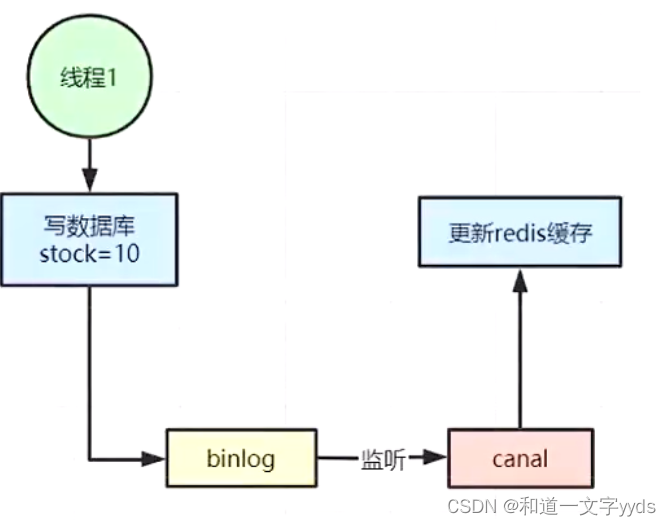
图片来源:维亚切斯拉夫·叶菲莫夫
一、说明
SImilarity 搜索是一个问题,给定一个查询的目标是在所有数据库文档中找到与其最相似的文档。
在数据科学中,相似性搜索经常出现在NLP领域,搜索引擎或推荐系统中,其中需要检索最相关的文档或项目以进行查询。通常,文档或项目以文本或图像的形式表示。但是,机器学习算法不能直接处理原始文本或图像,这就是为什么文档和项目通常被预处理并存储为数字向量的原因。
有时,向量的每个组件都可以存储语义含义。在这种情况下,这些表示也称为嵌入。这样的嵌入可以有数百个维度,它们的数量可以达到数百万个!由于数量如此之大,任何信息检索系统都必须能够快速检测相关文档。
在机器学习中,向量也称为对象或点。
二、索引指数
为了提高搜索性能,在数据集嵌入之上构建了一个特殊的数据结构。这种数据结构称为索引。该领域已经有很多研究,并且已经发展了许多类型的索引。在选择要申请某项任务的索引之前,有必要了解它在引擎盖下的运作方式,因为每个索引都有不同的用途,并且各有优缺点。
在本文中,我们将看看最幼稚的方法 — kNN。基于 kNN,我们将切换到倒排文件 — 用于更具可扩展性的搜索的索引,可以将搜索过程加速数倍。
2.1 kNN
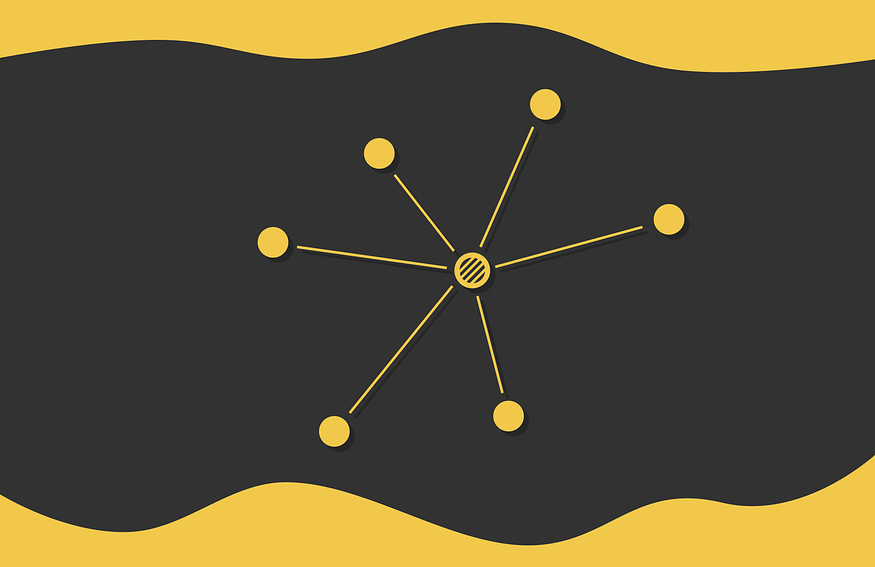
kNN是最简单、最幼稚的相似性搜索算法。考虑一个向量数据集和一个新的查询向量 Q。我们想找到与 Q 最相似的前 k 个数据集向量。要考虑的第一个方面是如何测量两个向量之间的相似性(距离)。事实上,有几个相似性指标可以做到这一点。其中一些如下图所示。
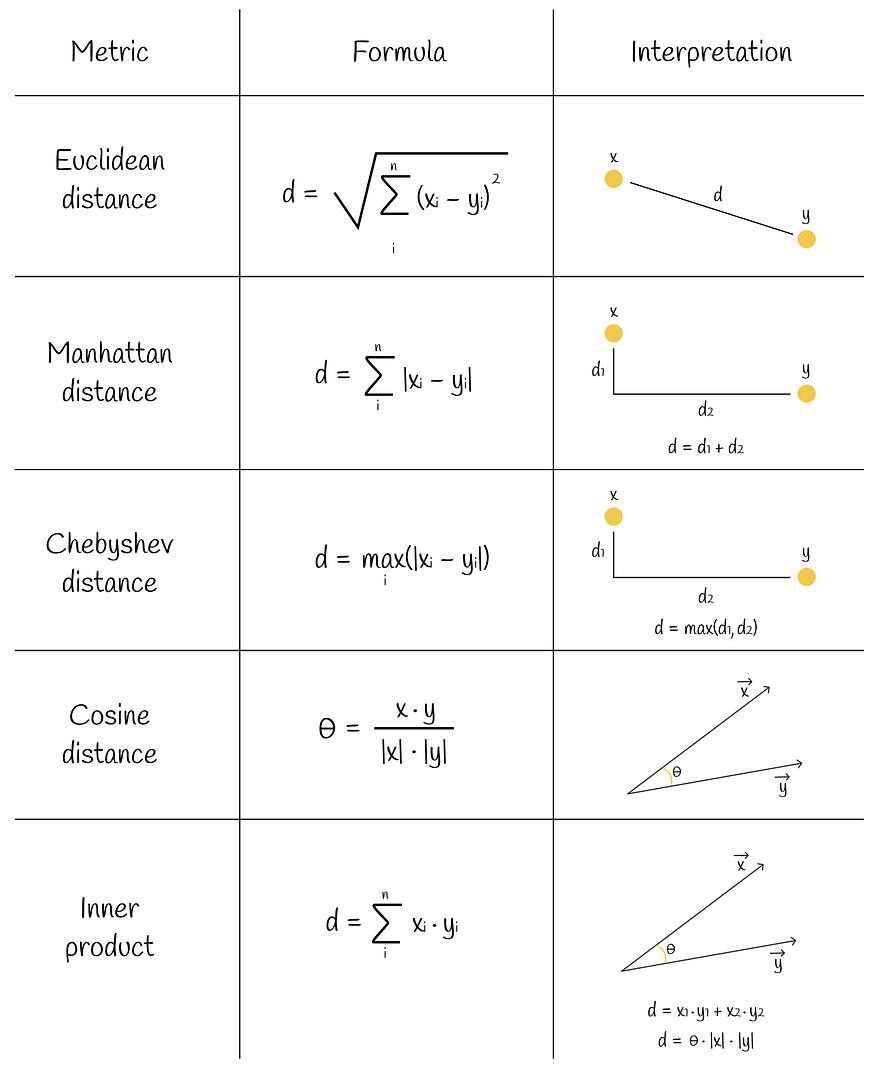
相似性指标
2.2 knn相似性训练和使用
2.2.1 训练
kNN是机器学习中为数不多的不需要训练阶段的算法之一。选择合适的指标后,我们可以直接进行预测。
2.2.2 推理
对于新对象,该算法会详尽地计算到所有其他对象的距离。之后,它找到距离最小的 k 个对象并将它们作为响应返回。
显然,通过检查到所有数据集向量的距离,kNN 保证 100% 准确的结果。但是,就时间性能而言,这种蛮力方法效率非常低。如果数据集由 n 个具有 m 维的向量组成,则对于 n 个向量中的每一个,都需要 O(m) 时间来计算从查询 Q 到它的距离,这会导致 O(mn) 的总时间复杂度。正如我们稍后将看到的,存在更有效的方法。
此外,原始矢量没有压缩机制。想象一个包含数十亿个对象的数据集。将它们全部存储在RAM中可能是不可能的!
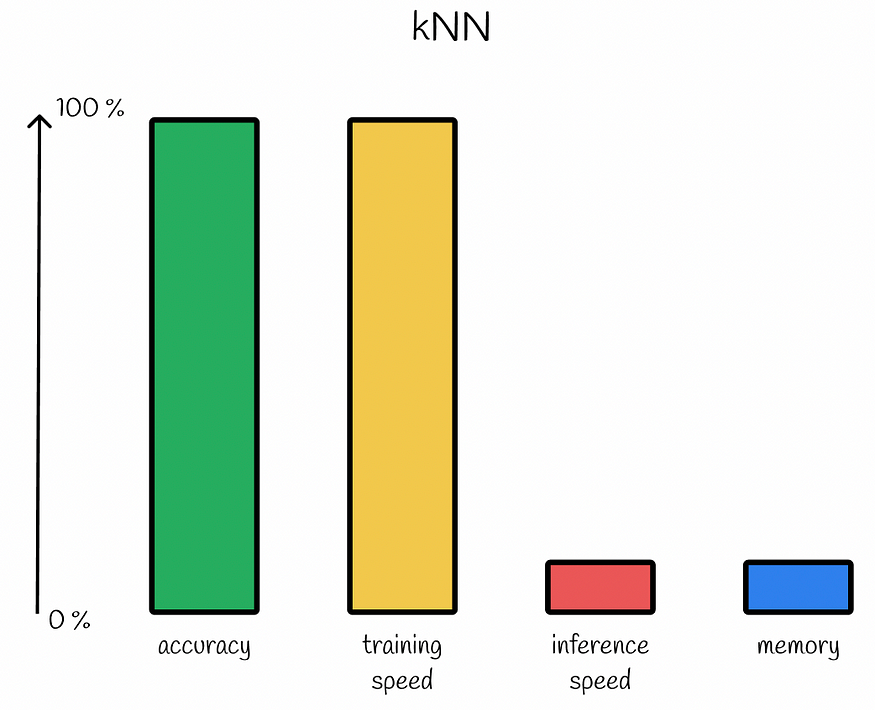
kNN 性能。具有 100% 的准确性且没有训练阶段会导致在向量推理和无内存压缩期间进行详尽搜索。注意:这种类型的图表显示了不同算法的相对比较。根据情况和所选的超参数,性能可能会有所不同。
2.3 如何应用
kNN 的应用范围有限,应仅在以下场景之一中使用:
- 数据集大小或嵌入维度相对较小。这方面确保算法仍然快速执行。
- 算法所需的精度必须为 100%。在准确性方面,没有其他最近邻算法可以超越kNN的性能。
根据一个人的指纹检测一个人是需要100%准确性的问题的一个例子。如果该人犯罪并留下了指纹,则仅检索正确的结果至关重要。否则,如果系统不是100%可靠的,那么另一个人可能会被判犯有罪行,这是一个非常严重的错误。
基本上,有两种主要方法可以改善 kNN(我们将在后面讨论):
- 缩小搜索范围。
- 降低矢量的维数。
使用这两种方法之一时,我们不会再次执行详尽搜索。这种算法被称为近似最近邻(ANN),因为它们不能保证100%准确的结果。
三、倒排文件索引
“倒排索引(也称为帖子列表、帖子文件或倒排文件)是一种数据库索引,存储从内容(如单词或数字)到其在表格、文档或一组文档中的位置的映射” — 维基百科
执行查询时,将计算查询的哈希函数,并从哈希表中获取映射值。这些映射值中的每一个都包含其自己的一组潜在候选项,然后根据条件完全检查这些候选项,使其成为查询的最近邻域。这样,所有数据库向量的搜索范围都会缩小。
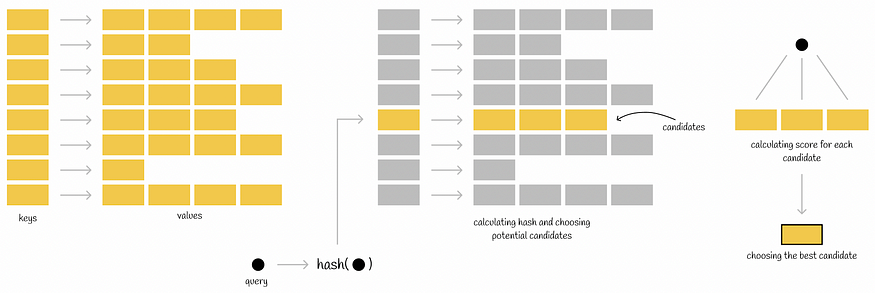
倒排文件索引工作流
此索引有不同的实现,具体取决于哈希函数的计算方式。我们将要研究的实现是使用Voronoi图(或狄利克雷镶嵌)的实现。
3.1 训练
该算法的思想是创建每个数据集点所属的几个非相交区域。每个区域都有自己的质心,指向该区域的中心。
有时沃罗诺伊地区被称为单元或分区。

沃罗诺伊图的示例。白点是包含一组候选项的相应分区的中心。
Voronoi 图的主要性质是,从一个质心到其区域的任何一点的距离小于从该点到另一个质心的距离。
3.2 推理
当给定一个新对象时,将计算到Voronoi分区的所有质心的距离。然后选择距离最小的质心,然后将该分区中包含的向量作为候选。
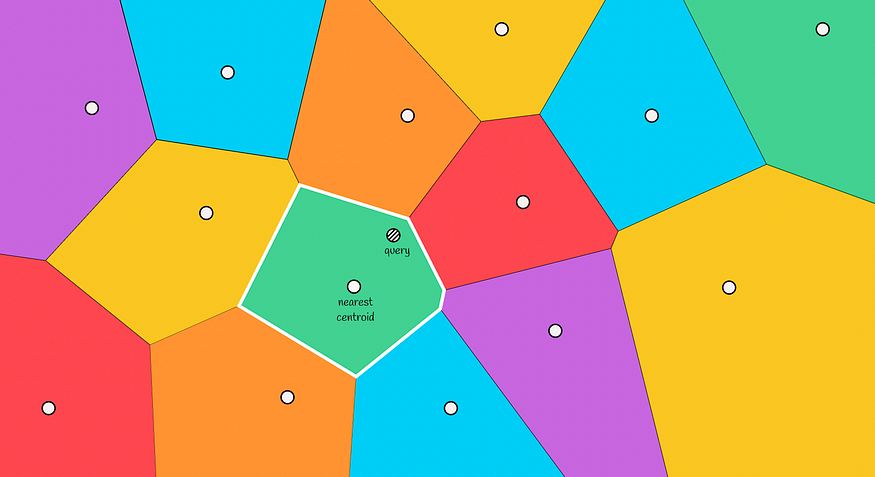
通过给定的查询,我们搜索最近的质心(位于绿色区域)
最终,通过计算到候选人的距离并选择离候选人最近的前 k 个,返回最终答案。
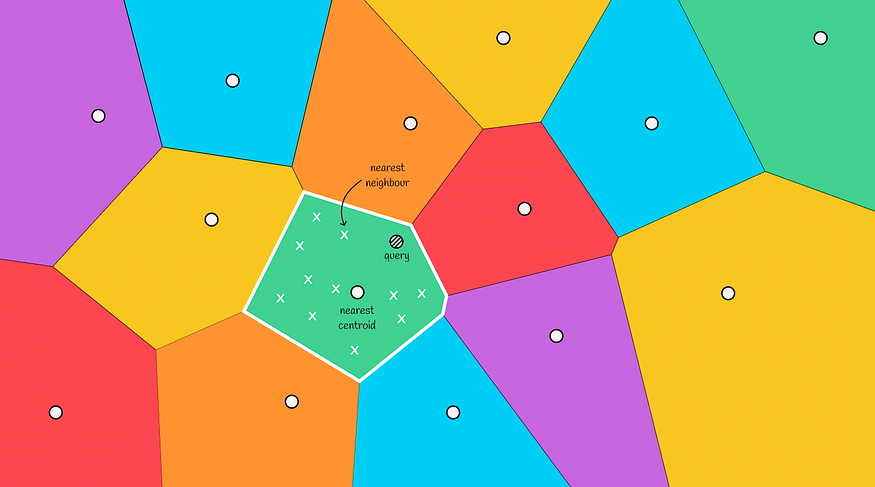
查找所选区域中最近的邻居
如您所见,这种方法比前一种方法快得多,因为我们不必查看所有数据集向量。
3.3 边缘问题
随着搜索速度的提高,反转文件有一个缺点:它不能保证找到的对象始终是最近的。
在下图中,我们可以看到这样的场景:实际的最近邻位于红色区域,但我们仅从绿色区域中选择候选人。这种情况称为边缘问题。
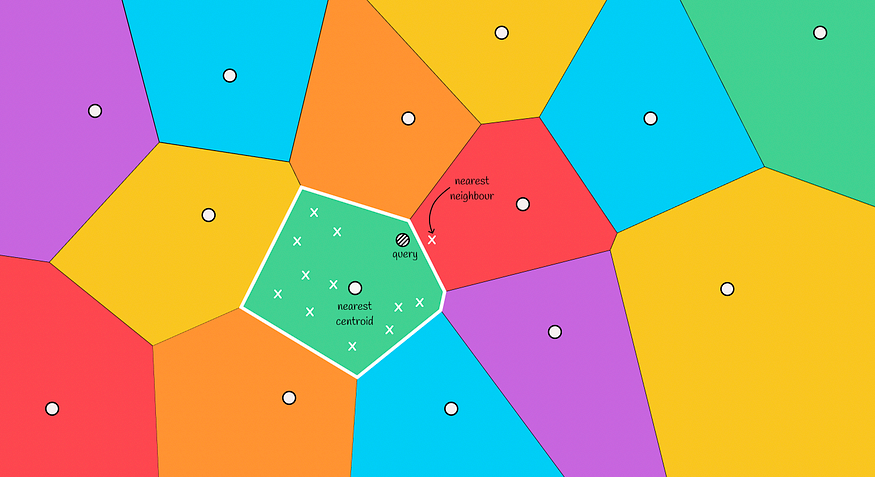
边缘问题
当查询的对象位于与另一个区域的边界附近时,通常会发生这种情况。为了减少这种情况中的错误数量,我们可以增加搜索范围,并根据最接近对象的前 m 个质心选择几个区域来搜索候选者。
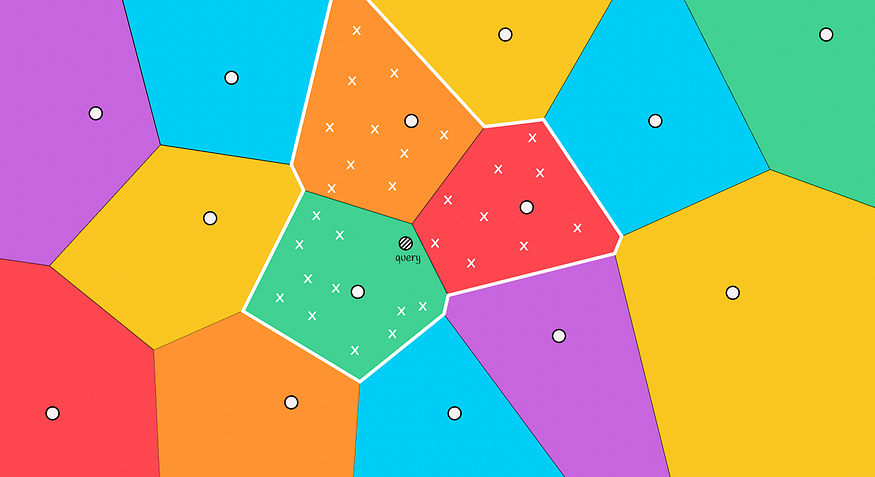
在多个区域内搜索最近的邻居 (m = 3)
探索的区域越多,结果就越准确,计算它们所需的时间就越多。
3.4 应用
尽管存在边缘问题,但反转文件在实践中显示出不错的结果。在我们想要权衡精度略有下降以实现多次速度增长的情况下,它是完美的选择。
其中一个用例示例是基于内容的推荐系统。想象一下,它根据用户过去看过的其他电影向用户推荐一部电影。该数据库包含一百万部电影可供选择。
- 通过使用kNN,系统确实为用户选择了最相关的电影并推荐它。但是,执行查询所需的时间很长。
- 让我们假设使用倒排文件索引,系统会推荐第 5 部最相关的电影,这在现实生活中可能就是这种情况。搜索时间比 kNN 快 20 倍。
从用户体验来看,很难区分这两个推荐的质量结果:第 1 和第 5 个最相关的结果都是来自一百万个可能的电影的好推荐。用户可能会对这些建议中的任何一个感到满意。从时间的角度来看,倒置文件显然是赢家。这就是为什么在这种情况下最好使用后一种方法。
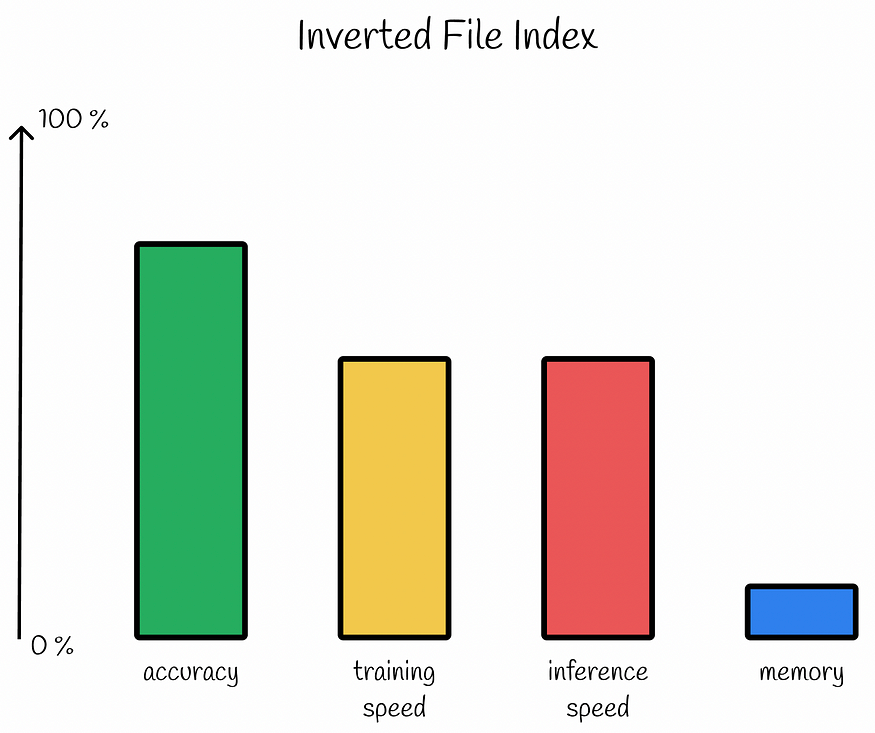
倒排文件索引性能。在这里,我们略微降低了在推理过程中实现更高速度的精度。
四、Faiss库实施
Faiss(Facebook AI Search Similarity)是一个用C++编写的Python库,用于优化的相似性搜索。该库提供了不同类型的索引,这些索引是用于有效存储数据和执行查询的数据结构。
根据 Faiss 文档中的信息,我们将了解如何创建和参数化索引。
4.1 实现kNN
实现 kNN 方法的索引在 Faiss 中被称为平面索引,因为它们不压缩任何信息。它们是保证正确搜索结果的唯一索引。实际上,Faiss中存在两种类型的平面索引:
- 索引平L2.相似性计算为欧几里得距离。
- 索引平面IP。相似性计算为内积。
这两个索引都需要在其构造函数中包含一个参数 d:数据维度。这些索引没有任何可调参数。
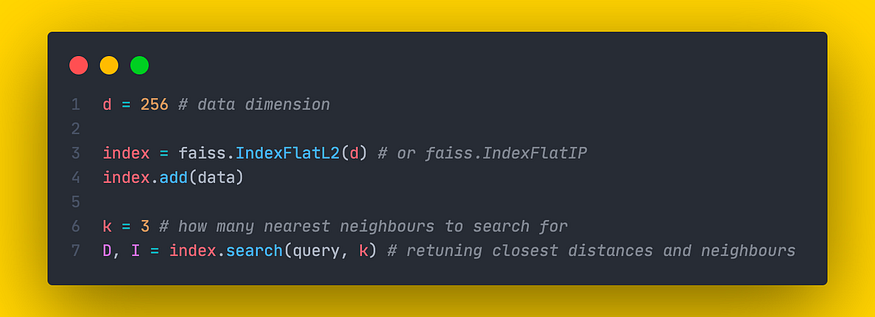
IndexFlatL2 和 IndexFlatIP 的 Faiss 实现
存储矢量的单个分量需要 4 个字节。因此,要存储维度为 d 的单个向量,需要 4 * d 字节。
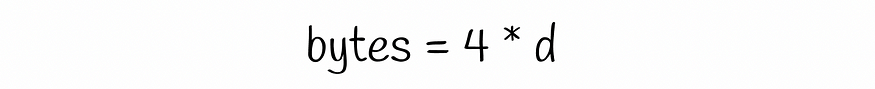
4.2 倒排文件索引
对于描述的倒置文件,Faiss 实现了类 IndexIVFFlat。与 kNN 的情况一样,单词“Flat”表示原始向量没有解压缩并且它们已完全存储。
要创建此索引,我们首先需要传递一个量化器 — 一个确定如何存储和比较数据库向量的对象。
IndexIVFFlat 有 2 个重要参数:
- nlist:定义训练期间要创建的多个区域(Voronoi 单元)。
- nprobe:确定搜索候选项的区域数。更改 nprobe 参数不需要重新训练。
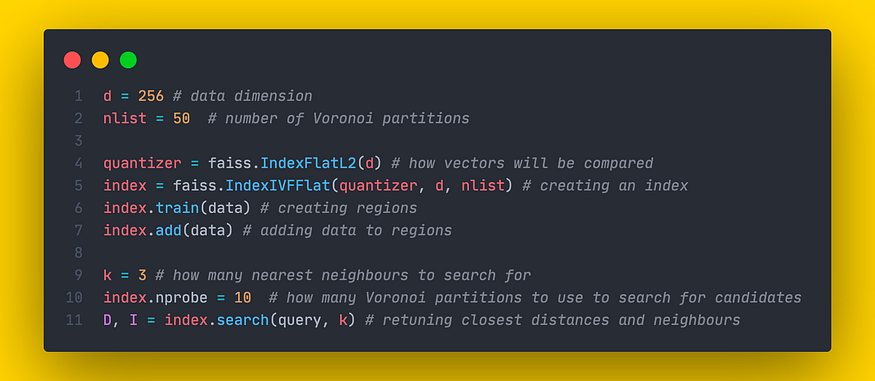
Faiss 实现 IndexIVFFlat
与前面的情况一样,我们需要 4 * d 字节来存储单个向量。但是现在我们还必须存储有关数据集向量所属的Voronoi区域的信息。在 Faiss 实现中,此信息每个向量占用 8 个字节。因此,存储单个向量所需的内存为:
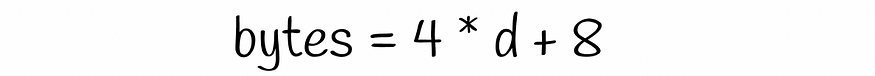
五、结论
我们已经在相似性搜索中经历了两种基本算法。实际上,朴素的kNN几乎不应该用于机器学习应用程序,因为它的可扩展性很差,除非在特定情况下。另一方面,反转文件为加速搜索提供了良好的启发式方法,可以通过调整其超参数来提高其质量。仍然可以从不同的角度增强搜索性能。在本系列文章的下一部分中,我们将介绍一种旨在压缩数据集向量的方法。
系列下篇:相似性搜索:第 2 部分:产品量化_无水先生的博客-CSDN博客
参考资源
- 倒排索引 |维基百科
- 费斯文档
- 费斯存储库
- 费斯指数摘要
- 选择索引的准则