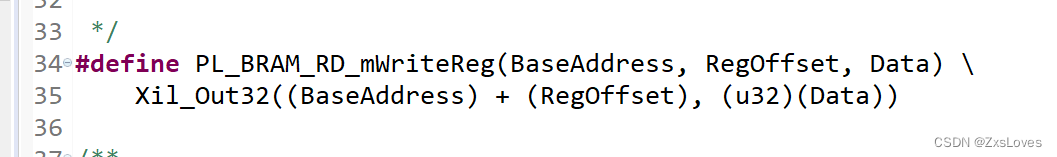基数排序(Radix Sort)是一种非比较性排序算法,它根据元素的每个位上的值来进行排序。基数排序适用于整数或字符串等数据类型的排序。本文将详细介绍基数排序的原理、性能分析及java实现。

基数排序原理
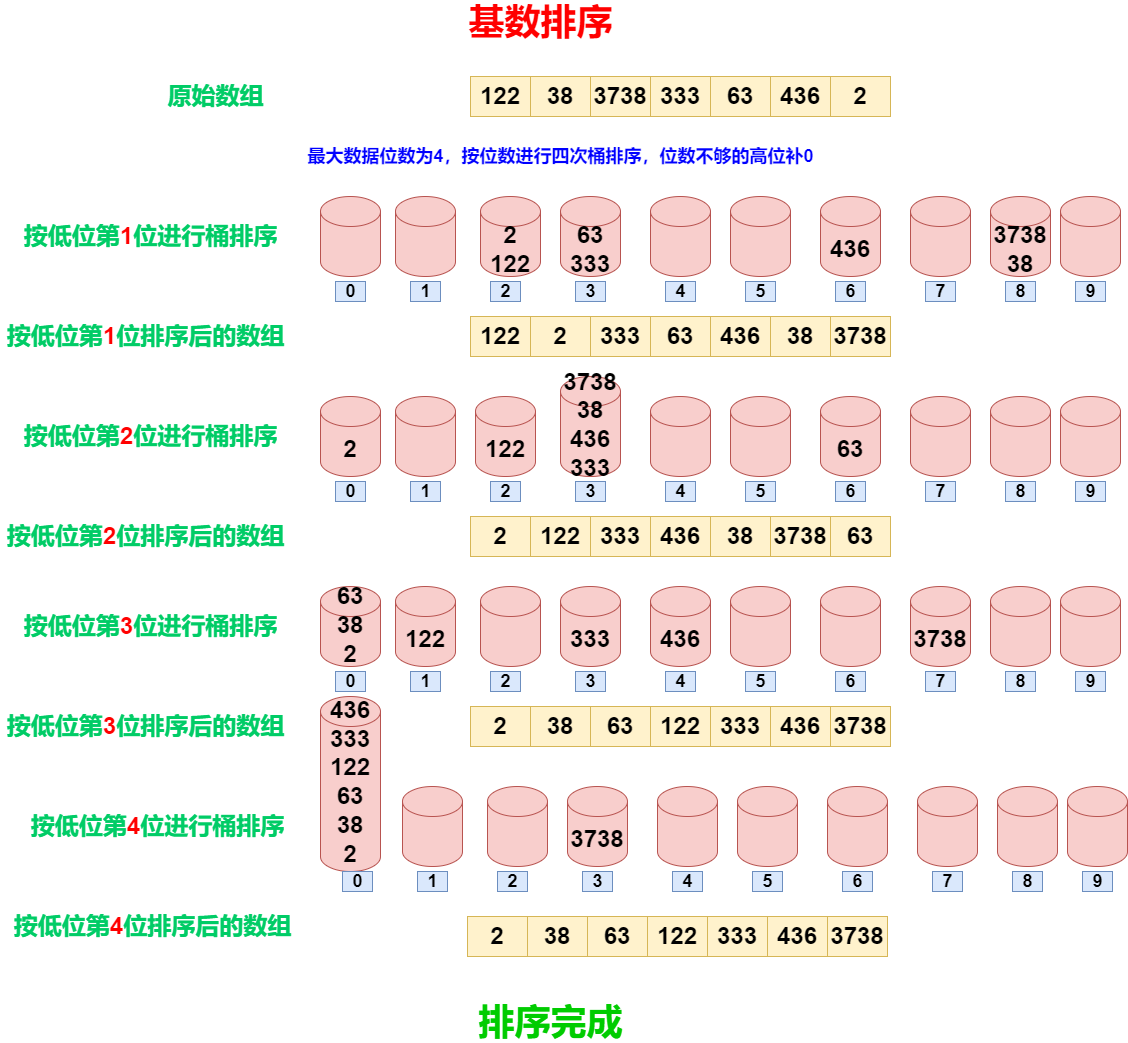
基数排序的基本原理是按照低位先排序,然后收集;再按照高位排序,再收集;以此类推,直到最高位。这样从最低位排序一直到最高位排序完成后,数列就变成一个有序序列。步骤如下:
-
从最低位开始,依次进行一次稳定的计数排序(或桶排序),根据当前位的值将元素分配到不同的桶中。
-
每一轮排序根据当前位的值进行桶排序,保证稳定性。
-
重复以上步骤直到最高位排序完成。
排序图解:
Java代码实现
以下是使用 Java 实现基数排序的示例代码:
public class Test {public static void main(String[] args) {int[] arr = new int[]{122,38,3738,333,63,436,2};System.out.println("原始数组:"+ Arrays.toString(arr));radixSort(arr);System.out.println("排序后的数组:"+ Arrays.toString(arr));}//基基数排序(Radix Sort)public static void radixSort(int[] arr) {//数组为空或者只有一个元素是返回if(arr == null || arr.length < 2){return;}//获取数组中的最大值int maxVal = Arrays.stream(arr).max().getAsInt();//计算最大值的位数int numDig = String.valueOf(maxVal).length();//数组长度int len = arr.length;//位数计数值int dig = 1;//计算每个位数上的数字的被除数int dividend = 1;// 用于存储每个桶中元素的出现次数int[] order = new int[10];// 用于存储每个桶中的数据int[][] tempArr = new int[10][len];//循环每个位数进行桶排序while (dig <= numDig){//将数组中的数据按i位的数据放入桶中for(int i = 0; i < len; i++){//计算当前位数的值int index = (arr[i] / dividend ) % 10 ;tempArr[index][order[index]] = arr[i];//当前位数的桶计数order[index]++;}//给元素中返回数据的下标int l = 0;//将按当前位数进行过桶排序的数据放回到源数组中for (int j = 0; j < order.length; j++){//当前桶中有数据才进行操作if(order[j] > 0){for(int k = 0; k < order[j];k++){arr[l++] = tempArr[j][k];}//将计数数组的值设置为0,方便下一位计数order[j] = 0;}}System.out.println("第"+dig+"位排序后的数组:"+ Arrays.toString(arr));//位数加1,下次进行下一位的排序dig++;//被除数乘以10,方便计算下一位数的值的计算dividend *= 10;}}}输出结果为:
原始数组:[122, 38, 3738, 333, 63, 436, 2]
第1位排序后的数组:[122, 2, 333, 63, 436, 38, 3738]
第2位排序后的数组:[2, 122, 333, 436, 38, 3738, 63]
第3位排序后的数组:[2, 38, 63, 122, 333, 436, 3738]
第4位排序后的数组:[2, 38, 63, 122, 333, 436, 3738]
排序后的数组:[2, 38, 63, 122, 333, 436, 3738]
性能分析
-
时间复杂度:基数排序的时间复杂度通常为 O ( d ∗ ( n + r ) ) O(d * (n + r)) O(d∗(n+r)),其中n是元素数量,d是数字位数,r是基数的大小。通常情况下,基数排序的时间复杂度为线性的,但它依赖于数据位数。如果位数很大,性能可能会受到影响。
-
空间复杂度:基数排序的空间复杂度取决于计数排序的使用情况。在处理较大范围的数据时,空间复杂度可能会较高。
-
稳定性:基数排序通常是稳定的。
实用场景
-
当处理的数据是整数或字符串时,基数排序是一个理想的选择。例如,对于字符串排序,可以按照字符的ASCII码值进行排序。
-
当数据集的位数相对较小且分布较为均匀时,基数排序可以表现出良好的性能。它不依赖于比较操作,因此在一些特定情况下可以优于基于比较的排序算法。
-
在内存充足的情况下,基数排序可以高效地处理大量数据,但在位数非常大的情况下可能会受到内存限制的影响。
总结
综上所述,基数排序是一种高效的排序算法,特别适用于处理位数相对较小且分布较为均匀的整数或字符串。但需要注意,对于位数较大的数据集或内存受限的情况,可能需要考虑其他排序算法来满足要求。



![Flask框架配置celery-[1]:flask工厂模式集成使用celery,可在异步任务中使用flask应用上下文,即拿即用,无需更多配置](https://img-blog.csdnimg.cn/92a5319c10354348b1c7ba2819c89045.png)