这里介绍两种
1. 基于SAM的点云标注
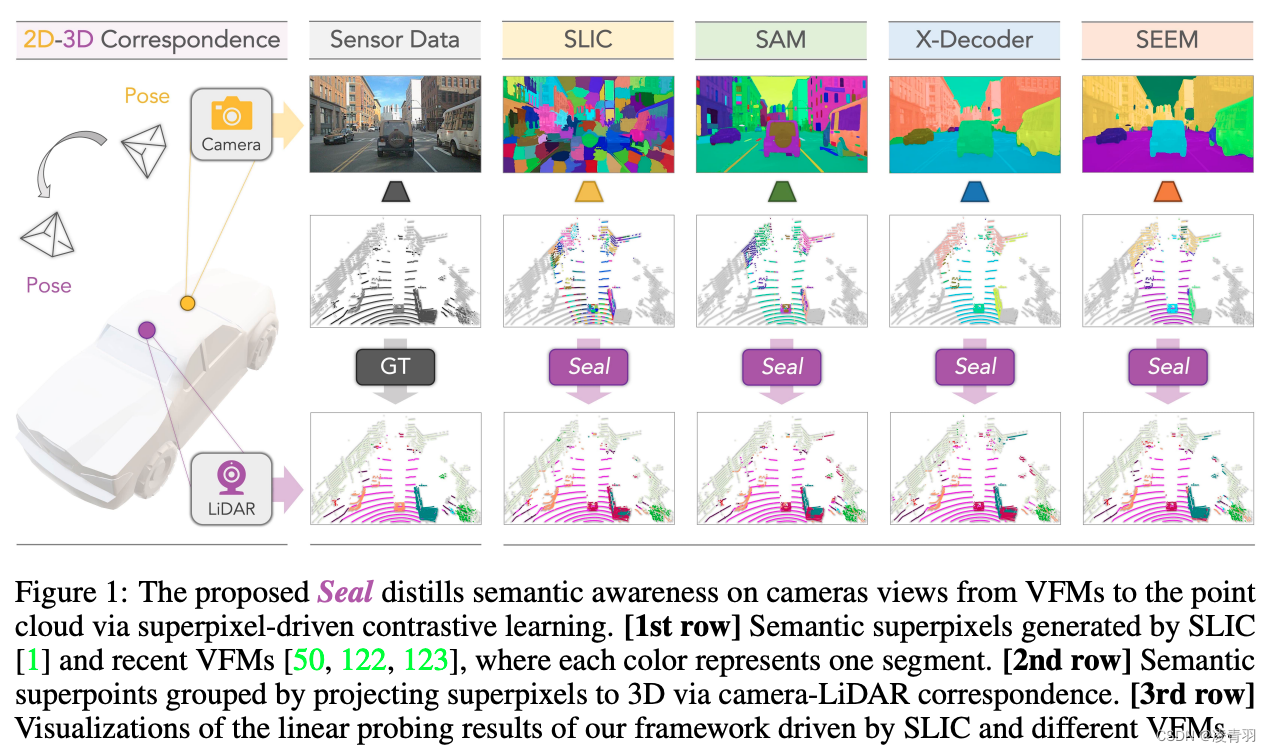
Seal:是一个多功能的自监督学习框架,能够通过利用视觉基础模型的现成知识和2D-3D的时空约束分割自动驾驶数据集点云
- Scalability:可拓展性强,视觉基础模型蒸馏到点云中,避免2D和3D的标注
- Consistency:时空关系的约束在camera-to-lidar和点到分割这两个阶段得到应用,加速了多模态的表征学习
点云通过坐标变换投影到图像上,只要我们分割图像像素的类别,就得到点云的类别(见下图)
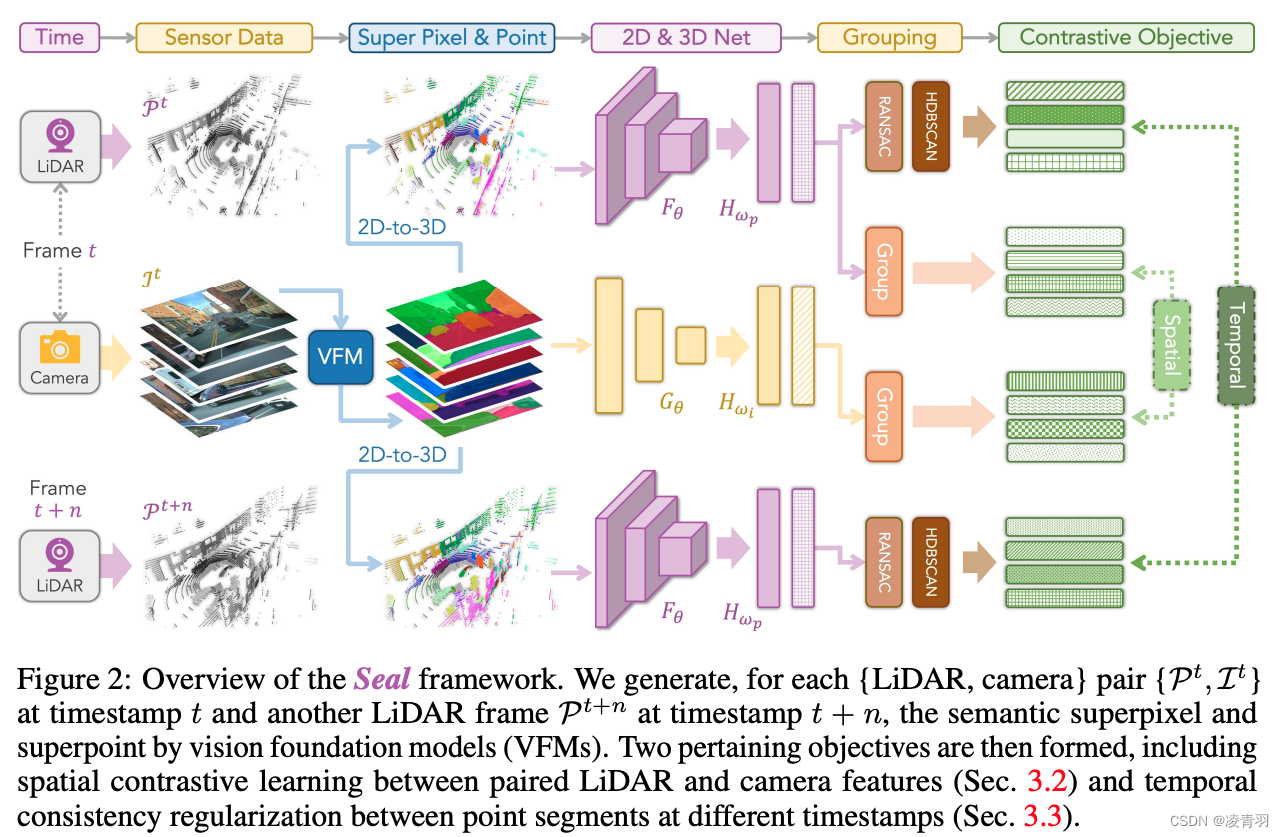
3D框生成步骤(见下图):
- SAM分割图像中每个点的类别(点为prompt,prompt的形式由三种:点、框、)
- 坐标系对齐:不同时间戳的对齐,组成(camera,lidar)pair
- 点云投影到SAM分割后的图像得到点云分割的结果
- 多帧时序结果对点云分割做进一步优化
- 对每个类别的点云分割结果做最小外接矩形框得到3D框,结合每个类别的长宽高先验,再进一步优化
- 比如小轿车:4.61.81.4;中型轿车&皮卡:4.91.91.8; 行人:0.60.71.7
- 比如小轿车:4.61.81.4;中型轿车&皮卡:4.91.91.8; 行人:0.60.71.7
- 点云对齐到图像:
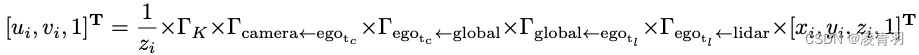
2. 基于离线点云3D检测模型的自动标注
2.1. CTRL(图森)—— 检测+跟踪
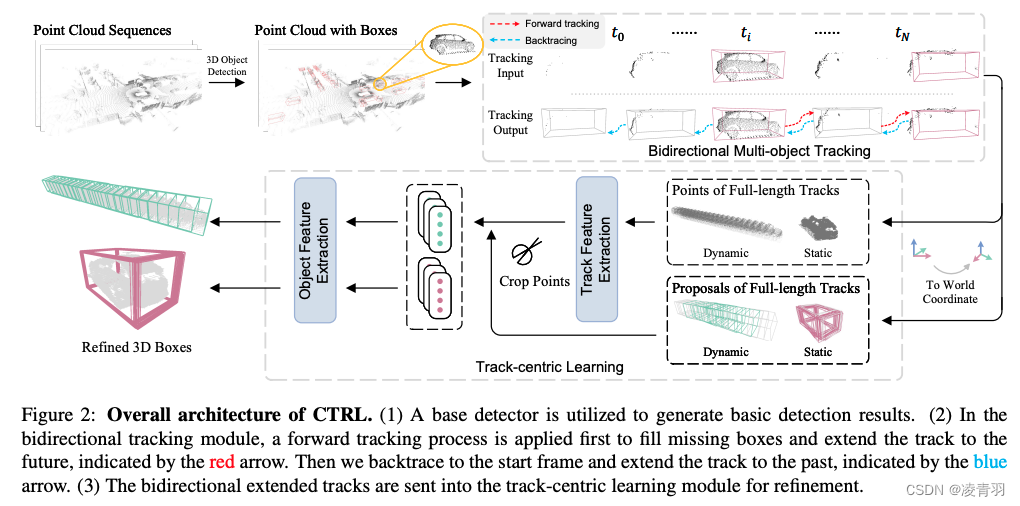
图森提出一种基于轨迹的离线的激光雷达检测模型(一旦检测,永不丢失)—— CTRL(https://github.com/tusen-ai/SST)
- 动机:经验丰富的标注人员会以轨迹为中心的视角来标注物体,首先标注轨迹中形状清晰的物体,然后利用时间上的连续性来推断模糊物体(遮挡或点云少)的标注
- 方法概述:
- 采用轨迹为中心的视角,而不是传统的物体为中心的视角
- 采用双向跟踪模块和轨迹为中心的学习模块
算法流程:
- 检测模型(FSDv2,FSD V2: Improving Fully Sparse 3D Object
Detection with Virtual Voxels)得到初步检测结果 - 双向跟踪模块:
- 在跟踪过程中,采用简单的运动模块来填补模型检测的难例,并双向拓展轨迹,大大延长了轨迹的生命周期
- Refine
- 原因:简单运动模型无法检测物体准确位姿
- 解决:提出track-centric learning模块来进一步refine
- 具体步骤:把所有点云和proposal当作输入,送入refine模块
检测-跟踪-refine详细步骤:
- 检测:
- 采用frame-skigping的多帧合并检测,隔一帧,添加一帧,来减少计算量
- 添加一帧??什么意思
- 为了防止过拟合,采用frame dropout 策略,有一半的frame会有20%的几率被dropout
- 检测模块存在问题:误检和漏检,提高检测的过滤阈值,会导致漏检,需要引入跟踪模块
- 思考:它通过把误检的先去掉,来单独解决漏检的问题
- 采用frame-skigping的多帧合并检测,隔一帧,添加一帧,来减少计算量
- 双向跟踪:
- Forward tracking:填充早期有检出,中间漏检的框
- 当tracklet在一定时间步长,没有相匹配的观测,跟踪的前向运动模块会预测一个pseudo-3D box;所以tracklet不会消亡,直到序列结束或目标超出预设的范围。遮挡和截断等难例也能在长时间的跟踪中被检出
- Back tracking:填充在首次检测之前的漏检框
- 动机:物体的出现和消失是连续
- 方法:采用反向的运动模型,从未来有检测帧去反推历史帧的漏检框
- Forward tracking:填充早期有检出,中间漏检的框
- Refine模块-tracking-centric learning
- 原因:跟踪模块存在问题:跟踪模块增加的框的位置和置信度相对不准,导致false positive增加,需要refine
- Multiple-in-multiple-out:
- 根据扩大后track proposal把整个序列的点云crop下来,downsample到1024个点(防止显存不足),并转到第一帧的全局坐标上,且把同一个track内的点云concat在一起,作为一个训练sample
- Track feature extraction
- 采用sparse unet为backbone提取track feature(point-wise feature)
- Object feature extraction
- 扩大后Proposal去crop track feature,确保crop物体的完整性
- Point net去提取特征,对于不同timestamp的crop roi会添加一个编号,表示从哪个timestamp crop下来的