一般业务系统中都有导出到 Excel 功能,其实质就是把数据库里面一条条记录转换到 Excel 文件上。Java 常用的第三方类库有 Apache POI 和阿里巴巴开源的 EasyExcel 等。另外也有通过 Web 模板技术渲染 Excel 文件导出,这实质是 MVC 模式的延伸,数据转为成不同的视图罢了。
网上很多文章介绍用 Freemarker 模板渲染,应用这一机制的问题不大,本文也是遵循此思路,但没有依赖 Freemarker,而是 Java Servlet 原生的 JSP 模板机制,更加轻量级。
常见的问题
网上文章都介绍模板来自 Excel 另存为 xml 格式的,渲染然后改扩展名为 xls,xml 是文本文件当然可以轻易修改。但致命的问题是,Office Excel 打开的话会有对话框的警告提示,对用户而言非常错愕,用户自然觉得此 Excel 有什么问题,但确认后又可正常显示。在 WPS/LiberOffice 却没有这警告。
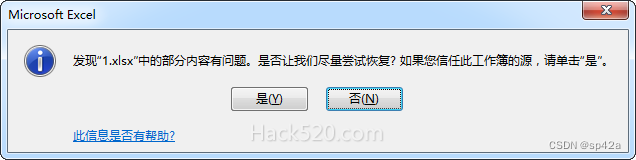
有没有办法绕过这提示呢?直接的方法好像没有,只要是 xml 纯文本的格式就绕不过。我想到了导出 word,同样也是 Freemarker 渲染,但更高明地,使用 zip 压缩包的文档格式,而非 xml 纯文本。我想,能不能在 Excel 上面亦如此炮制呢?
可惜的是,搜遍全网也没发现有类似的思路。但皇天不负有心人,我多次尝试后,亦发现此法可在 Excel 上成功。
使用步骤
新建 Excel 模板
新建 Excel 文档,有标题和模板填充占位符。我喜欢用 LiberOffice 的 Calc,亦无问题。
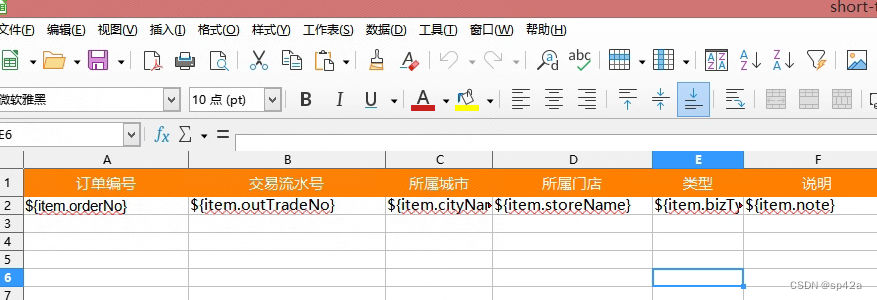
诸如${item.orderNo},显然是 JSP 的 EL 表达式。别告诉我你不会,这是最基础的 Java Web 开发内容。item 是固定的,后面的实际字段取值 key。
当然 EL 表达式能够支持的,这里你也同样可以写,如${xxx == 1 ? 'yes' : 'no'},不过建议在前面的数据层面就处理,这里直接显示了。
编辑好模板之后,保存为xlsx格式,注意是 xlsx 而非 xls,因为 xlsx 是 ZIP 压缩包而 xls 不是。
xlsx 文件等下还需要被使用的,将其放到工程的资源目录下。
提取模板
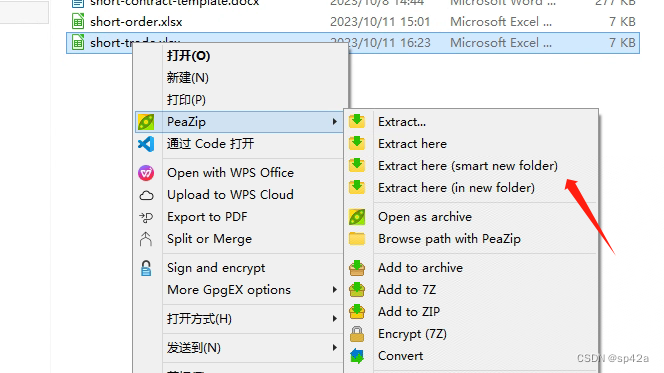
解压缩这个 xlsx 包,强制解压。这里我用 PeaZip,其他 7Zip、WinRaR 的工具一样。
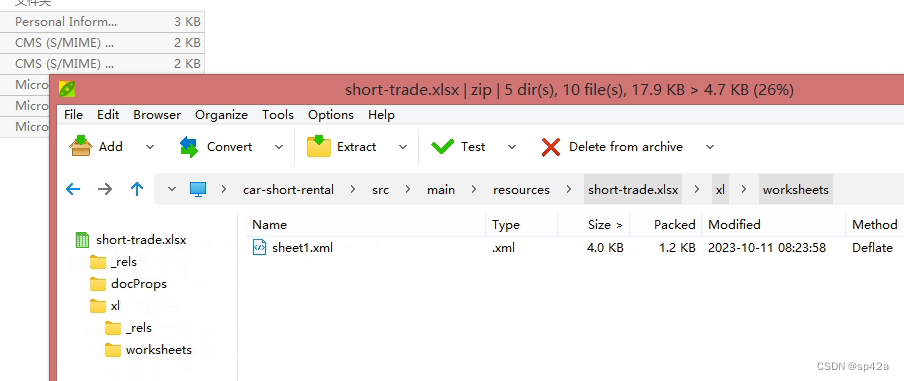
找到目录xl/worksheets这里的文件sheet1.xml,1 表示第一个工作簿,如此类推。
复制这个 sheet1.xml 到 Web 模板可读取的位置。什么意思呢?就是 Servlet 可以渲染此模板,填充数据的目录。这个 xml 是变成 JSP 文件的。根据 Servlet 3.0 规范,META-INF/resources就是 WebRoot,可以放置 HTM/CSS/JS/JSP,就算打包成 SpringBoot 的 jar 包可以。所以,一般这个 xml 就放到META-INF/resources中。
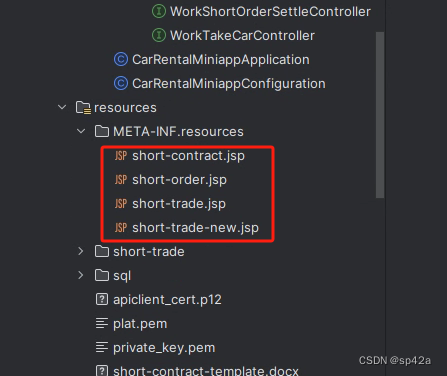
但又因,这里相当于 WebRoot,浏览器可以直接访问的,那么,放到META-INF/resources/WEB-INF/下似乎更好。
修改模板
当前模板还是 xml,先别急,用代码编辑器(如 VS-code)格式化下先,再改名 jsp 不迟。
然后加入文件头:<%@ page trimDirectiveWhitespaces="true" contentType="text/html; charset=UTF-8" import="java.util.*"%>,不然你会中文乱码的。

找到刚输入的 EL 表达式部分,要重新梳理下。因为 Excel SharedStrings 的缘故,你很可能找不到那些 EL 表达式字符串,没关系,大概就是节点<sheetData>下的第二个<row>节点(第一个是表头)。
重新梳理后的结果如下:
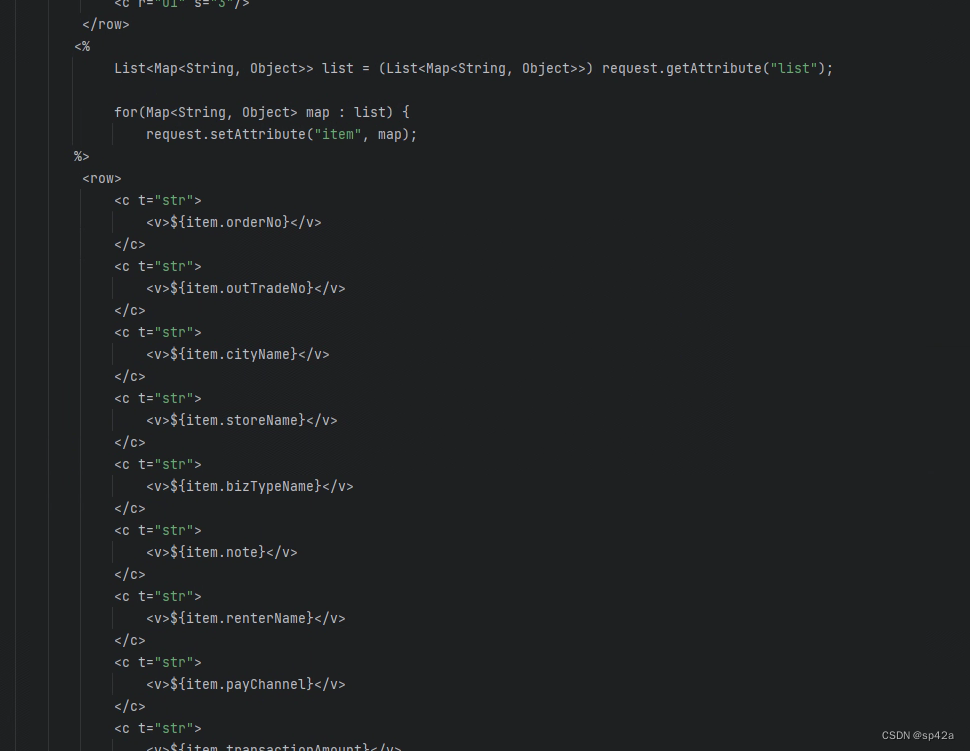
列表循环,这里的for很好理解,就是基础 Web 开发知识。
<%List<Map<String, Object>> list = (List<Map<String, Object>>) request.getAttribute("list");for(Map<String, Object> map : list) {request.setAttribute("item", map);%>
记得for后面的结束括号,别忘了加:
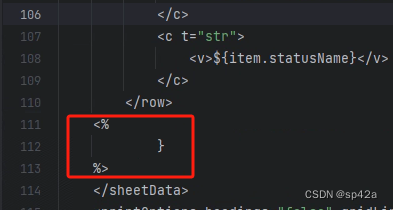
这里为什么要request.setAttribute("item", map);然后通过 EL 表达式取值呢?为什么不用<%=map.get("xxx")%>? 后者方式也行,但如果是 null 值就会显示 null,${item.statusName}的方式不会。
此时模板就搞定了。
渲染
有模板有数据就可以渲染了。假设是数据是List<Map<String, Object>> list,另外要有对象HttpServletRequest req, HttpServletResponse resp,下面就可渲染了。
Export e = new Export();
e.setIsXsl(true);
e.setIsOfficeZipInRes(true);
e.setTplJsp("/short-trade-new.jsp");
e.setOfficeZip("short-trade.xlsx");
e.setRespOutput(resp, "交易流水 " + DateUtil.now(DateUtil.DATE_FORMAT_SHORTER) + ".xlsx");
e.renderOffice(list, req, resp);
这是渲染到Response的,就是浏览器会直接提示下载的。如果你想保存到文件而非下载。去掉setRespOutput()并设置setOutputPath()保存路径即可。
看看这个单测,就是读取 xml 模板生成 xlsx 的
public static ByteArrayOutputStream p(String path) {File file = new File(path);try (FileInputStream fis = new FileInputStream(file); ByteArrayOutputStream bos = new ByteArrayOutputStream()) {byte[] buffer = new byte[1024];int len;while ((len = fis.read(buffer)) != -1)bos.write(buffer, 0, len);return bos;} catch (IOException e) {e.printStackTrace();}return null;
}@Test
public void replaceXsl() {String newXml = "C:\\code\\car-short-rental\\src\\main\\resources\\META-INF\\resources\\short-trade-new.xml";Export e = new Export();e.setIsXsl(true);e.setOfficeZip("C:\\code\\car-short-rental\\src\\main\\resources\\short-trade.xlsx");e.setOutputPath("C:\\temp\\test.xlsx");e.zip(p(newXml));
// e.zip(new ByteArrayServletOutputStream(p(newXml)));
}
源码
这个 Office 导出工具包,不但可以导出 Excel 还可以导出 Word 的,三个类去掉注释才 200 多行源码,足够精简。
package com.ajaxjs.tools.office_export;import com.ajaxjs.util.io.Resources;
import com.ajaxjs.util.io.StreamHelper;
import com.ajaxjs.util.logger.LogHelper;
import lombok.Data;import javax.servlet.RequestDispatcher;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpServletResponseWrapper;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.Enumeration;
import java.util.List;
import java.util.Map;
import java.util.zip.ZipEntry;
import java.util.zip.ZipFile;
import java.util.zip.ZipOutputStream;/*** Office 导出*/
@Data
public class Export {private static final LogHelper LOGGER = LogHelper.getLog(Export.class);/*** 模板 XML 文件*/private String tplXml;/*** 模板 JSP 文件,必须 / 开头,以及 .jsp 结尾*/private String tplJsp;/*** 原始 docx/xlsx 文档,其实是个 zip 包,我们取其结构,会替换里面的 xml*/private String officeZip;/*** 是否在资源文件目录*/private Boolean isOfficeZipInRes;private File officeZipRes;/*** 导出的 docx/xlsx 位置*/private String outputPath;/*** true=Excel 文件*/private Boolean isXsl;/*** 浏览器下载文件。如果设置该属性,表示浏览器下载文件,否则保存到文件*/private HttpServletResponse respOutput;/*** 浏览器下载文件。如果设置该属性,表示浏览器下载文件,否则保存到文件** @param respOutput 响应对象* @param fileName 下载的文件名*/public void setRespOutput(HttpServletResponse respOutput, String fileName) {this.respOutput = respOutput;respOutput.setContentType("application/vnd.ms-excel");respOutput.setHeader("Content-Disposition", "attachment; filename=\"" + Utils.encodeFileName(fileName) + "\"");}public void renderOffice(Object data, HttpServletRequest req, HttpServletResponse resp) {if (isXsl) {List<Map<String, Object>> list = (List<Map<String, Object>>) data;req.setAttribute("list", list); // 内容数据} else {Map<String, Object> map = (Map<String, Object>) data;for (String key : map.keySet())req.setAttribute(key, map.get(key)); // 内容数据}if (!tplJsp.startsWith("/"))throw new IllegalArgumentException("参数 tplJsp 必须以 / 开头");RequestDispatcher rd = req.getServletContext().getRequestDispatcher(tplJsp);try (ByteArrayServletOutputStream stream = new ByteArrayServletOutputStream();PrintWriter pw = new PrintWriter(new OutputStreamWriter(stream.getOut(), StandardCharsets.UTF_8));) {rd.include(req, new HttpServletResponseWrapper(resp) {@Overridepublic ServletOutputStream getOutputStream() {return stream;}@Overridepublic PrintWriter getWriter() {return pw;}});pw.flush();officeZipRes = input2file(officeZip);zip(stream);officeZipRes.delete();} catch (IOException | ServletException e) {LOGGER.warning(e);}}/*** 替换 Zip 包中的 XML** @param stream 文件流*/void zip(ByteArrayServletOutputStream stream) {zip(stream.getOut());}/*** 替换 Zip 包中的 XML** @param stream 文件流*/void zip(ByteArrayOutputStream stream) {int len;byte[] buffer = new byte[1024];try (ZipFile zipFile = isOfficeZipInRes ? new ZipFile(officeZipRes) : new ZipFile(officeZip); // 原压缩包ZipOutputStream zipOut = new ZipOutputStream(respOutput == null ? Files.newOutputStream(Paths.get(outputPath)) : respOutput.getOutputStream()) /* 输出的 */) {Enumeration<? extends ZipEntry> zipEntry = zipFile.entries();
// ByteArrayInputStream imgData = img((List<Map<String, Object>>) dataMap.get("picList"), zipOut, dataMap, resXml);String targetXml = isXsl ? "xl/worksheets/sheet1.xml" : "word/document.xml";
//// 开始覆盖文档------------------while (zipEntry.hasMoreElements()) {ZipEntry entry = zipEntry.nextElement();try (InputStream is = zipFile.getInputStream(entry)) {zipOut.putNextEntry(new ZipEntry(entry.getName()));if (entry.getName().indexOf("document.xml.rels") > 0) { //如果是document.xml.rels由我们输入
// if (documentXmlRelsInput != null) {
// while ((len = documentXmlRelsInput.read(buffer)) != -1) zipOut.write(buffer, 0, len);
//
// documentXmlRelsInput.close();
// }while ((len = is.read(buffer)) != -1) zipOut.write(buffer, 0, len);} else if (targetXml.equals(entry.getName())) {//如果是word/document.xml由我们输入stream.writeTo(zipOut);} else {while ((len = is.read(buffer)) != -1) zipOut.write(buffer, 0, len);}}}} catch (IOException e) {LOGGER.warning(e);}}/*** 从资源目录中获取文件对象,兼容 JAR 包的方式** @param resourcePath 资源文件* @return 文件对象*/public static File input2file(String resourcePath) {try {File outputFile = File.createTempFile("outputFile", ".docx");// 创建临时文件// 创建输出流try (InputStream input = Resources.getResource(resourcePath);OutputStream output = Files.newOutputStream(outputFile.toPath())) {StreamHelper.write(input, output, false);}return outputFile;} catch (IOException e) {LOGGER.warning(e);}return null;}
}
完整的代码在这里。
参考
- 使用Freemarker填充模板导出复杂Excel,其实很简单哒!
- OOXML:详解Excel共享字符串(sharedStrings)
- 掀开面纱,看看Excel文件到底是什么
- 使用Freemarker模版导出xls文件使用excel打开提示文件损坏
- 一次大数据量导出优化–借助xml导出xls、xlsx文件