文章目录
- 前言
- 文件扫描模块
- 设计初级扫描方案一
- 实现单线程扫描
- 整合扫描步骤
- 设计初级扫描方案二
- 周期性扫描
- 总结
前言
我们这个模块考虑的是数据库里面的内容从哪里获取。
获取完成后,这时候,我们就需要把目录里面文件/子文件都获取出来,并存入数据库。
文件扫描模块
文件扫描模块,这个模块我们要考虑的是基本的业务逻辑理清楚,我们究竟要干什么,我们基本的步骤如下:
设计初级扫描方案一
我们会设计扫描方案,具体的扫描方案如下:
- 针对单个⽬录, 列出该⽬录下现有的 ⽂件 + ⽬录, 记为 scanned
- 根据⽬录, 从数据库查, 看当前数据库⾥记录了哪些数据, 记为 saved
- 对⽐看哪些⽂件是 scanned ⾥没有, saved ⾥有的, 就从数据库中删除. (说明该⽂件是已经被删了)
- 对⽐看哪些⽂件是 scanned ⾥⾯有, saved ⾥没有的, 就添加到数据库中. (说明该⽂件是新来的)
具体的业务逻辑代码:
//针对单个目录的扫描/*** scan针对一个目录进行处理(整个遍历过程中的基本操作)* 这个方法针对当前path对应的目录进行分析* 列出这个path包含的文件和子目录,并且把这些内容更新到数据库中* 此方法不考虑子目录里面的内容* @param path*/private void scan(File path){/*具体的方法步骤:1.先把当前路径在文件系统上有哪些文件/目录,列出来.=>把真实情况的结果作为List,称为scanned(看看真实的情况)2.拿着这个path去数据库查,看看数据库里都包含哪些对应的结果=>把这个结果也作为一个List,称为saveed(数据库保存的情况)3.看看scaned里面哪些数据是saved不存在的,把这些数据插入数据库,看看saved里面的哪些数据是scaned不存在的,把这些从数据库删除*/System.out.println("[FileManger] 扫描路径: "+path.getAbsolutePath());//1.累出文件系统的真实目录List<FileMeta> scanned=new ArrayList<>();File[] files=path.listFiles();if (files !=null){for (File f: files) {scanned.add(new FileMeta(f));}}//2.列出数据库里面的内容List<FileMeta> saved=fileDao.searchByPath(path.getPath());//3.根据数据库里面的内容与文件系统中的内容进行比对,如果数据库与文件系统比对,文件系统有的,数据库没有的,就增加//文件系统没有的,数据库有的,数据库就删除List<FileMeta> forDelete=new ArrayList<>();for (FileMeta fileMeta:saved) {if (!scanned.contains(saved)){forDelete.add(fileMeta);}}fileDao.delete(forDelete);//4.找出文件系统中有的,数据库没有的,把这些内容往数据库插入List<FileMeta> forInsert=new ArrayList<>();for (FileMeta fileMeta:scanned){if (!saved.contains(scanned)){forInsert.add(fileMeta);}}fileDao.add(forInsert);}
实现单线程扫描
具体的扫描步骤确定之后,我们来规定一下扫描的方式,我们先试用单线程扫描的方式来看看。
总体思路是:
1.扫描当前目录。
2.获取当前目录下所有文件。
3.递归扫描每个子目录。
4.递归出口是当前根目录下无任何文件或目录时返回。
具体代码如下:
public void scanAllOneThread(File basPath){if(!basPath.isDirectory()){return;}//1.针对当前目录进行扫描scan(basPath);//2.列出当前目录的所有文件File[] files=basPath.listFiles();//4.递归出口是当前根目录下无任何文件或目录时返回。if (files == null || files.length==0){//当前目录下没有东西return;}// 3.递归扫描每个子目录。for (File f :files){if (f.isDirectory()){scanAllOneThread(f);}}}
整合扫描步骤
这个类是来整合扫描具体的步骤。
public class SearchService {private FileDao fileDao=new FileDao();private FileManger fileManger=new FileManger();//程序初始化//basePath 为进行搜索指定路径public void init(String basePath){//1.创建数据表fileDao.initDB();//2.针对指定的目录开始扫描,然后进行数据库存储fileManger.scanAll(new File(basePath));System.out.println("[SearchService] 初始化完成!");}}
接下来再建个测试类,来测试一下扫描的结果。
public class TestSearchService {public static void main(String[] args) {SearchService searchService=new SearchService();//searchService.init("D:\\Study\\javaSe");}
}
设计初级扫描方案二
扫描的具体步骤跟扫描方案一的一样,就是扫描的方式变成了,多线程扫描而已。
使用线程池来创建。
具体代码如下
/*** 实现多线程扫描所有目录*///1.生成一个线程池private static ExecutorService executorService = Executors.newFixedThreadPool(8);private void scanAllByThreadPool(File basePath){if (!basePath.isDirectory()){return;}//2.扫描操作放在线程池里面完成executorService.submit(new Runnable() {@Overridepublic void run() {scan(basePath);}});//3.继续递归其他目录File[] files=basePath.listFiles();if (files == null || files.length==0){//当前目录下没有东西return;}for (File f :files){if (f.isDirectory()){scanAllByThreadPool(basePath);}}}
到这里基本的多线程扫描方案已经基本构建完成,但实际上还是存在问题的。
存在什么样的问题呢?大家可以想一想,我在这里列出来。
我们的代码相当于把扫描工作交给线程池完成,主线程只负责遍历目录。但这里就有问题存在了。
1.遍历目录完成了,扫描工作还没完成。
2.扫描工作完成了,遍历目录还没完成。
了解了问题之后,我们开始解决这个问题。之前在多线程也遇到了相同的问题,我们使用json解决的。
现在具体的解决方案如下:
1.引入一个计数器,每次线程增加任务的时候,都让计数器+1.
2.线程每昨晚一个任务的时候,就让计数器-1.
3.当计数器为0时,所有任务就执行完了。
其实这样的方案是有问题的,不过在这个扫描问题上,没问题,因为增加任务的速度大于执行任务的速度。
//初始化选手数目为1 ,当线程所有任务完成之后,就立即调用一次countDown进行撞线private CountDownLatch countDownLatch=new CountDownLatch(1);//衡量任务结束的计数器操作private AtomicInteger taskCount=new AtomicInteger(0);//主体逻辑版本public void scanAll(File baseDir){long beg=System.currentTimeMillis();System.out.println("[FileManager] scanAll 开始!");scanAllByThreadPool(baseDir);try {//开始等待countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}long end =System.currentTimeMillis();System.out.println("[FileManager] scanAll 结束!" +(end -beg) +"ms");}
// 线程池版本扫描,线程安全版private void scanAllByThreadPool(File basePath) {if (!basePath.isDirectory()) {return;}// 计数器自增taskCount.getAndIncrement(); // taskCount++// 扫描操作, 放到线程池里完成.executorService.submit(new Runnable() {@Overridepublic void run() {try {scan(basePath);} finally {// 计数器自减// 把这个自减逻辑放到 finally 中, 确保自减操作是肯定能执行到的.taskCount.getAndDecrement(); // taskCount--if (taskCount.get() == 0) {// 如果计数器为 0 了, 就通知主线程停表了.countDownLatch.countDown();}}}});// 继续递归其他目录.File[] files = basePath.listFiles();if (files == null || files.length == 0) {return;}for (File f : files) {if (f.isDirectory()) {scanAllByThreadPool(f);}}}
周期性扫描
我们最后还要加入一个周期性扫描呢。因为我们在我们的主逻辑中,是项目启动时,才扫描一次,我们万一在工具的使用中,加入新文件和删除旧文件呢,我们就需要周期性的扫描一次。
这个问题的思路有几种方式,我列举一下思路。
思路一:
可以搞一个单独的线程,这个线程周期性的扫描当前设定的这个路径
(比如设定每隔 30s 扫描一遍)
这个思路的问题:
这个扫描周期,不好确定
周期太长用户的修改不会及时感知到
周期太短浪费系统资源的.
思路二:
让操作系统来感知文件的变动(添加/删除/修改/重命名…,一旦有变化就通知咱们的程序Java 标准库提供了一个 APl,WatchService APl,就是干这个事情的
行不通!! 只能监测指定的目录,不能感知到目录里面的子目录/孙子目录等里面的情况…
思路三:
有一些第三方库,也实现了类似的功能.
Apache Commons-l0 这个包 里就提供了类似的 API可以感知到文件的增加,删除,重命名…支持子录/孙子目录…
这个方案本质上还是思路一!!!
everything!!! 是咋做的呢?
windows 上主流使用的文件系统
思路四:
everything 利用了 NTFS 这个文件系统的特殊性质
这个文件系统内置了一个特殊的日志功能.
会把用户的每次的变动都会记录到这个日志中, USN 机制
只需要读取这个日志内容,就知道用户进行了哪些文件改动
我们这里实现的思路是思路一:
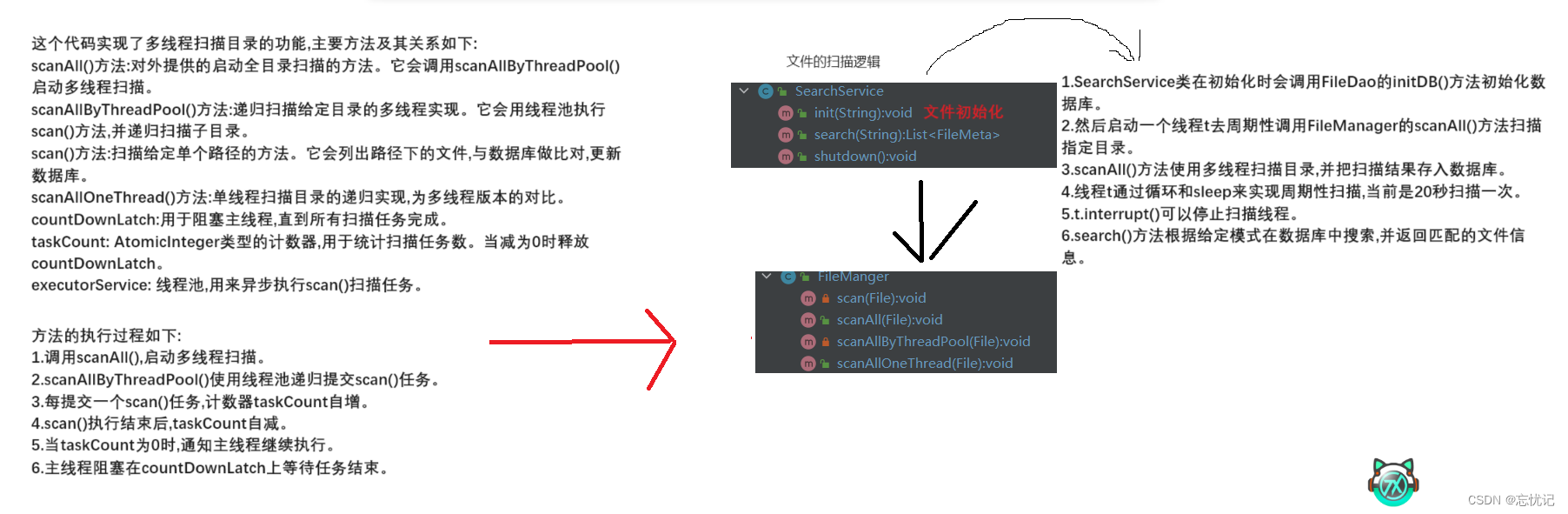
1.在init方法中,先进行数据库的初始化。
2.然后启动一个扫描线程t,在while循环中周期性调用fileManger的scanAll方法扫描指定目录。
3.scanAll方法扫描目录后,会把扫描结果存入数据库中。
4.通过sleep来控制扫描周期,当前代码设置为20秒扫描一次。
5.通过判断t.isInterrupted()来退出循环,当调用shutdown方法时,会interrupt扫描线程t,使其立即退出扫描循环。
代码如下:
private Thread t=null;//程序初始化//basePath 为进行搜索指定路径public void init(String basePath){//初始情况下,就是数据库初始化好,进行下一步操作fileDao.initDB();//把这个操作挪到扫描线程中
// fileManger.scanAll(new File(basePath));t=new Thread(()->{while (!t.isInterrupted()){fileManger.scanAll(new File(basePath));try {//
// Thread.sleep(60000);Thread.sleep(20000);} catch (InterruptedException e) {e.printStackTrace();break;}}});t.start();System.out.println("[SearchService] 初始化完成");}//使用这个方法,让我们的扫描线程停止下来public void shutdown(){if (t!=null){t.interrupt();}}
总结
最后我来梳理一下这个文件扫描的总体逻辑,具体图片如下: