EnBinDiff: Identifying Data-Only Patches for Binaries [TDSC 2021]
在本文中,我们将重点介绍纯数据补丁,这是一种不会引起任何结构更改的特定类型的安全补丁。作为导致假阴性的最重要原因之一,纯数据补丁成为影响所有最先进的二进制差分方法/工具的基本问题。为此,我们首先系统地研究了纯数据补丁,并彻底说明了其本质和对现有工具的不利影响。在此基础上,我们进一步提出并实现了一个基于Value Set Analysis (VSA)的EnBinDiff系统来有效识别纯数据补丁。具体来说,EnBinDiff首先从二进制文件中精确地识别函数,然后基于结构二进制差分有效地定位所有“匹配”的函数对。然后,EnBinDiff进行纯数据补丁分析,包括堆栈帧匹配和常数值匹配,从匹配的函数中识别纯数据补丁。为了证明EnBinDiff的有效性,我们对多个数据集进行了广泛的评估。结果表明,该系统优于最先进的二进制差分工具,假阴性率从11.02%降至1.63%。此外,我们应用EnBinDiff来分析现实世界的二进制文件,并成功识别了20个1day漏洞。
一句话:EnBinDiff,基于结构二进制差分(diffing)定位匹配函数对,并从匹配函数中识别纯数据补丁。
导论
软件公司总是为他们的产品发布补丁。一些补丁用于提供新功能(或修复不属于安全问题的错误),而另一些则称为安全补丁,其目的是修补漏洞。有趣的是,由于安全法规或政策的原因,软件公司可能会默默地修补公共未知漏洞[2]。
先前的研究[3]表明,向最终用户提供安全补丁可能需要6个月以上的时间,这导致攻击者有相对较长的时间窗口来破坏未打补丁的系统[4]。在此期间,相应的漏洞在一定程度上可以被视为零日漏洞,即使这些漏洞已经公开。显然,可以通过检测和分析安全补丁来获取这些漏洞的有用信息,这对攻击者和安全研究人员都很有价值。
一些工作[5],[6]已经提出通过在源代码级别应用补丁差异技术来检测安全补丁。然而,这些解决方案的使用是有限的,因为它们依赖于源代码级别的补丁,而这些补丁在实践中并不总是可用的,例如,许多软件公司不愿意披露补丁的细节。
为了解决这个问题,二进制差分技术已经被广泛探索以支持二进制水平分析。简单地说,二进制差分将原始二进制文件与打过补丁的二进制文件进行比较,以快速确定反汇编代码的差异。现有的二进制差分方法/工具根据其采用的技术分为三类,包括基于结构的[7]、[8]、[9]、[10]、[11]、[12]、[13],基于学习的[14]、[15]、[16]、[17]、[18],以及基于符号执行的[19]、[20]、[21]。
基于结构和基于学习的工具都存在假阴性的问题,原因有以下两个。具体来说,第一个原因源于代码结构的不准确(甚至不正确)识别,这是这些工具实现有效检测所必需的。例如,基于结构的工具需要精确地识别功能/调用图/控制流图。然而,在某些情况下,有效地识别代码结构并不总是一项微不足道的任务。第二个原因是缺乏捕捉不发生任何结构变化的补丁的能力[22],本文将其命名为data-only patch。以基于学习的工具为例,学习的规范化过程可能会忽略一些代码的变化,例如常数值的变化。
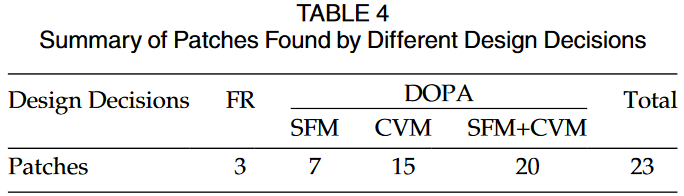
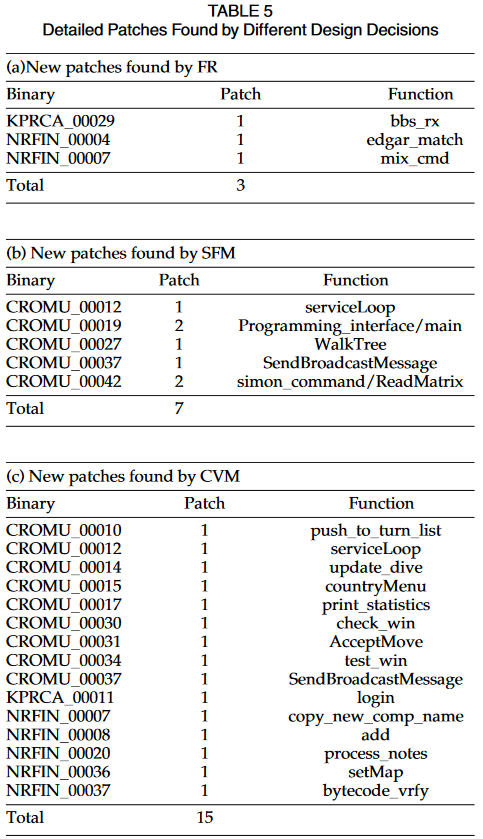
只有数据的补丁已经成为导致假阴性的最重要原因之一。我们对CGC数据集的调查[23]表明,只有数据的补丁在假阴性中占主导地位。该数据集包含245个安全补丁,其中23个(9.39%)为纯数据安全补丁。为了评估纯数据补丁的影响,我们使用最具代表性的工具BinDiff[9]进行分析。
我们通过分析各种现实世界漏洞的安全补丁进行了大规模研究[24]。我们总共调查了BinDiff的1458个安全补丁。结果,有69个假阴性,其中51个(74%)来自数据补丁。然而,以往的研究大多忽略了数据补丁,少数研究[22]意识到这些问题,也没有提供任何可能的解决方案。这是因为许多仅限数据的更改与安全性无关,甚至不是由源代码更改引起的,这可能导致误报的大幅增加。
研究表明,纯数据补丁主要引起两种类型的非结构性变化,即面向堆栈和面向恒定值。(这个是关键发现,所有创新都会依赖于新的发现)
检测这两种类型的纯数据补丁存在两个技术挑战。第一个挑战是定位在堆栈帧中改变其大小的变量,以定位面向堆栈的仅数据补丁。这是因为函数的所有局部变量都是在堆栈帧中分配的。然而,局部变量的顺序是不确定的。这是因为它是由编译器分配的,编译器有不同的编译标志和选项。因此,我们需要在两个堆栈帧中构造变量对,然后比较每个变量对的大小。第二个挑战是提取与补丁相关的变化常数值。因为常量值的改变可能是由编译器引入的,所以即使是未打补丁的函数也可能包含常量值的改变。因此,我们需要区分恒定值的变化是否是由数据补丁引起的。
Approach 提出了一种基于独特差异的新方法,该方法不会在堆栈框架和常量中引入任何结构变化。通过这样做,我们可以通过定位堆栈帧中变量的不同大小来找到面向堆栈的纯数据补丁,通过定位与补丁相关的不同常量值来确定面向常量值的纯数据补丁。因此,我们设计并实现了一个名为 EnBinDiff 的系统来识别仅数据补丁。EnBinDiff对输入的原始二进制和补丁二进制进行预处理,构造结构匹配函数对和结构补丁函数。对于结构匹配的函数对,EnBinDiff进行仅数据补丁分析,包括堆栈帧匹配和恒值匹配。
为了证明EnBinDiff的有效性,我们使用CGC数据集和Hybrid Utils数据集对EnBinDiff进行了广泛的评估结果表明,我们的工具完全优于最先进的工具,包括BinDiff、Diaphora和DeepBinDiff。
Contributions
- 系统地揭开了纯数据补丁的神秘面纱,这是最先进的二进制差分工具的一个根本缺陷
- 提出并实现了一个基于VSA的系统EnBinDiff,该系统能够通过执行纯数据补丁分析来识别纯数据补丁
- 用多个数据集评估了EnBinDiff,并将其应用于发现现实世界的漏洞。结果证明了EnBinDiff的有效性。
方案
Binary Diffing
二进制差分精确地度量相似性,并在函数或基本块粒度上表征两个输入二进制数据在语义上的差异。从理论上讲,比较函数可以分为三类:最匹配函数、部分匹配函数和不匹配函数。后两者被视为补丁函数。具体来说,二进制差分在预处理阶段为每个输入二进制提取一组函数。首先,二进制差分在原始二进制文件和补丁二进制文件中的函数之间进行函数匹配,以获得函数粒度上匹配的函数对列表和不匹配的函数列表。其次,对于每个匹配的函数对,二进制差分执行基本块匹配,以确定它是部分匹配的函数对还是最佳匹配的函数对。最后,输出一组修改过的函数,其中包括不匹配的函数和部分匹配的函数。两个输入二进制文件通常相对相似(例如,相同软件的两个相邻版本),因此输出通常是一个相对较小的集合。通过进一步分析变化的功能,研究人员可以发现1day漏洞。



Value Set Analysis

A Motivating Example
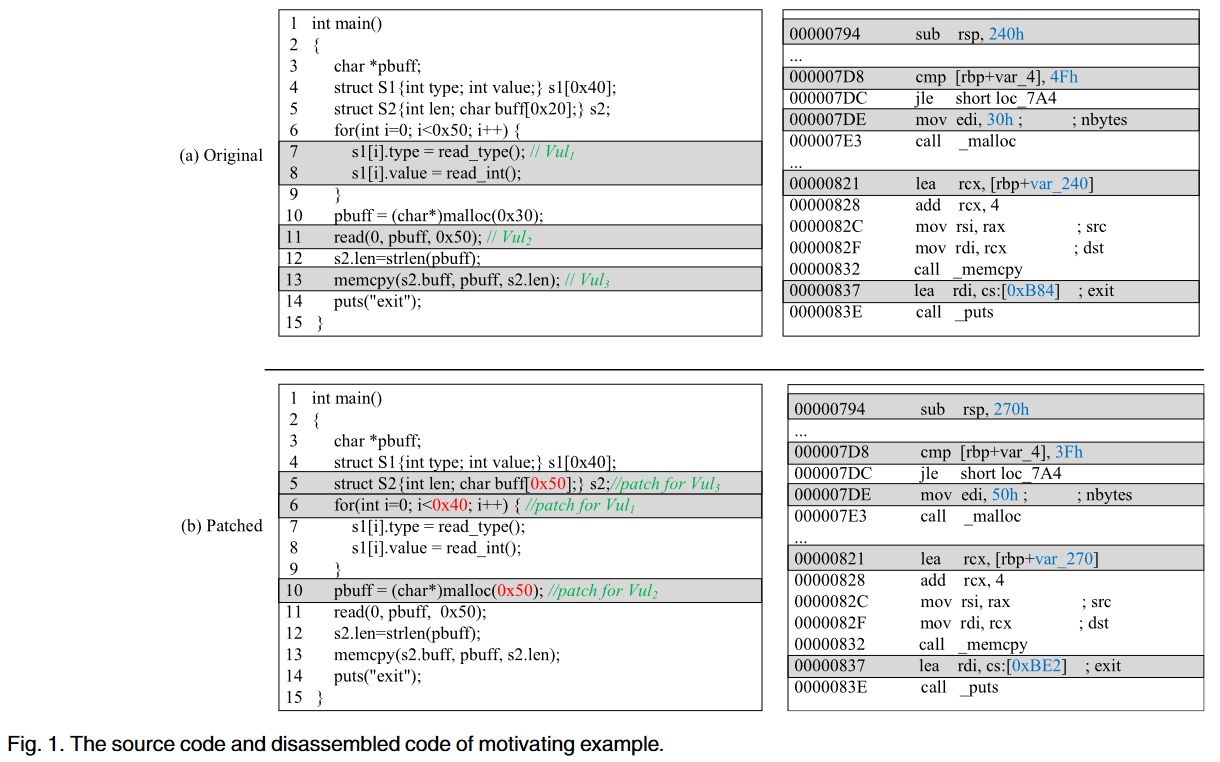
图1所示为仅数据补丁的示例。图1的上半部分为原始源代码和相应的反汇编代码在第7、10和12行中存在三个缓冲区溢出漏洞,它们分别被标记为vul1、vul2和vul3。它们与三个变量有关,即s1、pbuff和s2。vul1的根本原因是7-8行代码重复0x50(第6行)次,大于s1的长度(第4行0x40)。vul2的根本原因是要读取的最大字节数(第11行0x50)大于pbuff的大小(第10行0x30)。产生vul3的根本原因是s2的值。len(第12行中的0x50),即第13行中memcpy的第三个参数,大于s2的大小。buff(第5行0x20)。

Overall Design
流程包括两个主要阶段:预处理和仅数据补丁分析。预处理以一对(原始的和修补过的)二进制文件作为输入,当结构修补过的函数得到最终结果时,将结构匹配的函数对输出到下一阶段。然后将结构匹配的函数对发送给纯数据补丁分析,通过匹配堆栈帧和常量值来定位纯数据补丁。最后,EnBinDiff输出纯数据修补函数和结构修补函数作为最终修补函数。
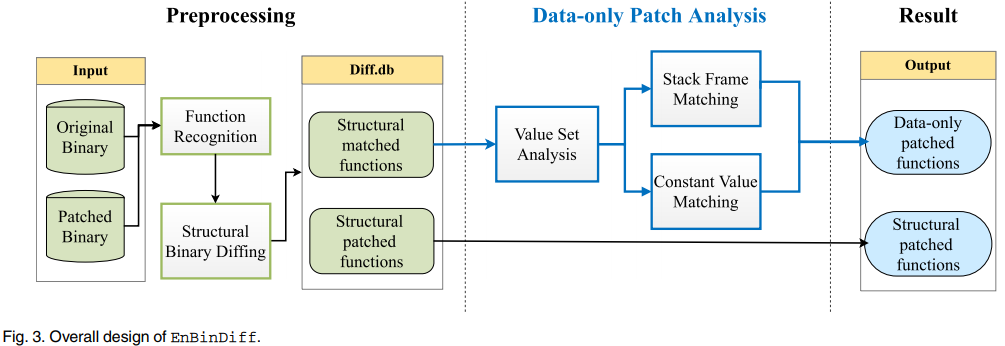
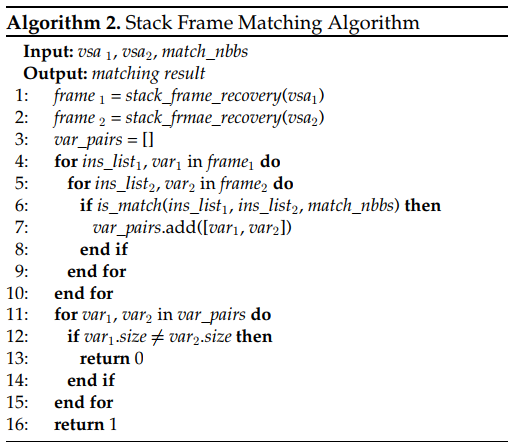
为了精确检测面向堆栈的纯数据补丁和面向恒值的纯数据补丁,纯数据补丁分析包括堆栈帧匹配和恒值匹配。堆栈帧匹配关注的是局部变量的大小,局部变量的大小可以通过面向堆栈的数据补丁来改变(如第3节所示)。然而,局部变量在堆栈帧中的位置是由编译器决定的,不同的编译器决定的位置是不同的。因此,堆栈帧匹配为每个函数恢复堆栈帧,并通过堆栈内存操作匹配局部变量。匹配后,EnBinDiff比较匹配的局部变量的大小,如果大小发生变化,则识别仅用于数据的补丁。对于常量值,它们的变化有时可能是噪声,这些噪声是由编译器引入的,甚至可以在未修补的函数中找到。因此,恒值匹配首先对面向恒值的数据补丁相关的恒值进行区分和匹配,然后进行比较,看它们在语义上是否相等。如果不是,EnBinDiff将该函数视为仅数据修补的函数。
Preprocessing
Nucleus[28]是一种新型的开源图论函数检测引擎,它采用一种新的基于结构CFG分析的无签名方法来精确识别剥离二进制文件的函数起始地址。尽管Nucleus支持多种指令集架构(例如x86、ARM和MIPS)和可执行文件格式(例如Unix ELF和Windows PE),但这对EnBinDiff来说是不够的。因此,EnBinDiff扩展了Nucleus以支持更多的平台和功能。
具体来说,EnBinDiff需要精确地识别CFG。然而,到目前为止,Nucleus的寻址分析还不支持ARM架构。因此,我们实现了基于arm的地址占用分析,以提高精度。此外,EnBinDiff还需要分析Nucleus不支持的DARPA CGC可执行格式[23]的二进制文件。因此,我们为Nucleus增加了相应的支持,以满足需求。
在获取函数之后,EnBinDiff使用结构二元差分来比较两个函数集,即 F o F_o Fo和 F p F_p Fp,其主要目的是生成结构匹配的函数对和结构补丁函数(由部分匹配的函数和不匹配的函数组成)。结构匹配的函数对将被输入到以下仅数据的补丁分析中。结构补丁函数将成为最终输出的一部分。具体来说,EnBinDiff利用BinDiff来完成这项工作。
Data-Only Patch Analysis
为了从结构匹配的函数对中捕获纯数据补丁,我们提出了一种基于值集分析(VSA)的纯数据补丁分析方法。具体来说,纯数据补丁分析处于基本块粒度。EnBinDiff首先从输入函数中生成规范化的基本块,以执行VSA来获取每个基本块的状态。然后,由于纯数据补丁会引起堆栈帧和常量的变化,因此EnBinDiff会进行堆栈帧匹配和常量匹配来检测纯数据补丁。对于堆栈帧匹配,EnBinDiff从VSA输出的状态中提取堆栈内存操作数来恢复堆栈帧。然后,EnBinDiff从原始二进制和补丁二进制中匹配堆栈帧中的局部变量,并比较它们的大小。对于常数值匹配,EnBinDiff从状态中提取函数参数和比较操作数,并比较其中的常数值。
值集分析
对于VSA, EnBinDiff首先生成规范化的基本块。EnBinDiff基于BinDiff生成基本块。对于每个输入结构匹配的函数对,BinDiff输出匹配的基本块对。但是,BinDiff生成的基本块并不是一直规范化的,这是VSA无法接受的。这是因为BinDiff不将调用指令视为退出指令,这导致一些基本块将调用指令作为常规指令包含。调用指令从基本块分支出来,这使得基本块包含多个出口。规范化的基本块应该是一个只有一个入口和一个出口的直线代码序列[29]。
EnBinDiff对BinDiff生成的所有基本块都采用规范化处理,通过调用指令进一步分割。例如,图4显示了激励示例中的反汇编代码片段。左边的基本块由BinDiff生成,包含五个调用指令,用于调用_malloc、_read、_strlen、_memcpy和_puts函数。EnBinDiff进一步将这个基本块分割成六个标准化的基本块,它们的起始地址是0x7DE、0x7E8、0x802、0x80E、0x837和0x843。
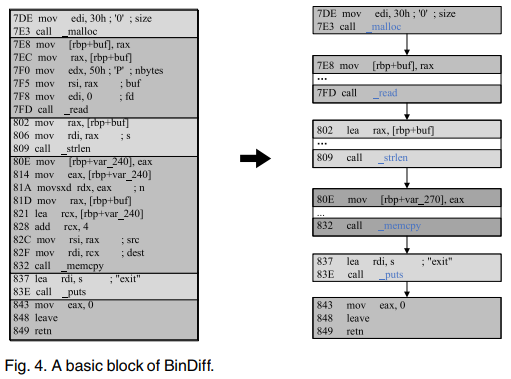
规范化后,EnBinDiff重新匹配新生成的基本块。来自两个匹配的BinDiff基本块的新基本块的数量是相同的,因为BinDiff使用调用指令的数量作为匹配基本块的签名。因此,EnBinDiff按地址对新的基本块进行排序,并逐个进行匹配。然后,EnBinDiff利用angr[30]来执行VSA。VSA将每个结构匹配函数的归一化基本块作为输入,输出每个基本块的状态。基本块的状态包括用于堆栈帧匹配的基本块中的堆栈内存操作,以及用于常量匹配的基本块的调用者和退出守卫(exit guards)的参数。
下面是栈帧匹配算法

常量匹配算法

实验
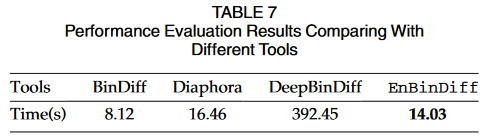
在实验中,我们将EnBinDiff与BinDiff、Diaphora和DeepBinDiff这三种工具进行了比较[18]。对于BinDiff和Diaphora,我们直接比较结果。对于DeepBinDiff,我们进一步分析DeepBinDiff的结果,得到所有的补丁函数,因为DeepBinDiff只输出匹配的基本块对。如果一个函数的所有基本块都有匹配的基本块,并且所有匹配的基本块都属于同一个函数,则该函数为未打补丁的函数,否则为打补丁的函数。
我们还比较了EnBinDiff的过载与最先进的基于符号执行的二进制差分方法iBinHunt。iBinHunt没有发布任何可用的工具,所以我们将EnBinDiff与iBinHunt论文[20]中的结果进行比较,使用相同的数据集。
Ground Truth Collection
为了评估,我们提取数据集中的所有补丁函数作为ground truth。我们依靠源代码级匹配和调试符号信息来收集地面真相。
Metric

Effectiveness in CGC Dataset
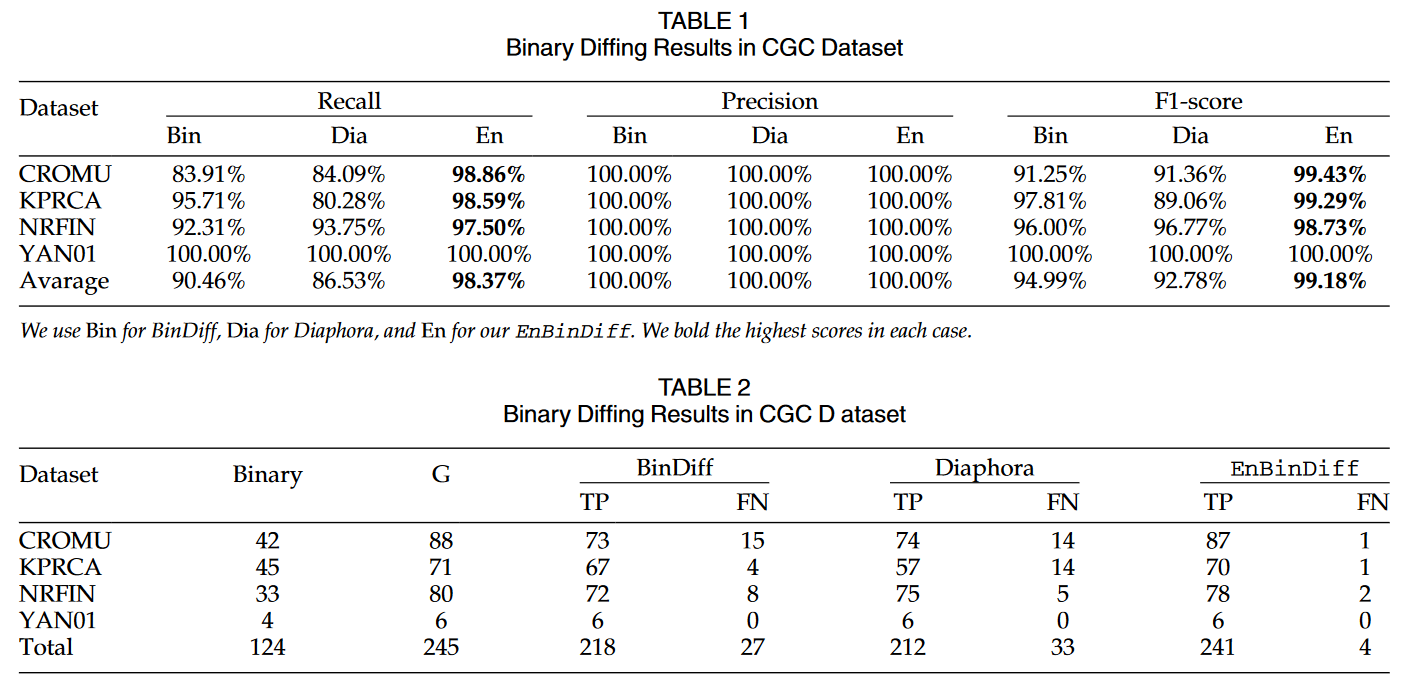
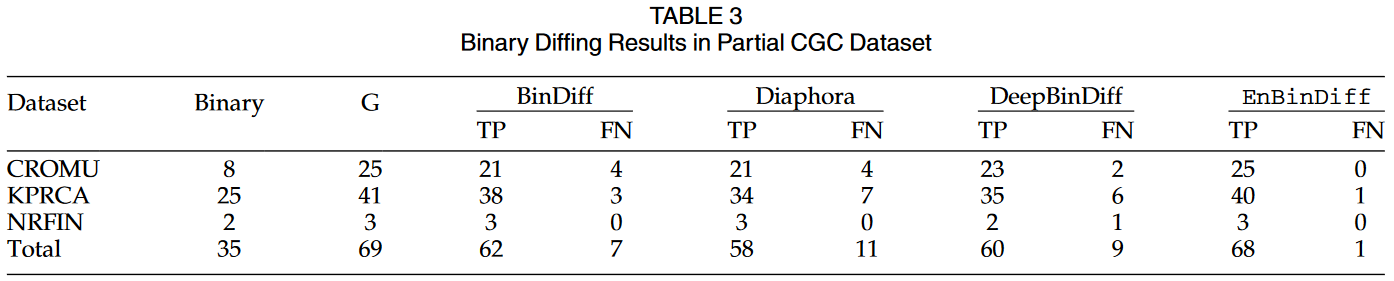
CGC数据集的有效性评价结果如表1所示。CGC数据集的假阴性问题。为了进行更直观的比较,我们使用公式4中所示的假阴性率(FNR)指标来进一步衡量这些不同工具在CGC数据集中的有效性。评价结果见表2。
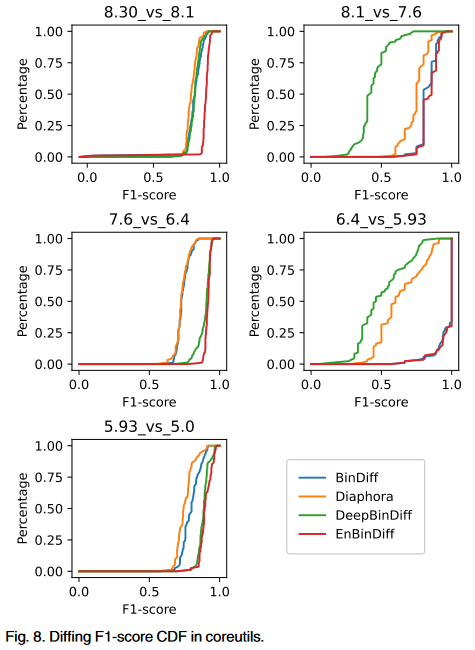
Effectiveness in Hybrid Utils Dataset
Performance
总结
References
[2] J. Peng et al., “1dVul: Discovering 1-day vulnerabilities through binary patches,” in Proc. 49th Annu. IEEE/IFIP Int. Conf. Dependable Syst. Netw., 2019, pp. 605–616.
[3] Z. Zhang, H. Zhang, Z. Qian, and B. Lau, “An investigation of the android kernel patch ecosystem,” in Proc. 30th USENIX Secur. Symp., 2021, pp. 3649–3666.
[4] D. Brumley, P. Poosankam, D. Song, and J. Zheng, “Automatic patch-based exploit generation is possible: Techniques and implications,” in Proc. IEEE Symp. Secur. Privacy, 2008, pp. 143–157.
[5] Y. Tian, J. Lawall, and D. Lo, “Identifying Linux bug fixing patches,” in Proc. 34th Int. Conf. Softw. Eng., 2012, pp. 386–396.
[6] Z. Xu, B. Chen, M. Chandramohan, Y. Liu, and F. Song, “Spain: Security patch analysis for binaries towards understanding the pain and pills,” in Proc. 39th Int. Conf. Softw. Eng., 2017, pp. 462–472.
[7] H. Flake, “Structural comparison of executable objects.,” in Proc. SIG SIDAR Conf. Detection Intrusions Malware Vulnerability Assessment, 2004, pp. 161–173.
[8] T. Dullien and R. Rolles, “Graph-based comparison of executable objects (english version),”SSTIC, vol. 5, no. 1, 2005, pp. 1–13.
[9] Zynamics Bindiff. Accessed: Oct. 28, 2019. [Online] Available: https://www.zynamics.com/bindiff.html
[10] M. Bourquin, A. King, and E. Robbins, “Binslayer: Accurate comparison of binary executables,” in Proc. 2nd ACM SIGPLAN Program Protection Reverse Eng. Workshop, 2013, pp. 1–10.
[11] C. Karamitas and A. Kehagias, “Efficient features for function matching between binary executables,” in Proc. IEEE 25th Int. Conf. Softw. Anal., Evol. Reeng., 2018, pp. 335–345.
[12] C. Karamitas and A. Kehagias, “Function matching between binary executables: Efficient algorithms and features,” J. Comput. Virol. Hacking Techn., 2019, pp. 1–17.
[13] J. Koret, “Diaphora: A free and open source program diffing tool,” Accessed: Oct. 28, 2019. [Online]. Available: http://diaphora.re/
[14] Q. Feng, R. Zhou, C. Xu, Y. Cheng, B. Testa, and H. Yin, ,“Scalable graph-based bug search for firmware images,” in Proc. ACM SIGSAC Conf. Comput. Commun. Secur., 2016, pp. 480–491.
[15] X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song, “Neural network-based graph embedding for cross-platform binary code similarity detection,” in Proc. ACM SIGSAC Conf. Comput. Commun. Secur., 2017, pp. 363–376.
[16] F. Zuo, X. Li, P. Young, L. Luo, Q. Zeng, and Zhang, “Neural machine translation inspired binary code similarity comparison beyond function pairs,” in Proc. Netw. Distrib. Syst. Secur. Symp., 2019, pp. 1–15.
[17] S. HH Ding, B. CM Fung, and P. Charland, “Asm2Vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization,” in Proc. IEEE Symp. Secur. Privacy, 2019, pp. 472–489.
[18] Y. Duan, X. Li, J. Wang, and H. Yin, “DeepBindiff: Learning program-wide code representations for binary diffing,” in Proc. Netw. Distrib. Syst. Secur. Symp., 2020, pp. 1–16.
[19] D. Gao, M. K. Reiter, and D. Song, “Binhunt: Automatically finding semantic differences in binary programs,” in Proc. Int. Conf. Inf. Commun. Secur., 2008, pp. 238–255.
[20] J. Ming, M. Pan, and D. Gao, “iBinHunt: Binary hunting with inter-procedural control flow,” in Proc. Int. Conf. Inf. Secur. Crypt., 2012, pp. 92–109.
[21] L. Luo, J. Ming, D. Wu, P. Liu, and S. Zhu, “Semantics-based obfuscation-resilient binary code similarity comparison with applications to software plagiarism detection,” in Proc. 22nd ACM SIGSOFT Int. Symp. Found. Softw. Eng., 2014, pp. 389–400.
[22] J. Oh., “Fight against 1-day exploits: Diffing binaries vs anti-diffing binaries,” Black Hat USA, 2009. [Online]. Available: https:// www.blackhat.com/presentations/bh-usa-09/OH/BHUSA09Oh-DiffingBinaries-PAPER.pdf
[23] Darpa cyber grand challenge binaries. Accessed: Oct. 28, 2019. [Online]. Available: https://github.com/CyberGrandChallenge
[24] X. Wang, K. Sun, A. Batcheller, and S. Jajodia, “Detecting “ 0-day” vulnerability: An empirical study of secret security patch in OSS.,” in Proc. 49th Annu. IEEE/IFIP Int. Conf. Dependable Syst. Netw., 2019, pp. 485–492.
[25] Hex-rays: Ida pro. Accessed: Oct. 28, 2019. [Online]. Available: https://www.hex-rays.com/products/ida/
[27] G. Balakrishnan and T. Reps, “Wysinwyx: What you see is not what you execute,” ACM Trans. Program. Lang. Syst., vol. 32, no. 6, pp. 1–84, 2010.
[28] D. Andriesse, A. Slowinska, and H. Bos., “Compiler-agnostic function detection in binaries,” in Proc. IEEE Eur. Symp. Secur. Privacy, 2017, pp. 177–189.
[29] Basic block. Accessed: May. 28, 2020. [Online]. Available: https:// en.wikipedia.org/wiki/Basic_block
Insights
(1) 尝试用大模型提高函数起始地址识别准确率