1.MySQL(老版)基础
-
开启MySQL服务:
net start mysqlmysql为安装时的名称 -
关闭MySQL服务:
net stop mysql注: 需管理员模式下运行Dos命令 . 打开服务窗口命令
services.msc -
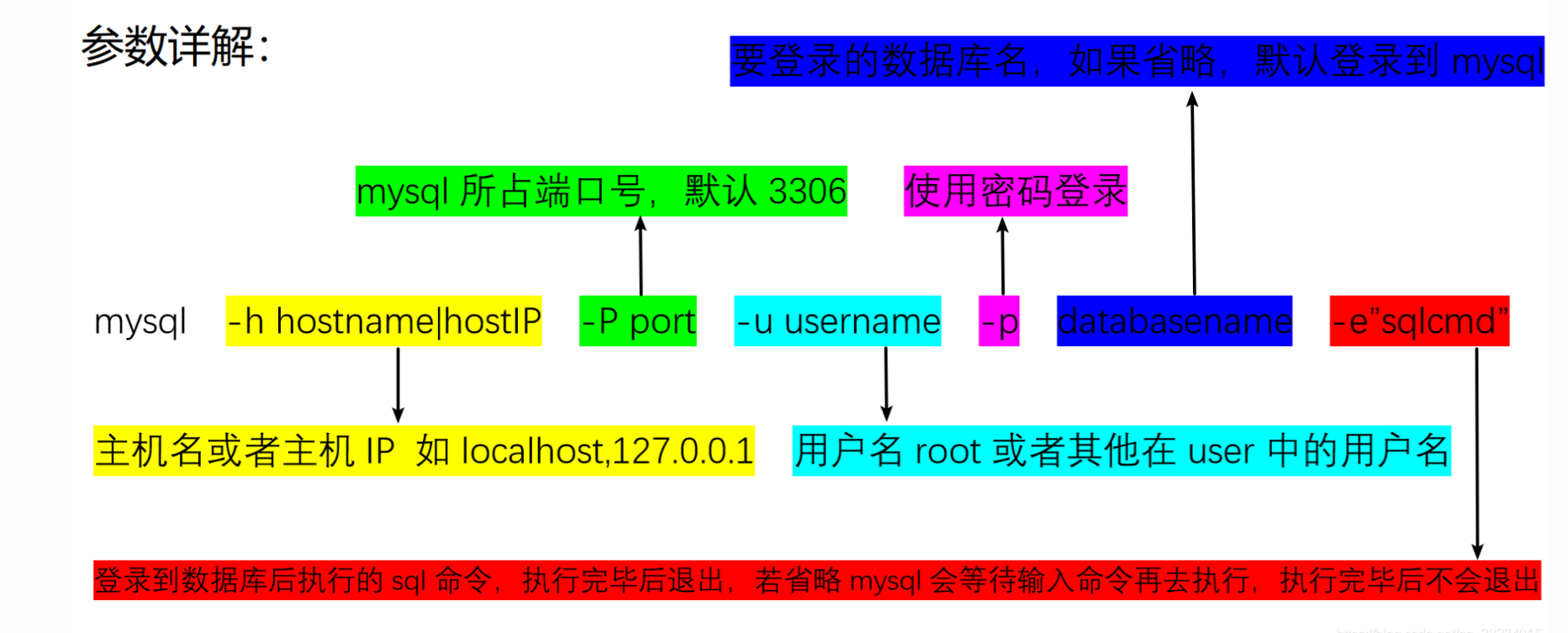
登录MySQL服务:
mysql [-h localhost -P 3306] -u root -p******
Navicat常用快捷键
| 键 | 动作 |
|---|---|
| CTRL+G | 设置位置文件夹 |
| CTRL+#(# 代表 0 至 9) | 从收藏夹列表打开对象窗口 |
| F6 | 命令列界面 |
| CTRL+H | 历史日志 |
| CTRL+Q | 新建查询 |
| F12 | 仅显示活跃对象 |
常规
| 键 | 动作 |
|---|---|
| CTRL+N | 新建对象 |
| SHIFT+CTRL+#(# 代表 0 至 9) | 添加收藏夹 |
| F8 | Navicat 主窗口 |
| CTRL+TAB 或 SHIFT+CTRL+TAB | 下一个窗口 |
| F1 | 说明 |
| CTRL+F1 | 在线文件 |
表设计器
| 键 | 动作 |
|---|---|
| CTRL+O | 打开表 |
| CTRL+F | 查找字段 |
| F3 | 查找下一个字段 |
| SHIFT+F3 | 查找上一个字段 |
表查看器或视图查看器
| 键 | 动作 |
|---|---|
| CTRL+D | 设计表或设计视图 |
| CTRL+Q | 查询表或查询视图 |
| CTRL+F | 查找文本 |
| F3 | 查找下一个文本 |
| CTRL+G | 前往行 |
| CTRL+ 左箭头 | 当前记录的第一个数据列 |
| CTRL+ 右箭头 | 当前记录的最后一个数据列 |
| CTRL+HOME | 当前列的第一个数据行 |
| CTRL+END | 当前列的最后一个数据行 |
| CTRL+PAGE UP 或 CTRL+ 上箭头 | 当前窗口的第一个数据行 |
| CTRL+PAGE DOWN 或 CTRL+ 下箭头 | 当前窗口的最后一个数据行 |
| CTRL+R | 在筛选向导套用筛选 |
| SHIFT+ 箭头 | 选择单元格 |
| CTRL+ENTER | 打开编辑器来编辑数据 |
| INSERT 或 CTRL+N | 插入记录 |
| CTRL+DELETE | 删除记录 |
| CTRL+S | 应用记录改变 |
| ESC | 取消记录改变 |
| CTRL+T | 停止加载数据 |
视图或查询
| 键 | 动作 |
|---|---|
| CTRL+O | 加载视图或加载查询 |
| CTRL+/ | 注释行 |
| SHIFT+CTRL+/ | 取消注释行 |
| CTRL+E | 视图定义或查询编辑器 |
| CTRL+R | 运行 |
| SHIFT+CTRL+R | 运行已选择的 |
| F7 | 从这里运行一个语句 |
| CTRL+T | 停止 |
SQL 编辑器
| 键 | 动作 |
|---|---|
| CTRL+F | 查找文本 |
| F3 | 查找下一个文本 |
| CTRL+= 或 CTRL+鼠标滚轮向上 | 放大 |
| CTRL± 或 CTRL+鼠标滚轮向下 | 缩小 |
| CTRL+0 | 重设缩放 |
调试器
| 键 | 动作 |
|---|---|
| F9 | 运行 |
| F8 | 逐过程 |
| F7 | 逐语句 |
| SHIFT+F7 | 跳过 |
报表
| 键 | 动作 |
|---|---|
| CTRL+O | 在报表设计中打开报表 |
| CTRL+P | 在报表设计中打印 |
| CTRL+G | 在报表设计中组 |
| PAGE DOWN | 下一页 |
| PAGE UP | 上一页 |
| END | 第尾页 |
| HOME | 第一页 |
模型
| 键 | 动作 |
|---|---|
| CTRL+D | 在模型中新建图表 |
| CTRL+P | 打印 |
| ESC | 选择 |
| H | 移动图表 |
| T | 新建表 |
| V | 新建视图 |
| L | 新建层 |
| A | 新建标签 |
| N | 新建笔记 |
| I | 新建图像 |
| R | 新建外键 |
| CTRL+B | 显示已选择的表、视图、外键或形状为粗体 |
| CTRL+= 或 CTRL+鼠标滚轮向上 | 放大 |
| CTRL± 或 CTRL+鼠标滚轮向下 | 缩小 |
| CTRL+0 | 重设缩放 |
一、DQL基础学习(data query language)
-
基础查询
/* 一、基础查询语法: SELECT 查询列表 FROM 表名;1.查询列表可以是:表中的字段、常量值、表达式、函数2.查询的结果是一个虚拟的表格 */ USE myemployees; #1.查询表中单个字段 SELECTlast_name FROMemployees;#2.查询表中多个字段 SELECTlast_name,salary,email FROMemployees;#3.查询表中所有字段 SELECT* FROMemployees; #4.查询常量值 SELECT100; SELECT"Tom"; #5.查询表达式 SELECT90 * 20; SELECT100 % 98; #6.查询函数 SELECTVERSION();#7.起别名 --> 便于理解;有重名时可以区分开来. #方式一: SELECTlast_name AS 姓,first_name AS 名 FROMemployees;#方式二: SELECTlast_name 姓,first_name 名 FROMemployees; SELECTsalary AS "OUT put" FROMemployees;#8.去重 #案例1:查询员工表中涉及到的所有的部门编号,(去重相同编号) distinct SELECT DISTINCTdepartment_id FROMdepartments;#9.连接字段 concat() SELECTCONCAT( last_name, first_name ) AS 姓名 FROMemployees;#10.查看表的结构 DESC departments; -
条件查询
/* 二、条件查询语法: select 查询列表 from 表名 where 筛选条件; */ #案例1:查询工资>12000的员工信息 SELECT* FROMemployees WHEREsalary > 12000;#案例2:查询部门编号不等于90号的员工名和部门编号 SELECTlast_name,department_id FROMemployees WHEREdepartment_id <> 90;#案例1:查询工资在10000到20000之间的员工名、工资以及奖金 SELECTlast_name,salary,commission_pct FROMemployees WHEREsalary <= 20000 AND salary >= 10000;#案例2:查询部门编号不是在90到110之间,或者工资高于15000的员工信息 SELECT* FROMemployees WHERE( department_id < 90 OR department_id >= 110 ) OR salary > 15000;/* 方式三、模糊查询like一般和通配符使用:% 任意多个字符,包含0个字符between andinis null is not null */ # like #案例1:查询员工名中包含字符a的员工信息 SELECT* FROMemployees WHERElast_name LIKE "%a%";#案例2:查询员工名中第三个字符为e,第五个字符为a的员工名和工资 SELECTlast_name,salary FROMemployees WHERElast_name LIKE "__n_l%";#案例3:查询员工名中第二个字符为_的员工名 SELECTlast_name FROMemployees WHERElast_name LIKE "_\_%";# between and #案例1:查询工资在10000到20000之间的员工名、工资以及奖金 SELECTlast_name,salary,commission_pct FROMemployees WHEREsalary BETWEEN 10000 AND 20000;#in #案例:查询员工的工种编号是IT_PROG、AD_VP、AD_PRES中的一个员工名和工种编号 SELECTlast_name,job_id FROMemployees WHEREjob_id = 'IT_PROT' OR job_id = 'AD_VP' OR JOB_ID = 'AD_PRES'; #------------------------------------- SELECTlast_name,job_id FROMemployees WHEREjob_id IN ( 'IT_PROT', 'AD_VP', 'AD_PRES' );# is null is no null ( = 号不可以判断 null) #案例1:查询没有奖金的员工名和奖金率 SELECTlast_name,commission_pct FROMemployees WHEREcommission_pct IS NULL; SELECTlast_name,commission_pct FROMemployees WHEREcommission_pct IS NOT NULL;#安全等于 <=> SELECTlast_name,commission_pct FROMemployees WHEREcommission_pct <=> NULL;#案例2:查询工资为12000的员工信息 SELECT* FROMemployees WHEREsalary <=> 12000;#案例3.查询员工号为176的员工的姓名和部门号和年薪 SELECTlast_name,department_id,employee_id,salary * 12 *(1+IFNULL ( commission_pct, 0 )) AS 年薪 FROMemployees WHEREemployee_id = '176';* FROMemployees; -
排序查询
/* 排序查询:语法:select 查询列表from 表[where 筛选条件]order by 排序列表 asc | desc */#案例1:查询员工信息,要求工资从高到低排序 SELECT* FROMemployees ORDER BYsalary DESC;SELECT* FROMemployees ORDER BYsalary DESC,hiredate ASC;#案例2:查询员工的姓名和部门号和年薪,按年薪降序按姓名升序 SELECTlast_name,department_id,salary * 12 *(1+IFNULL ( commission_pct, 0 )) AS 年薪 FROMemployees ORDER BY年薪 DESC,LENGTH( last_name ) ASC;#案例3:选择工资不在8000到17000的员工的姓名和工资,按工资降序 SELECTlast_name,salary FROMemployees WHERENOT ( salary >= 8000 AND salary <= 17000 ) ORDER BYsalary DESC;#案例4:查询邮箱中包含e的员工信息,并先按邮箱的字节数降序,再按部门号升序 SELECT*,LENGTH( email ) FROMemployees WHEREemail LIKE "%e%" ORDER BYLENGTH( email ) DESC,department_id ASC; -
常见函数
一、字符函数/*进阶四:常见函数:语法: select 函数名(实参列表) [from 表];分类函数:单行函数: 如 concat lenght ifnull等;双行函数: 功能:做统计使用,又称为统计函数、聚合函数、组函数 */#一、字符函数-- 1.LENGTH() 返回字节大小 SELECT LENGTH("Tom"); SELECT LENGTH("张三");-- 2.CONCAT(str1,str2,...) 拼接字符串 SELECT CONCAT(last_name,"_",first_name) AS 姓名 FROM employees; -- 3.UPPER(str)、LOWER(str) 大小写 SELECT UPPER("Tom"); SELECT LOWER("Tom");#案例1:将姓变大写,名变小写,然后拼接 SELECT CONCAT(UPPER(last_name),"_",LOWER(first_name)) AS 姓名 FROM employees;-- 4.substr、substring 索引从 1 开始 #截取从指定索引处后面所有字符 SELECT SUBSTR("李莫愁爱上了陆展元",7) output; #截取从指定索引处指定字符长度的字符 SELECT SUBSTR("李莫愁爱上了陆展元",1,3) output;#案例2:姓名中首字符大写,其他字符小写然后用_拼接,显示出来 SELECT CONCAT(UPPER(SUBSTR(last_name,1,1)),"_",LOWER(SUBSTR(last_name,2))) 姓名 FROMemployees;-- 5.instr 返回子串第一次出现的索引,如果找不到返回 0 ; SELECT INSTR("望庐山瀑布","庐山") AS 子串索引; -- 2-- 6.trim 去除字符两边指定字符,默认参数是去除空格 SELECT TRIM(" 张三 ") AS 姓名; SELECT TRIM("a" FROM " aaaaa张aaaaaaa三aaaaaaaaa") AS 姓名;-- 7.lpad,rpad 用指定的字符实现左(右)填充指定长度SELECT LPAD("张三",10,"*"); SELECT RPAD("张三",10,"*");-- 9.replace 替换 SELECT REPLACE("周芷若爱上了张无忌","周芷若","赵敏") AS 姓名;二、数学函数#二、数学函数-- 1.round 四舍五入 SELECT ROUND(-1.55); SELECT ROUND(1.155,2);-- 2.ceil 向上取整,返回 >= 该参数最小整数 SELECT CEIL(-1.02); SELECT CEIL(5.2);-- 3.floor 向下取整,返回 <= 该参数最大整数 SELECT FLOOR(-9.99); SELECT FLOOR(9.99)-- 4.truncate 截断 SELECT TRUNCATE(5.6854,1);-- 5.mod 取余 mod(a,b) : a-a/b*b = 10-10/3*3 = 1 SELECT MOD(10,3); SELECT 10 % 3;三、日期函数格式表
格式 描述 %a 缩写星期名 %b 缩写月名 %c 月,数值 %D 带有英文前缀的月中的天 %d 月的天,数值(00-31) %e 月的天,数值(0-31) %f 微秒 %H 小时 (00-23) %h 小时 (01-12) %I 小时 (01-12) %i 分钟,数值(00-59) %j 年的天 (001-366) %k 小时 (0-23) %l 小时 (1-12) %M 月名 %m 月,数值(00-12) %p AM 或 PM %r 时间,12-小时(hh:mm:ss AM 或 PM) %S 秒(00-59) %s 秒(00-59) %T 时间, 24-小时 (hh:mm:ss) %U 周 (00-53) 星期日是一周的第一天 %u 周 (00-53) 星期一是一周的第一天 %V 周 (01-53) 星期日是一周的第一天,与 %X 使用 %v 周 (01-53) 星期一是一周的第一天,与 %x 使用 %W 星期名 %w 周的天 (0=星期日, 6=星期六) %X 年,其中的星期日是周的第一天,4 位,与 %V 使用 %x 年,其中的星期一是周的第一天,4 位,与 %v 使用 %Y 年,4 位 %y 年,2 位 #三、日期函数 #now返回当前系统日期+时间 SELECT NOW()#curdate返回当前系统日期,不包含时间 SELECT CURDATE()#curtime返回当前时间,不包含日期 SELECT CURTIME()#可以获取指定的部分,年、月、日、小时、分钟、秒 SELECT YEAR(NOW()); SELECT MONTH(NOW()); SELECT MONTHNAME(NOW()); #返回英文格式 SELECT SECOND(NOW()) ;#datediff(exp1,exp2): 返回两个日期相差的天数 SELECT DATEDIFF(NOW(),"2000-1-24");#str_to_date 将字符通过指定的格式转换成日期SELECT STR_TO_DATE(NOW(),"%Y-%m-%d") AS 时间;#date_format: 将日期转换成指定格式的字符串,指定的格式是输出格式 SELECT DATE_FORMAT(NOW(),'%b %d %Y %h:%i %p');#案例1:查询有奖金的员工名和入职日期(xx月/xx日xx年) SELECT last_name,DATE_FORMAT(hiredate,"%m月/%d日%y年") AS 入职时间 FROM employees WHEREcommission_pct IS NOT NULL;四、其他函数#其他函数SELECT VERSION(); SELECT DATABASE(); SELECT USER();五、流程控制函数-- 1.if函数: if else 的效果 SELECT last_name,commission_pct,IF(commission_pct IS NOT NULL,"有奖金","没奖金") AS 备注 FROMemployees;-- 2.case函数的使用一: swich case 的效果/* 案例:查询员工的工资,要求部门号=30,显示的工资为1.1倍部门号=40,显示的工资为1.2倍部门号=50,显示的工资为1.3倍其他都门,显示的工资为原工资 */ SELECTsalary AS 原始工资,department_id, CASE department_id WHEN 30 THENsalary * 1.1 WHEN 40 THENsalary * 1.2 WHEN 50 THENsalary * 1.3 ELSE salary END AS 新工资 FROMemployees;-- 3.case函数的使用二: 类似于多重 if 的效果/* 案例1:查询员工的工资的情况如果工资>20000,显示A级别如果工资>15000,显示B级别如果工资>10000,显示c级别否则,显示D级别 */ SELECT salary, CASE WHEN salary > 20000 THEN "A"WHEN salary > 15000 THEN "B"WHEN salary > 10000 THEN "C"ELSE "D" END AS 等级 FROM employees;
六、分组函数
#六、分组函数/*功能:用作统计使用,又称为聚合函数或统计函数或组函数分类:sum 求和、avg 平均值、max 最大值、min 最小值、count 计数(非空)特点:1、sum、avg 一般用于处理数值型max、min、count可以处理任何类型2、以上分组函数都忽略nu11值3、可以和 distinct搭配实现去重的运算4、count函数的单独介绍一般使用 count(*)用作统计行数和分组函数一同查询的字段有限制,要求是group by后的字段 */-- 1.sum、avg、max、min、countSELECT SUM(salary) 求和 ,AVG(salary) 平均值,MAX(salary) 最大值,MIN(salary) 最小值 FROM employees;SELECT SUM(DISTINCT salary) FROM employees;-- 2.countSELECT COUNT(*) FROM employees;SELECT COUNT(1) FROM employees;#案例1.查询部门编号为90的员工个数SELECT COUNT(*)FROM employeesWHEREdepartment_id = 90;-
分组查询
#进阶五:分组查询 /*语法:select 分组函数,列(要求出现在 group by 的后面)from 表[where 筛选条件]group by 分组列表[order by 子句]注意:查询列表必须特殊,要求是分组函数和 group by后出现的字段 特点: 1、分组查询中的筛选条件分为两类数据源 位置 关键字 分组前筛选 原始表 group by子句的前面 where 分组后筛选 分组后的结果集 group by子句的后面 having①分组函数做条件肯定是放在 having子句中②能使用分组前筛选就尽量使用 --效率问题*/ #案例1:查询邮箱中包含a字符的,每个部门的平均工资 SELECT AVG(salary),department_id FROM employees WHERE email LIKE "%a%" GROUP BY department_id;#案例2:查询有奖金的每个领导手下员工的最高工资 SELECT MAX(salary),manager_id FROM employees WHERE commission_pct IS NOT NULL GROUP BY manager_id;#案例3:查询哪个部门的员工个数>2 #①查询每个部门的员工个数 SELECT COUNT(*),department_id FROM employees GROUP BY department_id #②根据①的结果进行筛选,查询哪个部门的员工个数>2 HAVING COUNT(*) > 2;#案例4:查询每个工种有奖金的员工的最高工资>12000的工种编号和最高工资 #①查询每个工种有奖金的员工的最高工资 SELECT MAX(salary) 最高工资,job_id FROM employees WHERE commission_pct IS NOT NULL GROUP BY job_id #②根据①结果继续筛选,最高工资>12000 HAVING MAX(salary) > 12000;#案例5:查询领导编号>102的每个领导手下的最低工资>5000的领导编号是哪个,以及其最低工资 SELECT MIN(salary),manager_id FROM employees WHERE manager_id >102 GROUP BY manager_id HAVING MIN(salary) > 5000;#案例6:查询每个部门每个工种的员工的平均工资,并排序 SELECT AVG(salary),department_id,job_id FROM employees GROUP BY department_id,job_id ORDER BY AVG(salary) DESC;练习:
#练习: #1.查询各job_id的员工工资的最大值,最小值,平均值,总和,并按 job_id升序 SELECT MAX(salary), MIN(salary), AVG(salary), SUM(salary),job_id FROM employees GROUP BY job_id ORDER BY job_id; #2.查询员工最高工资和最低工资的差距(DIFFERENCE) SELECT MAX(salary)-MIN(salary) DIFFERENCE FROM employees;#3.查询各个管理者手下员工的最低工资,#其中最低工资不能低于6000,没有管理者的员工不计算在内 SELECT MIN(salary),manager_id FROM employees WHERE manager_id IS NOT NULL GROUP BY manager_id HAVING MIN(salary) >=6000;#4.查询所有部门的编号,员工数量和工资平均值,并按平均工资降序 SELECT department_id,COUNT(*),AVG(salary) FROM employees GROUP BY department_id ORDER BY AVG(salary) DESC;#5.选择具有各个 job_id的员工人数 SELECT COUNT(*),job_id FROM employees WHERE job_id IS NOT NULL GROUP BY job_id; -
连接查询
#进阶六:连接查询 /*1、等值连接①多表等值连接的结果为多表的交集部分②n表连接,至少需要n-1个连接条件③多表的顺序没有要求④一般需要为表起别名⑤可以搭配前面介绍的所有子句使用,比如排序、分组、筛选 */ #三表连接 #案例:查询员工名、部门名和所在的城市 SELECT first_name,last_name,department_name,city FROM employees e,departments d,locations l WHERE e.department_id = d.department_id AND d.location_id = l.location_id ORDER BY last_name DESC;#2、非等值连接 #案例1:查询员工的工资和工资级别 SELECT salary,grade_level FROM employees e,job_grades g WHERE e.salary BETWEEN g.lowest_sal AND g.highest_sal -
基础查询补充
-
sql99语法:
-
语法:
select 查询列表from 表1 别名 【连接类型】[type ] join 表2 别名 #inner 可以省略on 连接条件【where 筛选条件】【group by 分组】【having 筛选条件】【order by 排序列表】-
内连接(同上):连接类型是inner
SELECT last_name,department_name FROMemployees e INNER JOIN departments d ON e.`department_id` = d.`department_id` ;- 外连接: -
左外:left 【outer】
SELECT b.name,bo.* FROMbeauty b LEFT JOIN boys bo ON b.boyfriend_id = bo.id WHERE bo.`id` IS NULL ;- 右外:right【outer】SELECT d.*,e.employee_id FROMemployees e RIGHT OUTER JOIN departments d ON d.`department_id` = e.`department_id` WHERE e.`employee_id` IS NULL ;- 全外:full 【outer】 `mysql不支持`SELECT b.*,bo.* FROMbeauty b FULL OUTER JOIN boys bo ON b.`boyfriend_id` = bo.id ;- 交叉连接(也就是笛卡尔乘积):cross
SELECT b.*,bo.* FROMbeauty b CROSS JOIN boys bo ; -
-
-
子查询
- 含义:出现在其他语句中的select语句,称为子查询或内查询;外部的查询语句,称为主查询或外查询.
- 嵌套在其他语句内部的select语句成为子查询或内查询
- 外面的语句可以是insert、update、delete、select等,一般select作为外面语句较多
分类:
按子查询出现的位置:
select后面:仅仅支持标量子查询
from后面:支持表子查询
where或having后面:支持标量子查询,列子查询,行子查询(较少)
exists后面(相关子查询):支持表子查询
按功能、结果集的行列数不同:
标量子查询(结果集只有一行一列)
列子查询(结果集只有一列多行)
行子查询(结果集有一行多列)
表子查询(结果集一般为多行多列)特点:
子查询放在小括号内
子查询一般放在条件的右侧,where,having
标量子查询,一般搭配着单行操作符使用(> < >= <= = <>)
列子查询,一般搭配着多行操作符使用(IN、ANY/SOME、ALL)
子查询的执行优选与主查询执行,主查询的条件用到了子查询的结果 -
分页查询
-
应用场景:当要显示的数据,一页显示不全,需要分页提交sql请求
-
语法:
select 查询列表from 表【join type】 join 表2on 连接条件where 筛选条件group by 分组字段having 分组后的筛选order by 排序的字段】limit offset,size;# offset:要显示条目的起始索引(从0开始)# size:要显示的条目个数-
特点:
-
limit语句放在查询语句的最后
-
公式:
要显示的页数page,每页的条目数size
select 查询列表 from 表 limit (page - 1)* size, size;
-
-
-
联合查询
-
union:联合,合并,将多条查询语句的结果合并成一个结果
-
应用场景:要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致
-
特点:
- 要求多条查询语句的查询列数是一致的
- 要求多条查询语句的查询的每一列的类型和顺序最好是一致的
- union关键字默认去重,如果使用union all可以包含重复项
/*语法: 查询语句1 union 【ALL】 查询语句2 union 【ALL】 … */#引入案例:查询部门编号>90或邮箱包含a的员工信息 #普通查询: SELECT * FROMemployees WHERE email LIKE "%a%" OR department_id > 90 ;#联合查询 SELECT * FROM employees WHERE email LIKE "%a%" UNION SELECT * FROM employees WHERE department_id > 90;
-
-
查询总结
语法:
select 查询列表 7
from 表1 别名 1
连接类型 join 表2 2
on 连接条件 3
where 筛选 4
group by 分组列表 5
having 筛选 6
order by 排序列表 8
limit 排序列表 9
二、DML语言(Data Manipulation Language)
插入、修改、删除
/*
涉及到数据:插入:insert语法:方式一:insert into 表名(u,…)values(值1,…)方式二:insert into 表名 set 列名=值,列名=值,…修改:update语法:修改单表的记录:update 表名set 列=新值,列=新值…where 筛选条件;修改多表的记录:update 表1 别名inner | left | right join 表2 别名on 连接条件set 列=值,…where 筛选条件;删除:delete方式一:语法:单表的删除:delete from 表名 where 筛选条件[limit 值]多表的删除:delete 别名(要删哪个表就写哪个表的别名,都删就都写)from 表1 别名inner | left | right join 表2 别名 on 连接条件where 筛选条件limit 条目数;方式二:语法:truncate table 表名;truncate语句中不许加where特点:一删全删truncate删除没有返回值,delete删除有返回值truncate删除不能回滚,delete删除可以回滚
*/USE girls;INSERT INTO boys(id,boyName,userCP)
VALUES(6,"李四",100);INSERT INTO boys
SET boyName = "王五",userCP = 50;SELECT * FROM boys;UPDATE boys
SET userCP = 80
WHERE userCP=50;DELETE FROM boys
WHERE boyName LIKE "张%";TRUNCATE TABLE boys;
/*
修改数据:修改单表的记录:语法:update 表名set 列=新值,列=新值…where 筛选条件;修改多表的记录:语法:update 表1 别名inner | left | right join 表2 别名on 连接条件set 列=值,…where 筛选条件;*/UPDATE boys SET boyName = "张三"
WHERE boyName = 'cc';三、DDL(Data Definition Language)数据定义语言
- 库的管理
/*
一、创建库create database [if not exists] 库名 [character set 字符集];
二、修改库alter database 库名 character set 字符集;
三、删除库drop database [if exists] 库名;
*/
#创建库
CREATE DATABASE IF NOT EXISTS xiaozaiyi;
#修改库
ALTER DATABASE xiaozaiyi CHARACTER SET gbk;
#删除库
DROP DATABASE IF EXISTS xiaozaiyi;- 表的管理
/*
表的管理:一、创建表create table [if not exists] 表名(字段名 字段类型 [约束],....,字段名 字段类型 [约束]);二、修改表1.添加列alter table 表名 add column 列名 类型 [first | after 字段名];2.修改类型或约束alter table 表名 modify column 列名 新类型 [新约束];3.修改列名alter table 表名 change column 列名 新列名 类型;4.删除列alter table 表名 drop colunm 列名5.修改表名alter table 表名 rename [to] 新表名;三、删除表drop table [if exists ] 表名;*/
#创建表
USE girls;
CREATE TABLE IF NOT EXISTS books(id INT,author VARCHAR(10),price INT
);#1.添加列
ALTER TABLE books ADD COLUMN t1 INT;
ALTER TABLE books ADD COLUMN t2 INT FIRST;
ALTER TABLE books ADD COLUMN t3 INT AFTER id;
#2.修改类型或约束
ALTER TABLE books MODIFY COLUMN t2 DOUBLE;#3.修改列名
ALTER TABLE books CHANGE COLUMN t2 t4 DOUBLE;#4.删除列
ALTER TABLE books DROP COLUMN t4;#5.修改表名
ALTER TABLE books RENAME boks;
ALTER TABLE boks RENAME books;#删除表
DROP TABLE IF EXISTS books;DESC books;
DESC boks;-
数据类型
整型:
| 类型 | 字节 | 范围 |
|---|---|---|
| tinyint | 1 | -128 ~ 127 无符号 0-255 |
| smallint | 2 | -32768 ~ 32767 |
| mediumint | 3 | 略 |
| int | 4 | 略 |
| bigint | 8 | 略 |
注: int(M) M表示总位数
浮点型:
| 类型 | 字节 | 范围 |
|---|---|---|
| float | 4 | 略 |
| double | 8 | 略 |
注: 定义浮点型时,需指定总位数和小数位数。 float(M, D), double(M, D)
M表示总位数,D表示小数位数。
定点数:
| 类型 | 字节 |
|---|---|
| decimal | 4 |
| decimal(M, D) | M也表示总位数,D表示小数位数,默认decimal(10,0) |
字符型:
| 类型 | 备注 |
|---|---|
| char | 定长字符串,速度快,但浪费空间 |
| varchar(M) | 变长字符串,速度慢,但节省空间, M表示能存储的最大长度,此长度是字符数,非字节数。 |
| text | 在定义时,不需要定义长度,也不会计算总长度。 |
| blob | 二进制字符串(字节字符串) |
日期型:
| 类型 | 字节 | 说明 | 备注 |
|---|---|---|---|
| datetime | 8 | 日期+时间 | 1000-01-01 00:00:00 到 9999-12-31 23:59:59 |
| date | 3 | 日期 | 1000-01-01 到 9999-12-31 |
| time | 3 | 时间 | -838:59:59 到 838:59:59 |
| timestamp | 4 | 时间戳 | 1970-0-0 到 2038-01-19 03:14:07 |
| year | 1 | 年份 | 1901 - 2155 |
-
常见的约束
- 主键:
primary key
1.能唯一标识记录的字段,可以作为主键.
2.一个表只能有一个主键,主键具有唯一性。
创建方式:
#方式一 create table tab ( id int, stu varchar(10) primary key ); #方式二: create table tab ( id int, stu varchar(10), age int, primary key (stu, age));- 唯一索引(唯一约束):
unique
1.使得某字段的值也不能重复。可以为空
- 约束:
not null
1.null不是数据类型,是列的一个属性。
2.null,允许为空。默认。
3.not null,非空,用于保证该字段的值不能为空
- 默认值属性:
default - 默认,用于保证该字段有默认值。比如性别,年龄。
创建方式:
create table tab ( age int default 18);-
自动增长约束:
auto_increment标识列- 自动增长必须为索引(主键或unique)
- 表只能存在一个字段为自动增长.
- 默认为1开始自动增长。可以通过表属性
auto_increment = x进行设置,或alter table tbl auto_increment = x;
面试题:
特点:1.标识列必须和主键搭配吗?不一定,但要求是一个key。2.一个表可以有几个标识列?至多一个。3.标识列的类型?只能是数值型(int(一般是int),float,double)4.标识列可以通过SET auto_increment_increment = 3;设置步长,可以通过手动插入值设置起始值。CREATE TABLE tab_identity (id INT PRIMARY KEY AUTO_INCREMENT,NAME varcahr (20) ) ;#设置表时列的步长 SHOW VARIABLES LIKE '%auto_increment%'; SET auto_increment_increment = 3;
-
检查约束:
check【mysql中不支持】。 -
外键:
foreign key -
用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联列的值。在从表添加外键约束,用于应用主表中某列的值。比如学生表的专业编号,员工表的部门编号,员工表的工种编号。
-
存在外键的表,称之为从表(子表),外键指向的表,称之为主表(父表)。
-
作用:保持数据一致性,完整性,主要目的是控制存储在外键表(从表)中的数据。
CREATE TABLE IF NOT EXISTS stuinfo (id INT PRIMARY KEY,stuname VARCHAR (20) NOT NULL,gender CHAR(1),seat INT UNIQUE,age INT DEFAULT 18,majorID INT,CONSTRAINT fk_stuinfo_major FOREIGN KEY (majorID) REFERENCES major (id) ) ; - 主键:
四、TCL(Transaction Control Language)事务控制语言
-
视图
含义:
是一个虚拟表,其内容由查询定义。同真实的表一样,在引用视图时动态生成。视图具有表结构文件,但不存在数据文件。
视图的可更新性和视图中查询的定义有关系,以下类型的视图是不能更新的。(注意:视图一般用于查询,而不是更新。)
- 创建
语法:
create view 视图名 as 查询语句;#1.视图创建: CREATE VIEW view1 AS SELECT stuname,majorname FROMsuinfo s INNER JOIN major m ON s.majorid = m.`id` ;SELECT * FROM view1 WHERE stuname LIKE '张%' ;#2.视图的修改 #方式1: create or replace view 视图名 as 查询语句; #方式2: alter view 视图名 as 查询语句;#3.查看视图 show create view 视图名; desc 视图名;#4.删除视图 drop view 视图名,视图名,…; -
事务(transaction)
含义:
事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。
事务的特性(acid):
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
#事务开启 所有被执行的SQL语句均被认作当前事务内的SQL语句。 START TRANSACTION; #事物逻辑 .... #事务提交回滚 ROLLBACK; 事务回滚 等同 ROLLBACK WORK COMMIT; 事务确认 等同 COMMIT WORK#保存点 SAVEPOINT 保存点名称 -- 设置一个事务保存点 ROLLBACK TO SAVEPOINT 保存点名称; -- 回滚到保存点 RELEASE SAVEPOINT 保存点名称; -- 删除保存点#开始一个事物.等同与 START TRANSACTION #提交 START TRANSACTION; UPDATE boys SET boyName = "zzz" WHERE boyName ="张三"; UPDATE boys SET boyName = "xxx" WHERE boyName ="王五"; COMMIT; #回滚 START TRANSACTION; UPDATE boys SET boyName = "张三" WHERE boyName ="zzz"; UPDATE boys SET boyName = "xxx" WHERE boyName ="王五"; ROLLBACK;#保存点 START TRANSACTION; UPDATE boys SET boyName = "zzz" WHERE boyName ="张三"; SAVEPOINT a; UPDATE boys SET boyName = "xxx" WHERE boyName ="王五"; ROLLBACK TO SAVEPOINT a;– 注意
1. 数据定义语言(DDL)语句不能被回滚,比如创建或取消数据库的语句,和创建、取消或更改表或存储的子程序的语句。2. 事务不能被嵌套
2.MySQL(新版)基础
2022年2月10日20:04:03
安装
- 查看是否已经安装了mysql
rpm -qa|grep mysql #无输出说明没有安装cat /etc/redhat-releaseMySQL Yum存储库
wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
- 安装mysql源
rpm -Uvh mysql80-community-release-el7-3.noarch.rpmcd /etc/yum.repos.d/-rw-r--r--. 1 root root 2076 4月 25 2019 mysql-community.repo
-rw-r--r--. 1 root root 2108 4月 25 2019 mysql-community-source.repo
-
选择masql版本
使用MySQL Yum Repository安装MySQL,默认会选择当前最新的稳定版本[root@localhost ~] sudo yum-config-manager --enable mysql80-community [root@localhost ~] sudo yum-config-manager --disable mysql57-community -
安装mysql
sudo yum install mysql-community-server
systemctl start mysqld.service
systemctl status mysqld.service
tar 包安装
wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysql-8.0.31-linux-glibc2.12-x86_64.tar.xztar -xvf mysql-8.0.31-linux-glibc2.12-x86_64.tar.xzmv mysql-8.0.31-linux-glibc2.12-x86_64 /usr/local/mysqlgroupadd mysql
useradd -r -g mysql mysqlchown -R mysql.mysql /usr/local/mysqlcd /usr/local/mysqlmkdir data
mkdir logsvi /etc/my.cnf
my.cnf
[client]
port = 3306
socket = /usr/local/mysql/data/mysql.sock
default-character-set = utf8mb4[mysql]
default-character-set = utf8mb4[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_general_ci
init_connect = 'SET NAMES utf8mb4'port = 3306
socket = /usr/local/mysql/data/mysql.sock
skip-external-locking
key_buffer_size = 16M
max_allowed_packet = 1M
table_open_cache = 64
sort_buffer_size = 512K
net_buffer_length = 8K
read_buffer_size = 256K
read_rnd_buffer_size = 512K
myisam_sort_buffer_size = 8M
datadir = /usr/local/mysql/data
lower_case_table_names=1[mysqldump]
quick
max_allowed_packet = 16M[mysql]
no-auto-rehash[myisamchk]
key_buffer_size = 20M
sort_buffer_size = 20M
read_buffer = 2M
write_buffer = 2M[mysqlhotcopy]
interactive-timeoutyum install -y libaio./mysqld --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/ --initialize --lower-case-table-names=1E;-S3CqHC=p,/usr/local/mysql/support-files/mysql.server start
ln -s /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
ln -s /usr/local/mysql/mysql.sock /var/mysql.sock
service mysql restartcp -a ./support-files/mysql.server /etc/init.d/mysqlchmod +x /etc/init.d/mysql
chkconfig --add mysql
chown -R mysql:mysql /usr/local/mysql/ln -s /usr/local/mysql/bin/mysql /usr/binservice mysql start #服务启动
service mysql status #查看服务状态
service mysql stop #停止服务
service mysql restart #重启服务 flush privileges;# 修改密码#8.0ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '1932794922.'; #5.6use mysql;UPDATE user SET Password = PASSWORD('1932794922.') WHERE user = 'root';flush privileges;
开放远程连接
use mysql;
update user set user.Host='%' where user.User='root';# 如何报错ERROR 1062 (23000): Duplicate entry '%-root' for key 'PRIMARY'
GRANT ALL PRIVILEGES on *.* to 'root'@'%' IDENTIFIED BY '1932794922.' with grant option;
flush privileges; //刷新权限设置开机自启动(可选)
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld
chmod +x /etc/init.d/mysqld
chkconfig --add mysqld
chkconfig --list
注:如果看到mysqld的服务,并且3,4,5都是on的话则成功,如果是off,则执行
chkconfig --level 345 mysqld on