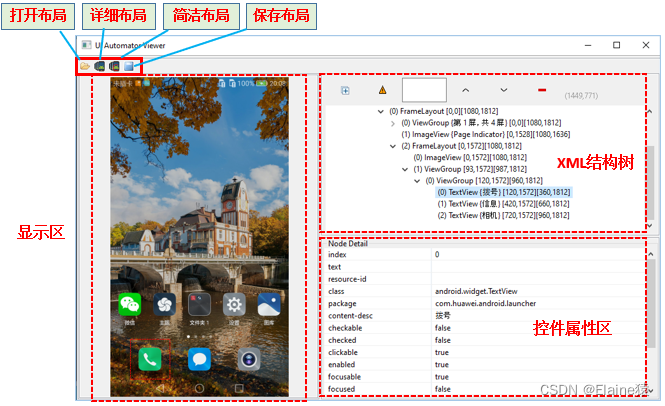
1.数组名的理解
一般数组名就是数组首元素的地址
但是有2个例外:1.sizeof(数组名) 这里面数组名表示的是整个数组,计算整个数组的大小,单位为字节。 2.&数组名 这里面数组名代表的是整个数组,&数组名取出的是整个数组的地址。 除此之外,遇到的所有数组名中都是数组首元素的地址
2.使用指针访问数组
我们可以使用指针输入和输出数组

用指针打印数组很简单,但是我们扩展一些知识。在我们打印数组时,我们可以用很多形式。比如printf("%d",arr[i]),printf("%d",*(arr+i))。这两种写法都可以,说明arr[i]==*(arr+i),也就是arr[i]本质上是等价于*(arr+i)。数组元素的访问在编译器处理的时候,也是转换成⾸元素的地址+偏移量求出元素的地址,然后解引⽤来访问的。 所以arr[i]只是一种形式。
由此类推,arr[i]=*(arr+i)=*(i+arr)=i[arr](交换律)。我们不论写成什么形式都是正确的。
3.一维数组传参的本质
我们通过一个例子了解一下。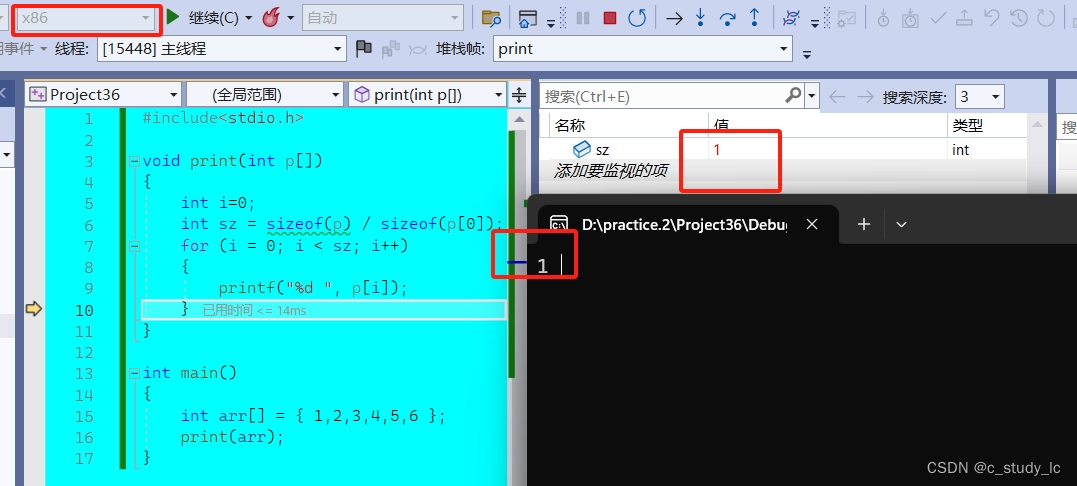
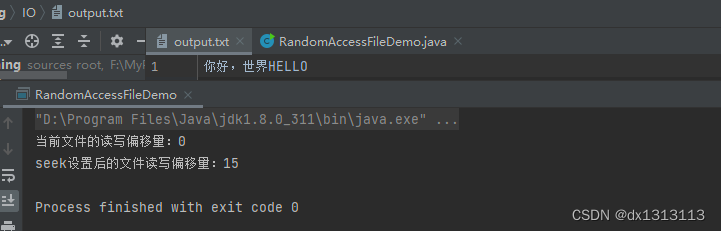
通过上面代码发现,我们sz=1,如果我们想正确打印数组,sz应该为6,那为什么sz算出来呢?
因为我们发现print(arr)传的时候里面的‘arr’既没有&,又没有sizeof,所以这里的‘arr'指的就是数组首元素地址。那我们形参接受的时候为什么是int p[ ]呢?我们上面说过,arr[i]只是一种形式,它在本质上等价于*(arr+i),所以int p[ ]==int* p。由此可知,我们传到函数去的是地址。所以sizeof(p)中的'p'是指针变量p,所以sizeof(p)=4,又sizeof(p[0])=sizeof(*p)=4,所以sz=4/4=1。这样循环就只进行了一次,所以只打印了'1'。
总结:一维数组传参类似传址调用,传的是数组首元素地址,而不是所有元素。
那不禁有人要问,既然传的是首元素地址,为什么能打印整个数组呢?请看下面代码

4. 冒泡排序
核心思想:两两相邻的数字进行比较。比如一个数组arr [ ]={1,4,5,7,3};一次冒泡排序后变为{1,4,5,3,7}。就像下面这个例子一样

假设一个数组有x个元素,则需要排x-1次,每次选出一个最大值,然后继续挑出除了上一次最大值剩下的值中的最大值。如arr [ ]={1,4,5,7,3},第一次挑出了7,为arr [ ]={1,4,5,3,7}。第二次挑出5,为arr [ ]={1,4,3,5,7}。第三次挑出4,为arr [ ]={1,3,4,5,7}…最后,我们数组就从左到右以小到大的顺序排列了。代码如下(优化后)
5. ⼆级指针
我们知道存放地址的是指针变量,那指针变量也是变量,它也有地址,那它的地址又存放在哪呢?答案是存放在二级指针里面。
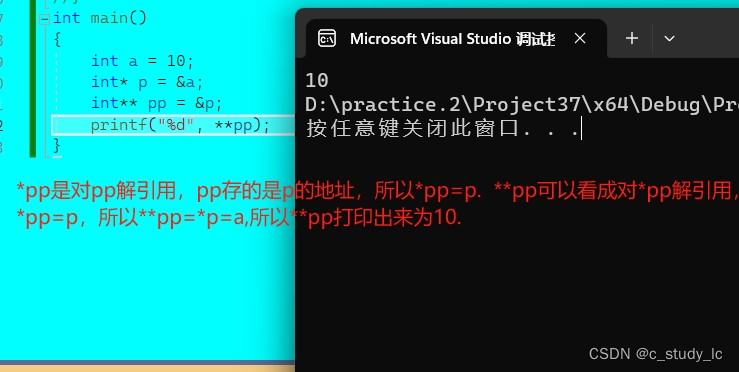
以此类推,int***pp就是三级指针了,用于存放二级指针地址
6. 指针数组
指针数组顾名思义就是存放指针的数组,里面存放的元素就是地址。指针每个元素是地址,又可以指向另一块区域


7. 指针数组模拟⼆维数组

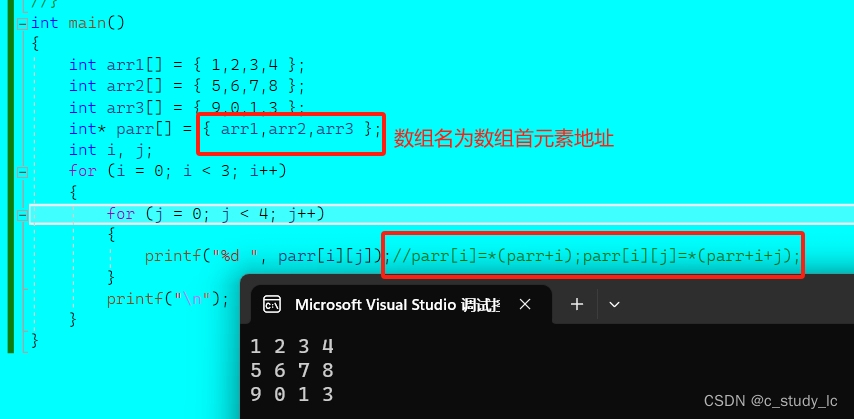
parr[i]是访问parr数组的元素,parr[i]找到的数组元素指向了整型⼀维数组,parr[i][j]就是整型⼀维数 组中的元素。 上述的代码模拟出⼆维数组的效果,实际上并⾮完全是⼆维数组,因为每⼀⾏并⾮是连续的。