文章目录
- (95) Shuffle机制
- 什么是shuffle?
- Map阶段
- Reduce阶段
- 参考文献
(95) Shuffle机制
面试的重点
什么是shuffle?
Map方法之后,Reduce方法之前的这段数据处理过程,就叫做shuffle,中文直译"洗牌"。
参考上一小节的MR工作流程,整个shuffle的工作流程如下图,可以理解成shuffle横跨map和reduce阶段:
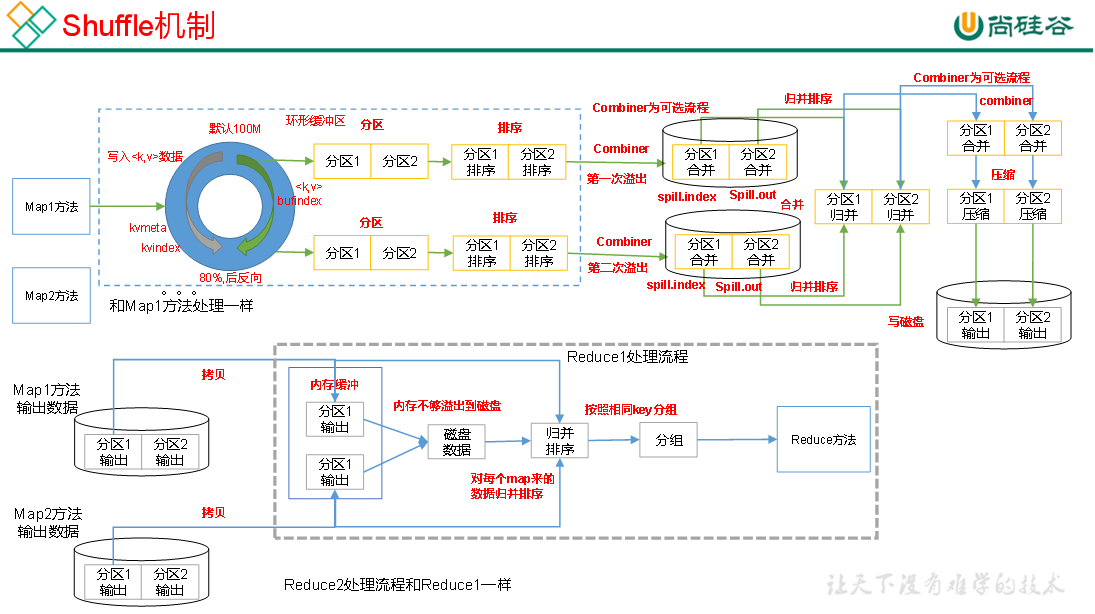
Map阶段
1) Map()处理之后的数据,会被传输进环形缓冲区,而在这个过程中,数据会被打上一个"分区",之后会讲这个分区是怎么来的。打好分区后,数据会被正式写入环形缓冲区。
2) 环形缓冲区的机制在上一小节里有介绍,看那个就行。需要注意,它在溢写到磁盘之前,需要对数据进行排序,即针对KEY值的索引,按照字典顺序进行快排。
每次溢写后会形成两个文件,一个是保存索引用的spill.index,一个是保存数据用的spill.out。这个过程中有一个可选环节,即combiner,即简单聚合,如果开启这个环节的话,会对本次溢写的文件做一些简单的预聚合,如将<a,1>, <a,1>合并成<a,2>,从而在一定程度上减轻reduce阶段的输入量。
3) 溢写会进行很多轮,即生成很多个.out文件。 当输入数据全部溢写完成后,会以分区为单位,对所有溢写结果做归并排序,并最终整合成一个大文件。相当于是在该MapTask下,最终只保留一个文件,且这个文件内部是按照分区由低到高排列,分区内部有序。
4) 归并排序后,仍然是一个可选的combiner环节,对文件内数据做再次的预聚合。
5) combiner之后,会对各分区的数据文件做压缩。从归并排序到压缩,这部分工作都是在内存中完成的,最后会将压缩后的数据写入磁盘。
为什么要进行压缩呢?
这是一个优化的手段,因为最终的输出是要传到Reduce里的,待传输的文件越小,输出的时间就越短,相比就更加高效。这个后面具体会讲
6) 最后,会将压缩后的文件放进磁盘中,等待Reduce来主动拉取。
Reduce阶段
在Reduce阶段
1) 每个ReduceTask会主动拉取Map阶段的处理结果(指定分区),优先读取到内存,因为内存里面直接处理会更快,但是如果内存不够那就没办法了,只能溢写到磁盘,后续一点点处理了。
2) 然后对从每个MapTask收上来的数据,做归并排序。
3) 归并排序完之后,再根据相同的key进行分组,分组之后的数据类似于如<key, [v1, v2, v3,...]>。
4) 最终,把分组后的数据送进Reduce(),做相应的业务逻辑处理,并输出。
以上流程,就是一个完整的shuffle流程。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】