一、模型介绍
Segment Anything 模型是一种新的图像分割模型,它可以在不需要大量标注数据的情况下,对图像中的任何物体进行分割。这种方法可以帮助计算机视觉领域的研究人员和开发人员更轻松地训练模型,从而提高计算机视觉应用程序的性能。该模型使用“自监督学习”的方法,在不需要大量标注数据的情况下训练模型。该模型使用了一个名为“Contrastive Predictive Coding (CPC)”的算法,可以从未标记的图像中学习到有用的特征,并将这些特征用于图像分割任务。
Segment Anything模型可以用于许多应用场景如:
-
自动驾驶汽车:自动驾驶汽车需要能够识别道路、车辆和行人等物体,并对它们进行分割。使用Segment Anything模型可以更准确地进行物体分割,从而提高自动驾驶汽车的性能。
-
医学图像分析:医学图像通常包含许多不同类型的组织和器官。使用Segment Anything模型可以更准确地对这些组织和器官进行分割,从而帮助医生更好地诊断疾病。
-
视频监控:视频监控系统需要能够识别和跟踪不同的对象,并对它们进行分割。使用Segment Anything模型可以更准确地进行对象分割,从而提高视频监控系统的性能。
与传统图像分割方法相比,Segment Anything模型的优势和不同之处主要有以下几点:
-
不需要大量标注数据就可以训练模型:传统的图像分割方法需要大量标注数据才能训练模型;
-
可以对任何物体进行分割:传统的图像分割方法通常只能对特定类型的物体进行分割;
-
更准确:与传统的图像分割方法相比,Segment Anything模型可以更准确地对图像中的物体进行分割;
-
更快速:由于Segment Anything模型不需要大量标注数据,因此可以更快地训练模型。
二、使用方法
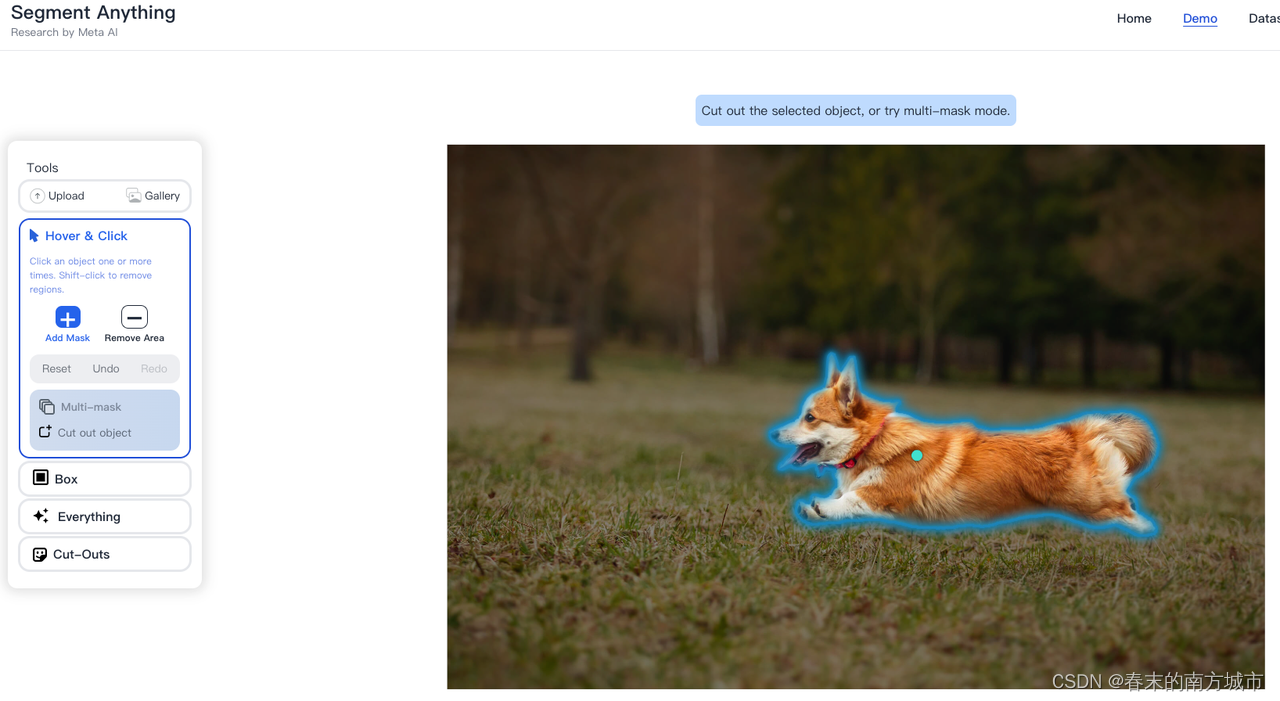
Segment Anything可以一键分割和屏蔽任何照片或视频中的任何对象,包括训练期间没有看到的对象和图像类型。同时还发布了配套的数据集,比现有的数据集大400倍。它从输入提示中产生高质量的物体遮罩,用来为图像中的所有物体产生遮罩。它已经在一个由1100万张图像和11亿个遮罩组成的数据集上进行了训练,并在各种分割任务中具有强大的性能。
使用Segment Anything模型进行图像分割,可用Facebook的Segment Anything库。该库是一个PyTorch库,提供了许多预训练模型,包括Segment Anything模型。使用这些预训练模型来进行图像分割,并将其集成到应用程序中。
Facebook官方示例
segment-anything在线demo体验
SAM数据集地址
三、代码实践
Segment Anything Model (SAM) 预测对象mask,给出所需识别出对象的提示输入。模型首先将图像转换为图像嵌入,然后解码器根据用户输入的提示生成高质量的掩模。
SamPredictor类为模型调用提供了一个简单的接口,用于提示模型的输入。它先让用户使用“set_image”方法设置图像,该方法会将图像输入转换到特征空间嵌入。然后,可以通过“predict”方法输入提示信息,以根据这些提示有效地预测掩码。predict函数支持将点和框提示以及上一次预测迭代中的mask作为输入。
#加载SAM模型
import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamPredictor# 模型在官方示例链接中下载,有三个模型,任意使用一个
sam_checkpoint = "sam_vit_b_01ec64.pth"model_type = "vit_b"device = "cuda"sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)predictor = SamPredictor(sam)#处理图像以生成图像嵌入特征向量,将其用于后续掩码预测
predictor.set_image(image)
1.单点输入预测mask
单点以(x, y)格式输入到模型中,并带有标签1(前景点)或0(背景点)。可以输入多个点。所选的点将在图像上显示为星形。SAM输出3个掩码,其中“scores”给出了模型对这些掩码质量的估计。该模型返回掩码(masks)、掩码的分数(scores)以及可传递到下一次预测迭代的低分辨率掩码(logits),选择在“分数”中返回的分数最高的一个来选择最佳的mask.
input_point = np.array([[250, 187]])
input_label = np.array([1])masks, scores, logits = predictor.predict(point_coords=input_point,point_labels=input_label,multimask_output=True,
)print(masks.shape) # (number_of_masks) x H x W | output (3, 600, 900)for i, (mask, score) in enumerate(zip(masks, scores)):plt.figure(figsize=(10,10))plt.imshow(image)show_mask(mask, plt.gca())show_points(input_point, input_label, plt.gca())plt.title(f"Mask {i+1}, Score: {score:.3f}", fontsize=18)plt.axis('off')plt.show() 模型输出:



2.多点输入预测mask
多点以(x, y)形式输入,并带有标签1(前景点)或0(背景点)。所选的点将在图像上显示为星形。使用多个提示指定单个对象时,可以通过设置“multimask_output=False”来请求获取单个mask。
#(2)多点输入生成mask
input_point = np.array([[250, 284], [362, 422]])
input_label = np.array([1, 1])mask_input = logits[np.argmax(scores), :, :] # Choose the model's best maskmasks, _, _ = predictor.predict(point_coords=input_point,point_labels=input_label,mask_input=mask_input[None, :, :],multimask_output=False,
)
print(masks.shape) #output: (1, 600, 900)plt.figure(figsize=(10,10))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show() 模型输出:

3.输入box预测mask
segment anything支持将xyxy格式的box作为输入,将框内的主体目标识别出来(类似于实例分割)
input_box = np.array([70, 140, 500, 610])
masks, _, _ = predictor.predict(point_coords=None,point_labels=None,box=input_box[None, :],multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
plt.axis('off')
plt.show()
模型输出:

4.自动预测生成mask
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictordef show_anns(anns):if len(anns) == 0:returnsorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)ax = plt.gca()ax.set_autoscale_on(False)img = np.ones((sorted_anns[0]['segmentation'].shape[0], sorted_anns[0]['segmentation'].shape[1], 4))img[:,:,3] = 0for ann in sorted_anns:m = ann['segmentation']color_mask = np.concatenate([np.random.random(3), [0.35]])img[m] = color_maskax.imshow(img)image = cv2.imread('dog11.jpg')
image = cv2.resize(image,None,fx=0.5,fy=0.5)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)sam_checkpoint = "sam_vit_b_01ec64.pth"
model_type = "vit_b"device = "cuda"sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
#自动生成采样点对图像进行分割
mask_generator = SamAutomaticMaskGenerator(sam)masks = mask_generator.generate(image)print(len(masks))
print(masks[0].keys())
print(masks[0])plt.figure(figsize=(16,16))
plt.imshow(image)
show_anns(masks)
plt.axis('off')
plt.show() 模型输出:

OK,最近工作中涉及到一些图像分割方面的应用,对于视觉大模型来说,Meta的Segment Anything肯定要实践一下的,Segment Anything可以用于多种场景下的图像分割,也可以涉及多种方式,可以针对自己的应用场景加以限制,欢迎大家一起交流~




![[PyTorch][chapter 57][WGAN-GP 代码实现]](https://img-blog.csdnimg.cn/1a227a6496cf4e3fb077aa12551839c9.png)