jenkins备份还原配置文件











本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/16428.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章


vue纯静态实现 视频转GIF 功能(附源码)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、实现后的效果二、使用步骤1.引入库2.下载or复制出来js3. 前端实现 总结 前言
一天一个小demo 今天来一个vue纯静态实现 视频转GIF 功能
上一篇我们讲到了…

嵌入式八股文面试题(二)C语言算法
相关概念请查看文章:C语言概念。
1. 如何实现一个简单的内存池? 简单实现: #include <stdio.h>
#include <stdlib.h>//内存块
typedef struct MemoryBlock {void *data; // 内存块起始地址struct MemoryBlock *next; // 下一个内…

【Python】集合
个人主页:GUIQU. 归属专栏:Python 文章目录 1. 集合的创建2. 集合的基本操作2.1 访问集合元素2.2 添加元素2.3 删除元素 3. 集合的数学运算3.1 交集(& 或 intersection() 方法)3.2 并集(| 或 union() 方法…

Flutter_学习记录_基本组件的使用记录_2
1. PopupMenuButton的使用
代码案例:
import package:flutter/material.dart;// ----PopupMemuButtonDemo的案例----
class PopupMemuButtonDemo extends StatefulWidget {const PopupMemuButtonDemo({super.key});overrideState<PopupMemuButtonDemo> crea…

基于java手机销售网站设计和实现(LW+源码+讲解)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…


PyTorch 中 `torch.cuda.amp` 相关警告的解决方法
在最近的写代码过程中,遇到了两个与 PyTorch 的混合精度训练相关的警告信息。这里随手记录一下。 警告内容
警告 1: torch.cuda.amp.autocast
FutureWarning: torch.cuda.amp.autocast(args...)
is deprecated. Please use torch.amp.autocast(cuda, args...)
i…

【PS 2022】Adobe Genuine Service Alert 弹出
电脑总是弹出Adobe Genuine Service Alert弹窗
1. 不关掉弹窗并打开任务管理器,找到Adobe Genuine Service Alert,并右键进入文件所在位置 2 在任务管理器中结束进程并将文件夹中的 .exe 文件都使用空文档替换掉 3. 打开PS不弹出弹窗,解决&a…

Vue2生命周期面试题
在 Vue 2 中,this.$el 和 this.$data 都是 Vue 实例的属性,代表不同的内容。
1. this.$el
this.$el 是 Vue 实例的根 DOM 元素,它指向 Vue 实例所控制的根节点元素。在 Vue 中,el 是在 Vue 实例创建时,指定的根元素&…

unity 安装Entities
因为Entities目前不支持用资源名动态加载资源!没错,AssetsBundle或Addressables都不能用于Entities;也就意味着现阶段不能用Entities开发DLC或热更游戏。
Entities必须使用SubScene,而SubScene不能从资源动态加载,路被…

基于 PyTorch 的树叶分类任务:从数据准备到模型训练与测试
基于 PyTorch 的树叶分类任务:从数据准备到模型训练与测试 1. 引言
在计算机视觉领域,图像分类是一个经典的任务。本文将详细介绍如何使用 PyTorch 实现一个树叶分类任务。我们将从数据准备开始,逐步构建模型、训练模型,并在测试…

团结引擎 Shader Graph:解锁图形创作新高度
Shader Graph 始终致力于为开发者提供直观且高效的着色器构建工具,持续推动图形渲染创作的创新与便捷。在团结引擎1.4.0中,Shader Graph 迎来了重大更新,新增多项强大功能并优化操作体验,助力开发者更轻松地实现高质量的渲染效果与…

C# OpenCV机器视觉:模仿Halcon各向异性扩散滤波
在一个充满创意与挑战的图像处理工作室里,阿强是一位热情的图像魔法师。他总是在追求更加出色的图像效果,然而,传统的图像处理方法有时候并不能满足他的需求。
有一天,阿强听说了 Halcon 中的各向异性扩散滤波功能,它…

超详细的数据结构3(初阶C语言版)栈和队列。
文章目录 栈和队列1.栈1.1 概念与结构1.2 栈的实现 2. 队列2.1 概念与结构2.2 队列的实现 总结 栈和队列
1.栈
1.1 概念与结构
栈:⼀种特殊的线性表,其只允许在固定的⼀端进行插⼊和删除元素操作。进⾏数据插⼊和删除操作的⼀端称为栈顶,另…

利用邮件合并将Excel的信息转为Word(单个测试用例转Word)
利用邮件合并将Excel的信息转为Word 效果一览效果前效果后 场景及问题解决方案 一、准备工作准备Excel数据源准备Word模板 二、邮件合并操作步骤连接Excel数据源插入合并域预览并生成合并文档 效果一览
效果前 效果后 场景及问题
在执行项目时的验收阶段,对于测试…
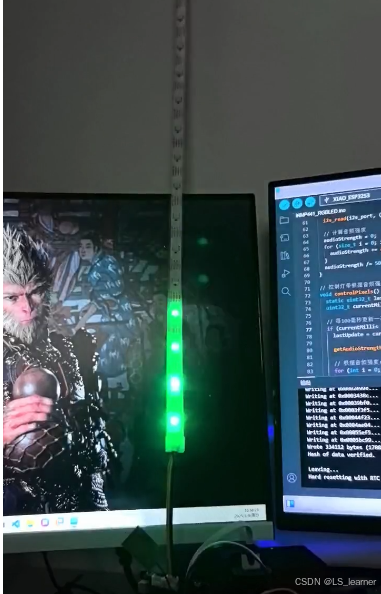
一个基于ESP32S3和INMP441麦克风实现音频强度控制RGB灯带律动的代码及效果展示
一个基于ESP32S3和INMP441麦克风实现音频强度控制RGB灯带律动的代码示例,使用Arduino语言:
硬件连接
INMP441 VCC → ESP32的3.3VINMP441 GND → ESP32的GNDINMP441 SCK → ESP32的GPIO 17INMP441 WS → ESP32的GPIO 18INMP441 SD → ESP32的GPIO 16RG…

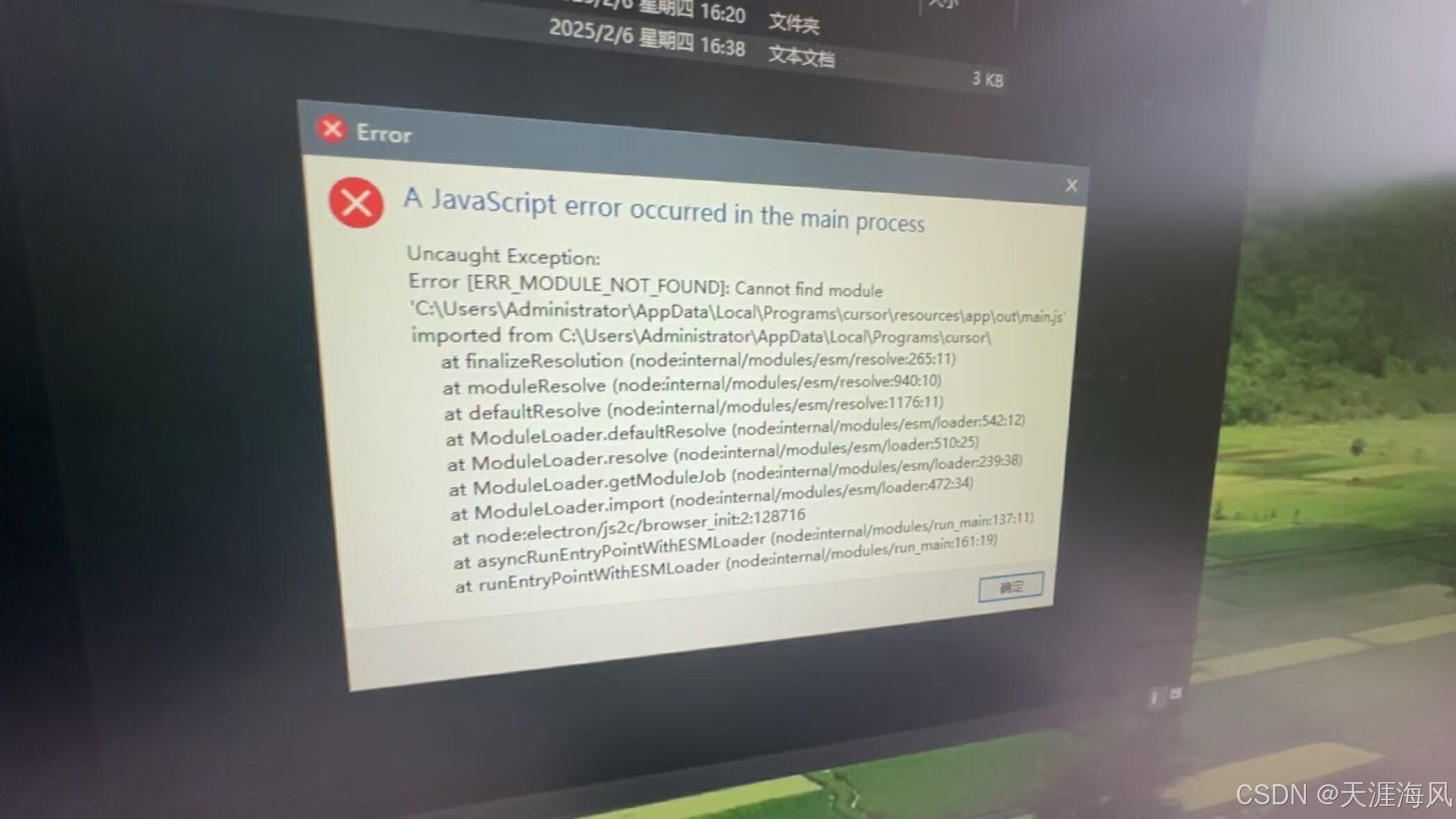
Curser2_解除机器码限制
# Curser1_无限白嫖试用次数
文末有所需工具下载地址
Cursor Device ID Changer
一个用于修改 Cursor 编辑器设备 ID 的跨平台工具集。当遇到设备 ID 锁定问题时,可用于重置设备标识。
功能特性
✨ 支持 Windows 和 macOS 系统🔄 自动生成符合格式的…

linux部署node服务
1、安装nvm管理node版本
# 下载、解压到指定目录
wget https://github.com/nvm-sh/nvm/archive/refs/tags/v0.39.1.tar.gz
tar -zxvf nvm-0.39.0.tar.gz -C /opt/nvm
# 配置环境
vim ~/.bashrc~:这是一个路径简写符号,代表当前用户的主目录。在大多数 …