目录:
- 1.源码:
- 2.情绪识别模型运行流程:
- 3.模型封装需要注意的地方:
- 4.未解决问题:
1.源码:
https://gitcode.com/xyint/deep_learning.git
2.情绪识别模型运行流程:
需要获取用户摄像头权限,摄像头会捕获用户的面部视频流,程序会在每一定时间内抽取一帧做处理,将图片与训练好的模型进行张量运算,最后输出各个情绪可能的百分比,取最高百分比的情绪为本次图片的情绪
由于人的情绪相对来说变化的不会很频繁所以情绪识别结果逻辑实现上是做了一个统计,即每30次情绪识别作为一个整体取其中占比最高的情绪作为本段时间用户的真实情绪,这样可以降低单次运算结果对整体结果的影响
import cv2
import logging
from EmotionDetection import DeepFace
from collections import defaultdict# 配置日志
logging.basicConfig(level=logging.ERROR, # 仅记录ERROR及以上级别的日志format='%(asctime)s - %(levelname)s - %(message)s',handlers=[logging.FileHandler("emotion_recognition.log"), # 将日志输出到文件logging.StreamHandler() # 仅在出现ERROR时在控制台输出]
)# 定义情绪与字母的对应关系
emotion_labels = {"angry": "a","disgust": "b","fear": "c","happy": "d","sad": "e","surprise": "f","neutral": "g"
}def update_active_emotion(emotion):# 获取对应字母label = emotion_labels.get(emotion, '?') # 如果情绪不在列表中,用 '?' 表示try:# 打开文件并写入对应字母with open("active_emotion", "w") as f:f.write(label)except Exception as e:logging.error(f"无法更新 active_emotion 文件: {e}")def main():# 初始化摄像头(0为默认摄像头)cap = cv2.VideoCapture(0)if not cap.isOpened():logging.error("无法打开摄像头")return# 可选:设置摄像头分辨率cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1024)cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 1024)# 初始化分析频率控制frame_count = 0analyze_every_n_frames = 5 # 每隔5帧进行一次情绪分析# 情绪统计emotion_buffer = [] # 用于存储30次情绪结果current_dominant_emotion = "neutral" # 当前主导情绪region = {'x': 0, 'y': 0, 'w': 100, 'h': 100} # 初始化区域以避免未定义错误while True:ret, frame = cap.read()if not ret:logging.error("无法读取帧")breaktry:if frame_count % analyze_every_n_frames == 0:# DeepFace 分析当前帧results = DeepFace.analyze(frame, actions=['emotion'], enforce_detection=False,detector_backend='opencv' # 可根据需要更改)# 如果检测到多张人脸,可以遍历 resultsif isinstance(results, list):faces = resultselse:faces = [results]face_detected = Falsefor face in faces:if face['region'] is None:# 未检测到人脸logging.error("未检测到人脸")continueface_detected = Trueregion = face['region']emotions = face['emotion']dominant_emotion = face['dominant_emotion']emotion_score = emotions[dominant_emotion]# 将当前情绪添加到缓冲区emotion_buffer.append(dominant_emotion)# 如果缓冲区达到30次,统计主要情绪并清空缓冲区if len(emotion_buffer) >= 30:# 统计每种情绪的出现次数emotion_counter = defaultdict(int)for emotion in emotion_buffer:emotion_counter[emotion] += 1# 找出出现次数最多的情绪if emotion_counter:new_dominant_emotion = max(emotion_counter, key=emotion_counter.get)if new_dominant_emotion != current_dominant_emotion:current_dominant_emotion = new_dominant_emotionlogging.error(f"主要情绪已更新为: {current_dominant_emotion}")# 更新 active_emotion 文件update_active_emotion(current_dominant_emotion)# 清空缓冲区emotion_buffer = []current_emotions = emotionsif not face_detected:# 没有检测到任何人脸,保持上一次的结果passexcept Exception as e:logging.error(f"处理帧时出错: {e}")# 仅在出现错误时显示提示cv2.putText(frame, "检测出错", (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)# # 绘制当前情绪信息(如果有)# if current_emotions:# x, y, w, h = region['x'], region['y'], region['w'], region['h']# cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)# text = f"{dominant_emotion} ({current_emotions[dominant_emotion]:.2f})"# cv2.putText(frame, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)# # 可选:显示所有情绪分数# offset = 0# for emotion, score in current_emotions.items():# cv2.putText(frame, f"{emotion}: {score:.2f}", (x, y + h + 20 + offset),# cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 1)# offset += 20# else:# # 显示提示# cv2.putText(frame, "未检测到人脸", (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)# # 显示视频帧# cv2.imshow('Real-time Emotion Recognition', frame)# 按下 'q' 键退出if cv2.waitKey(1) & 0xFF == ord('q'):breakframe_count += 1# 释放资源cap.release()cv2.destroyAllWindows()if __name__ == "__main__":main()

按上述逻辑去处理发现识别效果还可
本次没有用太大的模型,大的模型相应的会对算力要求有所提高,占据的资源也会比较大
3.模型封装需要注意的地方:
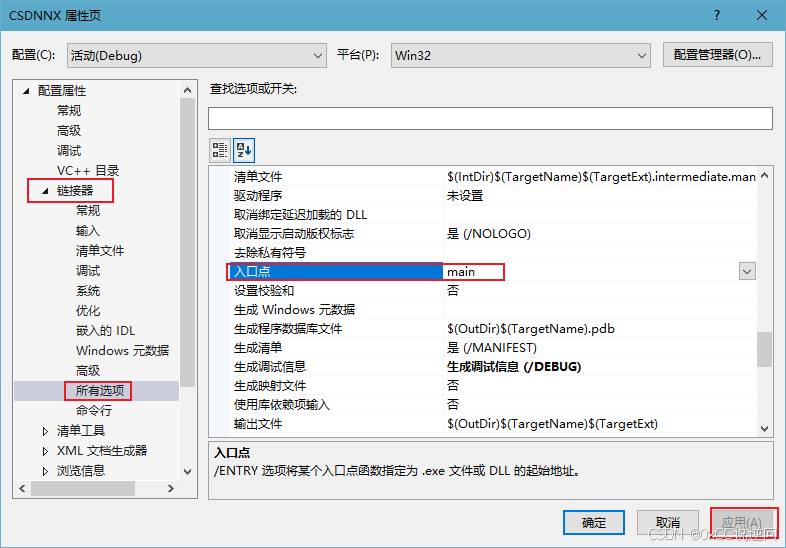
为什么要封装?封装是为了将程序转换成设备可直接阅读并执行的二进制文件就像c文件一样通过gcc编译成可执行文件,那么没有c环境的设备也能通过可执行文件直接运行编辑好的程序,那么将这个情绪识别模型转换成可执行文件部署到jetson上的时候就不用下载相关python库了
封装好的模型直接做一个函数来使用了,也就是获取用户情绪函数,让它单独做一个进程去使用,将用户的情绪结果放置到active_emotion文件中,其他进程需要使用到用户情绪的时候直接打开文件读取即可为了读取方便可以用a、b、c、d…对应相应情绪
注意:
直接用pyinstaller 封装main.py会导致找不到锁定人脸的xml文件和未能将模型封装到可执行文件中所以要先编辑一下.spec文件,这个文件是告诉pyinstaller如何打包,告诉他要把这些重要文件也打包了
# -*- mode: python ; coding: utf-8 -*-a = Analysis(['main.py'], # 主脚本路径pathex=[], # 附加路径(可选)binaries=[], # 二进制依赖(可选)datas=[ # 额外的数据文件('/home/saisi/Desktop/emotional/pth/best_model_CNN_RGB_size96.h5', 'pth'), # 权重文件路径('/home/saisi/.pyenv/versions/narnat/lib/python3.8/site-packages/cv2/data/haarcascade_frontalface_default.xml', 'cv2/data'), # Haar 文件路径('/home/saisi/.pyenv/versions/narnat/lib/python3.8/site-packages/cv2/data/haarcascade_eye.xml', 'cv2/data')],hiddenimports=[], # 隐藏的依赖模块(可选)hookspath=[], # 自定义 hook 脚本路径(可选)hooksconfig={}, # hook 配置(可选)runtime_hooks=[], # 运行时 hook(可选)excludes=[], # 排除的模块(可选)noarchive=False, # 是否禁用归档(可选)optimize=0, # 优化级别(可选)
)pyz = PYZ(a.pure)exe = EXE(pyz,a.scripts,[],exclude_binaries=True,name='main', # 生成的可执行文件名debug=False, # 是否启用调试模式bootloader_ignore_signals=False,strip=False, # 是否剥离符号表upx=True, # 是否启用 UPX 压缩console=True, # 是否显示控制台窗口disable_windowed_traceback=False,argv_emulation=False,target_arch=None, # 目标架构(可选)codesign_identity=None,entitlements_file=None,
)coll = COLLECT(exe,a.binaries,a.datas,strip=False,upx=True,upx_exclude=[], # 排除 UPX 压缩的文件(可选)name='main', # 生成的可执行文件名
)
datas=[ # 额外的数据文件('/home/saisi/Desktop/emotional/pth/best_model_CNN_RGB_size96.h5', 'pth'), # 权重文件路径('/home/saisi/.pyenv/versions/narnat/lib/python3.8/site-packages/cv2/data/haarcascade_frontalface_default.xml', 'cv2/data'), # Haar 文件路径('/home/saisi/.pyenv/versions/narnat/lib/python3.8/site-packages/cv2/data/haarcascade_eye.xml', 'cv2/data')],
这里是说明这些模型的位置.h5是训练好的模型,xml是opencv锁定人脸的文件,将这俩东西位置指定好后再用pyinstaller打包项目就能正常使用了
# README# pth存放训练好的模型
# EmotionDetection内是依赖函数
# main.py是主程序
# Main.py用于检测摄像头是否正常
# active_emotion存储主要情绪,用字母对应方便读取
# emotion_recognition.log存储log信息
# 其他无用的东西全部被删掉了|"requirements.txt"|
|begin|deepface
Werkzeug
Pillow
requests
opencv-python
numpy
# already install in deepface
# Flask
# opencv-python
# numpy
# tqdm|end|### 上述用于下载依赖库## 直接使用
git clone https://gitee.com/daetz_0/emotion_detection_client_server.git
cd emotion_detection_client_server
pip install -r requirements.txt
python main.py
# use the "q" exit### 本识别情绪模型接口是最简洁的模型接口删掉了很多不必要的垃圾
### 这个模块做一个接口使用,类似一个函数
### 预计是将其封装成可执行文件,部署到ubantu测试看能否跑通,不行就直接部署要下载库很麻烦
### main.spec用于将此模块封装成可执行文件运行在Linux系统之上
### 打包命令 pyinstaller main.spec
### 需要模型 best_model_CNN_RGB_size96.h5
### https://gitee.com/daetz_0/emotion_detection_client_server/releases/download/model-weight-data-upload/best_model_CNN_RGB_size96.h5
4.未解决问题:
目前用不了GPU,应该是python库版本问题