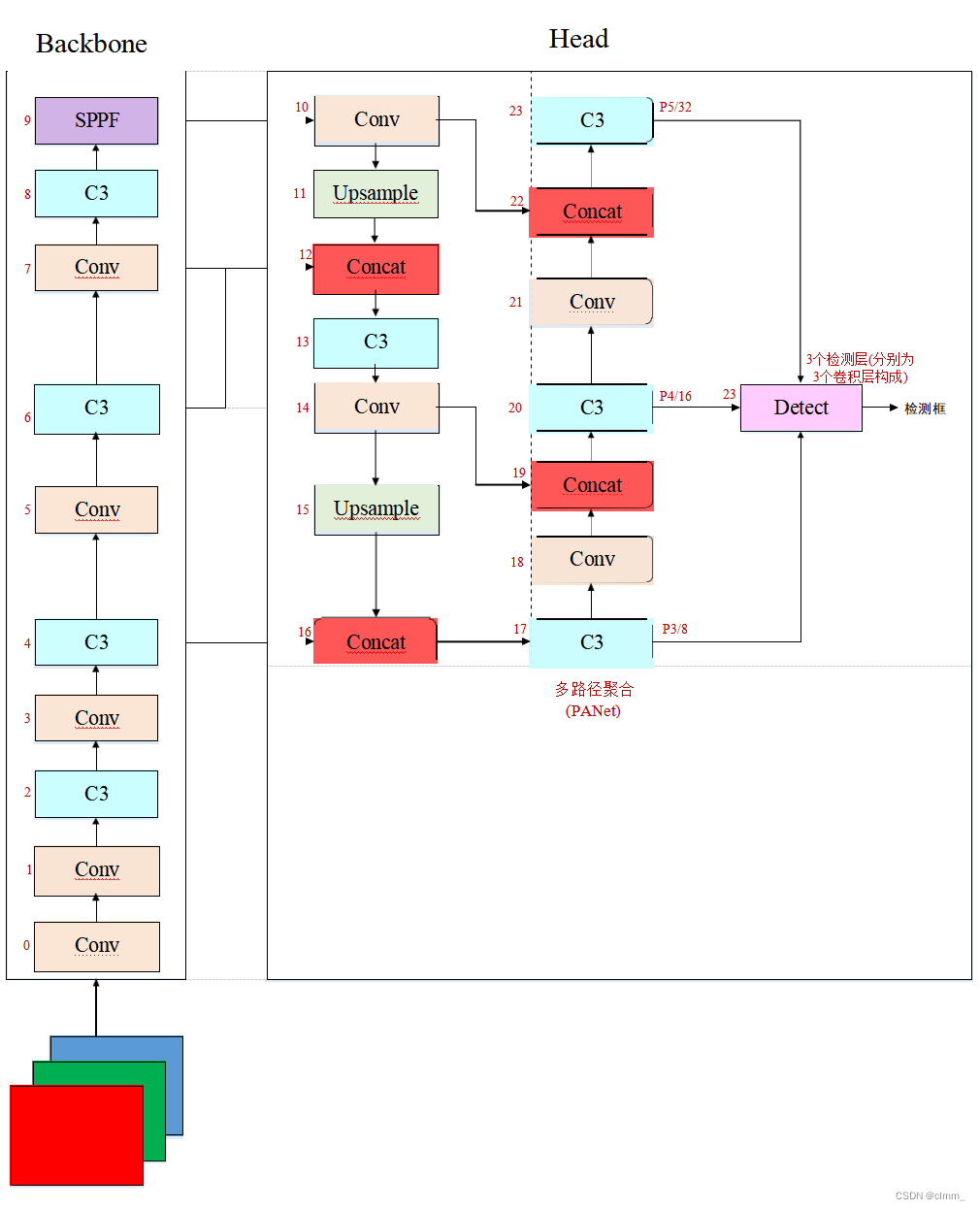
网络结构图(简易版和详细版)
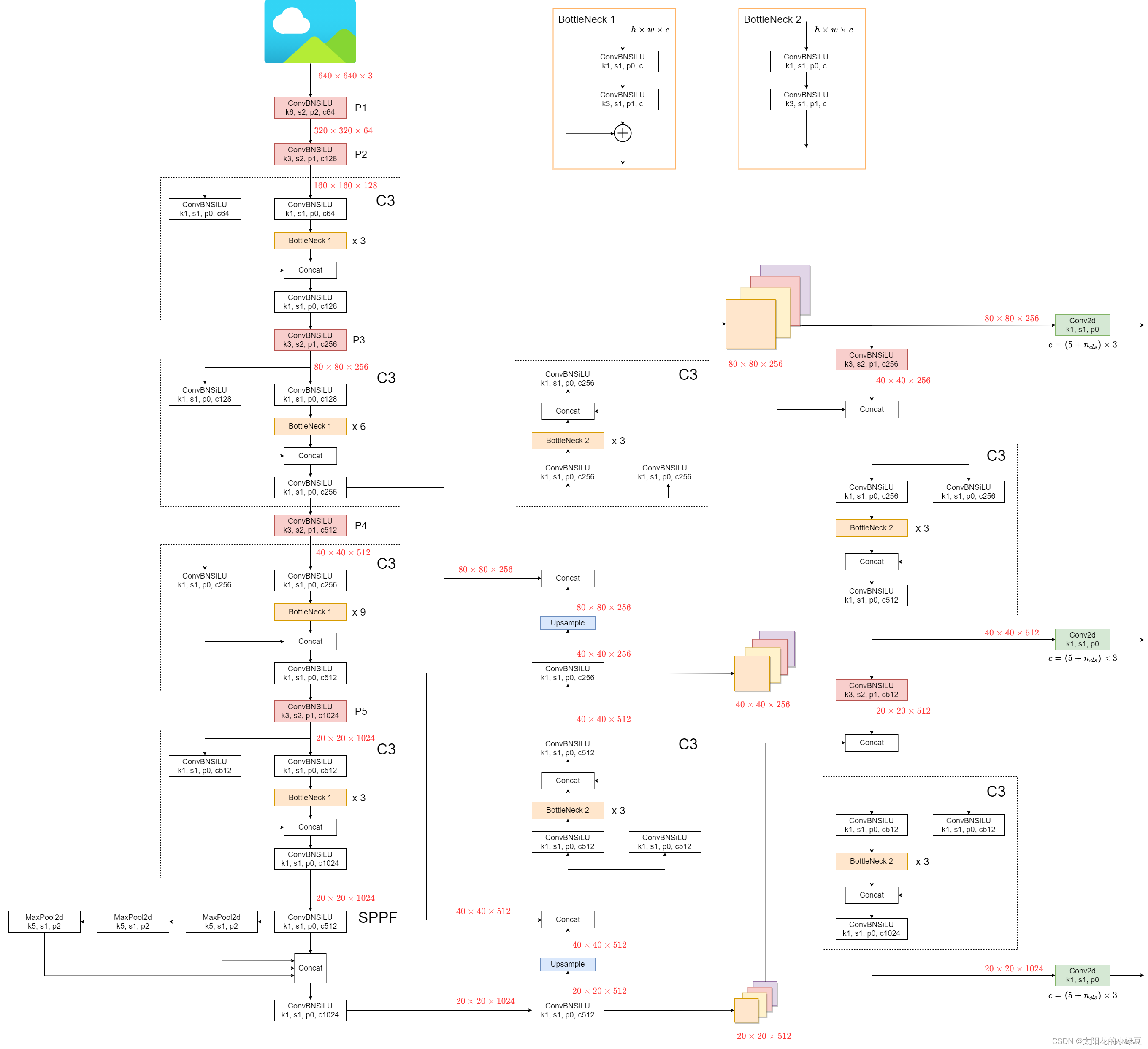
网络框架介绍
前言:
YOLOv5是一种基于轻量级卷积神经网络(CNN)的目标检测算法,整体可以分为三个部分,
backbone,neck,head。
如上图所示,我们需要先理解三个模块:Conv,C3,SPPF,以便理解网络结构图。
关于这三个模块的解释放在文章末尾。
其他我觉得有用的前置知识也会放在文章末尾。
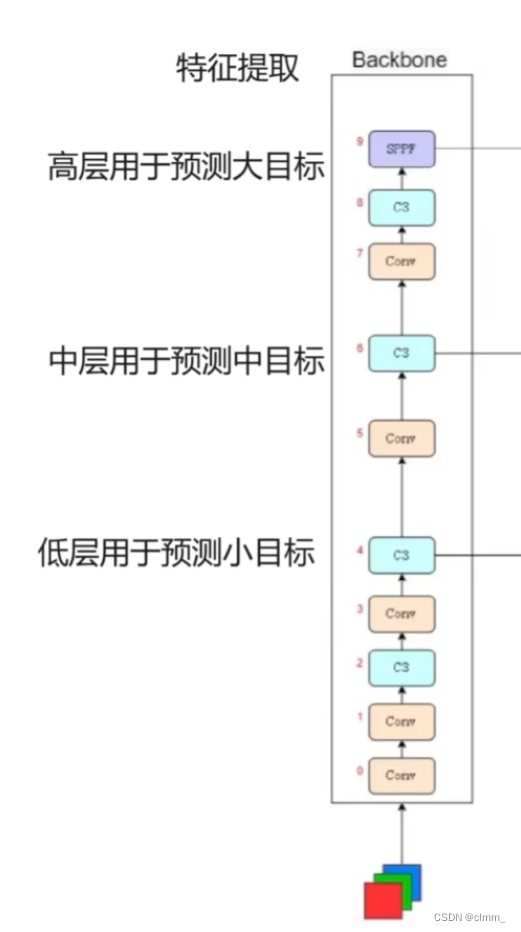
1.backbone
作用:提取特征
backbone(主干网络)通过一系列的卷积层和池化层对输入图像进行处理,逐渐降低特征图的尺寸同时增加通道数。这样做的目的是保留和提取图像中重要的特征。
经过backbone提取的特征图会传递给后续的特征金字塔网络(neck)和检测头(detection head)进行处理。
2.neck
neck(颈部)是backbone(主干网络)和detect(检测头)之间的网络模块。
作用:
在主干网络提取的特征基础上,进一步进行特征融合和上采样操作(Upsample),以提供更高级的语义信息和适应不同尺度图片的能力
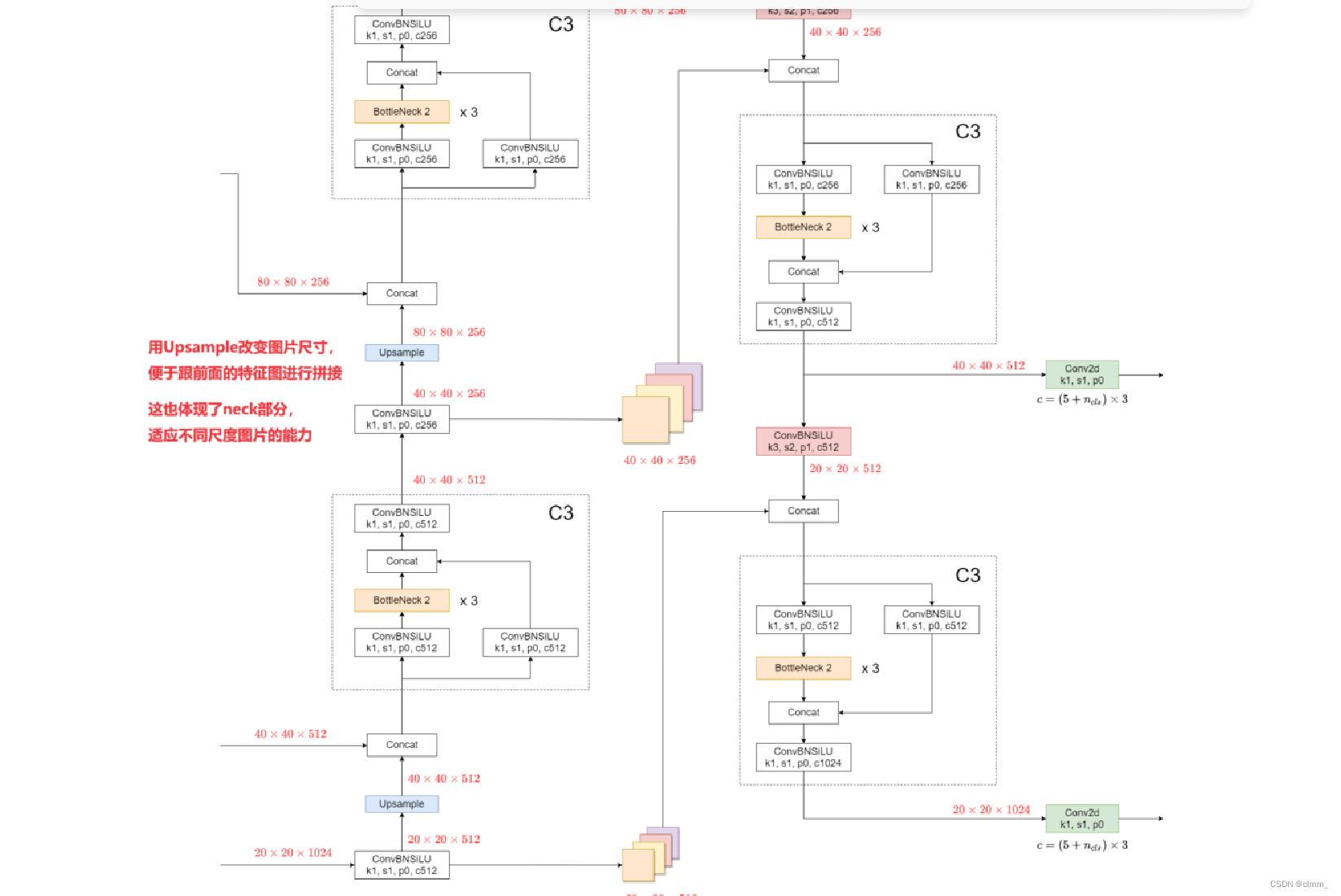
更进一步讲,
在卷积神经网络中,先从浅层提取到图形特征,它们是简单的图形,语义性不够强;
再从深层提取到语义特征,语义性很强了,但却没了简单的图形。
而通过neck部分,就能实现浅层图形特征和深层语义特征的融合,(Concat就是在做这件事情)
归根到底还是为了目标检测能够更精细、准确!
以上这段话借用自记录yolov5目标检测算法学习(模型的框架学习)23/10/10_晴友读钟的博客-CSDN博客
3.head
作用:
对提取到的特征进行进一步处理,并生成最终的输出结果。
细讲一下head中作用的其中一个方面,
特征融合与转换:head可以将不同尺度的特征进行融合和转换,这有助于捕捉更高层的语义信息和上下文关系。
我们结合网络结构图,可以看到,head接收了来自深度为第17,20,23层的特征图,
特征图分辨率越来越低,感受野越来越大,虽然可以学习到更高级的语义信息,但也会丢失细节
为了能检测到不同大小的物体(大物体在大尺度的特征图上进行检测,小物体在小尺度的特征图上进行检测),于是设计了detect模块来实现。
知识点补充
1.什么是CNN?
CNN通过模拟人类视觉系统的工作原理,通过层层堆叠的卷积层、池化层和全连接层等组件来进行图像数据的特征提取和分类。
2.什么是Conv?
Conv(卷积层)通常是由卷积(Convolution)、批标准化(Batch Normalization)和激活函数(Activation)这三个模块组成的
特点:
每经过一个Conv,原特征图大小减一半。
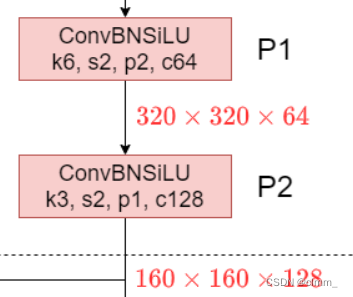
作用:
特征提取和特征融合
Conv(卷积)层的通道有什么用?
增加卷积层的通道数可以提高网络的表达能力,使其更好地适应复杂的任务。
例如:在图像分类过程中,最初的卷积层可以捕捉到低级特征,如边缘和颜色,
然而随着网络模型的深度加深,输出特征图中的模式和结构也越来越复杂。
如果网络太浅或通道数不够,则可能无法捕捉到复杂的特征,从而影响分类性能
总结:增加通道数可以使网络更加灵活和强大
3.什么是C3?

C3模块图如上。C3之所以叫C3,是因为在这个模块中有三个卷积层(Conv)
解释:
可以看到左侧卷积提取了一半的feature(特征),什么也不干,
右侧卷积也提取了一半的feature,使其经过BottleNeck(有两种)处理后,
两个部分进行Concat(拼接),然后再经过一次卷积层
作用:
从不同维度去提取特征并融合
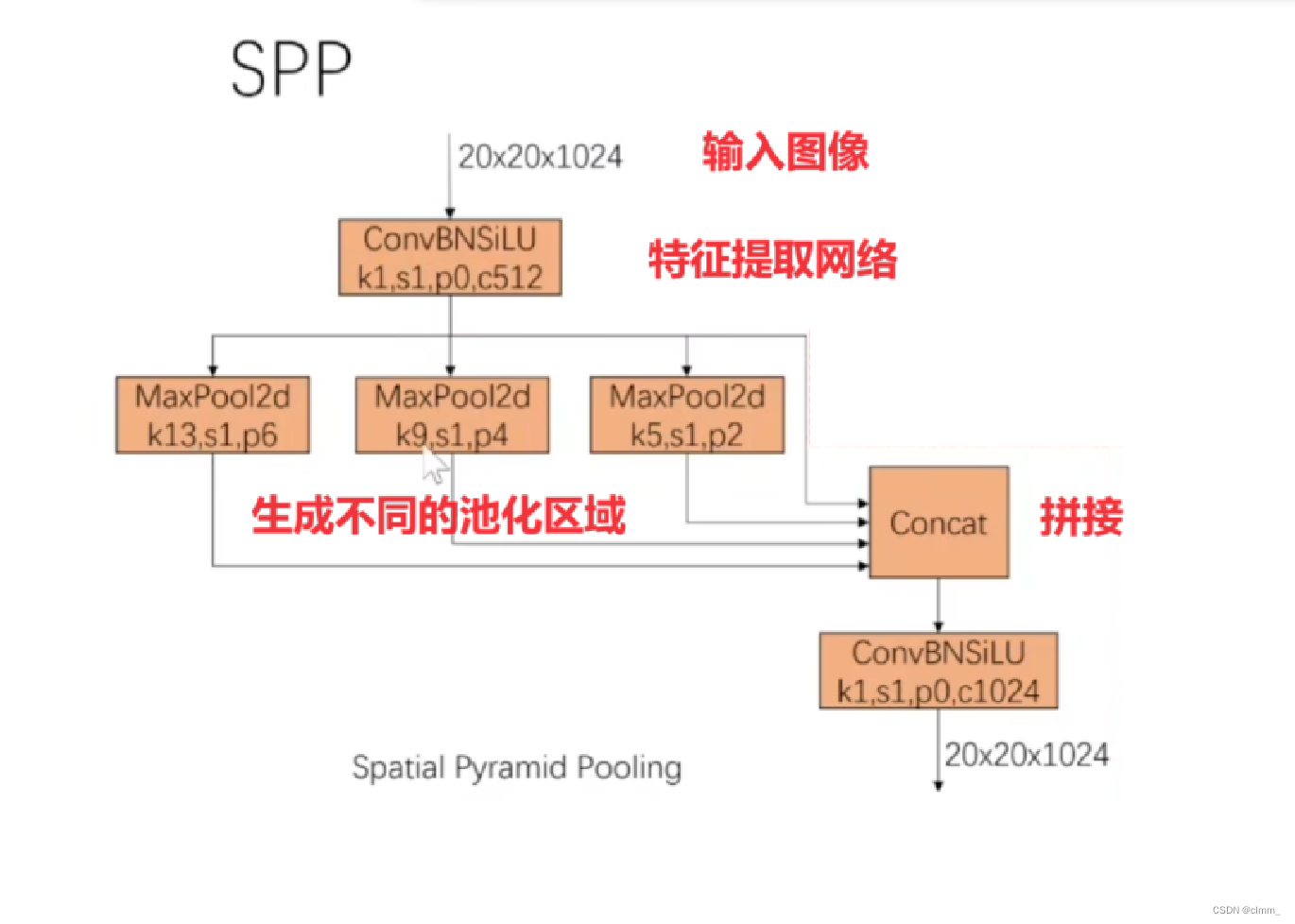
4.什么是SPPF?

了解SPPF前,我们先要知道SPP(Spatial Pyramid Pooling),中文为空间金字塔池化
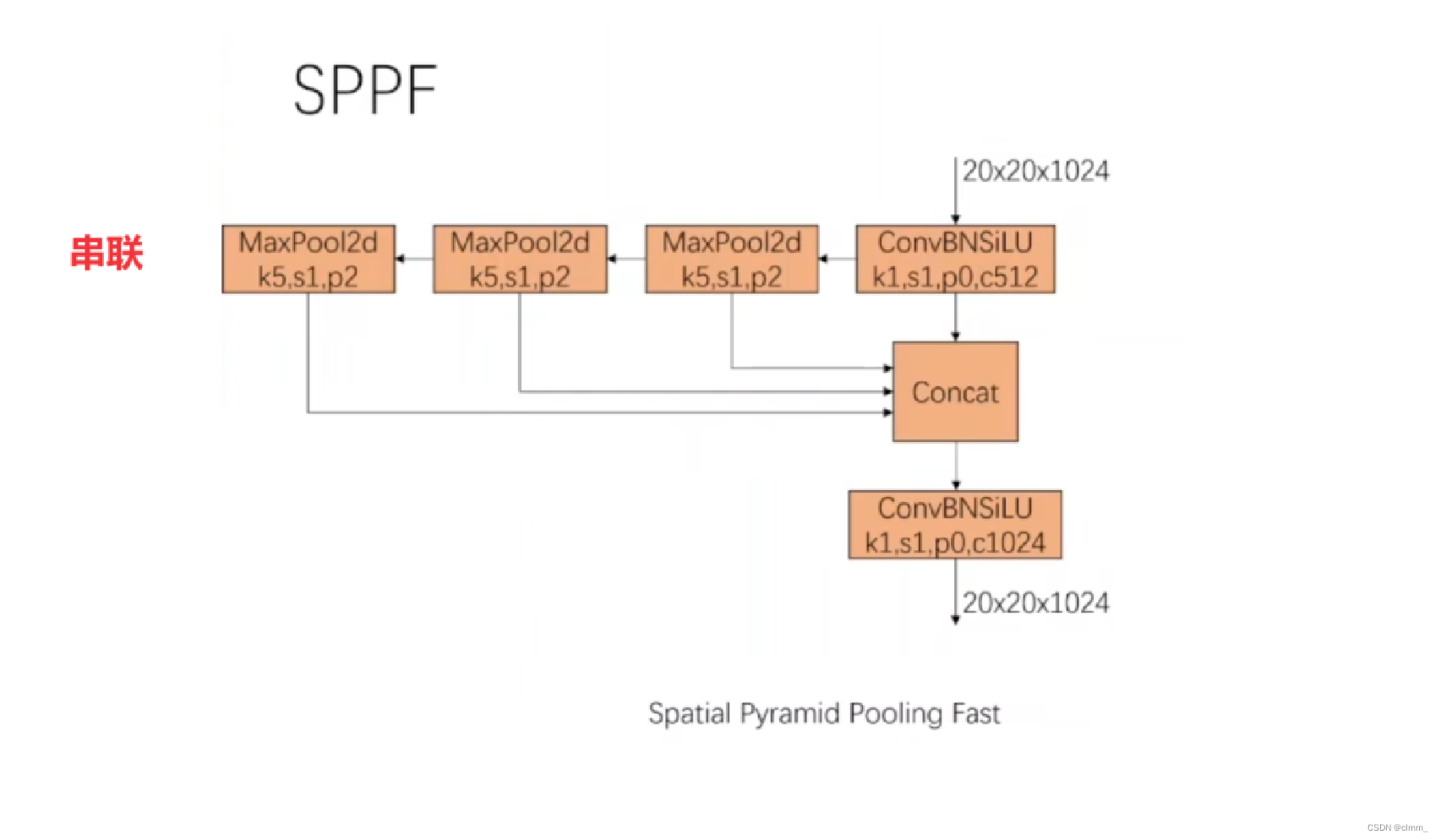
而SPPF(Spatial Pyramid Pooling Fusion)则是SPP的改进版。
什么是SPP?
在传统的CNN网络中,全连接层要求输入的特征图大小必须固定,但是图像中的物体大小和数量却是不确定的。因此,在使用全连接层之前,需要将所有的特征图resize到一个固定大小,这就会丢失掉部分信息(缺点)。
而SPP层可以通过金字塔池化的方式,在不同的尺度下进行池化操作,并将各个尺度的池化结果进行concat(拼接)作为输出,这样就可以在不改变特征图大小的情况下,得到一个固定长度的向量表示,从而解决了输入大小的问题。
作用:
特征提取和特征融合
优点:
SPP可以处理任意大小的输入特征图,因此可以避免特征图大小变化对模型的影响。
SPP是如何运作的?
1.输入图像:SPP层可以接受任意大小的输入图像。
2.特征提取网络:通常使用预训练好的卷积神经网络(CNN)来提取图像特征。
3.SPP:对于不同大小的输入图像,SPP层会自动根据其大小分别生成多个不同尺度的池化区域,在这里是13*13,9*9,5*5。然后在每个池化区域内执行最大池化操作,得到固定大小的特征向量。
4.Concat:将多个尺度的特征向量(即上一步的池化结果)进行拼接
SPPF在SPP上有何改进?
与SPP相比,SPPF的池化操作由并联变为串联,且池化区域大小不变。后面两次池化是在上一次的基础上进行的。提高了效率,原理此处不展开讲。
5.什么是语义信息?
通俗地讲,语义信息是指数据中所隐含的意义和信息。
在人类语言中,一句话由多个字词组成,每一个字词都有语义信息,我们通过分析每一个词的语义信息,就能推导出整句话的含义。
类似的,在计算机视觉中,一张图片由若干个像素组成,每一个像素都有其自身的颜色和位置信息,通过分析每一个像素的颜色和位置信息,就能推导出整张图片的含义
6.什么是图形特征?
关于这个概念,简单理解即可。
图形特征,就是一张图像所含有的特征
例如:形状,纹理,颜色,边缘等,这些都是图像的特征,统称图形特征
7.什么是上采样操作?
结构图中的Upsample就是常见的上采样操作。
作用:
上采样操作会将较低分辨率的特征图进行上采样,以恢复到与较高分辨率特征图相同的尺寸
说人话就是,把较小的输入图像恢复出较大的图像。
yolov5中的Upsample操作是为了让不同尺寸的图像拼接,特征融合
8.特征图尺度,细节信息,语义信息之间有什么联系?
较浅的特征图(即较大尺度,分辨率较高的特征图)可以捕捉到更多的细节信息,例如物体的纹理等。
较深的特征图(即较小尺度,分辨率较低的特征图)则具有更高级的语义信息,例如物体的类别,姿态等。
因此,需要利用不同尺度的特征图,以保留丰富的语义信息和细节信息。