TensorFlow在图像识别方面,提供了多个开源的训练数据集,比如CIFAR-10数据集、FASHION MNIST数据集、MNIST数据集。

CIFAR-10数据集有10个种类,由6万个32x32像素的彩色图像组成,每个类有6千个图像。6万个图像包含5万个训练图像和1万个测试图像。

FASHION MNIST数据集由衣服、鞋子等服饰组成,包含7万张图像,其中6万张训练图像加1万张测试图像,图像大小为28x28像素,都为单通道,共分10个类。
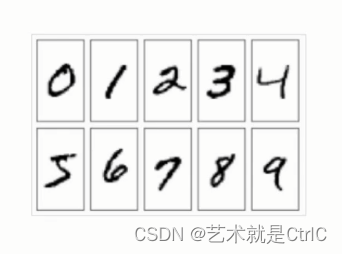
MNIST数据集是一个入门级的计算机视觉数据集,一共6万张训练图像和1万张测试图像,共有数字0-9共10个类别,包含了各种手写数字图片及每一张图片对应的标签。标签主要告诉我们每个图片中的数字是哪一个数字。
识别模糊手写图片的代码逻辑步骤包含:
①导入MNIST数据集
获得MNIST数据集有两种方法:
第一种是从MNIST数据集的官网获取,登录后手动下载
训练集图片文件信息格式如下:
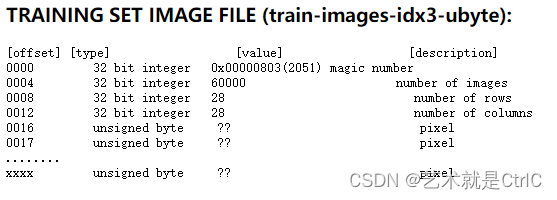
文件头信息包含4个unsinged int32整型数据,分别是魔数(magic number)、图片数、图片宽度、图片长度。其中魔数的值是0x00000803,转换成十进制是2051,数据存储的位置是0016,从0016开始后面的数据是所有图像的像素,每个byte一个像素点。图片的长度都是28,所以每张图片长度为20*28=784,每个像素点的取值范围是0~255。

如果训练集图片文件是黑白的图片,图片中黑色的地方数值为0;有图案的地方,数值为0~255之间的数字,数字的大小代表其颜色的深度。如果是彩色的图片,一个像素会由3个值来表示RGB(红、黄、蓝)。
训练集标签文件信息格式如下:

文件头信息包含2个unsinged int32整型数据,分别是魔数(magic number)、标签数。其中魔数的值是0x00000801,转换成十进制是2049。数据存储的位置是0008,从0008开始,后面的数据是所有的标签值。标签值的取值范围是0~9。
第二种是使用TensorFlow提供的库,直接自动下载与安装MNIST
示例代码如下:
import tensorflow as tf
import matplotlib.pyplot as plt
import tensorflow.keras as keras
(train_images,train_labels),(test_images,test_labels) = keras.datasets.mnist.load_data()print(train_images.shape,train_labels.shape)
print(train_labels[:3])
train_labels = tf.one_hot(train_labels,depth = 10)
print(train_labels[:3])plt.imshow(train_images[0])
plt.show()
plt.imshow(train_images[1])
plt.show()
plt.imshow(train_images[2])
plt.show()
plt.imshow(train_images[3])
plt.show()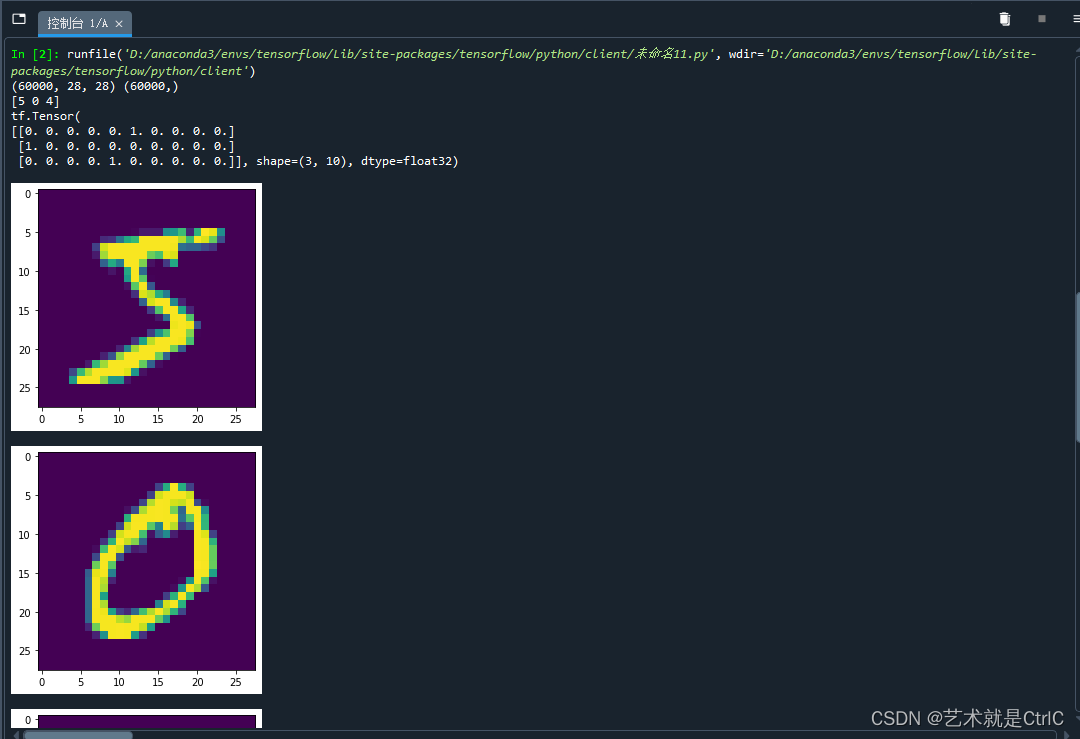

②分析MNIST样本特点
③构建模型
构建模型的代码示例如下:
model = keras.Sequential()model.add(keras.layers.Flatten(input_shape = (28,28)))model.add(keras.layers.Dense(128,activation = tf.nn.relu))model.add(keras.layers.Dense(10,activation = tf.nn.softmax))先使用序贯模型创建一个Sequential对象,通过add方法为对象添加了三个卷积层:
第一层是接受输入层,因minst数据集中图片的像素大小为28*28,因此将接受到的输入展平为一维向量28*28=784,获得图片输入
第二层是中间层,设置共有128个神经元,激活函数是relu
第三层是输出层,因为要分的类别为0~9,共10个,所以这里设置神经元为10个,激活函数是softmax
激活函数relu示意图如下
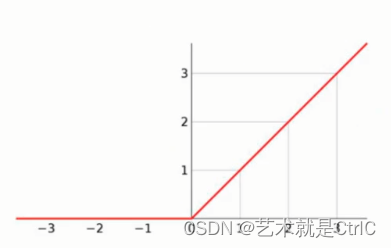
relu函数 : 只有当输入的值是正数时,才会有相应的输出。如果输入的是负数,不论输入多大,输出总是0。
激活函数softmax示意图如下
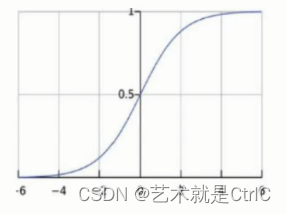
softmax函数 : 不论输入值的大小,把输出值压缩在0~1之间。
import tensorflow as tf
import tensorflow.keras as keras(train_images,train_labels),(test_images,test_labels) = keras.datasets.mnist.load_data()model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape = (28,28)))
model.add(keras.layers.Dense(128,activation = tf.nn.relu))
model.add(keras.layers.Dense(10,activation = tf.nn.softmax))
model.summary()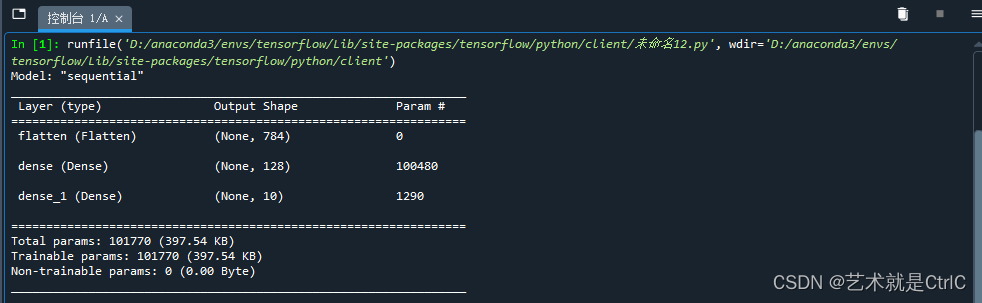
中间层是100480。每个图片展平后是784个元素,784*128个神经元等于100352。因为模型自动为输入层和中间层加了一个bias,相当于一个截距。所以最终等于(784+1)再乘以128,正好等于100480。同样的道理,输出层的1290等于128个神经元+1后乘以10计算所得。这种输入层加一个bias,中间层加一个bias。输出层分为10个类别的网络结构,也叫作全连接网络结构。
④训练模型并输出中间状态参数
train_images = train_images/255.0
#指定优化的方法、损失函数和训练时的精度
model.compile(optimizer = "adam",loss = "sparse_categorical_crossentropy",metrics = ["accuracy"])
#用测试数据集训练,训练5轮
model.fit(train_images,train_labels,epochs = 5,callbacks = [callbacks])
#用evaluate函数评估成效、模型的效果
test_images = test_images/255.0
model.evaluate(test_images,test_labels)一共分为三步:
第一步:指定优化的方法、损失函数和训练时的精度
第二步:用测试数据集进行训练,这里设置训练5轮
第三步:用evaluate函数评估训练的成效和模型的效果
第一步中的adam是常用的优化方法。当输出的数据是类别且需要判断类别时,需要用Categorical。Categorical分为SparseCategoricalCrossentropy()与CategoricalCrossentropy()两种:目标是one-hot编码,比如二分类[0,1][1,0]时,损失函数用categorical_crossentropy;目标是数字编码,比如二分类0,1,损失函数用sparse_categorical_crossentropy。因为现在label是整数9,所以就用sparse_categorical_crossentropy。
为了让训练的效果更好,可以对输入的数据做归一处理,将数据变成0~1之间的数。
import tensorflow as tf
import tensorflow.keras as keras(train_images,train_labels),(test_images,test_labels) = keras.datasets.mnist.load_data()model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape = (28,28)))
model.add(keras.layers.Dense(128,activation = tf.nn.relu))
model.add(keras.layers.Dense(10,activation = tf.nn.softmax))#归一化
train_images = train_images/255.0
#指定优化的方法、损失函数和训练时的精度
model.compile(optimizer = "adam",loss = "sparse_categorical_crossentropy",metrics = ["accuracy"])
#用训练数据集训练,训练5轮
model.fit(train_images,train_labels,epochs = 5)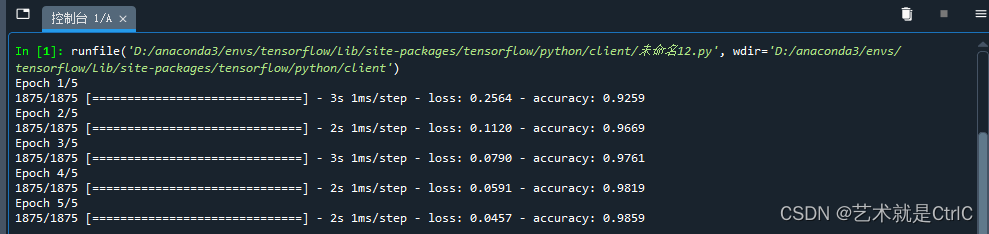
⑤测试模型
测试模型的代码示例如下:
test_images = test_images/255.0
#用evaluate函数评估成效、模型的效果
model.evaluate(test_images,test_labels)示例代码如下:
import tensorflow as tf
import tensorflow.keras as keras(train_images,train_labels),(test_images,test_labels) = keras.datasets.mnist.load_data()model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape = (28,28)))
model.add(keras.layers.Dense(128,activation = tf.nn.relu))
model.add(keras.layers.Dense(10,activation = tf.nn.softmax))#归一化
train_images = train_images/255.0
#指定优化的方法、损失函数和训练时的精度
model.compile(optimizer = "adam",loss = "sparse_categorical_crossentropy",metrics = ["accuracy"])#用训练数据集训练,训练5轮
model.fit(train_images,train_labels,epochs = 5)#归一化
test_images = test_images/255.0
#用evaluate函数评估成效、模型的效果
model.evaluate(test_images,test_labels)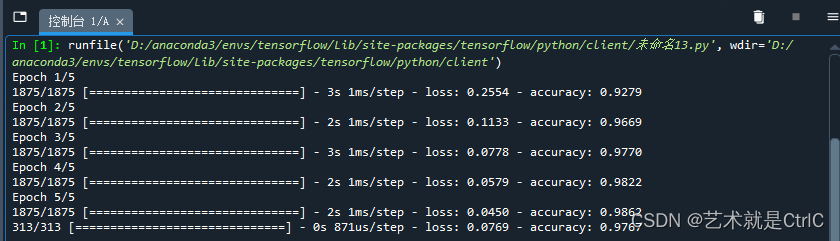
过拟合
过拟合就是神经网络模型对它判别过的图片识别得很准确,但对新的图片识别得很差
当训练时候的损失loss和测试时候的损失loss出现分叉的时候,过拟合现象就出现了
在训练过程中,需要设置一些条件,及时终止训练,防止过拟合现象的发生。这些条件可以通过Python代码自定义为一个回调类,生成一个实例;也可以直接使用TensorFlow的回调函数callbacks;在使用model.fit方法训练模型时,作为参数,传递给callbacks,从而使得程序在满足条件后终止训练。
示例代码如下:
import tensorflow as tf
import tensorflow.keras as kerasclass myCallback(keras.callbacks.Callback):def on_epoch_end(self,epoch,logs = {}):if (logs.get("loss") < 0.4):self.model.stop_training-Truecallbacks = myCallback()(train_images,train_labels),(test_images,test_labels) = keras.datasets.mnist.load_data()model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape = (28,28)))
model.add(keras.layers.Dense(128,activation = tf.nn.relu))
model.add(keras.layers.Dense(10,activation = tf.nn.softmax))#归一化
train_images = train_images/255.0
#指定优化的方法、损失函数和训练时的精度
model.compile(optimizer = "adam",loss = "sparse_categorical_crossentropy",metrics = ["accuracy"])#用训练数据集训练,训练5轮
model.fit(train_images,train_labels,epochs = 5,callbacks = [callbacks])#归一化
test_images = test_images/255.0
#用evaluate函数评估成效、模型的效果
model.evaluate(test_images,test_labels)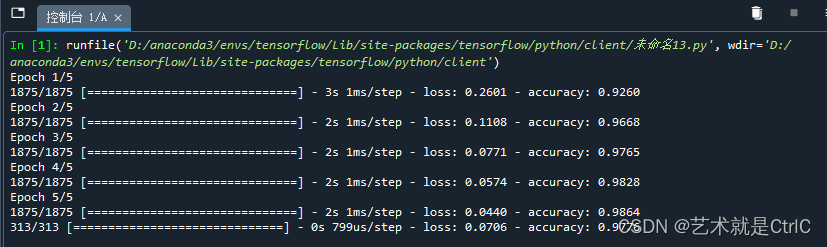
我们也可以稍微改下代码,使数据可视化
示例代码如下:
import tensorflow as tf
import matplotlib.pyplot as plt
import tensorflow.keras as kerasclass myCallback(keras.callbacks.Callback):def on_epoch_end(self,epoch,logs = {}):if (logs.get("loss") < 0.4):self.model.stop_training-Truecallbacks = myCallback()(train_images,train_labels),(test_images,test_labels) = keras.datasets.mnist.load_data()model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape = (28,28)))
model.add(keras.layers.Dense(128,activation = tf.nn.relu))
model.add(keras.layers.Dense(10,activation = tf.nn.softmax))#归一化
train_images = train_images/255.0
#指定优化的方法、损失函数和训练时的精度
model.compile(optimizer = "adam",loss = "sparse_categorical_crossentropy",metrics = ["accuracy"])
#归一化
test_images = test_images/255.0
#用训练数据集训练,训练5轮
history = model.fit(train_images,train_labels,validation_data = (test_images,test_labels),epochs = 5,callbacks = [callbacks])# 绘制训练损失和验证损失随训练轮次变化的曲线图
plt.plot(history.history['loss'], label='Train Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()# 绘制训练准确率和验证准确率随训练轮次变化的曲线图
plt.plot(history.history['accuracy'], label='Train Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()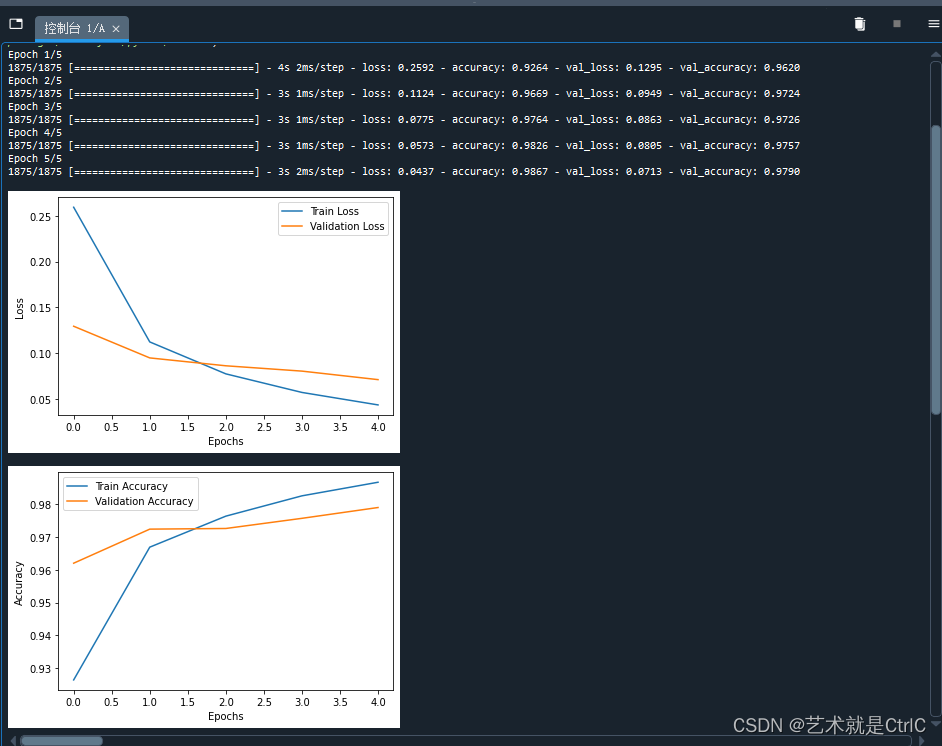
⑥保存模型
训练好模型,指定了模型保存的路径后,使用keras的回调函数(callbacks)的断点方法(ModelCheckpoint)将模型保存到指定的路径。该方法的作用是按照一定的频率保存模型到指定的路径,通常是每结束一轮训练即保存一次,和model.compile()、model.fit()结合使用。该方法的具体参数如下:
keras.callbacks.ModelCheckpoint(filepath,monitor = "val_loss",verbose = 0,save_best_only = False,save_weights_only = False,mode = "auto",period = 1)其中
filepath接收的参数是个字符串,指保存模型的路径。
monitor为被监测的数据,值为精度(val_acc)或损失值(val_loss)。一般和model.compile()函数中metrics的值相同。如compile()函数中指定metrics = ["accuracy"],则monitor = "accuracy"。
verbose指详细展示模式,值为0或者1。0为不打印输出信息,1为打印输出信息。
save_best_only,用于设置是否保存在验证集上性能最好的模型,如果save_best_only = True,将覆盖之前的模型,只保存在验证集上性能最好的模型。
save_weights_only,用于设置是否只保存模型参数,如果为True,那么只保存模型参数,如果为False,则保存整个模型。二者的区别在于,只保存模型参数的情况下,想用模型参数时,需要先将整个网络结构写出来,然后将模型参数文件导入到网络中。
mode,该参数的值为{auto,min,max}的其中之一,具体为哪个值和前面的参数设置有关。如果save_best_only = True,则是否覆盖保存文件的决定就取决于被监测数据(monitor)的最大值或最小值。如果是精度(val_acc),mode则为max;如果是损失值(val_loss),mode则为min。在auto模式下,评价准则由被监测值的名字自动推断。
period,该参数指每个检查点之间的间隔,即训练轮数。
示例代码如下:
import tensorflow as tf
import tensorflow.keras as kerasclass myCallback(keras.callbacks.Callback):def on_epoch_end(self,epoch,logs = {}):if (logs.get("loss") < 0.4):self.model.stop_training-Truecallbacks = myCallback()save_model_cb = tf.keras.callbacks.ModelCheckpoint(filepath='model.keras', save_freq='epoch')(train_images,train_labels),(test_images,test_labels) = keras.datasets.mnist.load_data()model = keras.Sequential()
model.add(keras.layers.Flatten(input_shape = (28,28)))
model.add(keras.layers.Dense(128,activation = tf.nn.relu))
model.add(keras.layers.Dense(10,activation = tf.nn.softmax))#归一化
train_images = train_images/255.0
#指定优化的方法、损失函数和训练时的精度
model.compile(optimizer = "adam",loss = "sparse_categorical_crossentropy",metrics = ["accuracy"])
#归一化
test_images = test_images/255.0
#用训练数据集训练,训练5轮
history = model.fit(train_images,train_labels,validation_data = (test_images,test_labels),epochs = 5,callbacks = [callbacks,save_model_cb])
⑦读取模型
读取模型,即向模型传入新的图片,实现图片的识别。一共分为三步:
第一步 : 查找到模型文件
第二步 : 加载模型
第三步 : 使用模型判断图片中的数字是哪个标签类别的概率
示例代码如下:
import tensorflow as tf
import tensorflow.keras as keras
import numpy as np
from PIL import Image
import osclass model(object):def __init__(self):#创建一个Sequential对象,以便堆叠各个卷积层。model=keras.Sequential()#给模型添加第一个输入层,将输入展平为一维向量28*28=784,获得图片输入model.add(keras.layers.Flatten(input_shape=(28,28)))#给模型添加第二个中间层,共有128个神经元model.add(keras.layers.Dense(128, activation=tf.nn.relu))#输出层为10的普通的神经网络,激活函数是softmax,10位恰好可以表达0-9十个数字。model.add(keras.layers.Dense(10, activation=tf.nn.softmax))#用来打印定义的模型的结构model.summary()self.model = modelclass Predict(object):def __init__(self):#加载由keras保存的模型loaded_model = keras.models.load_model('model.keras')#print("===========///===========: ",loaded_model.get_weights())self.model=model()#使用Keras加载模型的权重,并将其设置为当前模型的权重self.model.model.set_weights(loaded_model.get_weights())def predict(self, image_path):# 以灰度图像方式读取图片img=Image.open(image_path).convert('L')#将PIL图像对象转换为大小为(28, 28)的NumPy数组flatten_img = np.reshape(img, (28, 28))#将形状重塑后的图像数组包装成一个数组 x,这是因为模型期望以批次的形式接收输入,即使只有一张图像也要如此x = np.array([flatten_img])#使用模型对输入的图像进行预测,得到预测结果y = self.model.model.predict(x,verbose=1)print("image_path: ",image_path)# 因为x只传入了一张图片,取y[0]即可# np.argmax()取得最大值的下标,即代表的数字print('神经网络 -> 预测结果:您写入的数字为:', np.argmax(y))if __name__ == "__main__":image_predict = Predict()file_dir = 'D:/anaconda3/envs/tensorflow/Lib/site-packages/tensorflow/python/client/test_image'for filename in os.listdir(file_dir):image_path = os.path.join(file_dir, filename) # 拼接文件路径image_predict.predict(image_path)
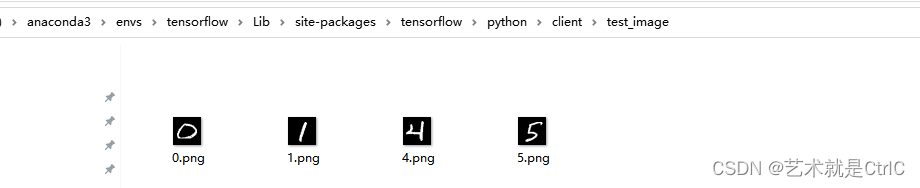
其中的model.keras是之前保存的模型,file_dir是存放图片的路径,如下图
代码运行结果如下:

需要注意的是:
在使用图像处理工具包打开图片路径的时候,该路径下的图片需要和训练时输入的图片保持像素大小以及不同像素分布特点上的一致。这是因为,在构建模型时,设置的输入图片的形状大小,就是28*28像素。因此读取环节,向模型输入的图片也需要是28*28像素。为了保证识别得准确度,最后向模型输入的图片,是将下载的mnist数据集解析后,从解析的图片中挑选出来的。
文件解析的方法与原理![]() http://t.csdnimg.cn/rCY0q
http://t.csdnimg.cn/rCY0q