目录
一 准备安装包
二 安装 scala
三 修改配置文件
1)修改 workers 文件
2)修改 spark-env.sh文件
四 进入 spark 交互式平台
一 准备安装包
可以自行去 spark 官网下载想要的版本
这里准备了 spark3.1.2的网盘资源
链接: https://pan.baidu.com/s/1Brm6XqaqYQnXQwOd8mUt7A?pwd=2bye 提取码: 2bye
下载后上传至 linux 服务器上
这里放在了 /opt/install 目录
解压至 /opt/soft 目录
tar -zxf /opt/install/spark-3.1.2-bin-hadoop3.2.tgz -C /opt/soft/改个名
cd /opt/softmv spark-3.1.2-bin-hadoop3.2/ spark312修改一下环境变量
#SPARK_HOME
export SPARK_HOME=/opt/soft/spark312
export PATH=$SPARK_HOME/bin:$PATH
二 安装 scala
安装过scala的 朋友可以跳过此步骤
scala 的安装比较简单,spark 的运行环境需要 scala
这里同样准备了网盘资源
链接: https://pan.baidu.com/s/1ua01OvTYjFQyG82AG1g1yg?pwd=imc6 提取码: imc6
下载后上传至 linux 服务器上
这里放在了 /opt/install 目录
解压至 /opt/soft 目录
tar -zxf /opt/install/scala-2.12.10.tgz -C /opt/soft/解压后改个名
mv scala-2.12.10/ scala212修改环境变量,末尾添加下面内容
#SCALA_HOME
export SCALA_HOME=/opt/soft/scala212
export PATH=$SCALA_HOME/bin:$PATH
修改后保存退出,source一下
source /etc/profile三 修改配置文件
进入 spark312/conf 目录
将 两个临时文件cp 一下
cp spark-env.sh.template spark-env.shcp workers.template workers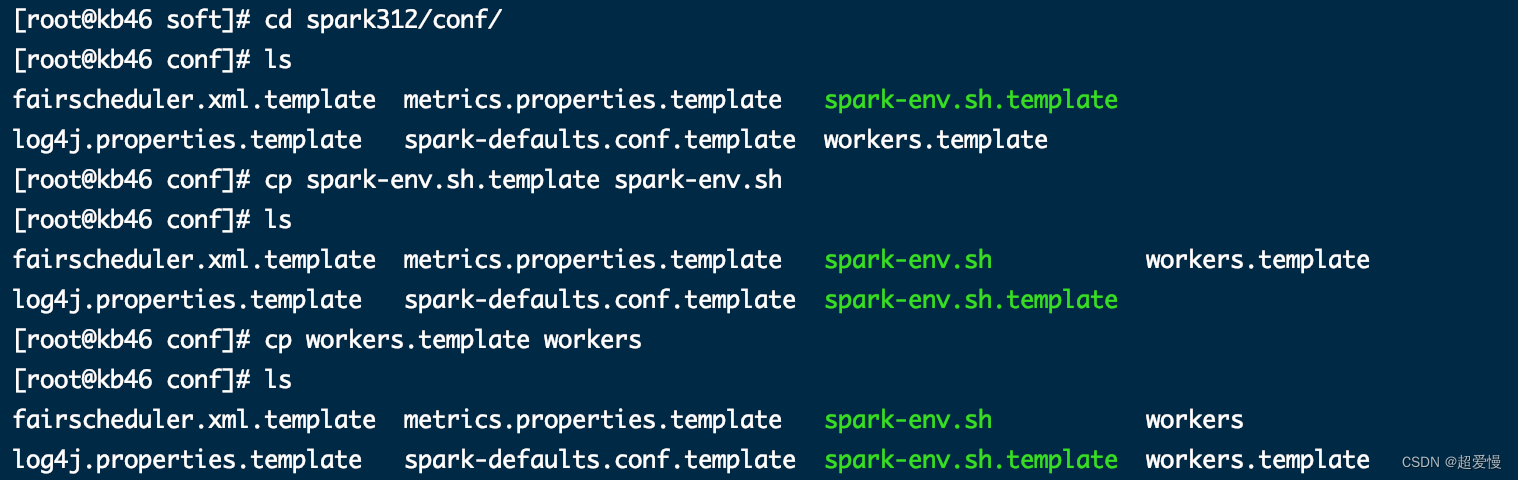
1)修改 workers 文件
vim workers由于这里就是单机版,所以就不做修改
![]()
2)修改 spark-env.sh文件
vim spark-env.sh添加配置,这里根据自己的各个安装包的位置来
export SCALA_HOME=/opt/soft/scala212
export JAVA_HOME=/opt/soft/jdk180
export SPARK_HOME=/opt/soft/spark312
export HADOOP_INSTALL=/opt/soft/hadoop313
export HADOOP_CONF_DIR=$HADOOP_INSTALL/etc/hadoop
export SPARK_MASTER_IP=172.25.38.169
export SPARK_DRIVER_MEMORY=2G
export SPARK_EXECUTOR_MEMORY=2G
export SPARK_LOCAL_DIRS=/opt/soft/spark312四 进入 spark 交互式平台
输入命令回车
spark-shell未给参数默认等同于下面的命令
spark-shell --master local[*]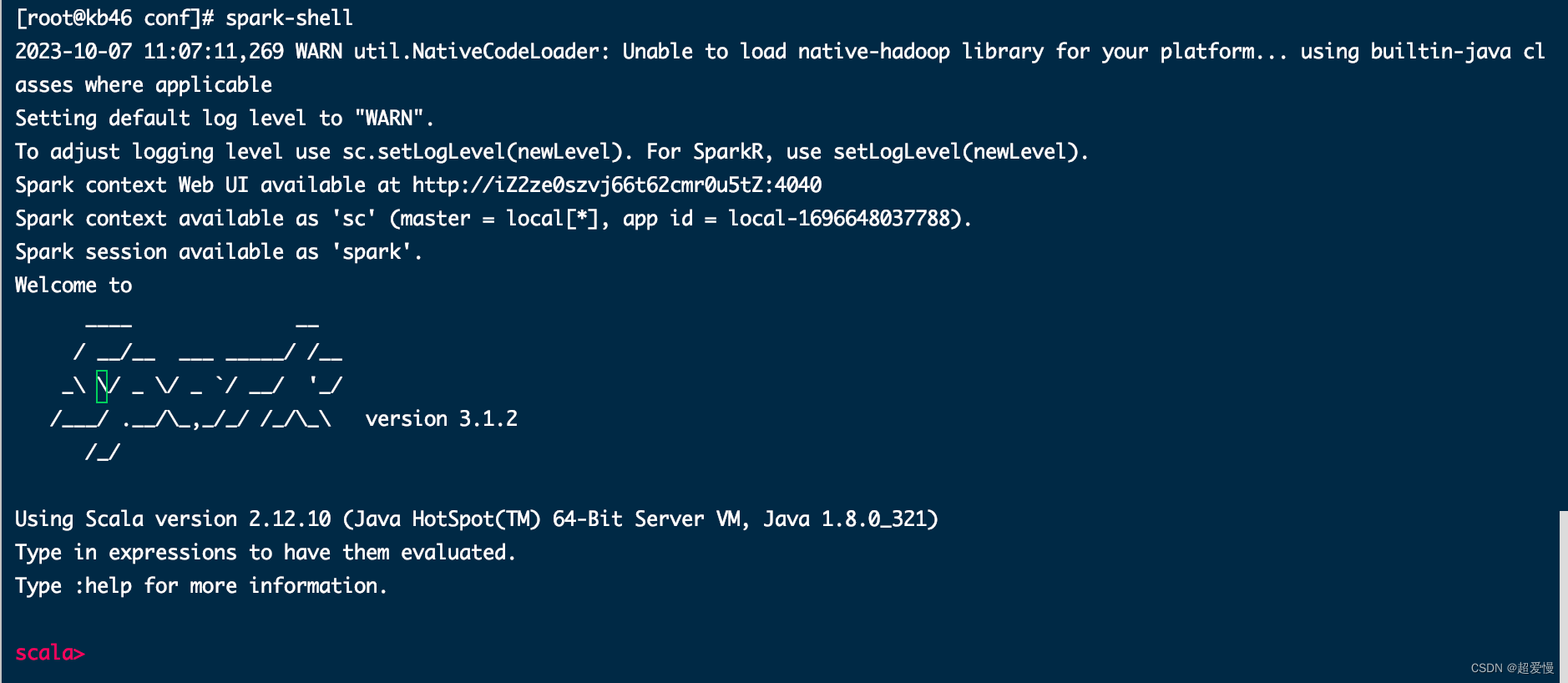
创建一个 RDD
sc.parallelize(1 to 10,3)


![练[FBCTF2019]RCEService](https://img-blog.csdnimg.cn/img_convert/0b10314a302197c35a939c815bef9c95.png)
![2023年中国互联网本地生活服务行业发展历程及趋势分析:国内市场仍有增长潜力[图]](https://img-blog.csdnimg.cn/img_convert/6d00f3c30ae465626960c0107935b591.png)