什么是 List
在集合框架中, List 是一个接口,继承自 Collection 。
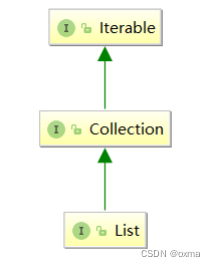
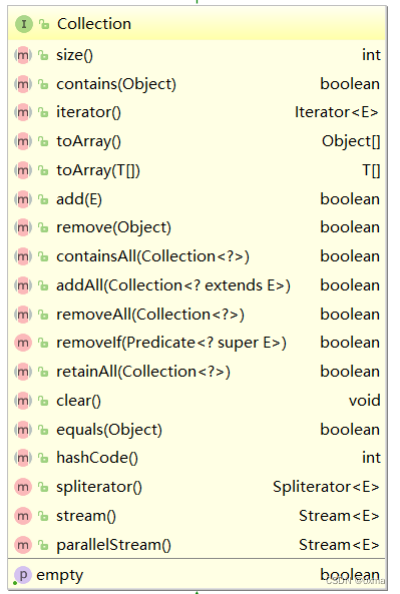
Collection 也是一个接口 ,该接口中规范了后序容器中常用的一些方法,具体如下所示:
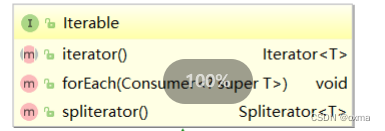
Iterable 也是一个接口,表示实现该接口的类是可以逐个元素进行遍历的,具体如下:
站在数据结构的角度来看, List 就是一个线性表,即 n 个具有相同类型元素的有限序列,在该序列上可以执行增删 改查以及变量等操作 。
常见接口介绍
List 中提供了好的方法,具体如下:
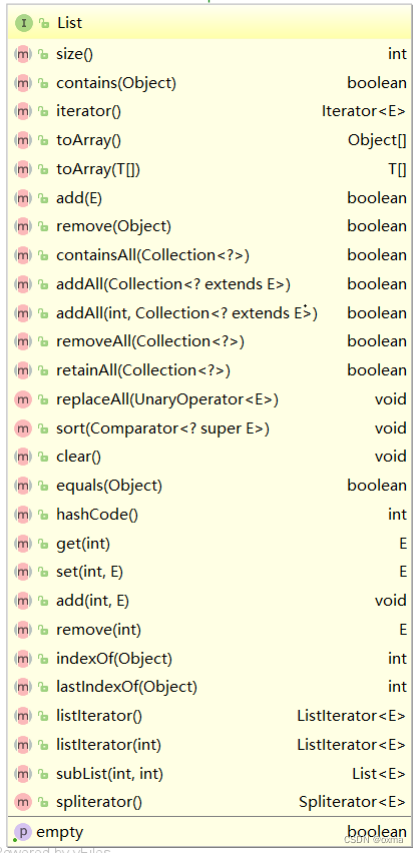
虽然方法比较多,但是常用方法如下:
| 方法 | 解释 |
| boolean add(E e) | 尾插 e |
| void add(int index, E element) | 将 e 插入到 index 位置 |
| boolean addAll(Collection<? extends E> c) | 尾插 c 中的元素 |
| E remove(int index) | 删除 index 位置元素 |
| boolean remove(Object o) | 删除遇到的第一个 o |
| E get(int index) | 获取下标 index 位置元素 |
| E set(int index, E element) | 将下标 index 位置元素设置为 element |
| void clear() | 清空 |
| boolean contains(Object o) | 判断 o 是否在线性表中 |
| int indexOf(Object o) | 返回第一个 o 所在下标 |
| int lastIndexOf(Object o) | 返回最后一个 o 的下标 |
| List<E> subList(int fromIndex, int toIndex) | 截取部分 list |
List的使用
注意: List 是个接口,并不能直接用来实例化
如果要使用,必须去实例化 List 的实现类。在集合框架中, ArrayList 和 LinkedList 都实现了 List 接口 。
线性表
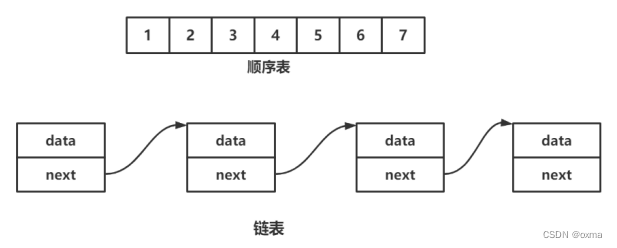
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结 构,常见的线性表:顺序表、链表、栈、队列...
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物 理上存储时,通常以数组和链式结构的形式存储。
顺序表
顺序表是用一段 物理地址连续 的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成 数据的增删查改。
ArrayList 简介
在集合框架中, ArrayList 是一个普通的类,实现了 List 接口,具体框架图如下:

【 说明 】
- ArrayList是以泛型方式实现的,使用时必须要先实例化
- ArrayList实现了RandomAccess接口,表明ArrayList支持随机访问
- ArrayList实现了Cloneable接口,表明ArrayList是可以clone的
- ArrayList实现了Serializable接口,表明ArrayList是支持序列化的
- 和Vector不同,ArrayList不是线程安全的,在单线程下可以使用,在多线程中可以选择Vector或者 CopyOnWriteArrayList
- ArrayList底层是一段连续的空间,并且可以动态扩容,是一个动态类型的顺序表
ArrayList 使用
ArrayList 的构造
| 方法 | 解释 |
| ArrayList() | 无参构造 |
| ArrayList(Collection<? extends E> c) | 利用其他 Collection 构建 ArrayList |
| ArrayList(int initialCapacity) | 指定顺序表初始容量 |
public static void main(String[] args) {// ArrayList创建,推荐写法// 构造一个空的列表List<Integer> list1 = new ArrayList<>();// 构造一个具有10个容量的列表List<Integer> list2 = new ArrayList<>(10);list2.add(1);list2.add(2);list2.add(3);// list2.add("hello"); // 编译失败,List<Integer>已经限定了,list2中只能存储整形元素// list3构造好之后,与list中的元素一致ArrayList<Integer> list3 = new ArrayList<>(list2);// 避免省略类型,否则:任意类型的元素都可以存放,使用时将是一场灾难List list4 = new ArrayList();list4.add("111");list4.add(100);
} ArrayList 常见操作
ArrayList 虽然提供的方法比较多,但是常用方法如下所示,需要用到其他方法时,可以自行查看 ArrayList 的帮助文档
| 方法 | 解释 |
| boolean add(E e) | 尾插 e |
| void add(int index, E element) | 将 e 插入到 index 位置 |
| boolean addAll(Collection<? extends E> c) | 尾插 c 中的元素 |
| E remove(int index) | 删除 index 位置元素 |
| boolean remove(Object o) | 删除遇到的第一个 o |
| E get(int index) | 获取下标 index 位置元素 |
| E set(int index, E element) | 将下标 index 位置元素设置为 element |
| void clear() | 清空 |
| boolean contains(Object o) | 判断 o 是否在线性表中 |
| int indexOf(Object o) | 返回第一个 o 所在下标 |
| int lastIndexOf(Object o) | 返回最后一个 o 的下标 |
| List<E> subList(int fromIndex, int toIndex) | 截取部分 list |
public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("JavaSE");list.add("JavaWeb");list.add("JavaEE");list.add("JVM");list.add("测试课程");System.out.println(list);// 获取list中有效元素个数System.out.println(list.size());// 获取和设置index位置上的元素,注意index必须介于[0, size)间System.out.println(list.get(1));list.set(1, "JavaWEB");System.out.println(list.get(1));// 在list的index位置插入指定元素,index及后续的元素统一往后搬移一个位置list.add(1, "Java数据结构");System.out.println(list);// 删除指定元素,找到了就删除,该元素之后的元素统一往前搬移一个位置list.remove("JVM");System.out.println(list);// 删除list中index位置上的元素,注意index不要超过list中有效元素个数,否则会抛出下标越界异常list.remove(list.size()-1);System.out.println(list);// 检测list中是否包含指定元素,包含返回true,否则返回falseif(list.contains("测试课程")){list.add("测试课程");}// 查找指定元素第一次出现的位置:indexOf从前往后找,lastIndexOf从后往前找list.add("JavaSE");System.out.println(list.indexOf("JavaSE"));System.out.println(list.lastIndexOf("JavaSE"));// 使用list中[0, 4)之间的元素构成一个新的SubList返回,但是和ArrayList共用一个elementData数组List<String> ret = list.subList(0, 4);System.out.println(ret);list.clear();System.out.println(list.size());
} ArrayList的遍历
ArrayList 可以使用三方方式遍历: for 循环 + 下标、 foreach 、使用迭代器
public static void main(String[] args) {List<Integer> list = new ArrayList<>();list.add(1);list.add(2);list.add(3);list.add(4);list.add(5);// 使用下标+for遍历for (int i = 0; i < list.size(); i++) {System.out.print(list.get(i) + " ");}System.out.println();// 借助foreach遍历for (Integer integer : list) {System.out.print(integer + " ");}System.out.println();Iterator<Integer> it = list.listIterator();while(it.hasNext()){System.out.print(it.next() + " ");}System.out.println();
} ArrayList 的扩容机制
ArrayList 是一个动态类型的顺序表,即:在插入元素的过程中会自动扩容。以下是 ArrayList 中扩容方式:
- 检测是否真正需要扩容,如果是调用grow准备扩容
- 预估需要库容的大小
初步预估按照1.5倍大小扩容
如果用户所需大小超过预估1.5倍大小,则按照用户所需大小扩容
真正扩容之前检测是否能扩容成功,防止太大导致扩容失败 - 使用copyOf进行扩容
ArrayList 的问题及思考
- ArrayList底层使用连续的空间,任意位置插入或删除元素时,需要将该位置后序元素整体往前或者往后搬移,故时间复杂度为O(N)
- 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。
- 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间
ArrayList的缺陷
由于ArrayList是通过数组来实现的其底层是一段连续空间,当 在 ArrayList 任意位置插入或者删除元素时,就需要将后序元素整体往前或者往后 搬移,时间复杂度为 O(n) ,效率比较低,因此 ArrayList 不适合做任意位置插入和删除比较多的场景 。因此: java 集合中又引入了LinkedList ,即链表结构。
链表的概念及结构
链表是一种 物理存储结构上非连续 存储结构,数据元素的 逻辑顺序 是通过链表中的 引用链接 次序实现的 。
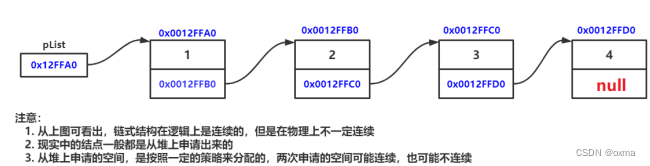
LinkedList
LinkedList 的底层是双向链表结构 ,由于链表没有将元素存储在连续的空间中,元素存储在单独的节点中,然后通过引用将节点连接起来了,因此在在任意位置插入或者删除元素时,不需要搬移元素,效率比较高。
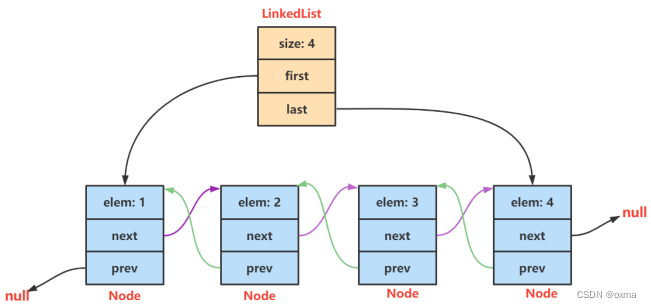
在集合框架中, LinkedList 也实现了 List 接口,具体如下:
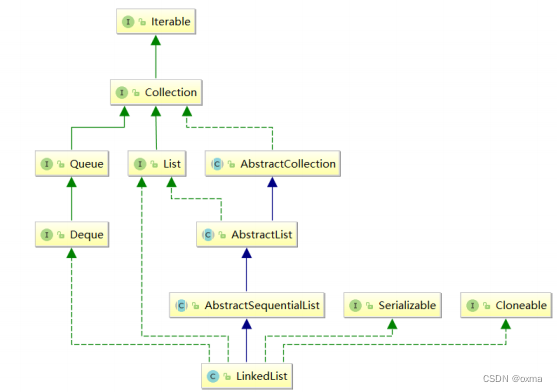
【说明】
- LinkedList实现了List接口
- LinkedList的底层使用了双向链表
- LinkedList没有实现RandomAccess接口,因此LinkedList不支持随机访问
- LinkedList的任意位置插入和删除元素时效率比较高,时间复杂度为O(1)
- LinkedList比较适合任意位置插入的场景
LinkedList 的使用
| 方法 | 解释 |
| LinkedList() | 无参构造 |
| public LinkedList(Collection<? extends E> c) | 使用其他集合容器中元素构造List |
public static void main(String[] args) {// 构造一个空的LinkedListList<Integer> list1 = new LinkedList<>();List<String> list2 = new java.util.ArrayList<>();list2.add("JavaSE");list2.add("JavaWeb");list2.add("JavaEE");// 使用ArrayList构造LinkedListList<String> list3 = new LinkedList<>(list2);
} LinkedList 的其他常用方法介绍
| 方法 | 解释 |
| boolean add(E e) | 尾插 e |
| void add(int index, E element) | 将 e 插入到 index 位置 |
| boolean addAll(Collection<? extends E> c) | 尾插 c 中的元素 |
| E remove(int index) | 删除 index 位置元素 |
| boolean remove(Object o) | 删除遇到的第一个 o |
| E get(int index) | 获取下标 index 位置元素 |
| E set(int index, E element) | 将下标 index 位置元素设置为 element |
| void clear() | 清空 |
| boolean contains(Object o) | 判断 o 是否在线性表中 |
| int indexOf(Object o) | 返回第一个 o 所在下标 |
| int lastIndexOf(Object o) | 返回最后一个 o 的下标 |
| List<E> subList(int fromIndex, int toIndex) | 截取部分 list |
public static void main(String[] args) {LinkedList<Integer> list = new LinkedList<>();list.add(1); // add(elem): 表示尾插list.add(2);list.add(3);list.add(4);list.add(5);list.add(6);list.add(7);System.out.println(list.size());System.out.println(list);// 在起始位置插入0list.add(0, 0); // add(index, elem): 在index位置插入元素elemSystem.out.println(list);list.remove(); // remove(): 删除第一个元素,内部调用的是removeFirst()list.removeFirst(); // removeFirst(): 删除第一个元素list.removeLast(); // removeLast(): 删除最后元素list.remove(1); // remove(index): 删除index位置的元素System.out.println(list);// contains(elem): 检测elem元素是否存在,如果存在返回true,否则返回falseif(!list.contains(1)){list.add(0, 1);}list.add(1);System.out.println(list);System.out.println(list.indexOf(1)); // indexOf(elem): 从前往后找到第一个elem的位置System.out.println(list.lastIndexOf(1)); // lastIndexOf(elem): 从后往前找第一个1的位置int elem = list.get(0); // get(index): 获取指定位置元素list.set(0, 100); // set(index, elem): 将index位置的元素设置为elemSystem.out.println(list);// subList(from, to): 用list中[from, to)之间的元素构造一个新的LinkedList返回List<Integer> copy = list.subList(0, 3); System.out.println(list);System.out.println(copy);list.clear(); // 将list中元素清空System.out.println(list.size());
} LinkedList 的遍历
public static void main(String[] args) {LinkedList<Integer> list = new LinkedList<>();list.add(1); // add(elem): 表示尾插list.add(2);list.add(3);list.add(4);list.add(5);list.add(6);list.add(7);System.out.println(list.size());// foreach遍历for (int e:list) {System.out.print(e + " ");}System.out.println();// 使用迭代器遍历---正向遍历ListIterator<Integer> it = list.listIterator();while(it.hasNext()){System.out.print(it.next()+ " ");}System.out.println();// 使用反向迭代器---反向遍历ListIterator<Integer> rit = list.listIterator(list.size());while (rit.hasPrevious()){System.out.print(rit.previous() +" ");}System.out.println();
} ArrayList 和 LinkedList 的区别
| 不同点 | ArrayList | LinkedList |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 头插 | 需要搬移元素,效率低O(N) | 只需修改引用的指向,时间复杂度为O(1) |
| 插入 | 空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |