文章目录
- 反转类型:
- 206.反转链表
- 完整版
- 二刷记录
- 25. K个一组反转链表
- 1 :子链表左闭右闭反转版本
- 2 : 子链表左闭右开反转版本(推荐)
- ⭐反转链表左闭右闭和左闭右开
- 合并类型:
- 21.合并两个有序链表
- 1: 递归法
- 2: 模拟(迭代法)
- 不使用虚拟头节点的做法
- 使用虚拟头节点优化
- ⭐虚拟头节点的意义
- ⭐虚拟头节点使用场景:
- 链表相交/环形类型
- 160.相交链表
- 思路
- 完整版
- ⭐swap函数保证headA始终指向更长的链表
- ⭐关于链表头节点指针指向
- 7.环形链表
- 思路
- 判断有环
- 找环入口
- 完整版
- 删除类型
- 203.移除链表元素
- 1.不使用虚拟头节点
- 注意:
- 2.使用虚拟头节点
- 注意:
- 二刷记录
- 二刷注意点:为什么移除链表元素需要临时指针变量
- 总结:
- 链表所有节点都是存在堆上面的吗?
- 19.删除链表倒数第N个节点
- 思路
- 完整版
- ⭐关于虚拟头结点的补充
- 交换类型
- 两两交换链表元素
- 完整版
- 注意问题:为什么一定要return dummyHead->next而不是return head
- ⭐关于虚拟头节点指针指向的分析
反转类型:
206.反转链表
- 反转类型的话可以不用虚拟头节点,因为可以直接把虚拟头节点看成nullptr
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:

输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
示例 2:

输入:head = [1,2]
输出:[2,1]
示例 3:
输入:head = []
输出:[]
提示:
- 链表中节点的数目范围是
[0, 5000] -5000 <= Node.val <= 5000
完整版
class Solution {
public:ListNode* reverseList(ListNode* head) {//设置一个指针指向当前节点反转后应该指向的那一位ListNode* next = nullptr;ListNode* cur = head;//设置遍历用的指针ListNode* pre = nullptr;//这里用来保存cur->next,因为cur->next会更改while(cur!=nullptr){ //这里需要提前保存cur的下一个节点!pre = cur->next;//保存节点cur->next = next;next = cur;cur = pre;}return next;//这里应该返回next}
};
二刷记录
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* reverseList(ListNode* head) {//先定义节点存放当前节点指向的下一个节点ListNode* next = nullptr;//遍历用的指针ListNode* cur = head;//这里不能这么写限制条件,链表只有一个节点或者为空的时候,就会出现nullptr->next的问题//while(cur->next!=nullptr)while(cur!=nullptr){ListNode* pre = cur->next;cur->next = next;next = cur;cur = pre;}//这里返回的是next,也就是cur的前一个return next;}
};
25. K个一组反转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:
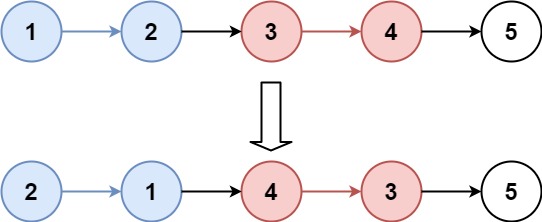
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
示例 2:

输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
提示:
- 链表中的节点数目为
n 1 <= k <= n <= 50000 <= Node.val <= 1000
1 :子链表左闭右闭反转版本
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:pair<ListNode*,ListNode*> reverseSon(ListNode* head,ListNode* tail){//左闭右闭区间反转[head,tail]的所有元素ListNode* cur = head;ListNode* next = nullptr,;//左闭右闭要保证tail不是空节点while(cur!=tail->next){ListNode* pre = cur->next;cur->next = next;next = cur;cur = pre;}return {tail,head};}ListNode* reverseKGroup(ListNode* head, int k) {ListNode* cur = head;bool firstReverse = true;//为了接起来子区间,要记录上一个区间的尾部ListNode* tail = nullptr;while(cur!=nullptr){ListNode* cur1 = cur;//先查看剩下部分是不是<kfor(int i=0;i<k-1;i++){//<k就直接返回头节点cur1 = cur1->next;if(cur1==nullptr){return head;}//cur1 = cur1->next;}//cur1这个时候指向的是K组最后一位!//if(cur1)//cout<<cur1->val<<endl;ListNode* cur2 = nullptr;if(cur1!=nullptr){cur2 = cur1->next;//cout<<cur2->val<<endl;}//剩下部分>k,开始反转前k个//if(cur) cout<<cur->val<<endl;pair<ListNode*,ListNode*>res = reverseSon(cur,cur1);//反转之后要更新head指针if(firstReverse){head = res.first;firstReverse = false;}//ListNode* tail = nullptr;//只要tail不是空指针,就说明不是第一个区间的末尾if(tail!=nullptr){tail->next = res.first;}tail = res.second;tail->next = cur2;cur = tail->next; }return head;}
};
2 : 子链表左闭右开反转版本(推荐)
class Solution {
public:// pair<ListNode*,ListNode*> reverseSon(ListNode* head,ListNode* tail){// //左闭右闭区间反转[head,tail]的所有元素// ListNode* cur = head;// ListNode* next = nullptr,*x = tail->next;// while(cur!=x){// ListNode* pre = cur->next;// cur->next = next;// next = cur;// cur = pre;// }// return {tail,head};// }pair<ListNode*,ListNode*> reverseSon(ListNode* head,ListNode* tail){//左闭右开区间反转[head,tail)的所有元素ListNode* cur = head;ListNode* prev = nullptr;while(cur != tail){//与左闭右闭的区别1:cur!=tailListNode* next = cur->next;cur->next = prev;prev = cur;cur = next;}//此时cur==tail,不反转tail,现在的尾部是prev//与左闭右闭的区别2:返回的头部应该是prev而不是tailreturn {prev, head}; // prev指向新的头部,head现在是尾部}ListNode* reverseKGroup(ListNode* head, int k) {ListNode* cur = head;bool firstReverse = true;//为了接起来子区间,要记录上一个区间的尾部,这里必须前面统一声明!ListNode* tail = nullptr;while(cur!=nullptr){ListNode* cur1 = cur;//先查看剩下部分是不是<kfor(int i=0;i<k;i++){cout<<"开始运行for循环第"<<i<<"次";//<k就直接返回头节点if(cur1==nullptr){return head;}cout<<"next之前"<<cur1->val<<endl;cur1 = cur1->next;}//i<k的话,cur1这个时候指向的是K组最后一位的下一位//剩下部分>k,开始反转前k个,这里的反转必须是左闭右开区间!pair<ListNode*,ListNode*>res = reverseSon(cur,cur1);//反转之后要更新head指针if(firstReverse){head = res.first;firstReverse = false;}//tail存放上一个区间的结尾,用于连接,这个tail必须放在外面声明!否则每次while执行重新定义tail就没有意义!//ListNode* tail = nullptr;//只要tail不是空指针,就说明不是第一个区间的末尾if(tail!=nullptr){tail->next = res.first;}tail = res.second;tail->next = cur1;cur = tail->next; }return head;}
};
⭐反转链表左闭右闭和左闭右开
普通的反转链表,例如下面的reverseList函数是完整地反转一个链表。这种反转链表的方式实际上不是左闭右开也不是左闭右闭,因为它处理的是整个链表,不是区间。也就是说,从链表的开始到结束,每一个节点都被反转了。
class Solution {
public:ListNode* reverseList(ListNode* head) {//设置一个指针指向当前节点反转后应该指向的那一位ListNode* next = nullptr;ListNode* cur = head;//设置遍历用的指针ListNode* pre = nullptr;//这里用来保存cur->next,因为cur->next会更改while(cur!=nullptr){ //这里需要提前保存cur的下一个节点!pre = cur->next;//保存节点cur->next = next;next = cur;cur = pre;}return next;//这里应该返回next}
};
如果我们想在这种基础上讨论区间的概念,那么可以说它是从头节点head开始,到链表的结束进行反转,因此相当于左闭右开。“开”的部分是指向nullptr的,因为链表的结束就是nullptr。
左闭右闭的写法,是包含了反转tail节点:
pair<ListNode*,ListNode*>reverseSon(ListNode* head,ListNode* tail){ListNode* cur = head;ListNode* prev = nullptr;//需要保证tail不是nullptrwhile(cur!=tail->next){ListNode* next = cur->next;cur->next = prev;prev = cur;cur = next;}return {tail,head};
}
左闭右开写法:
pair<ListNode*,ListNode*>reverseSon(ListNode* head,ListNode* tail){ListNode* cur = head;ListNode* prev = nullptr;//不包括反转tailwhile(cur!=tail){ListNode* next = cur->next;cur->next = prev;prev = cur;cur = next;}return {prev,head};//返回的时候要返回tail的前一个
}
合并类型:
21.合并两个有序链表
1: 递归法
class Solution {
public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {//第一种方式:递归//终止条件:如果List1为空了那么返回list2if(list1==nullptr) return list2;if(list2==nullptr) return list1;//单层逻辑if(list1->val < list2->val){//这里一定要把比较大的那个list节点本身传进去,否则就会导致两个同样位置地节点只选一个list1->next = mergeTwoLists(list1->next,list2);return list1;}list2->next = mergeTwoLists(list1,list2->next);return list2;}
};
2: 模拟(迭代法)
不使用虚拟头节点的做法
class Solution {
public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {//第二种方式:模拟,不使用虚拟头节点if(list1==nullptr) return list2;if(list2==nullptr) return list1;ListNode* head = nullptr;ListNode* cur = nullptr;//定义头节点if(list1->val < list2->val){head = list1;list1 = list1->next;}else{head = list2;list2 = list2->next;}cur = head;//挨个遍历存放新的链表节点while(list1!=nullptr&&list2!=nullptr){if(list1->val < list2->val){cur->next = list1;list1 = list1->next;}else{cur->next = list2;list2 = list2->next;}//给cur->next赋值结束后,继续增加节点cur = cur->next;}//结束之后还有多的就拼接if(list1!=nullptr){cur->next = list1;}else if(list2!=nullptr){cur->next = list2;}return head;}
};
使用虚拟头节点优化
class Solution {
public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {//第三种方式:模拟,使用虚拟头节点优化代码if(list1==nullptr) return list2;if(list2==nullptr) return list1;//虚拟头节点需要建立一个新节点,确保不存在nullptr->next的问题ListNode* dummyHead = new ListNode(0);ListNode* cur = nullptr;// ListNode* head = nullptr;// //定义头节点// if(list1->val < list2->val){// head = list1;// list1 = list1->next;// }// else{// head = list2;// list2 = list2->next;// }cur = dummyHead;//挨个遍历存放新的链表节点while(list1!=nullptr&&list2!=nullptr){if(list1->val < list2->val){//虚拟头节点就是为了防止这里出问题!cur->next = list1;list1 = list1->next;}else{cur->next = list2;list2 = list2->next;}//给cur->next赋值结束后,继续增加节点cur = cur->next;}//结束之后还有多的就拼接if(list1!=nullptr){cur->next = list1;}else if(list2!=nullptr){cur->next = list2;}//最后的头节点是虚拟头节点的下一个节点return dummyHead->next;}
};
⭐虚拟头节点的意义
- 使用虚拟头节点:
- 创建一个虚拟头节点。
- 不需要单独处理结果链表的头节点。
- 直接在循环中操作
cur->next,不需要担心cur是否为空。 - 最后直接返回
dummyHead->next。
- 不使用虚拟头节点:
- 需要单独处理结果链表的头节点。
- 在循环开始前,必须确定哪个链表的节点作为头节点,这需要额外的条件判断。
- 需要确保在操作
cur->next之前cur不为空。
⭐虚拟头节点使用场景:
- 删除链表元素:当需要删除头部元素时,没有虚拟头节点可能需要单独处理这种情况,因为直接删除头节点会改变链表的头部。但是,如果有一个虚拟头节点指向真正的头部,那么删除头部元素就与删除链表中的其他元素一样了。
- 插入链表元素:当在链表的开头或特定位置插入元素时,虚拟头节点可以简化操作。不需要单独判断是否是在链表的头部插入。
- 涉及到nullptr->next的情况:在某些操作中,可能存在访问空指针的风险。例如,在合并、反转或排序链表时,操作
cur->next之前必须确保cur不是nullptr。使用虚拟头节点可以确保始终有一个非空节点,从而避免这种风险。 - 返回链表的结果:在某些操作中,如合并两个有序链表,结果链表的头部可能会在运行时确定。使用虚拟头节点可以避免为结果链表的实际头部做特殊处理,因为可以直接返回
dummyHead->next作为结果。
虽然虚拟头节点对于简化代码和处理边界情况很有帮助,但在使用时也要确保不忘记释放其内存(尤其在C++中),以防止内存泄漏。
链表相交/环形类型
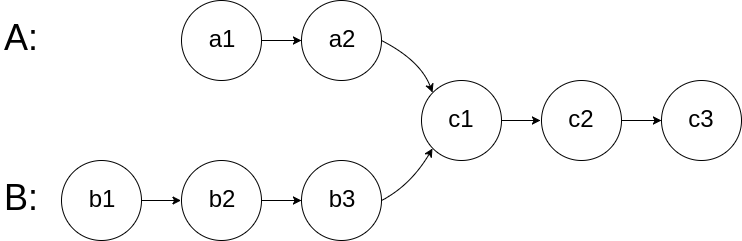
160.相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
图示两个链表在节点 c1 开始相交**:**
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
示例 1:
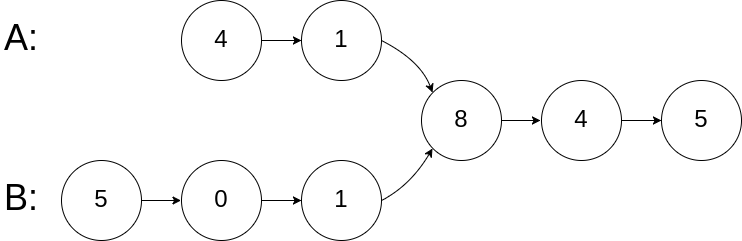
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:

输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
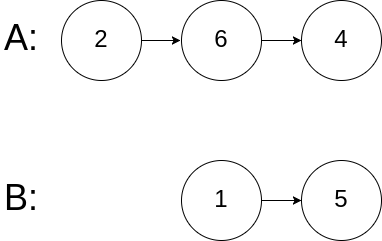
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
提示:
listA中节点数目为mlistB中节点数目为n0 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n- 如果
listA和listB没有交点,intersectVal为0 - 如果
listA和listB有交点,intersectVal == listA[skipA + 1] == listB[skipB + 1]
思路
求出两个链表的长度,然后求解长度差值,让末尾元素对齐(末尾元素对齐的目的是因为后面的才会相等,所以让末尾元素对齐而不是开头元素),然后找到第一个相等的节点,直接返回即可。
完整版
class Solution {
public:ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {//求出lenAint lenA=0;int lenB=0;ListNode* curA = headA;while(curA!=nullptr){lenA++;curA = curA->next;}//求出lenBListNode* curB = headB;while(curB!=nullptr){lenB++;curB = curB->next;}//让A和B末尾对齐int gap = abs(lenA-lenB);//对齐之前先强行让lenA = 比较长的那个链表的长度if(lenA<lenB){swap(lenA,lenB);//同时也要让headA = 比较长的那个链表头节点?swap(headA,headB);}//重新置零遍历的两个指针curA = headA;curB = headB;while(gap--){curA = curA->next;}//末尾对齐之后,从较短的链表第一个元素位置开始遍历,相等直接返回,没有相等的返回-1//curA现在是对齐的第一个元素while(curA!=nullptr&&curB!=nullptr){if(curA==curB)//注意是指针相等而不是值相等!return curA;else{curA = curA->next;curB = curB->next;}}return nullptr;}
};
⭐swap函数保证headA始终指向更长的链表
在C++的标准库中,swap 函数可以交换两个对象的值。在这个代码中,headA 和 headB 都是指向 ListNode 的指针。当你调用 swap(headA, headB),实际上是交换了两个指针的值,而不是它们所指向的整个链表。
如果,想确保 headA(和相应的 curA)始终指向更长的链表,就可以直接swap一下headA和headB,让headA指向链表B的头部,headB指向链表A的头部。
⭐关于链表头节点指针指向
headA 是一个指向链表节点的指针,这个节点有 val 和 next 这两个属性。
但是,当 swap(headA, headB) 时,仅仅是交换了两个指针的值,也就是它们指向的内存地址。你没有交换这些指针所指向的内容,即没有交换任何节点的 val 和 next 属性。
假设,链表A的起始节点的内存地址是 0x1000,链表B的起始节点的内存地址是 0x2000:
-
在 swap之前:
headA存储的值是0x1000。headB存储的值是0x2000。
-
执行swap(headA, headB)之后:
headA存储的值变成了0x2000。headB存储的值变成了0x1000。
但在内存地址 0x1000 和 0x2000 处的实际内容(也就是链表的节点)并没有改变。所以说,我们只是改变了指针的指向,而不是它们所指向的内容。
headA 仅仅是一个指针,它存储的是一个内存地址,也就是 0x1000 在上面的例子中。这个地址指向的实际内存位置存储了节点的内容,即 val 和 next 属性。
当访问 headA->val 或 headA->next 时,实际上是在访问内存地址 0x1000 处的内容。而 headA 本身并不存储这个节点的内容,它只存储了一个指向该节点的地址。
所以,当交换 headA 和 headB 的值时,实际上只是交换了两个指针存储的内存地址,而不是这些地址所指向的实际内容。
7.环形链表
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:

输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
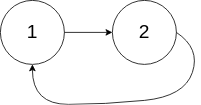
输入:head = [1,2], pos = 0
输出:返回索引为 0 的链表节点
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1
输出:返回 null
解释:链表中没有环。
提示:
- 链表中节点的数目范围在范围
[0, 104]内 -105 <= Node.val <= 105pos的值为-1或者链表中的一个有效索引
思路
代码随想录 (programmercarl.com)
判断有环
双指针法,fast走两步slow走一步,如果没有环那么这两个指针永远不会相遇。如果有环的话,那么fast和slow一定是在环中相遇。
这是因为对于slow来说,在环里面,fast是一个节点一个节点接近slow,所以fast和slow一定会重合。
所以看fast和slow是否重合,就可以判断是不是有环。
找环入口
假设从头结点到环形入口节点 的节点数为x。 环形入口节点到 fast指针与slow指针相遇节点 节点数为y。 从相遇节点 再到环形入口节点节点数为 z。 如图所示:
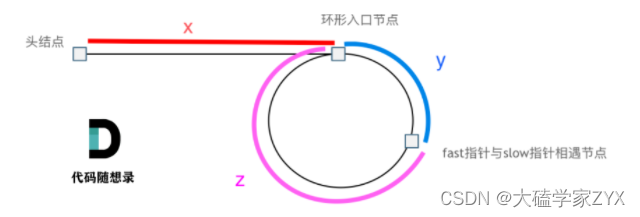
相遇的时候,slow走过了x+y距离,fast走过了x+y+n(y+z)的距离,n是套圈的圈数。y+z是圈的长度(圈的节点个数)。
fast一步俩节点,slow一步一节点,fast节点数=slow节点数*2。
(x+y)*2 = x+y+n(y+z)
消掉一个x+y:x+y = n(y+z)
求x:x = n(y+z)-y也就是x = (n-1)(y+z)+z
当n=1的时候,发现x=z!
x=z意味着,从相遇节点出发一个指针,头节点出发一个指针,那么他们相遇的地方,就是环的起点!
但,n如果大于1是什么情况呢,也就是fast指针在环形转n圈之后才遇到 slow指针。
其实这种情况和n为1的时候效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
总结:
- 先快慢指针找到相遇节点,快指针一次两步,慢指针一次一步,相遇了就是有环,没相遇就是没环
- 相遇节点和头节点各自出发一个指针,碰上的地方就是环起点
完整版
class Solution {
public:ListNode *detectCycle(ListNode *head) {//定义快慢指针,快指针一次两步,慢指针一次一步,相遇了就是有环ListNode* fast = head;ListNode* slow = head;while(slow!=nullptr&&fast!=nullptr&&fast->next!=nullptr){slow = slow->next;fast = fast->next->next;//当快慢指针重合,说明有环if(slow==fast){//如果重合,开始找环起点//相遇位置就是slowListNode* index1 = slow;ListNode* index2 = head;while(index1!=index2){index1 = index1->next;index2 = index2->next;}//此时index1==index2,也就是x=z,该位置就是环起点return index1;}}return nullptr;}
};
删除类型
203.移除链表元素
使用虚拟头节点(dummy head)的方式,统一头节点和非头节点的删除方式,不需要if再判断该节点是不是头节点
1.不使用虚拟头节点
(先确保不为空,操作空指针的话编译会报错)
class Solution {
public:ListNode* removeElements(ListNode* head, int val) {// 删除头结点//注意:不用虚拟头节点的话,需要考虑两种情况,第一种是head本身就符合删除条件,第二种是head本身不符合删除条件while (head != NULL && head->val == val) { // 注意这里不是if//进行内存释放的操作,先存起来之前指向的这个头结点的地址//指针存放的是地址ListNode* tmp = head;head = head->next;delete tmp;}// 删除非头结点ListNode* cur = head;while (cur != NULL && cur->next!= NULL) {if (cur->next->val == val) {ListNode* tmp = cur->next;cur->next = cur->next->next;delete tmp;} else {cur = cur->next;}}return head;}
};
注意:
-
不用虚拟头节点的话,需要考虑两种情况,第一种是head本身就符合删除条件,第二种是head本身不符合删除条件。
-
c++需要进行手动内存释放!也就是指针
tmp做的事情。 -
检查指针是否为空,空指针会报错。
-
移除头节点是一个持续移除的操作,因此应该使用while而不是if操作
-
定义的临时指针是从head开始的,而不是从head的下一个元素开始。原因在于,如果我要删除该元素,我需要找到这个元素的前一个元素。
如果head的下一个元素刚好是需要删除的,但这是一个单向链表,无法找到这个节点的上一个节点,该元素就无法删除。
-
因此,临时指针current必须从=head开始,而不是head->next.
2.使用虚拟头节点
class Solution {
public:ListNode* removeElements(ListNode* head, int val) { //注意:listNode* 表示一个listNode类型的指针,而listNode表示一个链表类型的对象//ListNode对象包括一个表示其值val和指向下一个对象的指针next.ListNode* dummyHead = new ListNode(0);dummyHead->next = head; //head是算法输入直接给出的头节点,注意指针指向头节点ListNode* cur = dummyHead;//临时指针cur不要重新定义,需要令cur和dummyHead指向同一块内存。while(cur->next!=NULL){//链表遍历结束的标志:最后一个节点的next指针为空//遍历未结束的时候,判断内容是否等于valif(cur->next->val==val){//如果相等,那么需要删除,先定义新指针存储需要删除的节点地址ListNode* tmp = cur->next;//再令遍历指针删除该节点cur->next = cur->next->next;//根据刚刚新建的指针找到该节点内存地址,手动释放内存delete tmp;}else//cur->next++;注意,链表中的指针++没有意义,因为链表内存不连续cur = cur->next;//}//返回新的头节点return dummyHead->next; //此处dummyHead->next才是新的头节点}
};
注意:
-
dummy head是new出来一个新的节点,让他的next指向原来链表的head. -
定义一个临时指针cur,用来遍历整个链表。注意不能用头节点来遍历,头节点遍历会导致头节点指向的值是在不断改变的。最后会无法返回原先列表的头节点。头结点指针是不能改的,需要定义临时指针。
-
临时指针指向虚拟头节点,而不是真的头节点。因为是单向链表。
-
一定要记住时刻判断指针是否为空。
-
return的时候,题目要求返回删除后新的头节点,此时我们return的不是head,而是虚拟头节点的下一个。不return head的原因是head有可能已经被删了。只有**
dummy_head->next才是新链表的头节点**。一定不要return head。
二刷记录
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* removeElements(ListNode* head, int val) {//第一种情况,head本身就符合删除条件//删除链表节点的时候,需要先存下来指向这个头节点的地址//要删除所有满足条件的!while(head!=nullptr&&head->val==val){ListNode* tmp = head;head = head->next;delete tmp;//释放原先头节点地址的内存}//head本身不满足条件ListNode* cur = head;while(cur!=nullptr&&cur->next!=nullptr){//如果相等if(cur->next->val==val){ListNode* tmp = cur->next;cur->next = cur->next->next;delete tmp;}//不相等的话指针继续else{cur = cur->next;}}return head;}
};
二刷注意点:为什么移除链表元素需要临时指针变量
- 操作链表用的指针
listNode*,就是指向链表节点存放的那个地址。所以,才需要删除之前存起来,方便删的时候找到对应地址,删除那个地址的内存。
ListNode* 是一个指针,它存储着链表节点对象的地址。当想要删除一个链表节点时,我们需要首先确保有一个临时的指针变量(例如 tmp)存储着该节点的地址,这样即使该节点被从链表中移除,也能通过这个临时指针访问到该节点对象的地址,从而可以正确地释放该节点所占用的内存。
总结:
- 指针存放地址:
ListNode*是一个指针,它存储的是链表节点的地址。 - 删除节点: 在删除链表中的一个节点前,需要有一个临时指针变量存储该节点的地址。这是因为在更改前一个节点的
next指针,跳过当前节点后,如果没有这个临时指针,你将无法访问到这个节点,也就无法释放它占用的内存。 - 释放内存: 一旦链表中的节点被跳过,且没有其他指针指向它,你就需要通过临时指针来释放该节点的内存,防止内存泄漏。
- 保持链表连贯性: 使用临时指针,在逻辑上移除链表节点之前保存节点地址,可以在物理上移除该节点时保持链表的连贯性。
链表所有节点都是存在堆上面的吗?
leetcode的代码片段没有提供创建 ListNode 对象的部分,所以我们不能直接从这个片段判断这些节点是在堆上还是栈上。但是,在解答中使用 delete 来释放节点内存,暗示这些节点很可能是在堆上分配的。
通常,你会在实际创建链表时确定节点的存储位置。如果链表是由用户输入或者文件输入等动态数据创建的,通常会使用 new 关键字动态分配内存,将节点存储在堆上。而如果是静态数据,固定大小,可能会选择将节点存储在栈上,以利用栈的自动内存管理。
如果创建链表节点的代码是这样的:
ListNode* newNode = new ListNode(1); // 节点在堆上分配
那么需要在删除节点时使用 delete 来释放内存。
如果创建链表节点的代码是这样的:
ListNode newNode(1); // 节点在栈上分配
那么不应该使用 delete,因为栈上的对象会在作用域结束时自动被销毁。
19.删除链表倒数第N个节点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:

输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
提示:
- 链表中结点的数目为
sz 1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
思路
删除倒数第N个节点,就是用双指针保持两个指针之间的距离是N。
fast先移动到第n+1个节点,slow在开头再开始移动。直到fast移动到nullptr,这个时候slow就指向倒数第n个节点的前一个节点。
(可以带入第一个例子尝试)
完整版
- 当使用虚拟头节点时,真实链表的起始节点始终是
dummyHead->next。
lass Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {ListNode* dummyHead = new ListNode(0);dummyHead->next = head;ListNode* fast = dummyHead;ListNode* slow = dummyHead;int count = 1;//快指针要到n+1个节点处,加上虚拟头节点就是走n+2步while(count<=n+1&&fast!=nullptr){fast = fast->next;count++;}if(fast!=nullptr)cout<<fast->val<<endl;//fast到了第n+1个节点位置while(fast!=nullptr){slow = slow->next;fast = fast->next;}cout<<slow->val<<endl;//slow到了第n个节点之前ListNode* tmp = slow->next;slow->next = slow->next->next;delete tmp;return dummyHead->next;}
};
⭐关于虚拟头结点的补充
当首次创建虚拟头节点并将其链接到真实链表时,例如:
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
此时,head 确实是原始链表的起始节点。但在之后的操作中,尤其是当你可能修改了链表的头部(如插入或删除节点)时,head 变量可能不再指向链表的第一个实际节点(例如交换链表元素那道题,head一直指向原来的头部节点)。
此时,dummyHead->next 会始终指向链表的第一个实际节点,而原始的 head 变量可能已经不再指向该节点。
因此,当我们说“使用虚拟头节点时,真实链表的起始节点始终是 dummyHead->next”,是指在完成链表操作后,我们可以始终依赖 dummyHead->next 来给我们正确的链表起点,而不是原始的 head 变量,除非你确保没有修改过头节点。
- 尽管最初
head和dummyHead->next都指向真实链表的起始,但在一系列操作后,通常只有dummyHead->next保证仍然这样做。
交换类型
两两交换链表元素
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:

输入:head = [1,2,3,4]
输出:[2,1,4,3]
示例 2:
输入:head = []
输出:[]
示例 3:
输入:head = [1]
输出:[1]
提示:
- 链表中节点的数目在范围
[0, 100]内 0 <= Node.val <= 100
完整版
class Solution {
public:ListNode* swapPairs(ListNode* head) {ListNode* dummyHead = new ListNode(0);dummyHead->next = head;ListNode* cur = dummyHead;ListNode* tmp = nullptr;ListNode* tmp2 = nullptr;while(cur->next!=nullptr&&cur->next->next!=nullptr){tmp = cur->next;//1位置tmp2 = cur->next->next->next;//3位置cur->next = cur->next->next;cout<<cur->next->val<<endl;cur->next->next = tmp;cur->next->next->next = tmp2;cur = cur->next->next;}//return head;//这里return head是错误的return dummyHead->next;}
};
注意问题:为什么一定要return dummyHead->next而不是return head
当我们对链表进行操作时,需要明确区分节点本身和变量或指针的概念。
首先,head这个变量始终是指向原链表的第一个节点的。当你创建了dummyHead并使其指向head时,dummyHead->next和head都指向同一个节点。但后续**,即使你改变了dummyHead->next的指向,head这个变量本身还是会指向原来的那个节点,它并不会随着dummyHead->next的改变而改变**。
考虑链表1->2->...。
- 初始时,
head指向1。 dummyHead->next = head之后,dummyHead->next也指向1。- 当执行
cur->next = cur->next->next,dummyHead->next(即cur->next)的指向改变,现在它指向2。但这并不影响head本身,head仍然指向1。
在交换操作后,head依然指向1,而dummyHead->next指向2。所以为了得到整个交换后的链表,应该返回dummyHead->next而不是head。
简而言之,即使dummyHead->next的指向发生了改变,head本身的指向并没有发生变化。这也是为什么我们需要返回dummyHead->next,而不是head的原因。
- 也就是说,head作为一个指针,只要我们没有直接修改head的指向,head就不会变化,始终指向1
在代码中,所有对链表结构的修改都是通过其他指针(如cur, dummyHead)进行的,而不是直接通过head。所以head的指向始终没有改变,它仍然指向原来的第一个节点。
⭐关于虚拟头节点指针指向的分析
-
ListNode* dummyHead = new ListNode(0);这里我们创建了一个新的节点
dummyHead。 -
ListNode* cur = dummyHead;这里我们创建了一个新的指针
cur,并让它指向dummyHead。此时cur和dummyHead都指向内存中的同一个位置。 -
在第一次的
while循环中,对cur的所有操作(例如cur->next = ...)实际上都是在修改dummyHead所指向的内存位置,因为此时cur和dummyHead指向相同的内存地址。 -
当我们执行
cur = cur->next->next;之后,cur的指向已经改变了。现在cur指向链表的其它位置,而不是最初的dummyHead位置。所以,在这之后的任何对cur的操作都不再影响dummyHead。
最后,我们返回dummyHead->next。注意,我们在整个函数中都没有修改dummyHead自身的指向,我们只修改了它的next属性(即dummyHead->next)。
简而言之:开始时,cur指向dummyHead,对cur的操作等同于对dummyHead的操作。但一旦我们改变了cur的指向,后续的操作就不再影响dummyHead了。