目录
一、前言
二、Hive select 完整语法树
三、Hive select 操作演示
3.1 数据准备
3.1.1 创建一张表
3.1.2 将数据load加载到t_usa_covid19表
3.1.3 再创建一张分区表
3.1.4 使用动态分区插入数据
3.2 select 常用语法
3.2.1 查询所有字段或者指定字段
3.2.2 查询匹配正则表达式的所有字段
3.2.3 查询当前数据库
3.2.4 查询使用函数
3.2.5 使用函数
3.3 distinct关键字
3.3.1 查询state字段并去重
3.3.2 多个字段distinct 整体去重
3.4 分区查询、分区裁剪
3.5 GROUP BY
3.5.1 GROUP BY 概念
3.5.2 hive中 GROUP BY 使用限制
3.6 HAVING
3.7 limit
3.7.1 返回结果集的前5条
3.7.2 分页查询
3.8 HAVING与WHERE区别
3.9 select 语句中关键字顺序总结
四、union
4.1 操作演示
4.1.1 使用union查询student_local和student_hdfs
4.1.2 使用ALL关键字会保留重复行
4.1.3 union之前的的表需要排序或者限制表的查询数量
五、子查询
5.1 where子句中子查询
5.1.1 不相关子查询
5.1.2 相关子查询
六、CTE
6.1 操作演示
6.1.1 CTE结合insert使用
6.1.2 CTE 其他用法
七、join关联查询
7.1 hive join语法树
关于语法树中关键参数说明
7.2 join语法丰富化
7.2.1 隐式联接表示法
7.2.2 非等值连接
7.3 hive join操作演示
7.3.1 数据准备
7.3.2 加载数据到表中
7.3.3 inner join 内连接
7.3.4 left join 左连接
7.3.5 right join 右连接
7.3.6 full outer join 全外连接
7.3.7 left semi join 左半开连接
7.3.8 cross join 交叉连接
7.3.9 关于 join使用 注意事项
八、写在文末
一、前言
由于Hive是基于Hadoop的数据仓库,是面向分析支持分析工具。将已有的结构化数据文件映射成为表,然后提供SQL分析数据的能力。因此在Hive中常见的操作就是分析查询select操作。
Hive早期是不支持update和delete语法的,因为Hive所处理的数据都是已经存在的的数据、历史数据。后续Hive支持了相关的update和delete操作,不过有很多约束。详见Hive事务的支持。
二、Hive select 完整语法树
看hive的select语法树,对于熟悉mysql的同学是不是觉得里面有些关键词比较熟悉,在hive的select 语法中,尤其值得注意的就是from后面的内容,表示从哪里获取数据,可以是普通物理表、视图、join结果或子查询结果;
[WITH CommonTableExpression (, CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr, select_expr, ...FROM table_reference[WHERE where_condition][GROUP BY col_list][ORDER BY col_list][CLUSTER BY col_list| [DISTRIBUTE BY col_list] [SORT BY col_list]][LIMIT [offset,] rows];表名和列名不区分大小写(大小写不敏感)
三、Hive select 操作演示
接下来通过实际的操作演示来体验下select语法的强大之处吧
3.1 数据准备
在当前的数据目录下有数据数据文件,内容如下,里面记录了2021-01-28美国各个县累计新冠确诊病例数和累计死亡病例数;

3.1.1 创建一张表
为了演示方便,这里提前创建一张新的数据库;
drop table if exists t_usa_covid19;
CREATE TABLE t_usa_covid19(count_date string,county string,state string,fips int,cases int,deaths int)
row format delimited fields terminated by ",";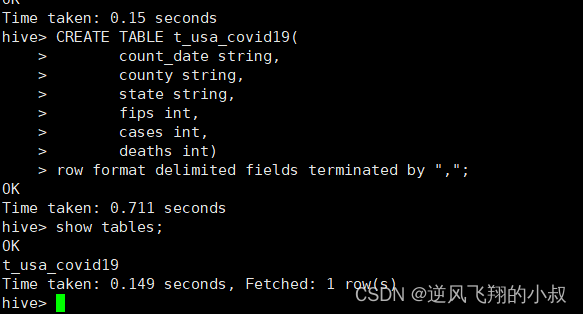
3.1.2 将数据load加载到t_usa_covid19表
load data local inpath '/usr/local/soft/selectdata/us-covid19-counties.dat' into table t_usa_covid19;
执行上面的加载命令;

3.1.3 再创建一张分区表
基于count_date日期,state州进行分区
CREATE TABLE if not exists t_usa_covid19_p(county string,fips int,cases int,deaths int)
partitioned by(count_date string,state string)
row format delimited fields terminated by ",";
3.1.4 使用动态分区插入数据
将数据导入t_usa_covid19_p中
set hive.exec.dynamic.partition.mode = nonstrict;
insert into table t_usa_covid19_p partition (count_date,state)
select county,fips,cases,deaths,count_date,state from t_usa_covid19;

执行完成后检查hdfs文件目录,可以看到分区目录已经存在了;

3.2 select 常用语法
下面对select涉及到的常用操作语法结合实际操作进行详细的说明。
3.2.1 查询所有字段或者指定字段
select * from t_usa_covid19_p;
select county, cases, deaths from t_usa_covid19_p;

3.2.2 查询匹配正则表达式的所有字段
使用正则表达式需要开启如下参数
SET hive.support.quoted.identifiers = none; --反引号不在解释为其他含义,被解释为正则表达式;

3.2.3 查询当前数据库
select current_database(); --省去from关键字

3.2.4 查询使用函数
select count(county) from t_usa_covid19_p;

3.2.5 使用函数
select state,count(deaths) from t_usa_covid19_p group by state having count(deaths) > 100;

3.3 distinct关键字
在hive中使用select xx from .. 时相当于是 select all ...,即返回所有匹配的行;
select state from t_usa_covid19_p;
如果数据有重复的话,就可以考虑使用distinct关键字进行去重处理;
3.3.1 查询state字段并去重
select distinct state from t_usa_covid19_p;

3.3.2 多个字段distinct 整体去重
select county,state from t_usa_covid19_p;
select distinct county,state from t_usa_covid19_p;
select distinct sex from student;
3.4 分区查询、分区裁剪
针对Hive分区表,在查询时可以指定分区查询,减少全表扫描,也叫做分区裁剪;
所谓分区裁剪指:对分区表进行查询时,会检查WHERE子句或JOIN中的ON子句中是否存在对分区字段的过滤,如果存在,则仅访问查询符合条件的分区,即裁剪掉没必要访问的分区
需求:找出来自加州,累计死亡人数大于1000的县
state字段就是分区字段 进行分区裁剪 避免全表扫描

由于分区表创建的时候指定了多个字段,这里还可以使用多分区裁剪
select * from t_usa_covid19_p where count_date = "2021-01-28" and state ="California" and deaths > 1000;

3.5 GROUP BY
3.5.1 GROUP BY 概念
使用过mysql的同学对group by 应该不陌生,即分组的意思,hive中GROUP BY语句用于结合聚合函数,根据一个或多个列对结果集进行分组;
注意:出现在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段
3.5.2 hive中 GROUP BY 使用限制
上面提到:出现在GROUP BY中select_expr的字段:要么是GROUP BY分组的字段;要么是被聚合函数应用的字段,主要原因是:避免出现一个字段多个值的歧义;
- 分组字段出现select_expr中,一定没有歧义,因为就是基于该字段分组的,同一组中必相同;
- 被聚合函数应用的字段,也没歧义,因为聚合函数的本质就是多进一出,最终返回一个结果;
如下图,左边为原始表数据,使用group by进行分组,基于category进行分组,相同颜色的分在同一组中。 在select_expr中,如果出现category字段,则没有问题,因为同一组中category值一样,但是返回day就有问题了,day的结果不一样;

需求:根据state州进行分组
select state,deaths from t_usa_covid19_p where count_date = "2021-01-28" group by state;
注意:执行上面的sql会报错,因为deaths不是分组字段 报错,而state是分组字段 可以直接出现在select_expr中;

group by 被聚合函数应用
select state,sum(deaths) from t_usa_covid19_p where count_date = "2021-01-28" group by state;

3.6 HAVING
在SQL中增加HAVING子句原因是,WHERE关键字无法与聚合函数一起使用。HAVING子句可以让我们筛选分组后的各组数据,并且可以在Having中使用聚合函数,因为此时where,group by已经执行结束,结果集已经确定。
需求:统计死亡病例数大于10000的州;
思路:先where分组前过滤(此处是分区裁剪),再进行group by分组, 分组后每个分组结果集确定 再使用having过滤
select state,sum(deaths)
from t_usa_covid19_p
where count_date = "2021-01-28"
group by state
having sum(deaths) > 10000;
也可以像下面这样写
select state,sum(deaths) as cnts
from t_usa_covid19_p
where count_date = "2021-01-28"
group by state
having cnts> 10000;这样写更好 即在group by的时候聚合函数已经作用得出结果 having直接引用结果过滤 不需要再单独计算一次了
执行上面的sql,结果是一样的,时间上来说,似乎更快一点;

3.7 limit
limit就是限制查询返回结果的数量,有时候我们并不希望一次性返回所有数据时就可以使用limit,这个就比较简单;
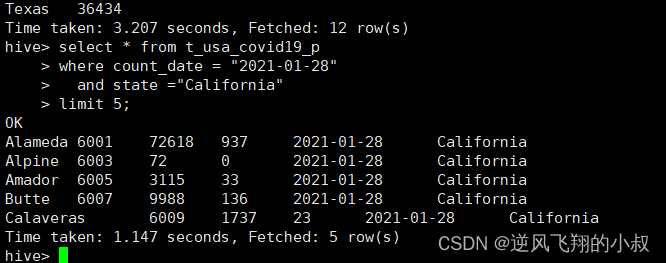
3.7.1 返回结果集的前5条
select * from t_usa_covid19_p
where count_date = "2021-01-28"
and state ="California"
limit 5;
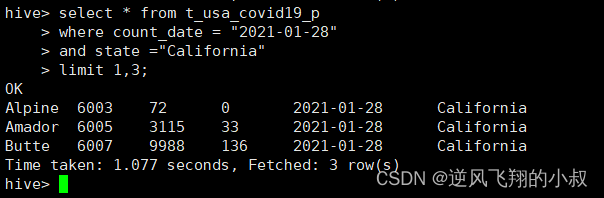
3.7.2 分页查询
查询第1~3条数据
3.8 HAVING与WHERE区别
不少同学在HAVING与where使用的时候有点懵,这里简单总结下:
- having是在分组后对数据进行过滤;
- where是在分组前对数据进行过滤;
- having后面可以使用聚合函数;
- where后面不可以使用聚合函数;
3.9 select 语句中关键字顺序总结
在查询过程中执行顺序:from > where > group(含聚合)> having >order > select;
1、聚合语句(sum,min,max,avg,count)要比having子句优先执行;
2、where子句在查询过程中执行优先级别优先于聚合语句(sum,min,max,avg,count)
下面用一句sql总结下:
select state,sum(deaths) as cnts
from t_usa_covid19_p
where count_date = "2021-01-28"
group by state
having cnts> 10000;
四、union
使用过mysql的同学应该对union不陌生,当需要对跨表数据进行组合,或者不方便通过关联查询得到满足结果的数据集的时候,就可以使用mysql的union查询,在hive中也提供了union的语法;
UNION用于将来自于多个SELECT语句的结果合并为一个结果集
语法
select_statement
UNION [ALL | DISTINCT]
select_statement
UNION [ALL | DISTINCT]
select_statement ...;
关于hive中的union做几点说明:
- 使用DISTINCT关键字与只使用UNION默认值效果一样,都会删除重复行。1.2.0之前的Hive版本仅支持UNION ALL,在这种情况下不会消除重复的行;
- 使用ALL关键字,不会删除重复行,结果集包括所有SELECT语句的匹配行(包括重复行);
- 每个select_statement返回的列的数量和名称必须相同;
4.1 操作演示
4.1.1 使用union查询student_local和student_hdfs
select num,name from student_local
UNION
select num,name from student_hdfs;使用DISTINCT关键字与使用UNION默认值效果一样,都会删除重复行

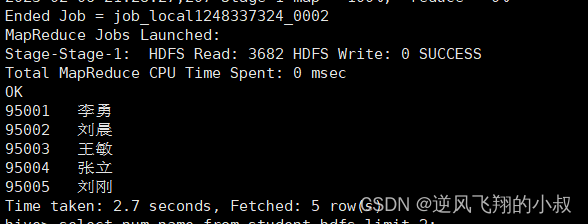
4.1.2 使用ALL关键字会保留重复行
select num,name from student_local
UNION ALL
select num,name from student_hdfs limit 5;执行上面的sql,如果两个表有相同的数据将会保留重复行
4.1.3 union之前的的表需要排序或者限制表的查询数量
如果要将ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY或LIMIT应用于单个SELECT,请将子句放在括住SELECT的括号内,如下:
SELECT num,name FROM (select num,name from student_local LIMIT 2) subq1
UNION
SELECT num,name FROM (select num,name from student_hdfs LIMIT 3) subq2;
如果要将ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY或LIMIT子句应用于整个UNION结果,请将ORDER BY,SORT BY,CLUSTER BY,DISTRIBUTE BY或LIMIT放在最后一个之后,如下:
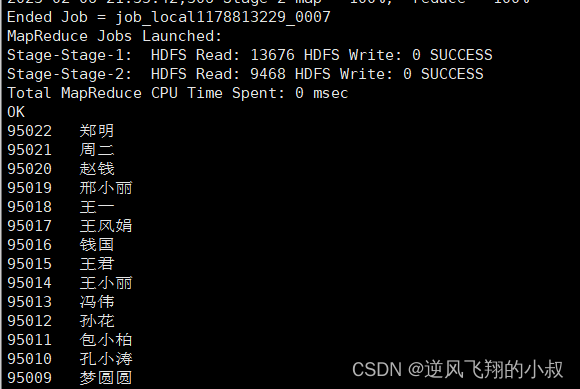
select num,name from student_local
UNION
select num,name from student_hdfs
order by num desc;
执行结果如下:
五、子查询
在上面的union最后就用到了子查询,在Hive0.12版本,仅在FROM子句中支持子查询,关于子查询的特点如下:
- 必须要给子查询一个名称,因为FROM子句中的每个表都必须有一个名称;
- 子查询返回结果中的列必须具有唯一的名称;
- 子查询返回结果中的列在外部查询中可用,就像真实表的列一样;
- 子查询也可以是带有UNION的查询表达式;
- Hive支持任意级别的子查询,也就是所谓的嵌套子查询(这点与mysql略有差异);
- Hive 0.13.0和更高版本中的子查询名称之前可以包含可选关键字AS;
from子句中子查询(Subqueries)
SELECT num
FROM (
select num,name from student_local
) tmp;
包含UNION ALL的子查询的示例
SELECT t3.name
FROM (
select num,name from student_local
UNION distinct
select num,name from student_hdfs
) t3;
5.1 where子句中子查询
从Hive 0.13开始,WHERE子句支持下述类型的子查询;
5.1.1 不相关子查询
该子查询不引用父查询中的列,可以将查询结果视为IN和NOT IN语句的常量;
执行子查询,其结果不被显示,而是传递给外部查询,作为外部查询的条件使用。
如下面的sql:
SELECT *
FROM student_hdfs
WHERE student_hdfs.num IN (select num from student_local limit 2);5.1.2 相关子查询
子查询引用父查询中的列,子查询的WHERE子句中支持对父查询的引用;
如下面的sql:
SELECT A
FROM T1
WHERE EXISTS (SELECT B FROM T2 WHERE T1.X = T2.Y);六、CTE
CTE是一个临时结果集,该结果集是从WITH子句中指定的简单查询派生而来的,紧接在SELECT或INSERT关键字之前,关于cte的使用:
- CTE仅在单个语句的执行范围内定义;
- CTE可以在 SELECT,INSERT, CREATE TABLE AS SELECT或CREATE VIEW AS SELECT语句中使用;
在hive的select语法树中所处的位置如下图:

6.1 操作演示
select语句中的CTE
with q1 as (select num,name,age from student where num = 95002)
select *
from q1;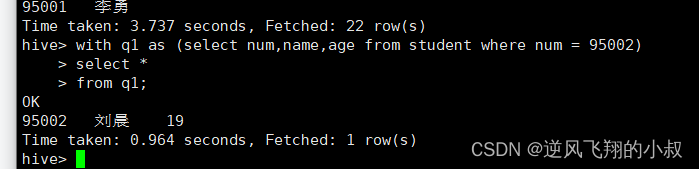
from风格的cte
with q1 as (select num,name,age from student where num = 95002)
from q1
select *;
链式风格的cte
with q1 as ( select * from student where num = 95002),q2 as ( select num,name,age from q1)
select * from (select num from q2) a;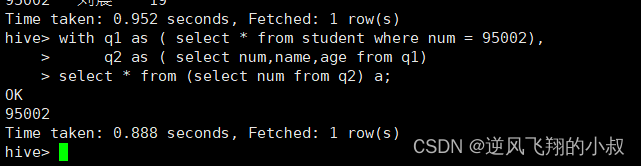
使用union的cte查询
with q1 as (select * from student where num = 95002),q2 as (select * from student where num = 95004)
select * from q1 union all select * from q2;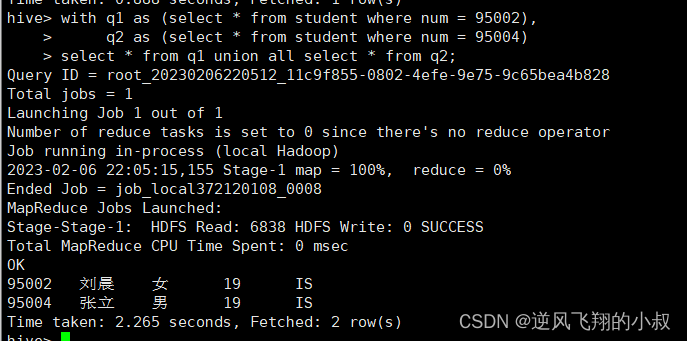
6.1.1 CTE结合insert使用
可以直接将cte中的查询结果插入到另一张表中,如下操作:
#创建一张待插入数据的表
create table s1 like student;#使用cte语法插入数据
with q1 as ( select * from student where num = 95002)
from q1
insert overwrite table s1
select *;#查询数据
select * from s1;6.1.2 CTE 其他用法
创建表来源于一个查询结果集
create table s2 as
with q1 as ( select * from student where num = 95002)
select * from q1;
使用cte创建视图
create view v1 as
with q1 as ( select * from student where num = 95002)
select * from q1;
七、join关联查询
使用mysql时,经常涉及到多张表的关联查询,相信大家并不陌生,在Hive中也提供了多种join查询,当下版本3.1.2总共支持6种join语法,它们分别是:
- inner join(内连接);
- left join(左连接);
- right join(右连接);
- full outer join(全外连接);
- left semi join(左半开连接);
- cross join(交叉连接,也叫做笛卡尔乘积);
7.1 hive join语法树
join_table:
table_reference [INNER] JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference [join_condition] (as of Hive 0.10)
join_condition:
ON expression
关于语法树中关键参数说明
table_reference
是join查询中使用的表名,也可以是子查询别名(查询结果当成表参与join)
table_factor
与table_reference相同,是联接查询中使用的表名,也可以是子查询别名
join_condition
join查询关联的条件,如果在两个以上的表上需要连接,则使用AND关键字
7.2 join语法丰富化
Hive中join语法从面世开始其实并不丰富,不像在RDBMS中那么灵活,从Hive 0.13.0开始,支持隐式联接表示法(请参阅HIVE-5558)。允许FROM子句连接以逗号分隔的表列表,而省略JOIN关键字,从Hive 2.2.0开始,支持ON子句中的复杂表达式,支持不相等连接(请参阅HIVE-15211和HIVE-15251)。在此之前,Hive不支持不是相等条件的联接条件。
7.2.1 隐式联接表示法
SELECT *
FROM table1 t1, table2 t2, table3 t3
WHERE t1.id = t2.id AND t2.id = t3.id AND t1.zipcode = '02535';
7.2.2 非等值连接
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department)
SELECT a.* FROM a LEFT OUTER JOIN b ON (a.id <> b.id)
7.3 hive join操作演示
7.3.1 数据准备
提前创建3张表并且加载数据到表中
--table1: 员工表
CREATE TABLE employee(id int,name string,deg string,salary int,dept string) row format delimited
fields terminated by ',';--table2:员工家庭住址信息表
CREATE TABLE employee_address (id int,hno string,street string,city string
) row format delimited
fields terminated by ',';--table3:员工联系方式信息表
CREATE TABLE employee_connection (id int,phno string,email string
) row format delimited
fields terminated by ',';执行上面的sql完成表的创建
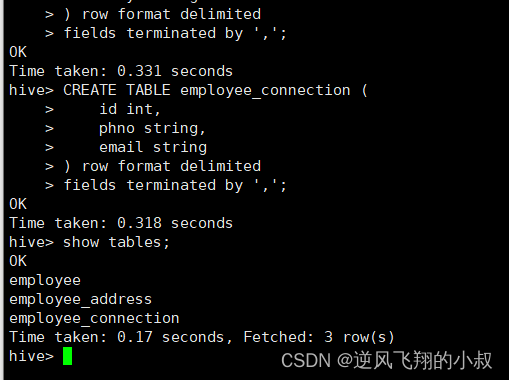
7.3.2 加载数据到表中
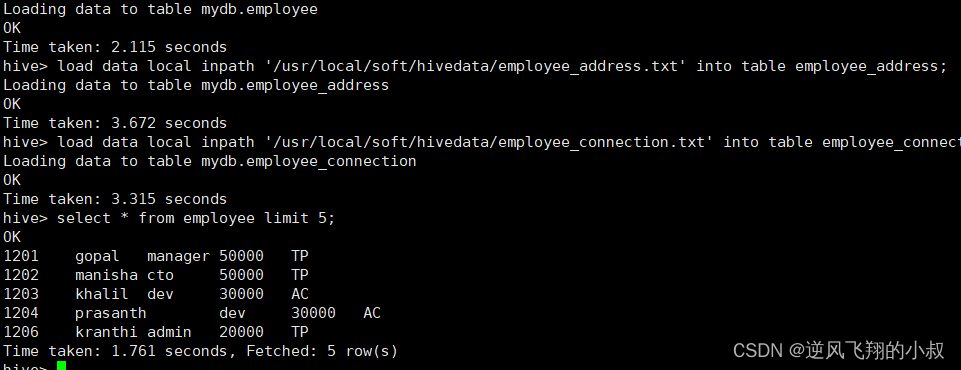
load data local inpath '/usr/local/soft/hivedata/employee.txt' into table employee;
load data local inpath '/usr/local/soft/hivedata/employee_address.txt' into table employee_address;
load data local inpath '/usr/local/soft/hivedata/employee_connection.txt' into table employee_connection;
7.3.3 inner join 内连接
- 内连接是最常见的一种连接,它也被称为普通连接,其中inner可以省略:inner join == join ;
- 只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来;
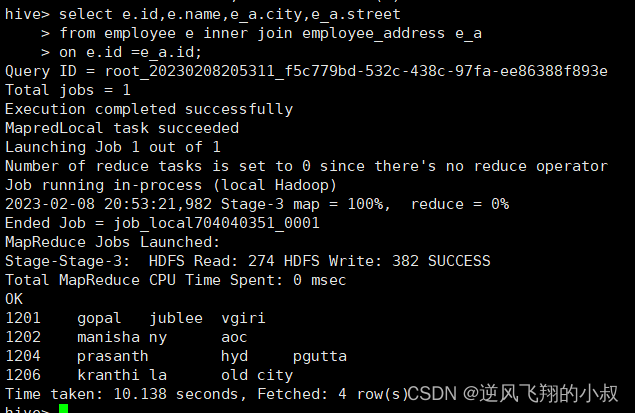
员工表与员工住址表关联查询
select e.id,e.name,e_a.city,e_a.street
from employee e inner join employee_address e_a
on e.id =e_a.id;
等价于
select e.id,e.name,e_a.city,e_a.street
from employee e join employee_address e_a
on e.id =e_a.id;
等价于 隐式连接表示法
select e.id,e.name,e_a.city,e_a.street
from employee e , employee_address e_a
where e.id =e_a.id;
7.3.4 left join 左连接
- left join中文叫做是左外连接(Left Outer Join)或者左连接,其中outer可以省略,left outer join是早期的写法;
- left join的核心就在于left左。左指的是join关键字左边的表,简称左表;
- 通俗解释:join时以左表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关联不上的显示null返回;
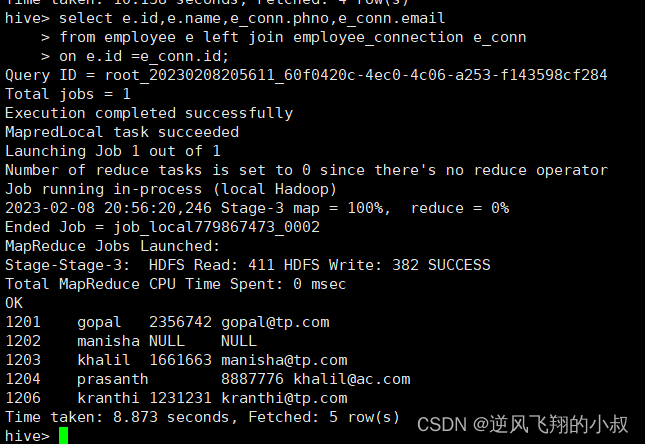
员工表和员工联系方式表关联查询
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left join employee_connection e_conn
on e.id =e_conn.id;
等价于查询 left outer join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left outer join employee_connection e_conn
on e.id =e_conn.id;
7.3.5 right join 右连接
- right join中文叫做是右外连接(Right Outer Jion)或者右连接,其中outer可以省略;
- right join的核心就在于Right右。右指的是join关键字右边的表,简称右表;
- 通俗解释:join时以右表的全部数据为准,左边与之关联;右表数据全部返回,左表关联上的显示返回,关联不上的显示null返回;
- 很明显,right join和left join之间很相似,重点在于以哪边为准,也就是一个方向的问题;
员工表和员工联系方式表关联查询
select e.id,e.name,e_conn.phno,e_conn.email
from employee e right join employee_connection e_conn
on e.id =e_conn.id;
等价于 right outer join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e right outer join employee_connection e_conn
on e.id =e_conn.id;
7.3.6 full outer join 全外连接
- full outer join 等价 full join ,中文叫做全外连接或者外连接;
- 包含左、右两个表的全部行,不管另外一边的表中是否存在与它们匹配的行;
- 在功能上:等价于对这两个数据集合分别进行左外连接和右外连接,然后再使用消去重复行的操作将上述两个结果集合并为一个结果集;
员工和员工住址表关联查询
select e.id,e.name,e_a.city,e_a.street
from employee e full outer join employee_address e_a
on e.id =e_a.id;
等价于
select e.id,e.name,e_a.city,e_a.street
from employee e full join employee_address e_a
on e.id =e_a.id;
7.3.7 left semi join 左半开连接
- 左半开连接(LEFT SEMI JOIN)会返回左边表的记录,前提是其记录对于右边的表满足ON语句中的判定条件;
- 从效果上来看有点像inner join之后只返回左表的结果;
员工和员工住址表关联查询
select *
from employee e left semi join employee_address e_addr
on e.id =e_addr.id;
相当于 inner join,但是只返回左表全部数据, 只不过效率高一些
select e.*
from employee e inner join employee_address e_addr
on e.id =e_addr.id;
7.3.8 cross join 交叉连接
- 交叉连接cross join,将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积。对于大表来说,cross join慎用;
- 在SQL标准中定义的cross join就是无条件的inner join。返回两个表的笛卡尔积,无需指定关联键;
- 在HiveSQL语法中,cross join 后面可以跟where子句进行过滤,或者on条件过滤;
下列A、B、C 执行结果相同,但是效率不一样:
--A:
select a.*,b.* from employee a,employee_address b where a.id=b.id;
--B:
select * from employee a cross join employee_address b on a.id=b.id;
select * from employee a cross join employee_address b where a.id=b.id;
--C:
select * from employee a inner join employee_address b on a.id=b.id;
一般不建议使用方法A和B,因为如果有WHERE子句的话,往往会先生成两个表行数乘积的行的数据表然后才根据WHERE条件从中选择。因此,如果两个需要求交集的表太大,将会非常非常慢,不建议使用。
7.3.9 关于 join使用 注意事项
- 允许使用复杂的联接表达式,支持非等值连接;
- 同一查询中可以连接2个以上的表;
- 如果每个表在联接子句中使用相同的列,则Hive将多个表上的联接转换为单个MR作业;
- join时的最后一个表会通过reducer流式传输,并在其中缓冲之前的其他表,因此,将大表放置在最后有助于减少reducer阶段缓存数据所需要的内存;
- 在join的时候,可以通过语法STREAMTABLE提示指定要流式传输的表。如果省略STREAMTABLE提示,则Hive将流式传输最右边的表;
- join在WHERE条件之前进行;
- 如果除一个要连接的表之外的所有表都很小,则可以将其作为仅map作业执行(mapjoin);
八、写在文末
查询操作对于Hive来说,不管是日常开发还是生产运维,都具有重要的意义,因此熟练掌握Hive的查询相关的语法和操作非常重要,希望对看到的伙伴有用。