前言
目标识别如今以及迭代了这么多年,普遍受大家认可和欢迎的目标识别框架就是YOLO了。按照官方描述,YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。从基本的YOLOv1版本到如今v8版本,完成了多次蜕变,现在已经相当成熟并且十分的亲民。我见过很多初学目标识别的同学基本上只花一周时间就可以参照案例实现一个目标检测的项目,这全靠YOLO强大的解耦性和部署简易性。初学者甚至只需要修改部分超参数接口,调整数据集就可以实现目标检测了。但是我想表达的并不是YOLO的原理有多么难理解,原理有多难推理。一般工作中要求我们能够运行并且能够完成目标检测出来就可以了,更重要的是数据集的标注。我们不需要完成几乎难以单人完成的造目标检测算法轮子的过程,我们需要理解YOLO算法中每个超参数的作用以及影响。就算我们能够训练出一定准确度的目标检测模型,我们还需要根据实际情况对生成结果进行一定的改写:例如对于图片来说一共出现了几种目标;对于一个视频来说,定位到具体时间出现了识别的目标。这都是需要我们反复学习再练习的本领。
完成目标检测后,我们应该输出定位出来的信息,YOLO是提供输出设定的超参数的,我们需要根据输出的信息对目标进行裁剪得到我们想要的目标之后再做上层处理。如果是车牌目标识别的项目,我们裁剪出来的车牌就可以进行OCR技术识别出车牌字符了,如果是安全帽识别项目,那么我们可以统计一张图片或者一帧中出现检测目标的个数做出判断,一切都需要根据实际业务需求为主。本篇文章主要是OCR模型对车牌进行字符识别,结合YOLO算法直接定位目标进行裁剪,裁剪后生成OCR训练数据集即可。开源项目地址如下,如果有帮助希望不吝点亮star~:
基于Yolov7-LPRNet的动态车牌目标识别算法模型![]() https://github.com/Fanstuck/Yolov7-LPRNet其中数据集的质量是尤为重要的,决定了模型的上限,因此想要搭建一个效果较好的目标识别算法模型,就需要处理流程较为完善的开源数据集。本篇文章采用的是CCPD数据集,上篇文章已经详细描述了整个项目的初步搭建过程,包括数据集准备和数据预处理,大体系统框架和数据标签聚合,以及利用Yolov7进行模型训练和推理,能够得到图片或者视频帧中车牌的定位数据,现在我们需要搭建LPRNet网络来实现OCR车牌字符识别输出。
https://github.com/Fanstuck/Yolov7-LPRNet其中数据集的质量是尤为重要的,决定了模型的上限,因此想要搭建一个效果较好的目标识别算法模型,就需要处理流程较为完善的开源数据集。本篇文章采用的是CCPD数据集,上篇文章已经详细描述了整个项目的初步搭建过程,包括数据集准备和数据预处理,大体系统框架和数据标签聚合,以及利用Yolov7进行模型训练和推理,能够得到图片或者视频帧中车牌的定位数据,现在我们需要搭建LPRNet网络来实现OCR车牌字符识别输出。
一、车牌字符识别
一般来说此类技术都成为OCR,OCR(Optical Character Recognition)技术是一种将图像中的文字转化为可编辑文本的技术。它可以通过计算机视觉和模式识别的方法来识别和提取图像中的文字信息。根据调研使用的常用网络框架有三种都可以作为车牌识别:
CRNN:最经典的OCR模型了,采用CNN+RNN的网络结构,提出CTC-Loss对齐算法解决不定长序列对齐问题;原始源码是用于文字识别的,稍微改成车牌数据集,即可用于车牌识别了
LPRNet*:*相比经典的CRNN模型,LPRNet 没有采用RNN结构;是专门设计用于车牌识别的轻量级的模型,整个网络结构设计高度轻量化,参数量仅有0.48M
PlateNet:LPRNet网络结构中存在MaxPool3d等算子,在端上部署时,会存在OP不支持等问题,PlateNet模型去除MaxPool3d,改成使用MaxPool2d,保证模型可端上部署成功。
| 模型 | input-size | params(M) | GFLOPs |
|---|---|---|---|
| LPRNet | 94×24 | 0.48M | 0.147GFlops |
| CRNN | 160×32 | 8.35M | 1.06GFlops |
| PlateNet | 168×48 | 1.92M | 1.25GFlops |
本项目采取的是LPRNet,这里简述一下LPRNet。
二、LPRNet
"LPRNet"是用于车牌识别(License Plate Recognition,LPR)的神经网络模型。主要设计出目标就是针对检测和识别车牌字符。 论文由Intel于2018年发表: LPRNet: License Plate Recognition via Deep Neural Networks,网络结构设计追求高度轻量化,为了能够方便在嵌入式设备使用,且识别率还不低完全够用。LPRNet的特点有:
- End-to-End设计:LPRNet是一个端到端的网络,可以直接从原始图像中提取车牌信息,而无需手动设计特征提取器。
- 针对性强:LPRNet专门设计用于车牌识别任务,因此在车牌识别任务上具有很强的性能。
- 多任务学习:LPRNet通常包括字符分类任务和位置回归任务。字符分类任务用于识别车牌上的每个字符,位置回归任务用于定位车牌的位置。
- 卷积神经网络:LPRNet通常使用卷积神经网络来提取特征,这使得它对图像的空间信息进行了很好的利用。
- 采用了特定的损失函数:LPRNet通常会使用CTC(Connectionist Temporal Classification)损失函数来处理字符级别的识别,这是一种适用于序列标注任务的损失函数。
Intel论文中设计了一个图像预处理网络,将车牌图像进行变换(如偏移、旋转车牌图片),得到合适的车牌图片输入到CNN中,论文使用的是LocNet网络自动学习最佳的转换参数。LocNet模型结构如下:
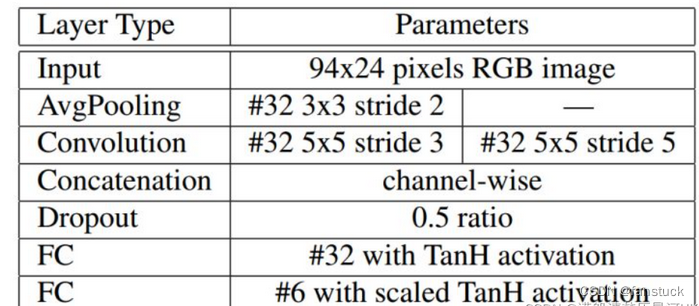
其中LPRNet的backbone模块是自行设计的一个轻量化的backbone,其中设计的一个Small basic block其实就是一个瓶颈型的结构。
Small basic block结构如下:
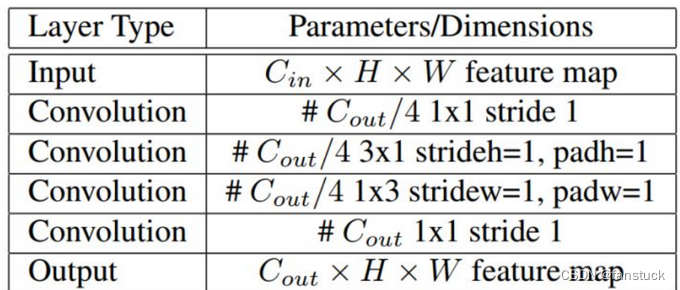
先经过第一个1x1卷积进行降维,再用一个3x1和一个1x3卷积进行特征提取,最后再用1个1x1卷积进行升维。不对称卷积可以代替对称矩阵,3x1+1x3产生和3x3一样的效果,参数量还更少了,而且还多了一个ReLU激活函数,增加了非线性。
class small_basic_block(nn.Module):def __init__(self, ch_in, ch_out):super(small_basic_block, self).__init__()self.block = nn.Sequential(nn.Conv2d(ch_in, ch_out // 4, kernel_size=1),nn.ReLU(),nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(3, 1), padding=(1, 0)),nn.ReLU(),nn.Conv2d(ch_out // 4, ch_out // 4, kernel_size=(1, 3), padding=(0, 1)),nn.ReLU(),nn.Conv2d(ch_out // 4, ch_out, kernel_size=1),)def forward(self, x):return self.block(x)backbone的整体架构:
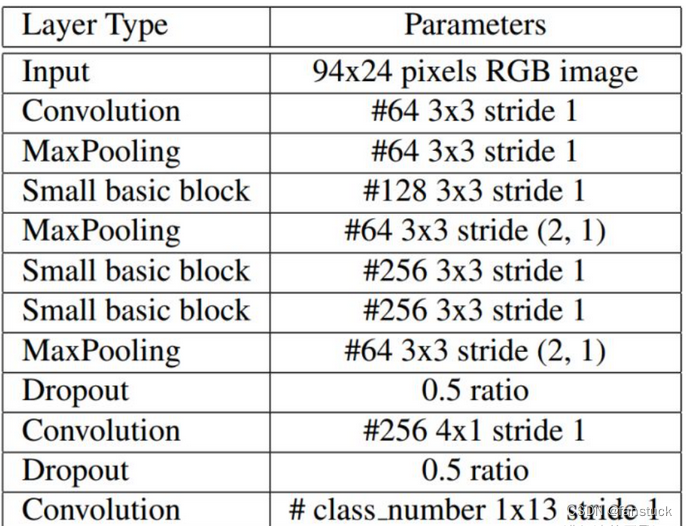
self.backbone = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1), # 0nn.BatchNorm2d(num_features=64),nn.ReLU(), # 2nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 1, 1)),small_basic_block(ch_in=64, ch_out=128), # *** 4 ***nn.BatchNorm2d(num_features=128),nn.ReLU(), # 6nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(2, 1, 2)),small_basic_block(ch_in=64, ch_out=256), # 8nn.BatchNorm2d(num_features=256),nn.ReLU(), # 10small_basic_block(ch_in=256, ch_out=256), # *** 11 ***nn.BatchNorm2d(num_features=256), # 12nn.ReLU(),nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(4, 1, 2)), # 14nn.Dropout(dropout_rate),nn.Conv2d(in_channels=64, out_channels=256, kernel_size=(1, 4), stride=1), # 16nn.BatchNorm2d(num_features=256),nn.ReLU(), # 18nn.Dropout(dropout_rate),nn.Conv2d(in_channels=256, out_channels=class_num, kernel_size=(13, 1), stride=1), # 20nn.BatchNorm2d(num_features=class_num),nn.ReLU(), # *** 22 ***)唯一需要注意的是:最后一层conv用的是一个13x1的卷积代替了原先的BiLSTM来结合序列方向(W方向)的上下文信息。全局上下文嵌入,这部分论文是使用一个全连接层提取上下文信息的,只融合了两层,而这里是使用的avg pool层,而且还在4个尺度上进行了融合:
global_context = list()for i, f in enumerate(keep_features):if i in [0, 1]:f = nn.AvgPool2d(kernel_size=5, stride=5)(f)if i in [2]:f = nn.AvgPool2d(kernel_size=(4, 10), stride=(4, 2))(f)f_pow = torch.pow(f, 2)f_mean = torch.mean(f_pow)f = torch.div(f, f_mean)global_context.append(f)x = torch.cat(global_context, 1)不用再自己从新搭一遍神经网络,比较麻烦, 我这里利用大佬的开源网络模型:GitHub - Fanstuck/LPRNet_Pytorch: Pytorch Implementation For LPRNet, A High Performance And Lightweight License Plate Recognition Framework.
作者:完全适用于中国车牌识别(Chinese License Plate Recognition)及国外车牌识别!
目前仅支持同时识别蓝牌和绿牌即新能源车牌等中国车牌,但可通过扩展训练数据或微调支持其他类型车牌及提高识别准确率!
将该模型集成到我们项目,
那么接下来我们需要对裁剪的数据集进行训练得到模型权重即可。有几点需要注意:
-
准备数据集,图像大小必须为94x24。
-
若要显示测试结果,请添加“--show true”或“--show 1”以运行命令。
其他都挺好看清楚的,看作者提供的主要参数说明:
-
-max_epoch:如果想要精度更高一点,epoch可以设定更高一点。
-
-dropout_rate:假设 Dropout rate 为 0.5,即隐藏层中 50% 的神经元将在每次训练迭中被随机关闭。防止过拟合,如果图片量过少的情况下需要高一点更好。
-
-learning_rate:要是算力充足可以调小一点更加精确。
-
train_batch_size和test_batch_size的默认就行,如果数据集较小不用太大。
-
resume_epoch重复训练,数据集小的可以,数据量大的没有必要。
训练模型
根据自己的数据集以及硬件条件设置train_LPRNet.py的超参数,这里得注意我们需要利用YOLOv7检测出来的定位信息去裁剪原图像的车牌坐标,裁剪到的图片需要转换为94,24的img_size的图片才能训练。之前我们有过准备数据集,直接使用即可。
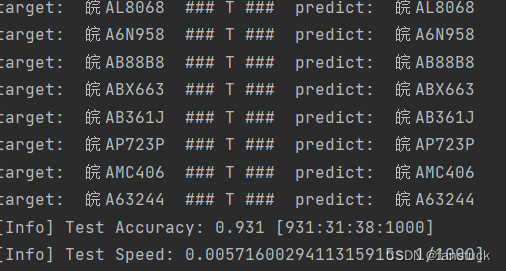
数据集足够大,训练时长给的足够多可以达到比较高的精度,我根据自己制作的数据集训练可以达到93.1%的正确率,该模型权重已经上传github大家不用再次训练了直接使用模型即可。
推理
开源的模型权重能够在我分割的数据集上面跑到73.2%准确率,我们可以使用预训练模型在此基础之上训练得到准确度更高的模型,利用上述模型我们可以进行车牌检测看看效果:




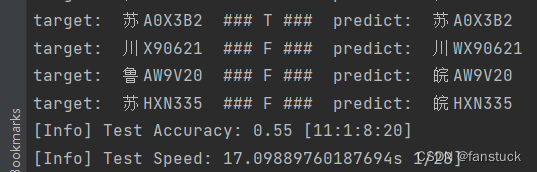
测试了20张图片达到50%,测试1000张图片达到92.3%,测试6000张图片达到了93.5%准确率,效果还是可以的。

备注
有问题的私信博主或者直接评论就可以了博主会长期维护此开源项目,目前此项目运行需要多部操作比较繁琐,我将不断更新版本优化,下一版本将加入UI以及一键部署环境和添加sh指令一键运行项目代码。下篇文章将详细解读LPRNet模型如何进行OCR识别, 再次希望对大家有帮助不吝点亮star~:
https://github.com/Fanstuck/Yolov7-LPRNet![]() https://github.com/Fanstuck/Yolov7-LPRNet
https://github.com/Fanstuck/Yolov7-LPRNet




![2023年中国汽车座舱行业发展现状及趋势分析:高级人机交互(HMI)系统将逐步提升[图]](https://img-blog.csdnimg.cn/img_convert/f637b1b5c70af2b2cc3a0748a2d95bfd.png)