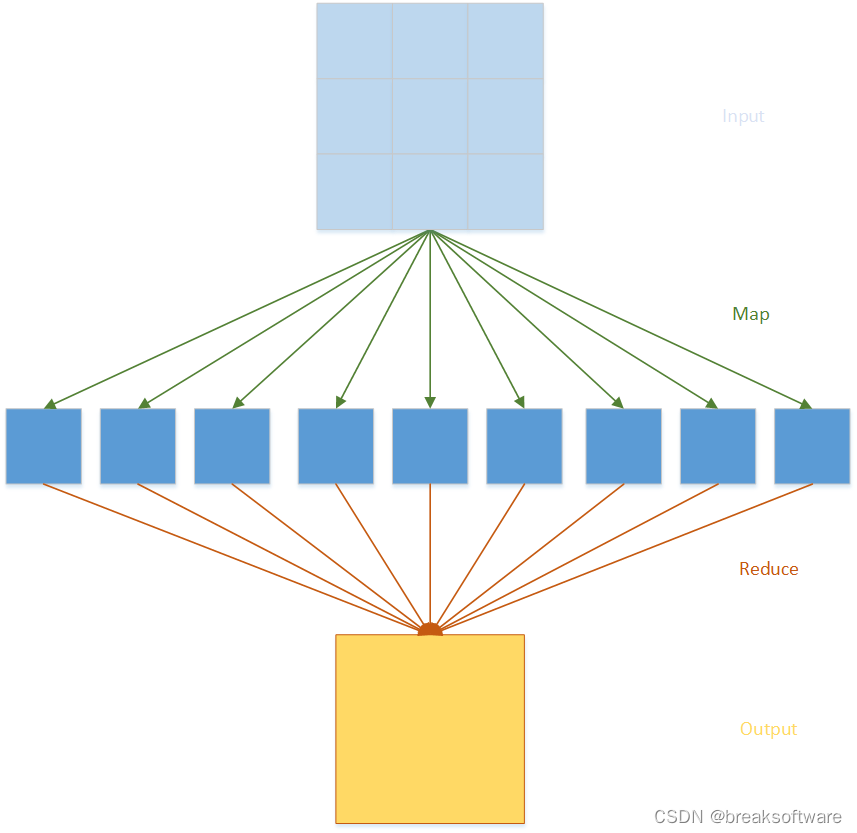
视频数据标注是对视频剪辑进行标注的过程。进行标注后的视频数据将作为训练数据集用于训练深度学习和机器学习模型。这些预先训练的神经网络之后会被用于计算机视觉领域。
自动化视频标注对训练AI模型有哪些优势
与图像数据标注类似,视频标注是教计算机识别对象的过程。两种数据标注方法都是更广泛的人工智能领域——计算机视觉(Computer Vision)的一部分,该领域旨在训练计算机模仿人眼的感知质量。 在视频数据标注项目中,人工标注员和自动化工具被结合起来用于标记视频素材中的目标对象。然后,这种经过标记的素材会由一台由AI支持的计算机进行处理,理想情况下会通过机器学习技术发现如何识别未标记的新视频中的目标对象。视频标签越准确,AI模型的表现就越好。借助自动化工具进行精确视频标注可帮助公司自信地部署并快速扩展。观看下方视频了解视频标注,及其和图像标注的区别。

视频与图像数据标注的差异
视频标注与图像标注有很多相似之处。我们在图像标注文章中介绍了标准图像标注技术,其中许多技术都与将标签应用于视频有关。但是,这两个过程之间存在显著差异,如果公司要在这两种数据类型之间作出选择,这种差异可以帮助他们作出决定。
一、数据
视频的数据结构比图像更复杂。但是,就每个数据单位的信息而言,视频的洞察力更强。利用视频,团队不仅可以识别对象的位置,还可以识别该对象是否在移动以及在向哪个方向移动。例如,图像无法表明一个人正在坐下去还是站起来。但一段视频就可以。 视频还可以利用先前帧中的信息来识别可能被部分遮挡的对象。而图像不具备这个功能。考虑到这些因素,每个数据单位的视频可以提供比图像更多的信息。
二、标注过程
与图像标注相比,视频标注的难度又高了一层。标注员必须同步和跟踪在各帧之间不断变换状态的对象。为了提高效率,许多团队使用自动化的流程组件。当今的计算机可以在无需人工干预的情况下跨帧跟踪对象,因此可以用较少的人工来标注整个视频片段。最终结果是,视频标注过程通常比图像标注快得多。
三、准确性
使用自动化工具标注视频时,帧与帧之间有更好的连续性,发生错误的几率更低。标注多张图像时,必须对同一对象使用相同的标签,但可能会出现一致性错误。标注视频时,计算机可以自动跨帧跟踪一个对象,并在整个视频中通过背景来记住该对象。与图像标注相比,这种方式具有更高的一致性和准确性,从而提高AI模型预测的准确性。 考虑到上述因素,在可以选择的情况下,公司都会倾向于视频标注而不是图像标注。视频所需的人力标注成本远远少于图像标注,从而大幅缩短了标注时间,但具有更高的准确度和更大规模的标注量。 进行标注后的视频数据将作为训练数据集用于训练深度学习和机器学习模型。这些预先训练的神经网络之后会被广泛应用于计算机视觉。计算机视觉是使用机器学习和深度学习模型处理视觉数据的工具、被大量应用于人脸识别、图像分类和自动视频标注平台等场景中。