目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
三、实验内容
0. 导入必要的工具包
1. RNN与梯度裁剪
2. LSTM模型
3. 训练函数
a. train_epoch
b. train
4. 文本预测
5. GPU判断函数
6. 训练与测试
7. 代码整合
经验是智慧之父,记忆是智慧之母。
——谚语
一、实验介绍
基于 LSTM 的语言模型训练
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
0. 导入必要的工具包
import torch
from torch import nn
from d2l import torch as d2l1. RNN与梯度裁剪
【深度学习实验】循环神经网络(一):循环神经网络(RNN)模型的实现与梯度裁剪_QomolangmaH的博客-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/133742433?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/133742433?spm=1001.2014.3001.5501
2. LSTM模型
【深度学习实验】循环神经网络(三):门控制——自定义循环神经网络LSTM(长短期记忆网络)模型-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/133864731?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63834988/article/details/133864731?spm=1001.2014.3001.5501
3. 训练函数
a. train_epoch
def train_epoch(net, train_iter, loss, updater, device, use_random_iter):state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()y = Y.T.reshape(-1)X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)metric.add(l * d2l.size(y), d2l.size(y))return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()-
参数:
net:神经网络模型train_iter:训练数据迭代器loss:损失函数updater:更新模型参数的方法(如优化器)device:计算设备(如CPU或GPU)use_random_iter:是否使用随机抽样
-
函数内部定义了一些辅助变量:
state:模型的隐藏状态变量timer:计时器,用于记录训练时间metric:累加器,用于计算训练损失之和和词元数量
-
函数通过迭代
train_iter中的数据进行训练。每次迭代中,执行以下步骤:- 如果是第一次迭代或者使用随机抽样,则初始化隐藏状态
state - 如果
net是nn.Module的实例并且state不是元组类型,则将state的梯度信息清零(detach_()函数用于断开与计算图的连接,并清除梯度信息) - 对于其他类型的模型(如
nn.LSTM或自定义模型),遍历state中的每个元素,将其梯度信息清零 - 将输入数据
X和标签Y转移到指定的计算设备上 - 使用神经网络模型
net和当前的隐藏状态state进行前向传播,得到预测值y_hat和更新后的隐藏状态state - 计算损失函数
loss对于预测值y_hat和标签y的损失,并取均值 - 如果
updater是torch.optim.Optimizer的实例,则执行优化器的相关操作(梯度清零、梯度裁剪、参数更新) - 否则,仅执行梯度裁剪和模型参数的更新(适用于自定义的更新方法)
- 将当前的损失值乘以当前批次样本的词元数量,累加到
metric中
- 如果是第一次迭代或者使用随机抽样,则初始化隐藏状态
-
训练完成后,函数返回以下结果:
- 对数似然损失的指数平均值(通过计算
math.exp(metric[0] / metric[1])得到) - 平均每秒处理的词元数量(通过计算
metric[1] / timer.stop()得到)
- 对数似然损失的指数平均值(通过计算
b. train
def train(net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False):loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)for epoch in range(num_epochs):ppl, speed = train_epoch(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:animator.add(epoch + 1, [ppl])print('Train Done!')torch.save(net.state_dict(), 'chapter6.pth')print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
- 参数
net(神经网络模型)train_iter(训练数据迭代器)vocab(词汇表)lr(学习率)num_epochs(训练的轮数)device(计算设备)use_random_iter(是否使用随机抽样)。
- 在函数内部,它使用交叉熵损失函数(
nn.CrossEntropyLoss())计算损失,创建了一个动画器(d2l.Animator)用于可视化训练过程中的困惑度(perplexity)指标。 - 根据
net的类型选择相应的更新器(updater)- 如果
net是nn.Module的实例,则使用torch.optim.SGD作为更新器; - 否则,使用自定义的更新器(
d2l.sgd)。
- 如果
- 通过迭代训练数据迭代器
train_iter来进行训练。在每个训练周期(epoch)中- 调用
train_epoch函数来执行训练,并得到每个周期的困惑度和处理速度。 - 每隔10个周期,将困惑度添加到动画器中进行可视化。
- 调用
- 训练完成后,打印出训练完成的提示信息,并将训练好的模型参数保存到文件中('chapter6.pth')。
- 打印出困惑度和处理速度的信息。
4. 文本预测
定义了给定前缀序列,生成后续序列的predict函数。
def predict(prefix, num_preds, net, vocab, device):state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]]get_input = lambda: torch.reshape(torch.tensor([outputs[-1]], device=device), (1, 1))for y in prefix[1:]: # 预热期_, state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds): # 预测num_preds步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])- 使用指定的
device和批大小为1调用net.begin_state(),初始化state变量。 - 使用
vocab[prefix[0]]将第一个标记在prefix中对应的索引添加到outputs列表中。 - 定义了一个
get_input函数,该函数返回最后一个输出标记经过reshape后的张量,作为神经网络的输入。 - 对于
prefix中除第一个标记外的每个标记,通过调用net(get_input(), state)进行前向传播。忽略输出的预测结果,并将对应的标记索引添加到outputs列表中。
5. GPU判断函数
def try_gpu(i=0):"""如果存在,则返回gpu(i),否则返回cpu()"""if torch.cuda.device_count() >= i + 1:return torch.device(f'cuda:{i}')return torch.device('cpu')6. 训练与测试
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_epochs, lr= 28, 256, 200, 1
device = try_gpu()
lstm_layer = nn.LSTM(vocab_size, num_hiddens)
model_lstm = RNNModel(lstm_layer, vocab_size)
train(model_lstm, train_iter, vocab, lr, num_epochs, device)-
训练中每个小批次(batch)的大小和每个序列的时间步数(time step)的值分别为32,25
-
加载的训练数据迭代器和词汇表
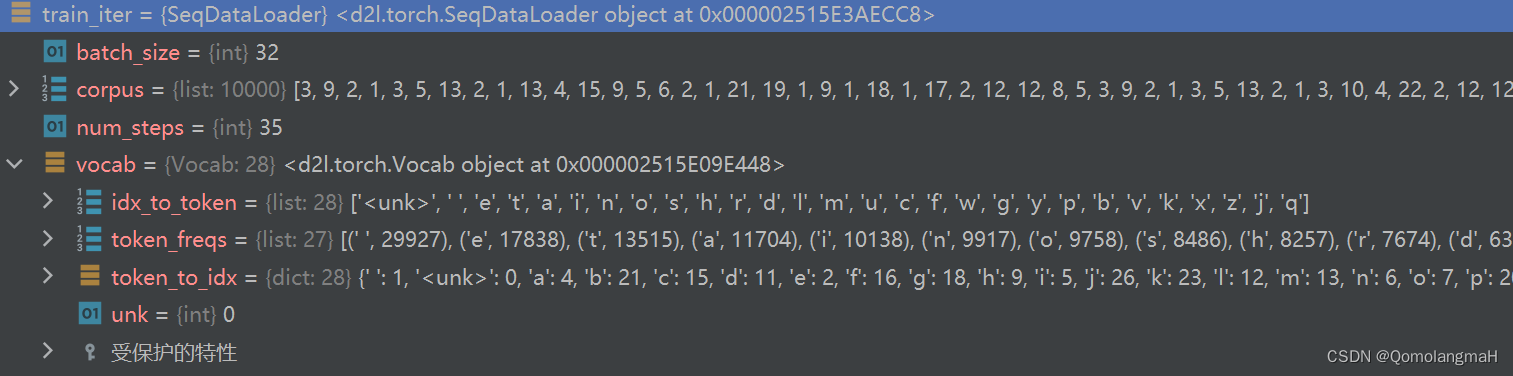
-
vocab_size是词汇表的大小,num_hiddens是 LSTM 隐藏层中的隐藏单元数量,num_epochs是训练的迭代次数,lr是学习率。 -
选择可用的 GPU 设备进行训练,如果没有可用的 GPU,则会使用 CPU。
-
训练模型
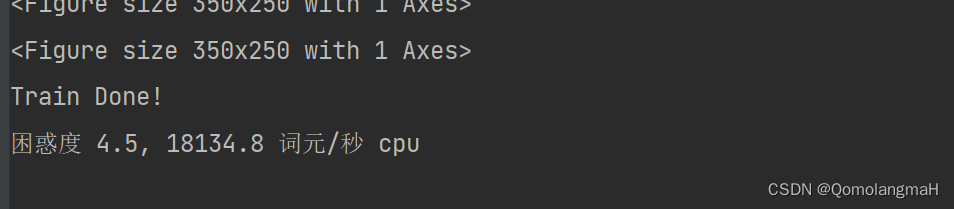
7. 代码整合
# 导入必要的库
import torch
from torch import nn
import torch.nn.functional as F
from d2l import torch as d2l
import mathclass LSTM(nn.Module):def __init__(self, input_size, hidden_size):super(LSTM, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_size# 初始化模型,即各个门的计算参数self.W_i = nn.Parameter(torch.randn(input_size, hidden_size))self.W_f = nn.Parameter(torch.randn(input_size, hidden_size))self.W_o = nn.Parameter(torch.randn(input_size, hidden_size))self.W_a = nn.Parameter(torch.randn(input_size, hidden_size))self.U_i = nn.Parameter(torch.randn(hidden_size, hidden_size))self.U_f = nn.Parameter(torch.randn(hidden_size, hidden_size))self.U_o = nn.Parameter(torch.randn(hidden_size, hidden_size))self.U_a = nn.Parameter(torch.randn(hidden_size, hidden_size))self.b_i = nn.Parameter(torch.randn(1, hidden_size))self.b_f = nn.Parameter(torch.randn(1, hidden_size))self.b_o = nn.Parameter(torch.randn(1, hidden_size))self.b_a = nn.Parameter(torch.randn(1, hidden_size))self.W_h = nn.Parameter(torch.randn(hidden_size, hidden_size))self.b_h = nn.Parameter(torch.randn(1, hidden_size))# 初始化隐藏状态def init_state(self, batch_size):hidden_state = torch.zeros(batch_size, self.hidden_size)cell_state = torch.zeros(batch_size, self.hidden_size)return hidden_state, cell_statedef forward(self, inputs, states=None):batch_size, seq_len, input_size = inputs.shapeif states is None:states = self.init_state(batch_size)hidden_state, cell_state = statesoutputs = []for step in range(seq_len):inputs_step = inputs[:, step, :]i_gate = torch.sigmoid(torch.mm(inputs_step, self.W_i) + torch.mm(hidden_state, self.U_i) + self.b_i)f_gate = torch.sigmoid(torch.mm(inputs_step, self.W_f) + torch.mm(hidden_state, self.U_f) + self.b_f)o_gate = torch.sigmoid(torch.mm(inputs_step, self.W_o) + torch.mm(hidden_state, self.U_o) + self.b_o)c_tilde = torch.tanh(torch.mm(inputs_step, self.W_a) + torch.mm(hidden_state, self.U_a) + self.b_a)cell_state = f_gate * cell_state + i_gate * c_tildehidden_state = o_gate * torch.tanh(cell_state)y = torch.mm(hidden_state, self.W_h) + self.b_houtputs.append(y)return torch.cat(outputs, dim=0), (hidden_state, cell_state)class RNNModel(nn.Module):def __init__(self, rnn_layer, vocab_size, **kwargs):super(RNNModel, self).__init__(**kwargs)self.rnn = rnn_layerself.vocab_size = vocab_sizeself.num_hiddens = self.rnn.hidden_sizeself.num_directions = 1self.linear = nn.Linear(self.num_hiddens, self.vocab_size)def forward(self, inputs, state):X = F.one_hot(inputs.T.long(), self.vocab_size)X = X.to(torch.float32)Y, state = self.rnn(X, state)# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)# 它的输出形状是(时间步数*批量大小,词表大小)。output = self.linear(Y.reshape((-1, Y.shape[-1])))return output, state# 在第一个时间步,需要初始化一个隐藏状态,由此函数实现def begin_state(self, device, batch_size=1):if not isinstance(self.rnn, nn.LSTM):# nn.GRU以张量作为隐状态return torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens),device=device)else:# nn.LSTM以元组作为隐状态return (torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device),torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device))def train(net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False):loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',legend=['train'], xlim=[10, num_epochs])if isinstance(net, nn.Module):updater = torch.optim.SGD(net.parameters(), lr)else:updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)for epoch in range(num_epochs):ppl, speed = train_epoch(net, train_iter, loss, updater, device, use_random_iter)if (epoch + 1) % 10 == 0:animator.add(epoch + 1, [ppl])print('Train Done!')torch.save(net.state_dict(), 'chapter6.pth')print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')def train_epoch(net, train_iter, loss, updater, device, use_random_iter):state, timer = None, d2l.Timer()metric = d2l.Accumulator(2) # 训练损失之和,词元数量for X, Y in train_iter:if state is None or use_random_iter:# 在第一次迭代或使用随机抽样时初始化statestate = net.begin_state(batch_size=X.shape[0], device=device)if isinstance(net, nn.Module) and not isinstance(state, tuple):# state对于nn.GRU是个张量state.detach_()else:# state对于nn.LSTM或对于我们从零开始实现的模型是个张量for s in state:s.detach_()y = Y.T.reshape(-1)X, y = X.to(device), y.to(device)y_hat, state = net(X, state)l = loss(y_hat, y.long()).mean()if isinstance(updater, torch.optim.Optimizer):updater.zero_grad()l.backward()grad_clipping(net, 1)updater.step()else:l.backward()grad_clipping(net, 1)# 因为已经调用了mean函数updater(batch_size=1)metric.add(l * d2l.size(y), d2l.size(y))return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()def predict(prefix, num_preds, net, vocab, device):state = net.begin_state(batch_size=1, device=device)outputs = [vocab[prefix[0]]]get_input = lambda: torch.reshape(torch.tensor([outputs[-1]], device=device), (1, 1))for y in prefix[1:]: # 预热期_, state = net(get_input(), state)outputs.append(vocab[y])for _ in range(num_preds): # 预测num_preds步y, state = net(get_input(), state)outputs.append(int(y.argmax(dim=1).reshape(1)))return ''.join([vocab.idx_to_token[i] for i in outputs])def grad_clipping(net, theta):if isinstance(net, nn.Module):params = [p for p in net.parameters() if p.requires_grad]else:params = net.paramsnorm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))if norm > theta:for param in params:param.grad[:] *= theta / normdef try_gpu(i=0):"""如果存在,则返回gpu(i),否则返回cpu()"""# if torch.cuda.device_count() >= i + 1:# return torch.device(f'cuda:{i}')return torch.device('cpu')batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_epochs, lr= 28, 256, 200, 1
device = try_gpu()
lstm_layer = nn.LSTM(vocab_size, num_hiddens)
model_lstm = RNNModel(lstm_layer, vocab_size)
train(model_lstm, train_iter, vocab, lr, num_epochs, device)