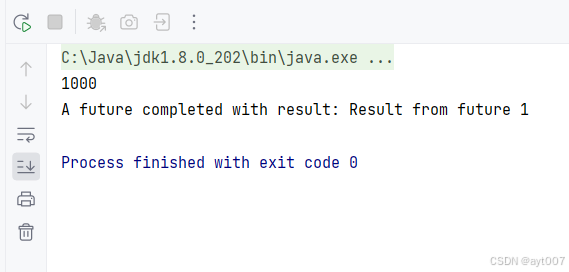
在构建 Web 应用程序时,路由是处理不同 URL 请求的核心机制。Express.js 是 Node.js 上最流行的轻量级框架之一,它简化了路由的定义和管理过程。本文将深入介绍如何使用 Express 进行路由配置,帮助你快速上手并掌握其核心概念。
什么是路由?
路由是指根据 HTTP 请求的 URL、方法(GET、POST 等)等信息来确定如何响应客户端请求的过程。在 Express 中,路由由请求方法、请求路径以及处理函数组成。通过设置不同的路由规则,可以实现对网站或 API 的精细化控制。
安装 Express
首先确保你的开发环境中已安装 Node.js 和 npm。接下来,可以通过以下命令创建一个新的项目并安装 Express:
mkdir myapp
cd myapp
npm init -y
npm install express --save基本路由
设置基本路由
下面是一个简单的例子,展示了如何为不同的 HTTP 方法定义路由:
const express = require('express');
const app = express();// GET 请求
app.get('/', (req, res) => {res.send('Hello World!');
});// POST 请求
app.post('/submit', (req, res) => {res.send('Received a POST request at /submit');
});// PUT 请求
app.put('/update', (req, res) => {res.send('Received a PUT request at /update');
});// DELETE 请求
app.delete('/delete', (req, res) => {res.send('Received a DELETE request at /delete');
});const PORT = process.env.PORT || 3000;
app.listen(PORT, () => console.log(`Server running on port ${PORT}`));动态路由
除了静态路径外,Express 还支持动态路径参数。例如,如果你想要获取用户 ID 来显示特定用户的资料页,你可以这样做:
app.get('/user/:id', (req, res) => {const userId = req.params.id;res.send(`User ID: ${userId}`);
});访问 /user/123 将返回 User ID: 123。
路由中间件
中间件是在请求到达最终的路由处理器之前执行的函数。它们可用于执行各种任务,如日志记录、身份验证等。
使用中间件
app.use((req, res, next) => {console.log(`${req.method} request for '${req.url}'`);next();
});app.get('/example', (req, res) => {res.send('This is an example route.');
});上述代码会在每次请求到来时打印出请求的方法和 URL。
错误处理中间件
错误处理中间件需要四个参数,按照 (err, req, res, next) 的顺序排列。
app.use((err, req, res, next) => {console.error(err.stack);res.status(500).send('Something broke!');
});路由模块化
随着应用的增长,保持路由逻辑的整洁变得尤为重要。Express 支持将路由分离到单独的文件中,这有助于提高代码的可维护性。
创建路由文件
创建一个名为 users.js 的文件,并添加如下内容:
const express = require('express');
const router = express.Router();router.get('/', (req, res) => {res.send('List of users');
});router.get('/:id', (req, res) => {res.send(`User with ID ${req.params.id}`);
});module.exports = router;然后,在主文件中导入并使用这个路由模块:
const userRoutes = require('./users');
app.use('/users', userRoutes);现在,当你访问 /users 或 /users/123 时,相应的路由处理函数会被调用。
结语
希望这篇文章能够帮助你在 Express 路由方面打下坚实的基础。如果你有任何问题或者想要分享你的经验,请留言交流!






![[学习笔记] Kotlin Compose-Multiplatform](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=compose.assets%2Ftooltips.gif&pos_id=img-JR8Vi11g-1738845957167)