目录
一、理论
1.K8S集群升级
2.集群概况
3.升级集群
4.验证集群
二、实验
1.升级集群
2.验证集群
三、问题
1.给node1节点打污点报错
一、理论
1.K8S集群升级
(1)概念
搭建K8S集群的方式有很多种,比如二进制,kubeadm,RKE(Rancher)等,K8S集群升级方式也各有千秋,目前准备使用kubeadm方式搭建的k8s集群升级方法。
需要注意的是,升级集群版本建议逐步升级,比如 v1.20.1–>v1.21.1–>v1.22.1–>v1.23.1–>v1.24.1,不能跨度过大,否则会报错。
2.集群概况
表1 集群概况
| 节点名称 | IP | 版本 | 目标版本 |
|---|---|---|---|
| master1 | 192.168.204.180 | v1.20.6 | v1.20.15 |
| master2 | 192.168.204.181 | v1.20.6 | v1.20.15 |
| node1 | 192.168.204.182 | v1.20.6 | v1.20.15 |
3.升级集群
(1)确定升级版本
可以看到目前的版本是v1.20.6。
kubectl get nodes # 查看集群版本NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 94d v1.20.6
master2 Ready control-plane,master 94d v1.20.6
node1 Ready worker 94d v1.20.6# 执行如下命令确定升级版本
yum list --showduplicates kubeadm --disableexcludes=kubernetes……
kubeadm.x86_64 1.20.6-0
kubeadm.x86_64 1.20.7-0
kubeadm.x86_64 1.20.8-0
kubeadm.x86_64 1.20.9-0
kubeadm.x86_64 1.20.10-0
kubeadm.x86_64 1.20.11-0
kubeadm.x86_64 1.20.12-0
kubeadm.x86_64 1.20.13-0
kubeadm.x86_64 1.20.14-0
kubeadm.x86_64 1.20.15-0
……我的目标版本是1.20.15-0。
(2)升级Master
①所有 master 节点操作
# 升级kubeadm
yum install -y kubeadm-1.20.15-0 --disableexcludes=kubernetes # --disableexcludes=kubernetes:禁掉除了这个kubernetes之外的别的仓库
# 升级完成后验证版本
kubeadm version
② 升级 master1 节点
# 验证升级计划。检查当前集群是否可被升级
kubeadm upgrade plan[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks.
[upgrade] Running cluster health checks
[upgrade] Fetching available versions to upgrade to
[upgrade/versions] Cluster version: v1.20.6
[upgrade/versions] kubeadm version: v1.20.6
W1012 13:13:14.679497 7949 version.go:102] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable.txt": Get "https://cdn.dl.k8s.io/rele context deadline exceeded (Client.Timeout exceeded while awaiting headers)
W1012 13:13:14.679539 7949 version.go:103] falling back to the local client version: v1.20.6
[upgrade/versions] Latest stable version: v1.20.6
[upgrade/versions] Latest stable version: v1.20.6
[upgrade/versions] Latest version in the v1.20 series: v1.20.15
[upgrade/versions] Latest version in the v1.20 series: v1.20.15Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
COMPONENT CURRENT AVAILABLE
kubelet 3 x v1.20.6 v1.20.15Upgrade to the latest version in the v1.20 series:COMPONENT CURRENT AVAILABLE
kube-apiserver v1.20.6 v1.20.15
kube-controller-manager v1.20.6 v1.20.15
kube-scheduler v1.20.6 v1.20.15
kube-proxy v1.20.6 v1.20.15
CoreDNS 1.7.0 1.7.0
etcd 3.4.13-0 3.4.13-0You can now apply the upgrade by executing the following command:kubeadm upgrade apply v1.20.15Note: Before you can perform this upgrade, you have to update kubeadm to v1.20.15._____________________________________________________________________The table below shows the current state of component configs as understood by this version of kubeadm.
Configs that have a "yes" mark in the "MANUAL UPGRADE REQUIRED" column require manual config upgrade or
resetting to kubeadm defaults before a successful upgrade can be performed. The version to manually
upgrade to is denoted in the "PREFERRED VERSION" column.API GROUP CURRENT VERSION PREFERRED VERSION MANUAL UPGRADE REQUIRED
kubeproxy.config.k8s.io v1alpha1 v1alpha1 no
kubelet.config.k8s.io v1beta1 v1beta1 no
_____________________________________________________________________
最高可以升级到 v1.20.15 版本,正好与我们的目标版本一致;只要可允许升级的最高版本高于你的目标版本,就可以升级。
注意:kubeadm upgrade命令也会自动对kubeadm在节点上所管理的证书执行续约操作。如果需要略过证书续约操作,可以使用
标志--certificate-renewal=false。确定集群升级目标版本,并且查看升级计划符合条件后,就可以在 master1 节点上执行升级集群的命令了
# 将 master1 升级到目标版本
kubeadm upgrade apply v1.20.15
③ 升级 master2节点
master2节点操作
升级master2节点与 master1 节点相同,但是使用下面的命令,而不是kubeadm upgrade apply命令。
kubeadm upgrade node
④升级kubectl和kubelet
两台 master 节点操作,操作顺序:master1——>master2
分别在两台master节点上执行如下操作,注意更改<节点名称>。
# 1.将当前节点标记为不可调度,并驱逐节点上的Pod
kubectl drain <节点名称> --ignore-daemonsets
##说明:
## --ignore-daemonsets 无视DaemonSet管理下的Pod。即--ignore-daemonsets往往需要指定的,这是
#因为deamonset会忽略unschedulable标签(使用kubectl drain时会自动给节点打上不可调度标签),
#由于deamonset控制器控制的pod被删除后可能马上又在此节点上启动起来,这样就会成为死循环。因此
#这里忽略daemonset。# 2.升级kubelet和kubectl组件
yum install -y kubelet-1.20.15-0 kubectl-1.20.15-0 --disableexcludes=kubernetes
## 说明: --disableexcludes=kubernetes:禁掉除了这个kubernetes之外的别的仓库# 3.重启kubelet
systemctl daemon-reload
systemctl restart kubelet# 4.恢复当前节点上的Pod调度,使其上线
kubectl uncordon <节点名称>
此时查看节点版本,发现两台master节点已经升级完毕。
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 95d v1.20.15
master2 Ready control-plane,master 94d v1.20.15
node1 Ready worker 94d v1.20.15
接下来升级worker节点。
(3) 升级 Worker
工作节点上的升级过程应该一次执行一个节点,或者一次执行几个节点,以不影响运行工作负载所需的最小容量。
由于我的集群中只有一个worker节点,所以这里只在一台机器上操作;如果你的集群中有多个worker节点,每个节点都需要操作。
# 升级kubeadm
yum install -y kubeadm-1.20.15-0 --disableexcludes=kubernetes
# 查看版本
kubeadm version# 升级 node 节点
kubeadm upgrade node# 设置节点不可调度并排空节点。只有1个worker节点时忽略此步,因为可能会报错
kubectl drain node1 --ignore-daemonsets# 升级kubelet和kubectl组件
yum install -y kubelet-1.20.15-0 kubectl-1.20.15-0 --disableexcludes=kubernetes# 重启kubelet
systemctl daemon-reload
systemctl restart kubelet# 恢复当前节点上的Pod调度。只有1个worker节点时忽略此步
kubectl uncordon node1 # node1 为worker节点名称
4.验证集群
(1)验证集群状态是否正常
kubectl get nodes# 结果如下:
[root@master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 95d v1.20.15
master2 Ready control-plane,master 94d v1.20.15
node1 Ready worker 94d v1.20.15
版本均已升级到 v1.20.15。
(2) 验证集群证书是否正常
kubeadm alpha certs check-expiration## 结果如下:
[root@master1 ~]# kubeadm alpha certs check-expiration
Command "check-expiration" is deprecated, please use the same command under "kubeadm certs"
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Oct 11, 2024 05:29 UTC 364d ca no
apiserver Oct 11, 2024 05:28 UTC 364d ca no
apiserver-etcd-client Oct 11, 2024 05:28 UTC 364d etcd-ca no
apiserver-kubelet-client Oct 11, 2024 05:28 UTC 364d ca no
controller-manager.conf Oct 11, 2024 05:29 UTC 364d ca no
etcd-healthcheck-client Oct 11, 2024 05:28 UTC 364d etcd-ca no
etcd-peer Oct 11, 2024 05:28 UTC 364d etcd-ca no
etcd-server Oct 11, 2024 05:28 UTC 364d etcd-ca no
front-proxy-client Oct 11, 2024 05:28 UTC 364d front-proxy-ca no
scheduler.conf Oct 11, 2024 05:29 UTC 364d ca no CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Jul 06, 2033 05:45 UTC 9y no
etcd-ca Jul 06, 2033 05:45 UTC 9y no
front-proxy-ca Jul 06, 2033 05:45 UTC 9y no
[root@master1 ~]#
二、实验
1.升级集群
(1)确定升级版本
可以看到目前的版本是v1.20.6。
执行如下命令确定升级版本
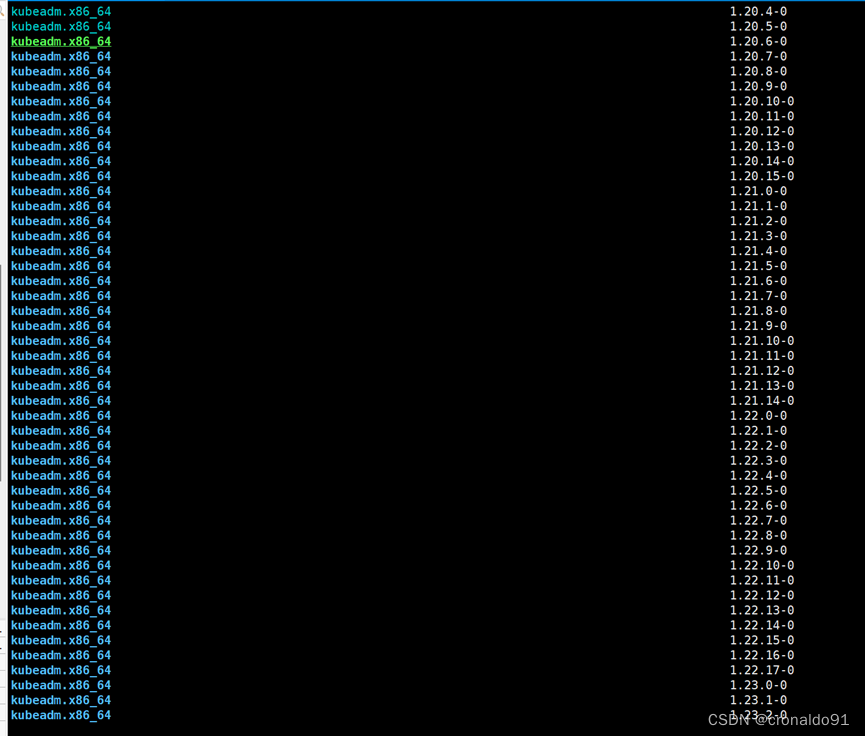
我的目标版本是1.20.15-0。
(2)升级Master
①所有 master 节点操作
升级kubeadm
![]() 升级完成后验证版本
升级完成后验证版本

② 升级 master1 节点
验证升级计划。检查当前集群是否可被升级
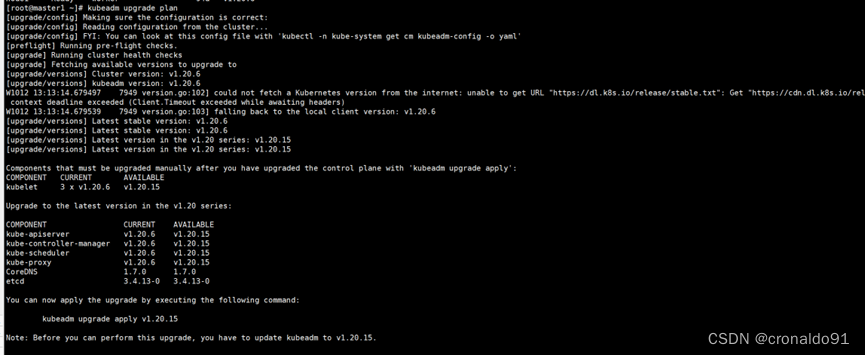
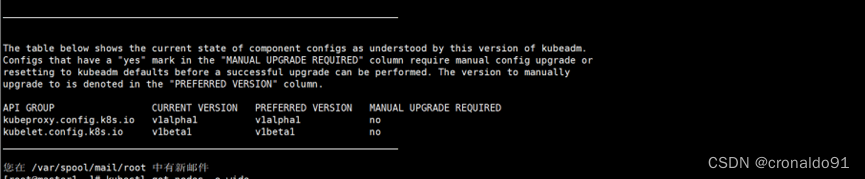
最高可以升级到 v1.20.15 版本,正好与我们的目标版本一致;只要可允许升级的最高版本高于你的目标版本,就可以升级。
注意:kubeadm upgrade命令也会自动对kubeadm在节点上所管理的证书执行续约操作。如果需要略过证书续约操作,可以使用
标志--certificate-renewal=false。确定集群升级目标版本,并且查看升级计划符合条件后,就可以在 master1 节点上执行升级集群的命令了
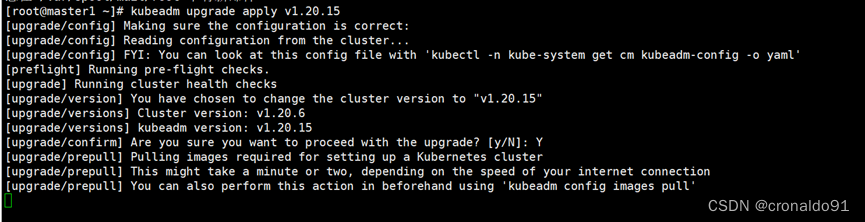
成功
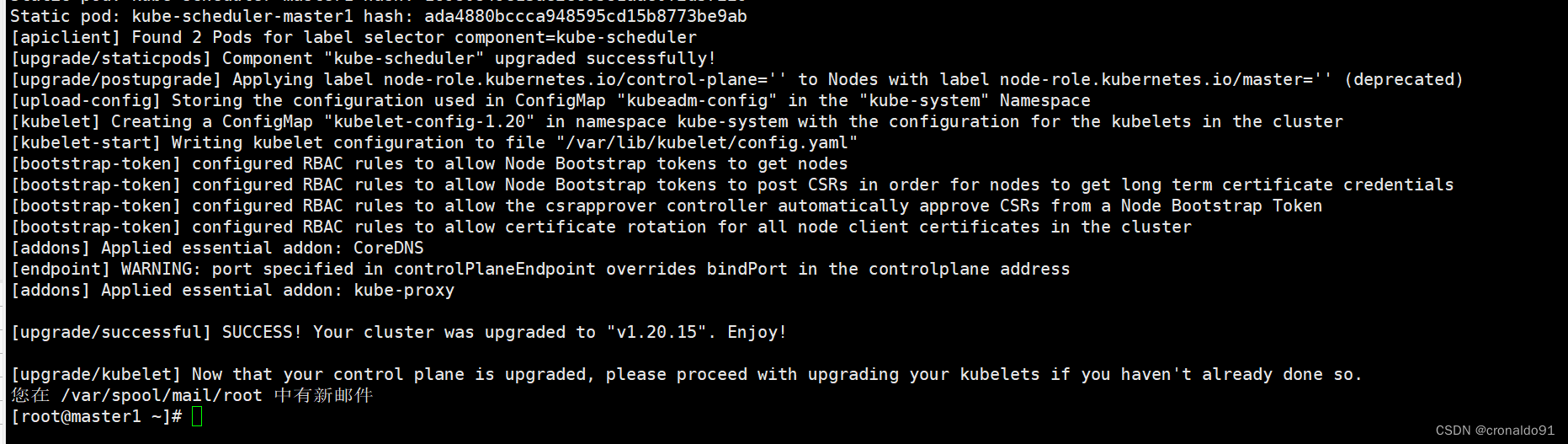
③ 升级 master2节点
master2节点操作
升级master2节点与 master1 节点相同,但是使用下面的命令kubeadm upgrade node
,而不是kubeadm upgrade apply命令。
升级kubeadm

升级完成后验证版本
 升级master2节点
升级master2节点

成功:

④升级kubectl和kubelet
两台 master 节点操作,操作顺序:master1——>master2
分别在两台master节点上执行如下操作,注意更改<节点名称>。
1)master1节点
将当前节点标记为不可调度,并驱逐节点上的Pod

升级kubelet和kubectl组件

重启kubelet

恢复当前节点上的Pod调度,使其上线

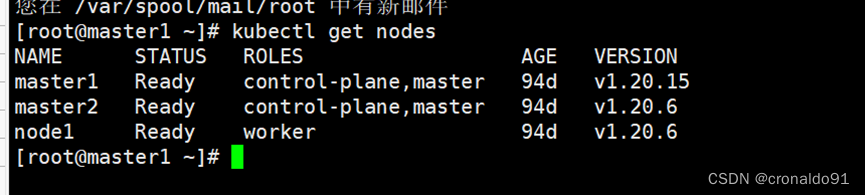
查看节点版本,发现一台master节点已经升级完毕。
2)master2节点
将当前节点标记为不可调度,并驱逐节点上的Pod

升级kubelet和kubectl组件
![]()
重启kubelet

恢复当前节点上的Pod调度,使其上线

此时查看节点版本,发现两台master节点已经升级完毕。

接下来升级worker节点。
(3) 升级 Worker
工作节点上的升级过程应该一次执行一个节点,或者一次执行几个节点,以不影响运行工作负载所需的最小容量。
由于我的集群中只有一个worker节点,所以这里只在一台机器上操作;如果你的集群中有多个worker节点,每个节点都需要操作。
升级kubeadm

查看版本
![]()
升级 node 节点

设置节点不可调度并排空节点。只有1个worker节点时忽略此步,因为可能会报错
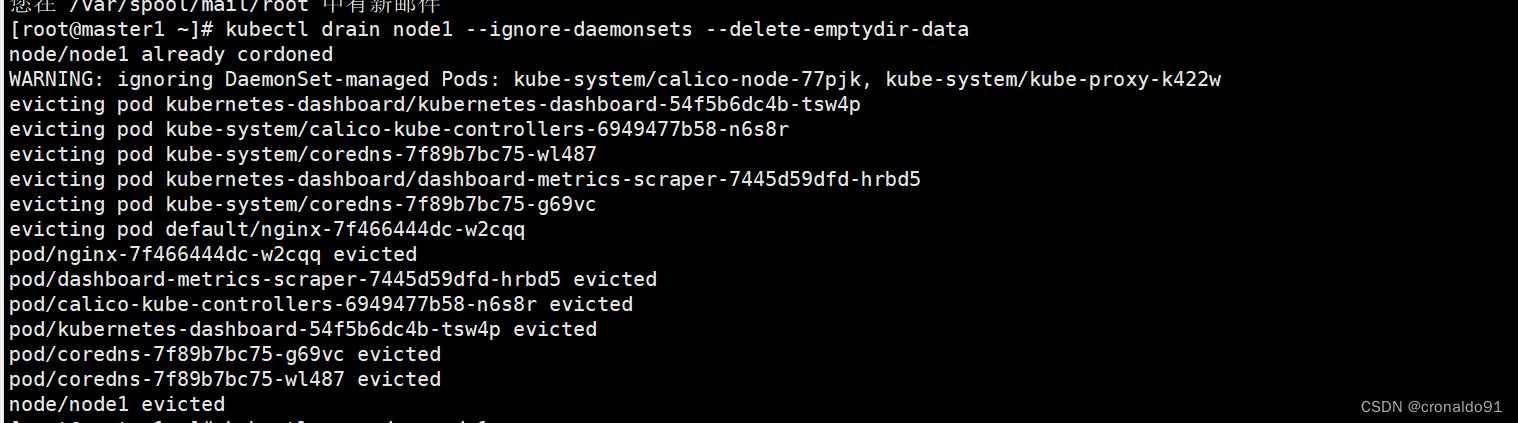
升级kubelet和kubectl组件
![]()
重启kubelet

恢复当前节点上的Pod调度。只有1个worker节点时忽略此步
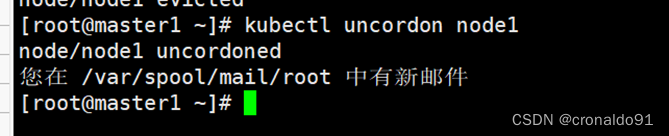
2.验证集群
(1)验证集群状态是否正常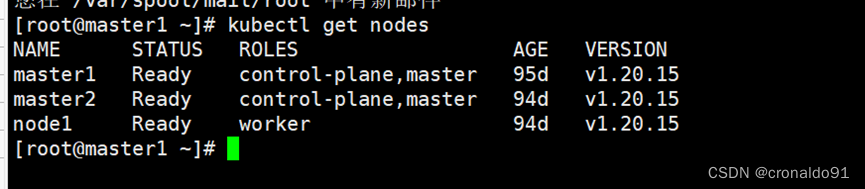
版本均已升级到 v1.20.15。
(2) 验证集群证书是否正常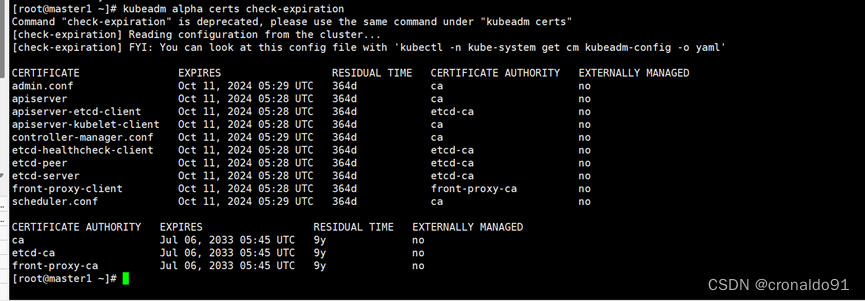
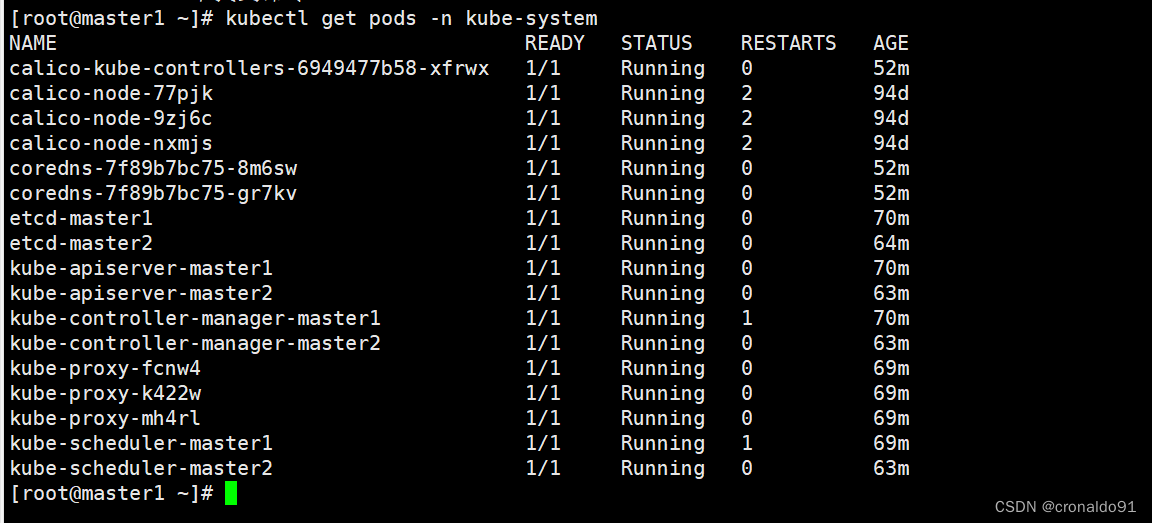
三、问题
1.给node1节点打污点报错
(1)报错

(2)原因分析
有pod在节点存储使用资源,需要驱逐
(3)解决方法
需要命令加上参数 --delete-emptydir-data
如果有mount local volumn的pod,会强制驱逐pod
[root@master1 ~]# kubectl drain node1 --ignore-daemonsets --delete-emptydir-data