代码随想录算法训练营
—day38
文章目录
- 代码随想录算法训练营
- 前言
- 一、322. 零钱兑换
- 二维dp数组
- 二、279.完全平方数
- 二维dp数组
- 三、139. 单词拆分
- 多重背包
- 背包问题总结
- 问题类型
- 递推公式
- 遍历顺序
前言
今天是算法营的第38天,希望自己能够坚持下来!
今日任务:
● 322. 零钱兑换
● 279.完全平方数
● 139.单词拆分
● 关于多重背包,你该了解这些!
一、322. 零钱兑换
题目链接
文章讲解
视频讲解
二维dp数组
思路:
物品无限,完全背包问题。
- dp[j]:凑足总额为j所需钱币的最少个数为dp[j]
- 递归公式:对于物品i,有放和不放两种
①放的话就是 dp[j- weigiht[i]] + 1 (预留出硬币i的空间,加上1个硬币)
②不放的话就是保持dp[j]
所以递推公式是两者取最小 dp[j] = min(dp[j], dp[j- weigiht[i]] + 1) - 初始化:dp[0] = 0 凑成0金额需要0个硬币,其余需要初始化成int最大值,因为递推公式要求最小值
- 遍历顺序:因为求的是个数,不管是组合还是排列,最少的硬币个数都是一样的,所以遍历顺序没有关系
代码如下:
class Solution {
public://dp[j]:凑成j金额最少需要dp[j]个硬币//dp[j] = min(dp[j], dp[j - coins[i]] + 1) 不放硬币i + 放硬币i (预留出硬币i的空间,加上1个硬币)//初始化:dp[0] = 0 凑成0金额需要0个硬币,其余需要初始化成int最大值,因为递推公式要求最小值//遍历顺序:因为求的是个数,不管是组合还是排列,最少的硬币个数都是一样的,所以遍历顺序没有关系int coinChange(vector<int>& coins, int amount) {vector<int> dp(amount + 1, INT_MAX);dp[0] = 0;for (int i = 0; i < coins.size();i++) { //遍历物品for (int j = coins[i]; j <= amount; j++) { //遍历背包if (dp[j - coins[i]] != INT_MAX) //如果等于初始值则跳过dp[j] = min(dp[j], dp[j - coins[i]] + 1); //不跳过的话这里+1会超int}}return dp[amount] == INT_MAX? -1:dp[amount];}
};
二、279.完全平方数
题目链接
文章讲解
视频讲解
二维dp数组
思路:
完全平方数就是物品(可以无限件使用),凑个正整数n就是背包,问凑满这个背包最少有多少物品?也就是完全背包的问题。思路跟动态规划:322. 零钱兑换是一样的,区别就是递推公式中,物品i的重量是i*i
- dp[j]:和为j的完全平方数的最少数量
- 递归公式:dp[j] = min(dp[j], dp[j - ii] + 1) 物品i放的话,腾出ii的位置,数量再+1
- 初始化:dp[0] = 0 ,其余需要初始化成int最大值,因为递推公式要求最小值
- 遍历顺序:因为求的是个数,不管是组合还是排列,最少的硬币个数都是一样的,所以遍历顺序没有关系
代码如下:
class Solution {
public://dp[j]:和为j的完全平方数的最少数量//dp[j] = min(dp[j], dp[j - i*i] + 1)int numSquares(int n) {vector<int> dp(n+1, INT_MAX);dp[0] = 0;for (int i = 1; i*i <= n; i++) {for (int j = i*i; j <= n; j++) {dp[j] = min(dp[j], dp[j - i*i] + 1);}}return dp[n]; //这里不需要判断INT_MAX,因为1就是完全平方数,不管n是什么,都可以用1来组成}
};
三、139. 单词拆分
题目链接
文章讲解
视频讲解
思路:
把字符串s当成 背包,字典里的单词是物品,能重复使用,完全背包问题
- dp[i]:长度为i的字符串可以由字符串列表拼成,因为求的是可以拼成,所以用 bool,dp[j]=true ,求dp[s.size()]
- 递推公式:if (dp[i] && 截取[j,i]区间的字符串可以在字典中找到) dp[i] = true (i前面的都可以拼成,且剩下部分也是字典有的单词)
- 初始化:dp[0] =true其余为false ,不然递推公式一直都是false
- 遍历顺序:因为对顺序有要求,所以要先遍历背包
- 举例推导dp数组:
以输入: s = “leetcode”, wordDict = [“leet”, “code”]为例,dp状态如图:

代码如下:
class Solution {
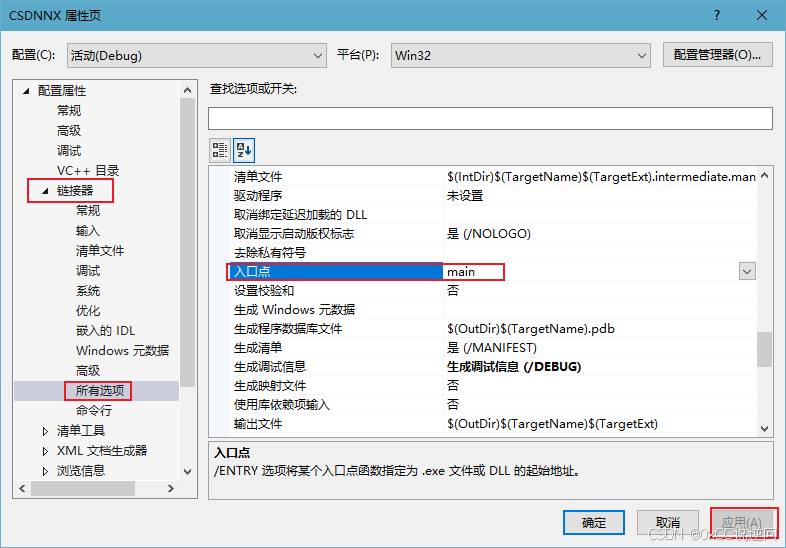
public://把字符串s当成 背包,字典里的单词是物品,能重复使用,完全背包问题//dp[i]:长度为i的字符串可以由字符串列表拼成,dp[i]=true ,求dp[s.size()]//递推公式:if (dp[i] && 截取[j,i]区间的字符串可以在字典中找到) dp[i] = true (i前面的都可以拼成,且剩下部分也是字典有的单词)//初始化:dp[0] =true其余为false ,不然递推公式一直都是false//遍历顺序:因为对顺序有要求,所以要先遍历背包bool wordBreak(string s, vector<string>& wordDict) {//需要转成set用find来判断字符串是否在字典里unordered_set<string>wordSet (wordDict.begin(), wordDict.end());vector<bool> dp(s.size() + 1, false);dp[0] = true;//每次截取[j,i]的字符串来判断,先固定右区间i,左区间j在内循环中移动for (int i = 1; i <= s.size(); i++) { //先遍历背包for (int j = 0; j < i; j++) { //遍历物品string word = s.substr(j, i - j); //substr(起始位置int,截取的个数int)if (wordSet.find(word) != wordSet.end() && dp[j]) {dp[i] = true;}}}return dp[s.size()];}
};
多重背包
题目链接
文章讲解
视频讲解
定义:
多重背包就是每个物品的数量都不一样。
思路:
可以将物品的数量展开,看成是每个物品的数量为1。

转化成数量1:

代码如下:
// 超时了
#include<iostream>
#include<vector>
using namespace std;
int main() {int bagWeight,n;cin >> bagWeight >> n;vector<int> weight(n, 0); vector<int> value(n, 0);vector<int> nums(n, 0);for (int i = 0; i < n; i++) cin >> weight[i];for (int i = 0; i < n; i++) cin >> value[i];for (int i = 0; i < n; i++) cin >> nums[i]; for (int i = 0; i < n; i++) {while (nums[i] > 1) { // 物品数量不是一的,都展开weight.push_back(weight[i]);value.push_back(value[i]);nums[i]--;}}vector<int> dp(bagWeight + 1, 0);for(int i = 0; i < weight.size(); i++) { // 遍历物品,注意此时的物品数量不是nfor(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);}}cout << dp[bagWeight] << endl;
}
但这种方法会超时,主要是因为,当物品数量很多的时候,将物品数量展开的时候 ,vector的动态底层扩容会非常耗时。
方法二:
再多加一个for循环来遍历分别放[1,num[i]]个物品的情况,取最大值
#include<iostream>
#include<vector>
using namespace std;
int main() {int bagWeight,n;cin >> bagWeight >> n;vector<int> weight(n, 0);vector<int> value(n, 0);vector<int> nums(n, 0);for (int i = 0; i < n; i++) cin >> weight[i];for (int i = 0; i < n; i++) cin >> value[i];for (int i = 0; i < n; i++) cin >> nums[i];vector<int> dp(bagWeight + 1, 0);for(int i = 0; i < n; i++) { // 遍历物品for(int j = bagWeight; j >= weight[i]; j--) { // 遍历背包容量// 以上为01背包,然后加一个遍历个数for (int k = 1; k <= nums[i] && (j - k * weight[i]) >= 0; k++) { // 遍历个数dp[j] = max(dp[j], dp[j - k * weight[i]] + k * value[i]);}}}cout << dp[bagWeight] << endl;
}
背包问题总结
问题类型
给定一个的背包(容器),一些物品,物品有自己的重量和价值,
求放满背包(容器),
1.最大价值 2.有多少种方法 3.最少放多少个物品
物品只能放一次:01背包
物品无限放入:完全背包
物品数量不一:多重背包
递推公式
总体就是围绕着对于当前物品i,放或者不放,然后取最大值或最小值,或者两种情况相加。
放则预留出物品i的空间 dp[j - 物品i重量],再根据dp定义,
- 能否装满背包(或者最多装多少),那么放物品i就是dp[j-物品i重量] + 物品i价值
dp[j] = max(dp[j], dp[j - nums[i]] + nums[i])
- 动态规划:416.分割等和子集
- 动态规划:1049.最后一块石头的重量 II
- 求的装满背包有几种方法,就直接是dp[j-物品i重量]
dp[j] += dp[j - nums[i]]
- 动态规划:494.目标和
- 动态规划:518. 零钱兑换
- 动态规划:377.组合总和Ⅳ
- 动态规划:70. 爬楼梯进阶版(完全背包)
- 求的是装满背包所有物品的最小个数,则是dp[j-物品i重量]+1(物品i)
dp[j] = min(dp[j - coins[i]] + 1, dp[j])
- 动态规划:322.零钱兑换
- 动态规划:279.完全平方数
遍历顺序
- 01背包,用一维数组必须先遍历物品,然后背包后序遍历
- 完全背包,如果求的是组合数,一维数组必须先遍历物品,背包正序遍历
- 完全背包,如果求的是排列数,一维数组必须先遍历背包,再遍历物品。
- . 完全背包,如果求的是最大价值,一维数组两种遍历顺序都可以。