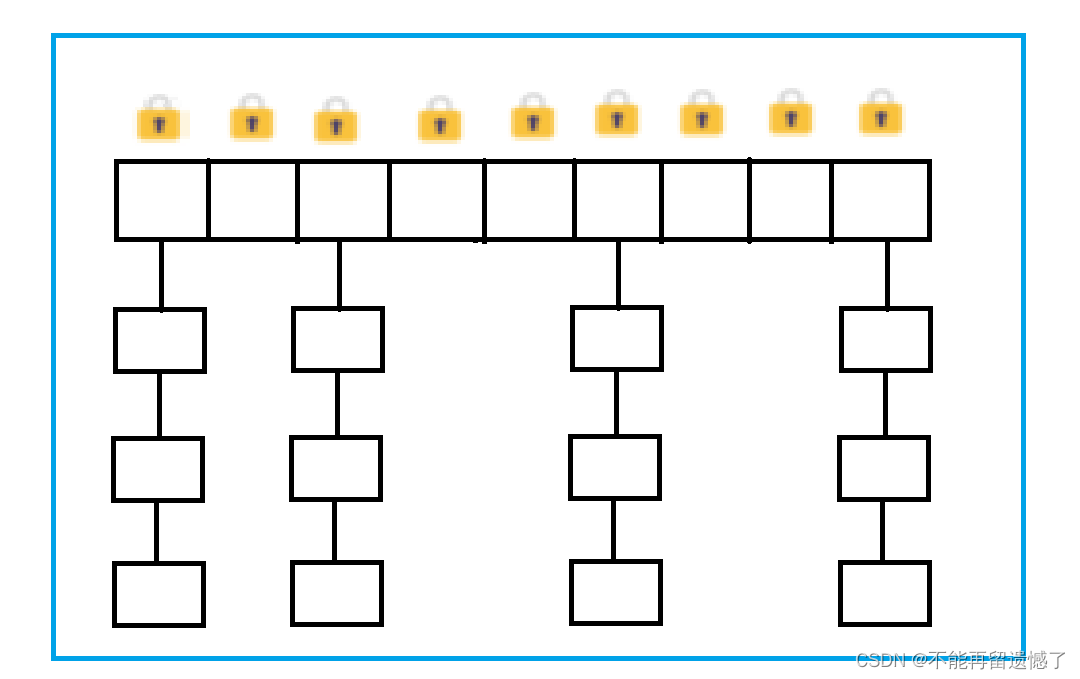
但是实际上,并不是多个线程只要访问同一个 HashTable 对象需要进行加锁,而是只有当两个线程访问到同一个链表的时候才需要进行加锁,并且哈希寻址的时候两个线程同时找到同一个链表的几率是比较小的,所以没必要将整个哈希表都进行加锁。
2. ConcurrentHashMap
ConcurrentHashMap 在 HashTable 的基础上做出了一系列的优化。
- ConcurrentHashMap 将 HashTable 的一个大锁转换为了一个一个加在锁桶的小锁,大大降低了锁冲突的现象。
- 充分利用 CAS 特性,避免了一些不必要加锁的情况。比如更改哈希表中的元素个数 size 时候就使用 CAS 原子操作,不进行加锁。
- ConcurrentHashMap 对读操作没有进行加锁,也就是说当多个线程同时进行读和读操作、读和写操作的时候都不会出现锁竞争的现象。
但是如果不对读操作进行加锁的话,会不会发生读到了一个只修改了一半的数据呢?
答:
其实是不会的,因为 ConcurrentHashMap 在底层编码的时候,比较谨慎的处理了一些细节。在修改操作的时候会避免使用++和- -的这些非原子性的操作,而是使用 = 这种原子性的操作。有了这些操作,就使得读取到的数据要么是修改之前的数据,要么是修改值时候的数据,不会出现读取到的数据是只修改了一半的数据。
- 优化了扩容方式: 化整为零。通过这个优化就避免了短时间内因哈希表中元素过多进行扩容的时候,需要改变的元素过多而造成计算机需要承担的负担过重而导致阻塞的情况。
- 发现需要扩容的线程, 只需要创建一个新的数组, 同时只搬几个元素过去.
- 扩容期间, 新老数组同时存在.
- 后续每个来操作 ConcurrentHashMap 的线程, 都会参与搬家的过程. 每个操作负责搬运一小部分元素.
- 搬完最后一个元素再把老数组删掉.
- 这个期间, 插入只往新数组加.
- 这个期间, 查找需要同时查新数组和老数组