前言:Hello大家好,我是小哥谈。目标检测是计算机视觉领域的一项重要研究方向,它在许多应用领域中都得到了广泛应用,如人脸识别、物体识别、自动驾驶、视频监控等。在过去,目标检测方法主要采用基于RCNN、Fast R-CNN等深度学习算法,这些方法虽然精度较高,但需要耗费很长时间进行计算,因此无法实现实时处理。而在2015年,Joseph Redmon等人设计了一种新的深度学习算法YOLO,这种算法具有处理速度快、准确性高的特点,被广泛应用于目标检测领域。本节课就给大家重点介绍下YOLO系列算法的开山之作—YOLOv1,希望大家学习之后能够有所收获!🌈
目录
🚀1.什么是目标检测?
🚀2.YOLOv1算法的诞生背景
🚀3.YOLOv1论文
🚀4.YOLOv1技术原理
💥💥4.1 网络结构
💥💥4.2 实现方法
💥💥4.3 训练策略
🚀5.YOLOv1性能评价

🚀1.什么是目标检测?
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
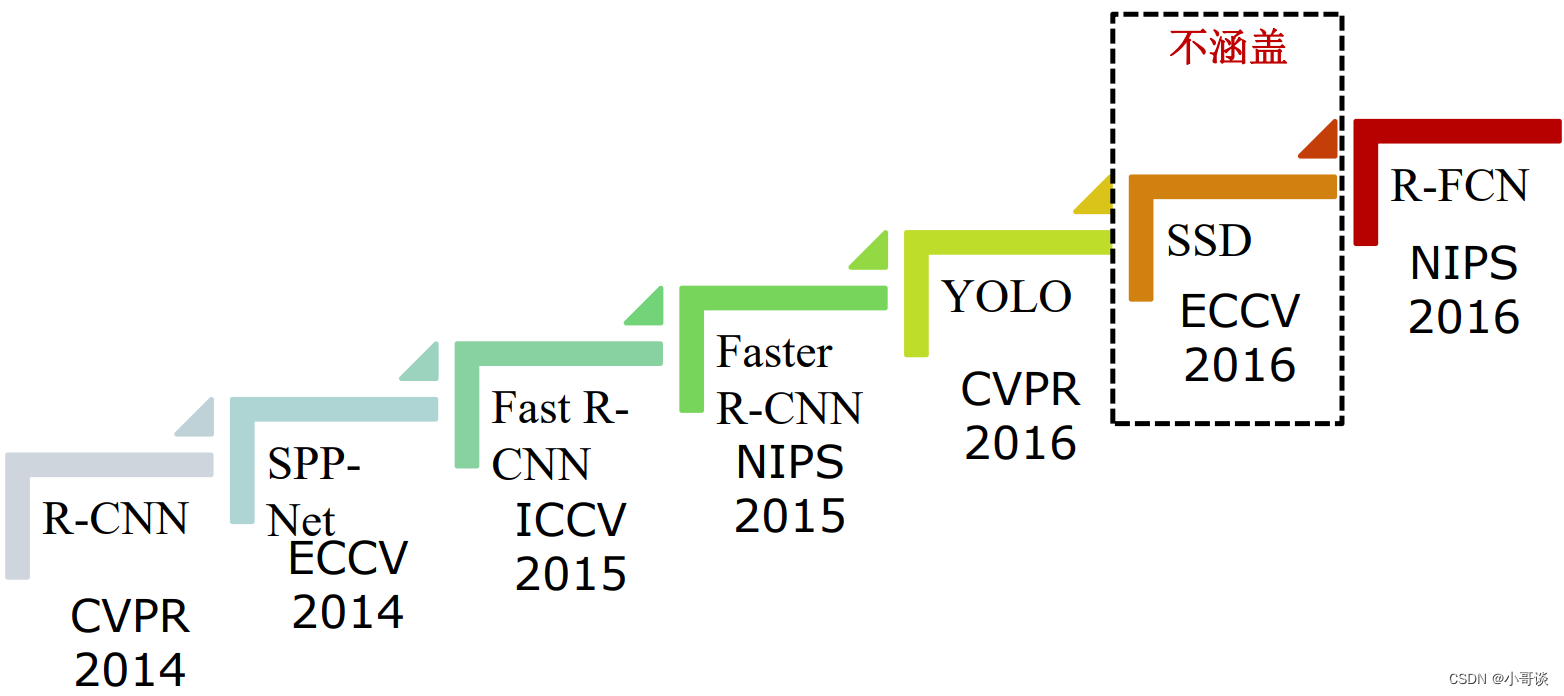
如今,目标检测的研究方法主要包括两大类:
- 基于传统图像处理和机器学习算法的目标检测与识别方法
- 基于深度学习的目标检测与识别方法
针对这两种目标检测方法,下面进行详细介绍。
🍀(1)基于传统图像处理和机器学习算法的目标检测与识别方法
传统的目标检测与识别方法主要可以表示为:目标特征提取 -> 目标识别 -> 目标定位。这里所用到的特征都是人为设计的,主要包括:
- SIFT (尺度不变特征变换匹配算法,Scale Invariant Feature Transform);
- HOG(方向梯度直方图特征,Histogram of Oriented Gradient);
- SURF( 加速稳健特征,Speeded Up Robust Features)。
通过这些特征对目标进行识别,然后再结合相应的策略对目标进行定位。
🍀(2)基于深度学习的目标检测与识别方法
如今,基于深度学习的目标检测与识别方法已经成为主流方法,主要可以表示为:图像的深度特征提取 -> 基于深度神经网络的目标识别与定位,其中主要用到的深度神经网络模型是卷积神经网络CNN。目前可以将现有的基于深度学习的目标检测与识别算法大致分为以下三大类:
- 基于区域建议的目标检测与识别算法,如R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNN等;
- 基于回归的目标检测与识别算法,如YOLO、SSD;
- 基于搜索的目标检测与识别算法,如基于视觉注意的AttentionNet,基于强化学习的算法等。
🚀2.YOLOv1算法的诞生背景
YOLOv1算法是在2016年发表的,由Joseph Redmon等人开发,其全称为You Only Look Once version 1。它的特点是将目标检测问题转化为一个回归问题,通过一个神经网络直接预测出目标的类别和位置信息。相比于传统的目标检测算法,YOLOv1具有速度快、精度高等优点。 YOLOv1算法的诞生背景是由于传统的目标检测算法在实时性和准确性上存在矛盾。传统的目标检测算法需要在图像中进行多次滑动窗口操作,计算量大,导致实时性较差。而YOLOv1算法采用了全卷积神经网络,将目标检测任务转化为一个回归问题,大大减少了计算量,提高了实时性。此外,YOLOv1算法还采用了多尺度训练和多尺度预测等技术,进一步提高了检测准确率。✅
❓❓YOLOv1算法相比于传统目标检测算法有哪些优势和劣势?
YOLOv1相比于传统目标检测算法的优势主要有两点:
- YOLOv1的检测速度非常快,可以达到实时检测的要求,这是因为YOLOv1采用了单个神经网络同时预测多个物体的位置和类别,避免了传统算法中的候选区域生成和特征提取等耗时的步骤。
- YOLOv1的检测精度相对较高,尤其是在小目标检测方面表现优异,这是因为YOLOv1采用了整张图像的全局信息进行物体检测,避免了传统算法中因为局部信息不足而导致的漏检和误检。
但是,YOLOv1也存在一些劣势:
- YOLOv1对于小目标的检测效果不如传统算法,这是因为YOLOv1采用了较大的输入图像尺寸和较粗的特征图,导致小目标的特征难以被有效提取。
- YOLOv1在物体定位方面存在一定的误差,这是因为YOLOv1采用了较粗的特征图进行物体位置预测,导致物体位置的精度不高。
🚀3.YOLOv1论文
YOLOv1算法论文的题目是《 You Only Look Once: Unified, Real-Time Object Detection》,由 Joseph Redmon、Santosh Divvala、Ross Girshick和 Ali Farhadi 四位作者于2016年提出。该论文提出了一种基于单个神经网络的实时目标检测算法,可以在一张图片中同时检测出多个不同类别的物体,并且速度非常快。该算法的核心思想是将目标检测问题转化为一个回归问题,通过一个神经网络直接输出物体的类别、位置和大小等信息。

说明:♨️♨️♨️
论文题目:《You Only Look Once: Unified, Real-Time Object Detection》
论文地址: https://arxiv.org/abs/1506.02640
说明:♨️♨️♨️
关于YOLOv1论文的详细解析,请参考文章:
开山之作 | YOLOv1论文介绍及翻译(纯中文版)
🚀4.YOLOv1技术原理
💥💥4.1 网络结构
YOLOv1网络借鉴了GoogLeNet分类网络结构,不同的是YOLOv1使用1x1卷积层和3x3卷积层替代inception module。如下图所示,整个检测网络包括24个卷积层和2个全连接层。其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。👇

现在看来,YOLOv1的网路结构非常明晰,是一种传统的one-stage的卷积神经网络:
- 网络输入:448×448×3的彩色图片。
- 中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征。
- 全连接层:由两个全连接层组成,用来预测目标的位置和类别概率值。
- 网络输出:7×7×30的预测结果。
💥💥4.2 实现方法
YOLOv1采用的是“分而治之”的策略,将一张图片平均分成7×7个网格,每个网格分别负责预测中心点落在该网格内的目标。回忆一下,在Faster R-CNN中,是通过一个RPN来获得目标的感兴趣区域,这种方法精度高,但是需要额外再训练一个RPN网络,这无疑增加了训练的负担。在YOLOv1中,通过划分得到了7×7个网格,这49个网格就相当于是目标的感兴趣区域。通过这种方式,我们就不需要再额外设计一个RPN网络,这正是YOLOv1作为单阶段网络的简单快捷之处!🔖
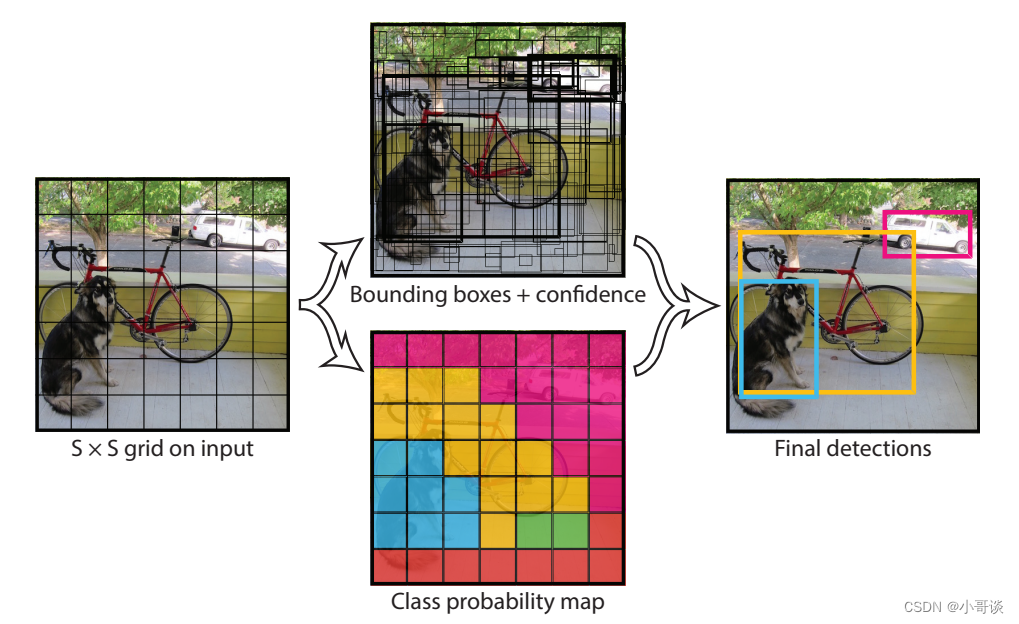
具体实现过程如下:👇
- 将一幅图像分成 S×S个网格(grid cell),如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个object。
- 每个网格要预测 B 个bounding box,每个 bounding box 要预测 (x, y, w, h) 和 confidence 共5个值。
- 每个网格还要预测一个类别信息,记为 C 个类。
- 总的来说,S×S 个网格,每个网格要预测 B个bounding box ,还要预测 C 个类。网络输出就是一个 S × S × (5×B+C) 的张量。在实际过程中,YOLOv1把一张图片划分为了7×7个网格,并且每个网格预测2个Box(Box1和Box2),20个类别。所以实际上,S=7,B=2,C=20。那么网络输出的shape也就是:7×7×30。
说明:♨️♨️♨️
1. 由于输出层为全连接层,因此在检测时,YOLOv1训练模型只支持与训练图像相同的输入分辨率(可以通过reshape的方法把你的照片压缩或扩张成YOLO要求的尺寸)。
2. 虽然每个格子可以预测B个bounding box,但是最终只选择只选择IoU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。
💥💥4.3 训练策略
YOLOv1的训练策略主要包括以下几个方面:👇
-
数据集准备:YOLOv1使用PASCAL VOC数据集进行训练,数据集中包含20个类别的物体,每个物体都有对应的边界框和标签信息。
-
模型设计:YOLOv1采用单个卷积神经网络同时预测物体类别和边界框信息,输出一个S*S(B*5+C)的张量,其中S表示特征图的大小,B表示每个格子预测的边界框数量,C表示物体类别数。
-
损失函数:YOLOv1使用均方误差作为损失函数,同时考虑物体类别预测误差和边界框预测误差。
-
训练过程:YOLOv1采用随机梯度下降算法进行训练,每次随机选择一张图片进行训练,采用多尺度训练和数据增强技术提高模型的泛化能力。
🚀5.YOLOv1性能评价
YOLOv1是一种基于单阶段检测器的目标检测算法,其主要特点是速度快,但精度相对较低。下面是YOLOv1的性能评价:
- 精度:在PASCAL VOC 2012数据集上,YOLOv1的mAP为63.4%,相比于当时的其他目标检测算法,如Faster R-CNN和SSD,精度较低。
- 速度:YOLOv1的速度非常快,可以达到45帧/秒的实时检测速度。
- 目标类别数:YOLOv1最多支持20个目标类别的检测。
综上所述,YOLOv1适用于对实时性要求较高,但对精度要求相对较低的场景,如视频监控等。✅