Caffeine Cache
高性能的 Java本地缓存库
底层使用 ConcurrentHashMap
TinyLFU
一个近乎最佳的命中率
LRU:最近最少使用算法,每次访问数据都会将其放在我们的队尾,如果需要淘汰数据,就只需要淘汰队首即可。容易导致了热点数据被淘汰。
LFU:最近最少频率使用,利用额外的空间记录每个数据的使用频率,然后选出频率最低进行淘汰。这样就避免了 LRU 不能处理时间段的问题,但实现成本高于lru
虽然命中率很高。但是热点数据访问量太高了,新数据无法淘汰他们,后期访问较多的记录则无法被命中。有一定局限性。
W-TinyLFU
TinyLFU维护了近期访问记录的频率信息,作为一个过滤器,当新记录来时,只有满足TinyLFU要求的记录才可以被插入缓存。如前所述,作为现代的缓存,它需要解决两个挑战:
- 如何避免维护频率信息的高开销
- 如何反应随时间变化的访问模式
W-TinyLFU(Window Tiny Least Frequently Used)是对LFU的的优化和加强。
- 算法:当一个数据进来的时候,会进行筛选比较,进入W-LRU窗口队列,以此应对流量突增,经过淘汰后进入过滤器,通过访问访问频率判决是否进入缓存。如果一个数据最近被访问的次数很低,那么被认为在未来被访问的概率也是最低的,当规定空间用尽的时候,会优先淘汰最近访问次数很低的数据;
- 优点:使用Count-Min Sketch算法存储访问频率,极大的节省空间;定期衰减操作,应对访问模式变化;并且使用window-lru机制能够尽可能避免缓存污染的发生,在过滤器内部会进行筛选处理,避免低频数据置换高频数据。
数据流Sketching技术,使用Count-Min Sketch记录我们的访问频率,
而这个也是布隆过滤器的一种变种
假如我们用一个hashmap来存储每个元素的访问次数,那这个量级是比较大的,并且hash冲突的时候需要做一定处理,否则数据会产生很大的误差,Count-Min Sketch算法将一个hash操作,扩增为多个hash,这样原来hash冲突的概率就降低了几个等级,且当多个hash取得数据的时候,取最低值
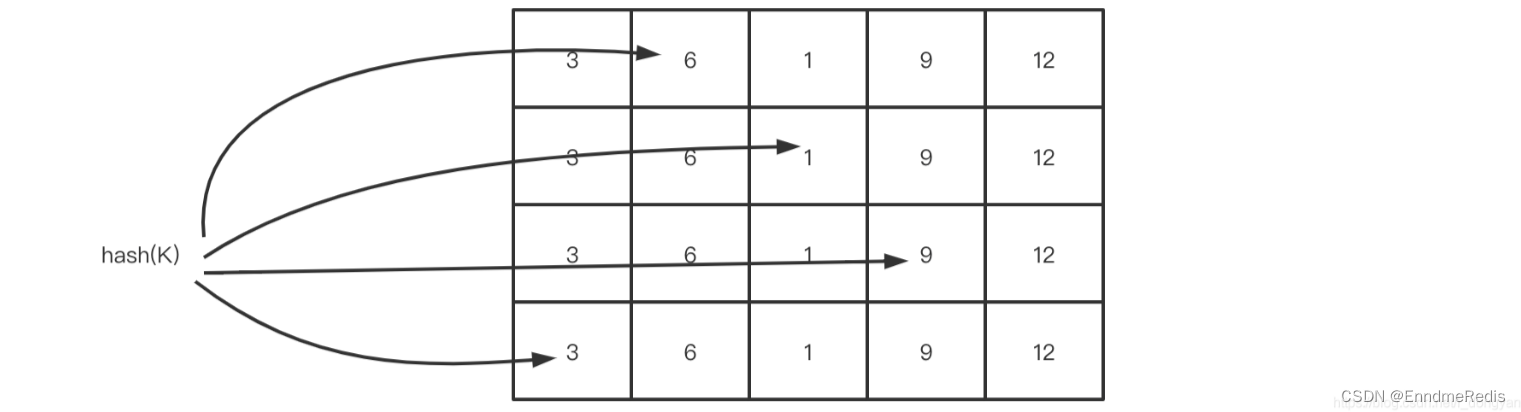
下图展示了Count-Min Sketch算法简单的工作原理:
- 假设有四个hash函数,每当元素被访问时,将进行次数加1;
- 此时会按照约定好的四个hash函数进行hash计算找到对应的位置,相应的位置进行+1操作;
- 当获取元素的频率时,同样根据hash计算找到4个索引位置;
- 取得四个位置的频率信息,然后根据Count Min取得最低值作为本次元素的频率值返回,即Min(Count);
回收策略
Caffeine提供了3种回收策略:基于大小回收,基于时间回收,基于引用回收。
- 基于大小的过期方式
基于大小的回收策略有两种方式:一种是基于缓存大小,一种是基于权重。 - 基于时间的过期方式
- 基于引用的过期方式





![[sqoop]hive导入mysql,其中mysql的列存在默认值列](https://img-blog.csdnimg.cn/7b88c454df43430999a49c43984ea63e.png)